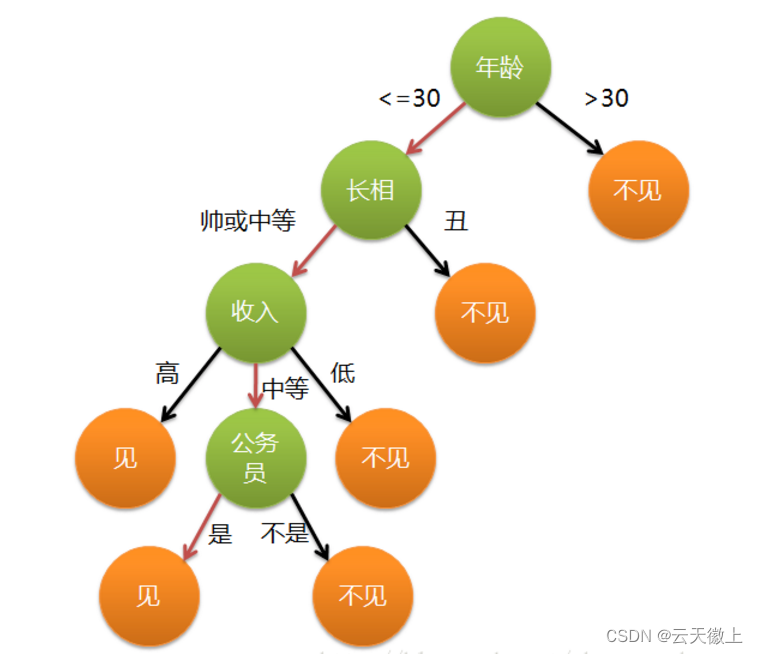
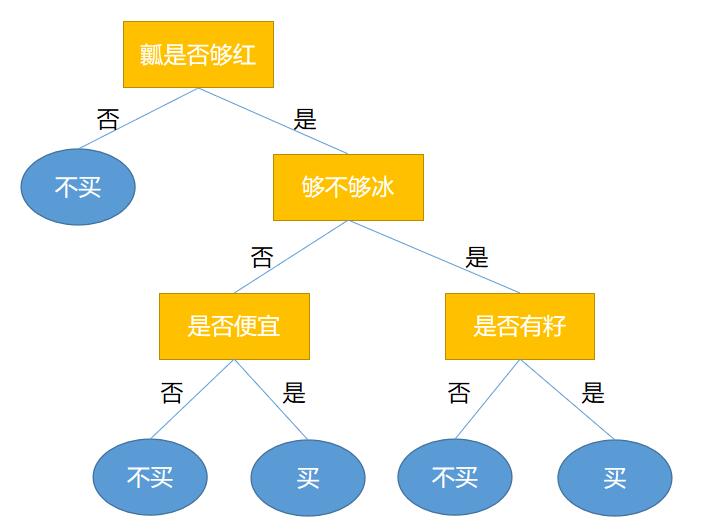
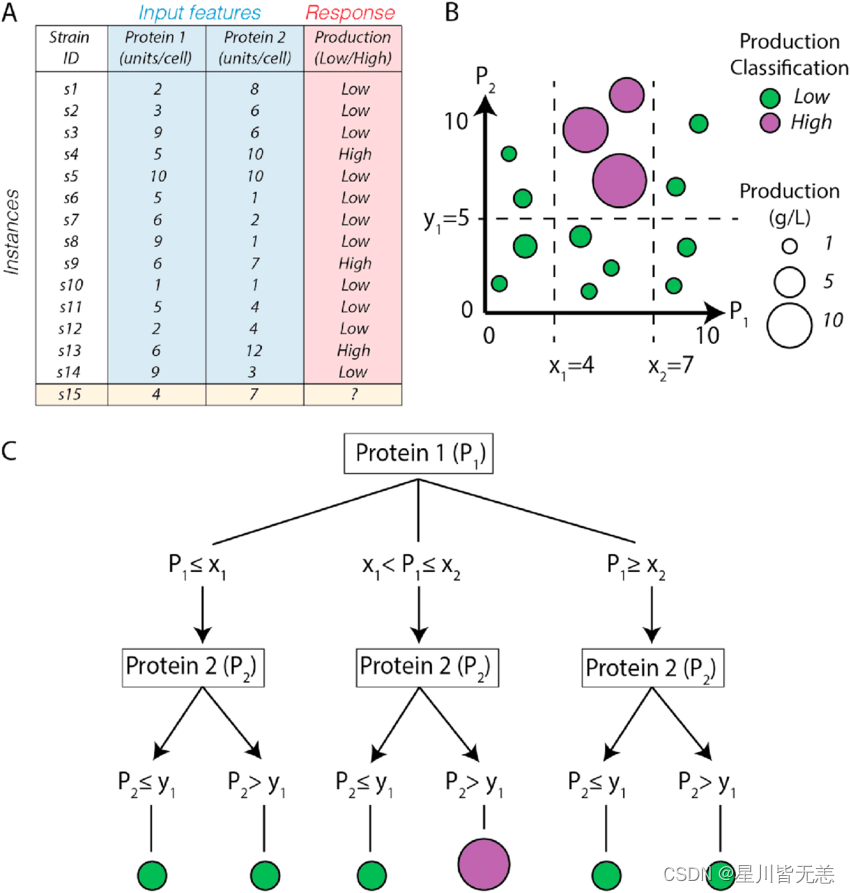
一、引言
决策树是一种广泛应用于分类和回归问题的监督学习算法。它通过构建一个树状模型来进行数据分析和预测。决策树的每个内部节点表示一个特征上的测试,每个分支代表一个测试输出,每个叶节点则代表一个类别或预测值。由于其直观易懂、易于解释和实现的特性,决策树算法在数据分析和机器学习领域有着广泛的应用。本文将详细介绍决策树算法的原理,并通过一个具体的案例和详细的代码实现来加深理解。
二、决策树算法原理
1. 决策树的基本概念
决策树是一种树形结构,其中每个内部节点表示一个特征或属性的测试,每个分支代表该特征的一个可能值(或值的范围),每个叶节点代表一个类别或预测值。决策树的构建过程就是从根节点开始,根据特征的测试值逐步向下分裂,直到满足停止条件为止。
2. 特征选择
在构建决策树时,如何选择一个好的特征进行分裂是关键。常见的特征选择准则有信息增益、增益率、基尼指数等。这些准则都是基于数据集的纯度来衡量的,即选择分裂后子数据集纯度提升最大的特征作为分裂依据。
- 信息增益:信息增益是基于信息熵的概念来计算的。信息熵用于衡量数据集的纯度,纯度越低,则信息熵越大。选择信息增益最大的特征进行分裂,意味着分裂后子数据集的纯度提升最大。
- 增益率:增益率是在信息增益的基础上考虑了特征自身的复杂度。为了避免选择取值过多的特征(如ID号等),增益率通过引入一个惩罚项来平衡信息增益和特征复杂度之间的关系。
- 基尼指数:基尼指数是CART(Classification and Regression Trees)算法中用于分类问题的特征选择准则。它表示按照某个特征划分数据集后,不纯度降低的程度。选择基尼指数最小的特征进行分裂,意味着分裂后子数据集的不纯度最低。
3. 决策树的构建
决策树的构建是一个递归过程。从根节点开始,对每个节点进行以下操作:
- 如果当前节点包含的样本全属于同一类别,则将该节点标记为叶节点,并将其类别设置为该样本的类别。
- 如果当前节点包含的样本集为空,则将该节点标记为叶节点,并将其类别设置为其父节点样本集中最多的类别(或根据其他策略设定)。
- 否则,从当前节点的特征集合中选择一个最优特征进行分裂。最优特征的选择依据上述特征选择准则。
- 根据选定的最优特征,将当前节点包含的样本集划分为若干个子集,每个子集对应一个分支。
- 对每个子集递归地执行上述操作,直到满足停止条件(如树深度达到预设值、节点包含的样本数小于预设阈值、所有特征都已使用等)。
4. 决策树的剪枝
为了避免过拟合,通常需要对决策树进行剪枝。剪枝分为预剪枝和后剪枝两种。预剪枝是在决策树构建过程中提前停止树的生长,如设置树的最大深度、节点包含的最小样本数等。后剪枝则是在决策树构建完成后,通过删除部分子树或叶子节点来降低过拟合程度。常见的后剪枝方法有错误率降低剪枝、悲观剪枝等。
三、案例实现与代码
下面将通过一个具体的分类案例来演示决策树算法的实现过程,并附上详细的Python代码。Python是一种常用的机器学习编程语言,它拥有丰富的库和工具包,可以方便地实现各种机器学习算法。
1. 案例描述
假设我们有一个数据集,包含四个特征(年龄、学历、婚姻状况、收入)和一个目标变量(是否购买保险)。我们的任务是构建一个决策树模型,用于预测给定特征值的个体是否会购买保险。
2. Python代码实现
首先需要导入必要的库和模块:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
然后加载数据集并进行预处理:
# 加载数据集(这里假设数据集已经保存为CSV文件)
data = pd.read_csv('insurance.csv')
# 查看数据集的前几行
print(data.head())
# 分离特征和目标变量
X = data[['age', 'education', 'marital_status', 'income']]
y = data['buys_insurance']
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
接下来将使用DecisionTreeClassifier类来训练决策树模型,并对测试集进行预测和评估:
# 初始化决策树分类器
clf = DecisionTreeClassifier(random_state=42)
# 训练模型
clf.fit(X_train, y_train)
# 对测试集进行预测
y_pred = clf.predict(X_test)
# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
如果数据集中的特征不是数值型的,而是分类型的(例如“学历”可能是“高中”、“本科”、“硕士”等),则可能需要先进行编码。在scikit-learn中,可以使用LabelEncoder或OneHotEncoder进行编码。但由于DecisionTreeClassifier能够直接处理分类特征(作为类别标签处理),所以在本例中我们假设特征已经是数值型或可以直接使用的。
另外,还可以使用export_graphviz或plot_tree函数来可视化决策树:
from sklearn.tree import export_graphviz
import graphviz
# 可视化决策树(需要安装graphviz库和python-graphviz包)
dot_data = export_graphviz(clf, out_file=None,
feature_names=X_train.columns,
class_names=['No', 'Yes'],
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph.render("insurance_decision_tree")
# 或者使用matplotlib进行可视化(更简单的方法)
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 7))
plot_tree(clf,
feature_names=X_train.columns,
class_names=['No', 'Yes'],
filled=True,
rounded=True,
ax=ax)
plt.show()
在上面的代码中,首先使用export_graphviz函数将决策树导出为Graphviz的DOT格式数据。然后使用graphviz.Source类将DOT数据渲染为图形文件(如PNG或PDF)。最后使用plot_tree函数和matplotlib库直接在Python环境中绘制决策树的可视化图形。
四、总结
本文详细介绍了决策树算法的原理,包括决策树的基本概念、特征选择准则、决策树的构建过程以及剪枝方法。然后,通过一个具体的分类案例和详细的Python代码实现,展示了如何使用scikit-learn库中的DecisionTreeClassifier类来训练决策树模型,并对模型进行预测和评估。最后,我们还介绍了如何使用Graphviz和matplotlib库来可视化决策树。希望本文能够帮助读者更好地理解和应用决策树算法。