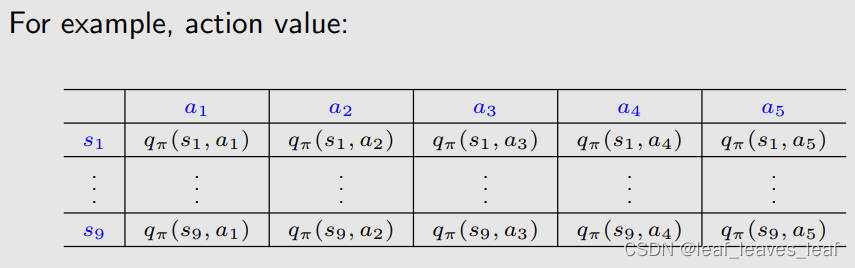
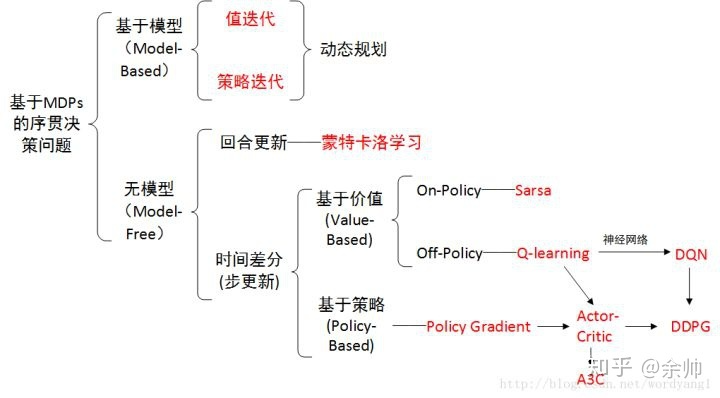
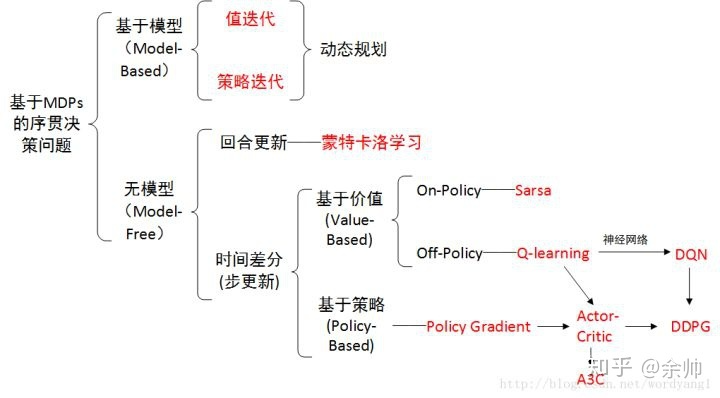
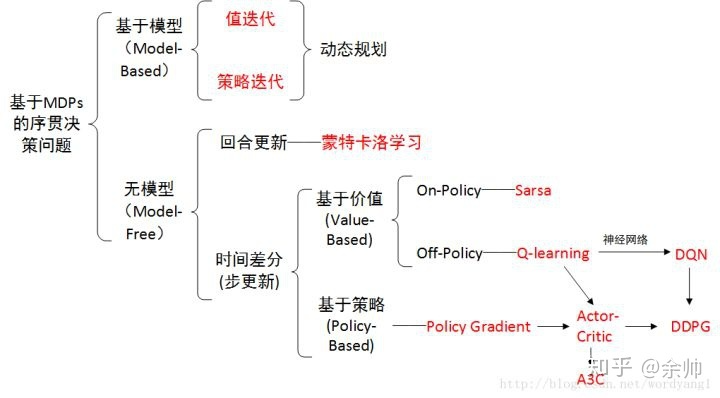
PPT 截取有用信息。 课程网站做习题。总体 MOOC 过一遍
- 1、视频 + 学堂在线 习题
- 2、相应章节 过电子书 [2023.8 版本] 复习
- 3、总体 MOOC 过一遍
学堂在线 课程页面链接
中国大学MOOC 课程页面链接
B 站 视频链接
PPT和书籍下载网址: 【github链接】
onedrive链接:
【书】
【课程PPT】
这种颜色表示 是 查看 PDF 电子书 后补充的笔记
如何学习强化学习?
1、原理 [算法背后的原理] 【本课程】
2、实践和编程
为何要了解算法背后的原理?
- 了解算法的原理是什么?它在做什么样的事情?有什么优势?有什么劣势?创新可以从哪些方面入手?
给目标分配合适的时间
不存在 速成 !!! ——> 充裕的时间,心态平和,稳扎稳打。
数学性强,系统性强。
预计 40 小时 ——> 可阅读论文
目标:不仅能知道 算法的过程,还能理解为什么要设计这个算法,为什么它能有效地工作。
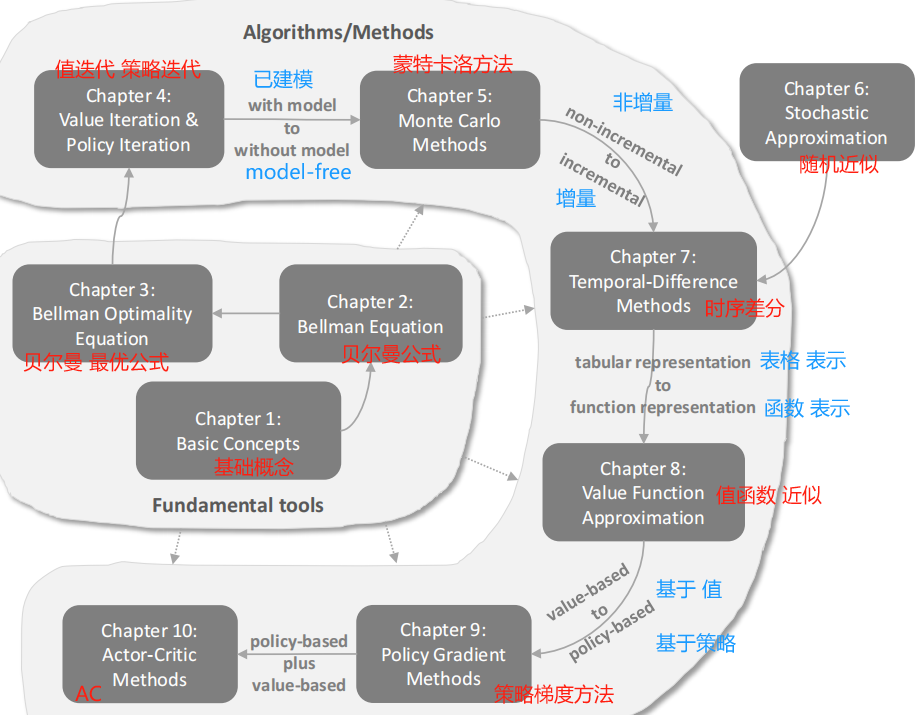
第 1 章 基本概念
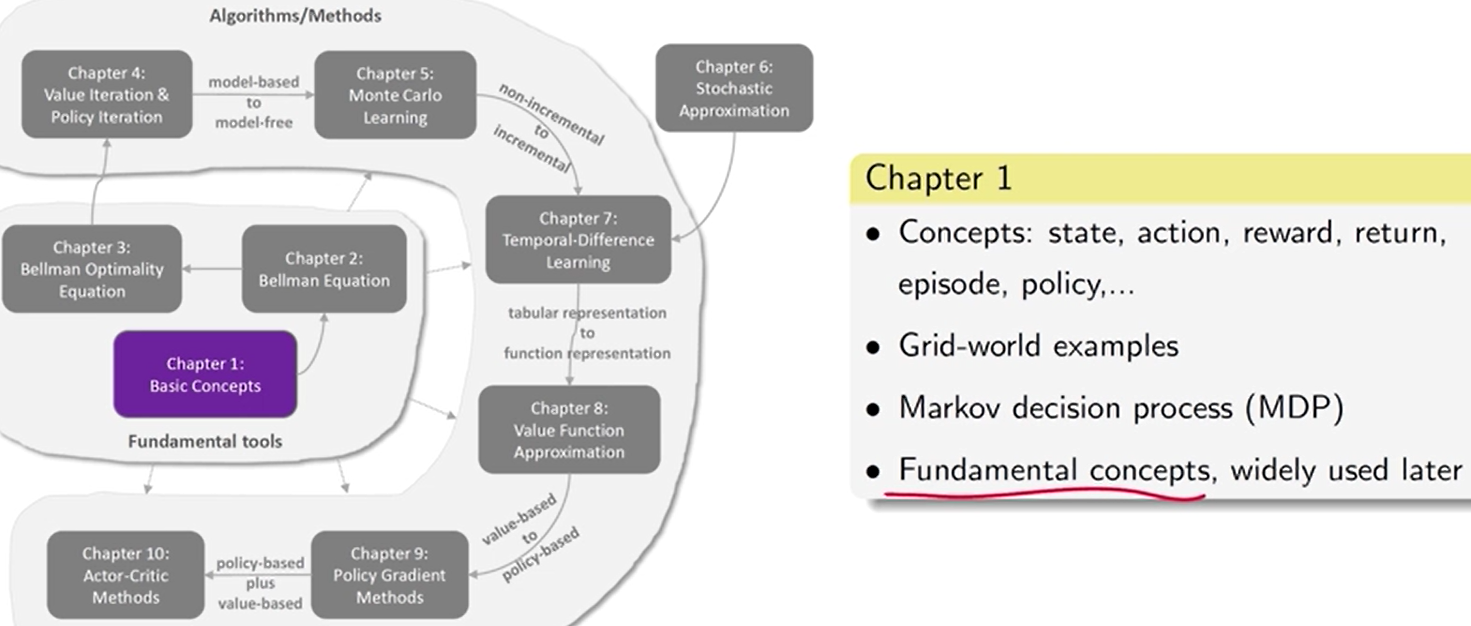
第 2 章 状态值 和 贝尔曼公式
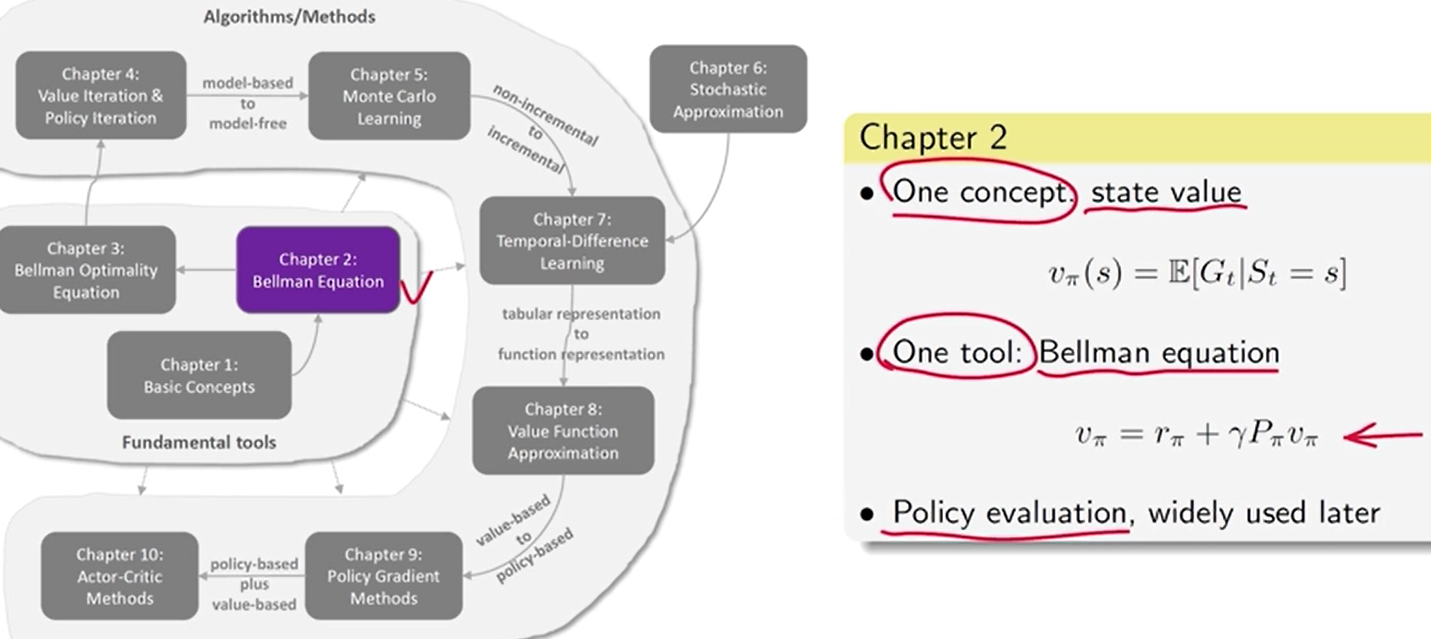
状态值: 用于评价一个策略的好坏。
贝尔曼公式:描述了 所有状态 和 状态值 之间的关系。
策略评价:求解贝尔曼公式进而得到一个策略所对应的状态值
——————
状态值: agent 在遵循给定策略的情况下从某个状态出发时所能获得的预期收益。状态值越大,对应的策略越好。
- 状态值可以用来评估策略是好还是坏。
Bellman 方程描述了所有状态值之间的关系。
通过求解 Bellman 方程,可以得到状态值。这样的过程被称为策略评估。
——————
第 3 章 最优策略 [ 贝尔曼最优公式 ]
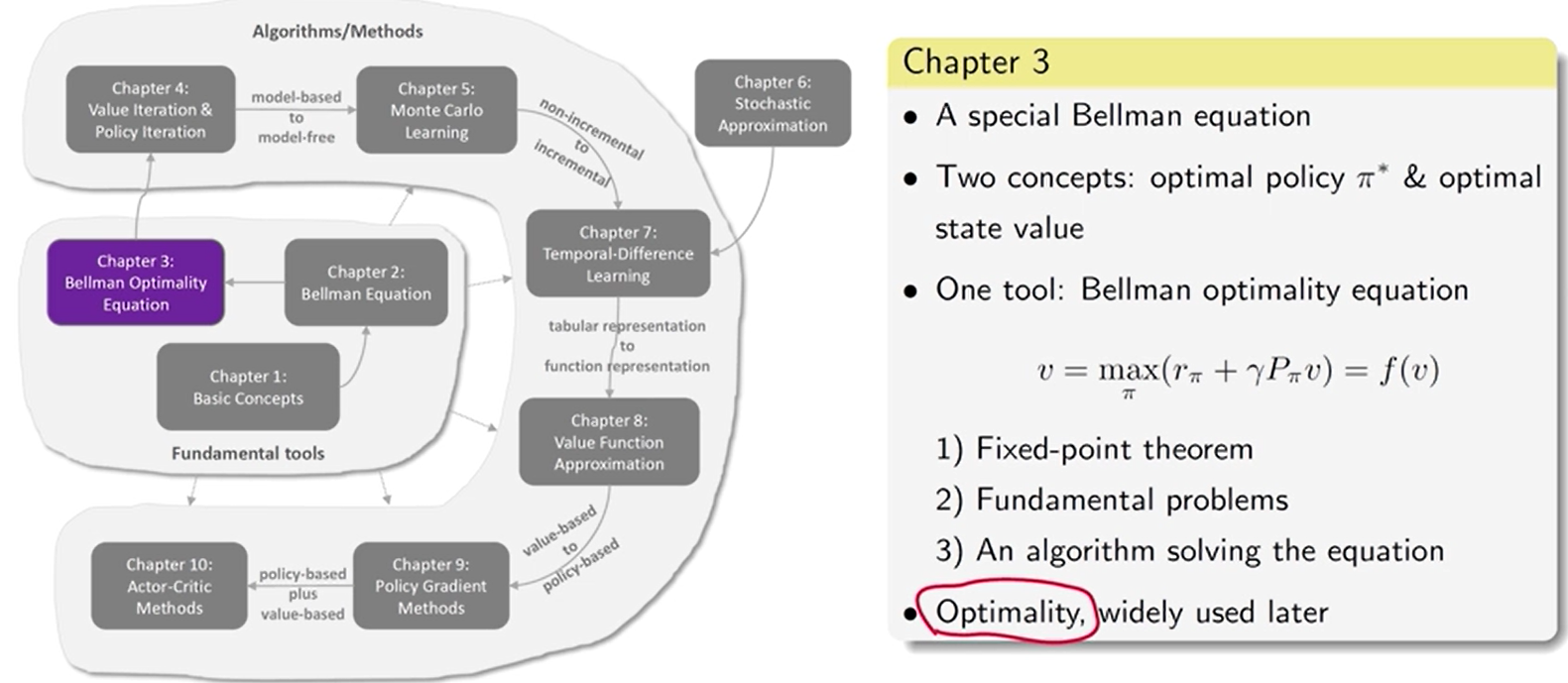
强化学习的终极目标: 求解最优策略
最优策略:能获得最大的状态值
第 4 章 值迭代 和 策略迭代
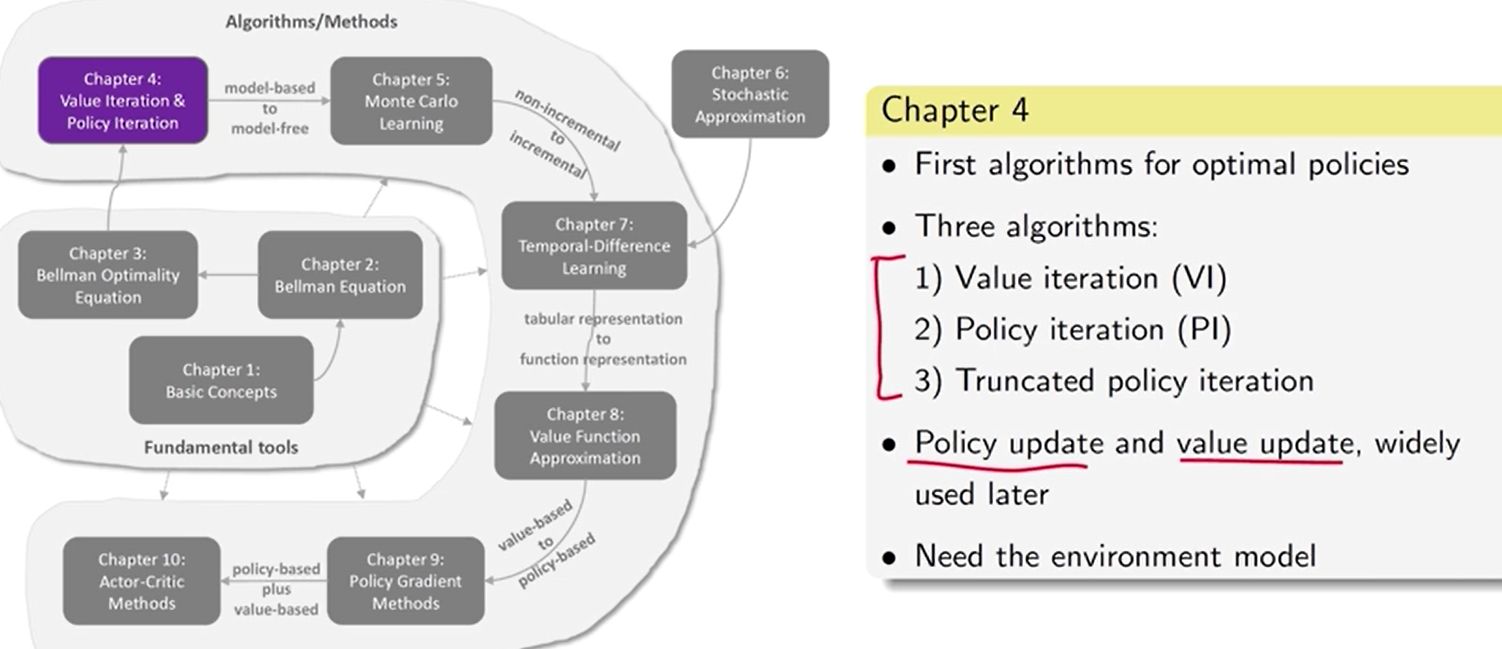
值迭代、策略迭代、截断策略迭代
- 前两个是第三个的特例
贝尔曼最优公式 值迭代
有一个不太好的策略——> 估计策略的值 【策略评价】,根据值改进策略——> 估计 新的策略 的值 , 改进策略——>…
动态规划 需要模型
第 5 章 model-free 的强化学习 算法
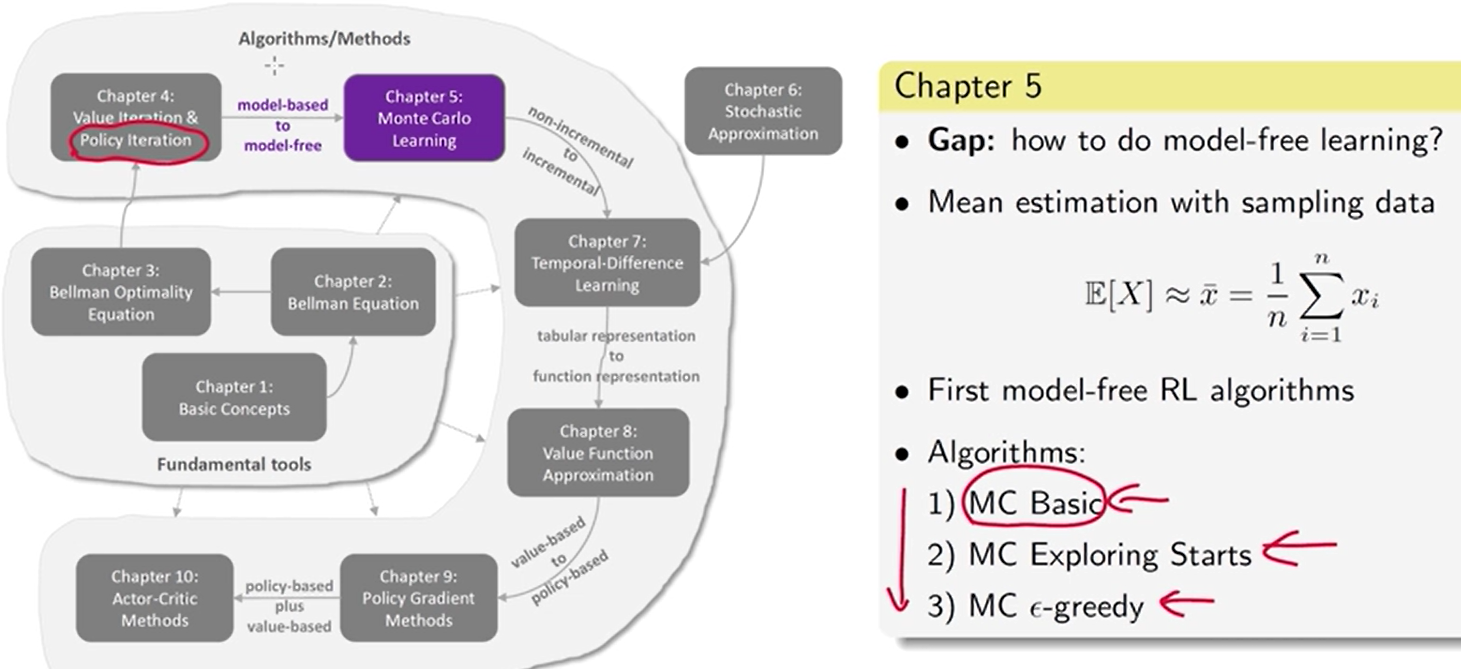
学习 随机变量 的期望值
数据 or 模型
强化学习中的“数据”是 指智能体与环境交互时产生的经验样本。
MC Basic: 策略迭代 中 依赖模型的部分 去掉,替换成依赖数据的
- 实际不可用,效率很低
——————
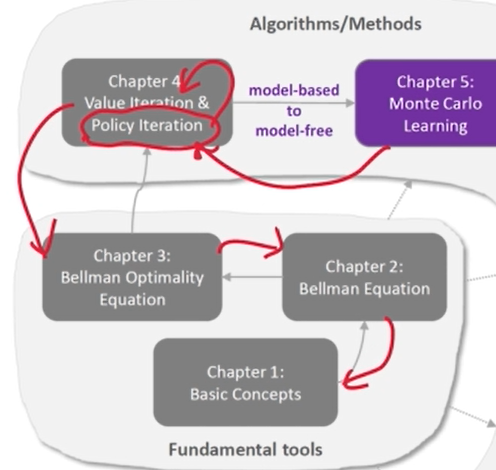
要研究 MC 算法 (第 5 章),首先要了解 策略迭代算法(第 4 章)。要研究策略迭代算法,首先要了解 值迭代 算法(第 4 章)。要了解值迭代算法,首先要了解 Bellman 最优性方程(第 3 章)。要了解 Bellman 最优性方程,首先要了解 Bellman 方程(第 2 章)。因此,强烈建议逐一学习。否则,可能难以理解后面各章的内容。
Bellman 方程(第 2 章) ——> Bellman 最优性方程(第 3 章) ——> 值迭代 算法(第 4 章) ——> MC 算法 (第 5 章)
————————
第 6 章 随机逼近 理论
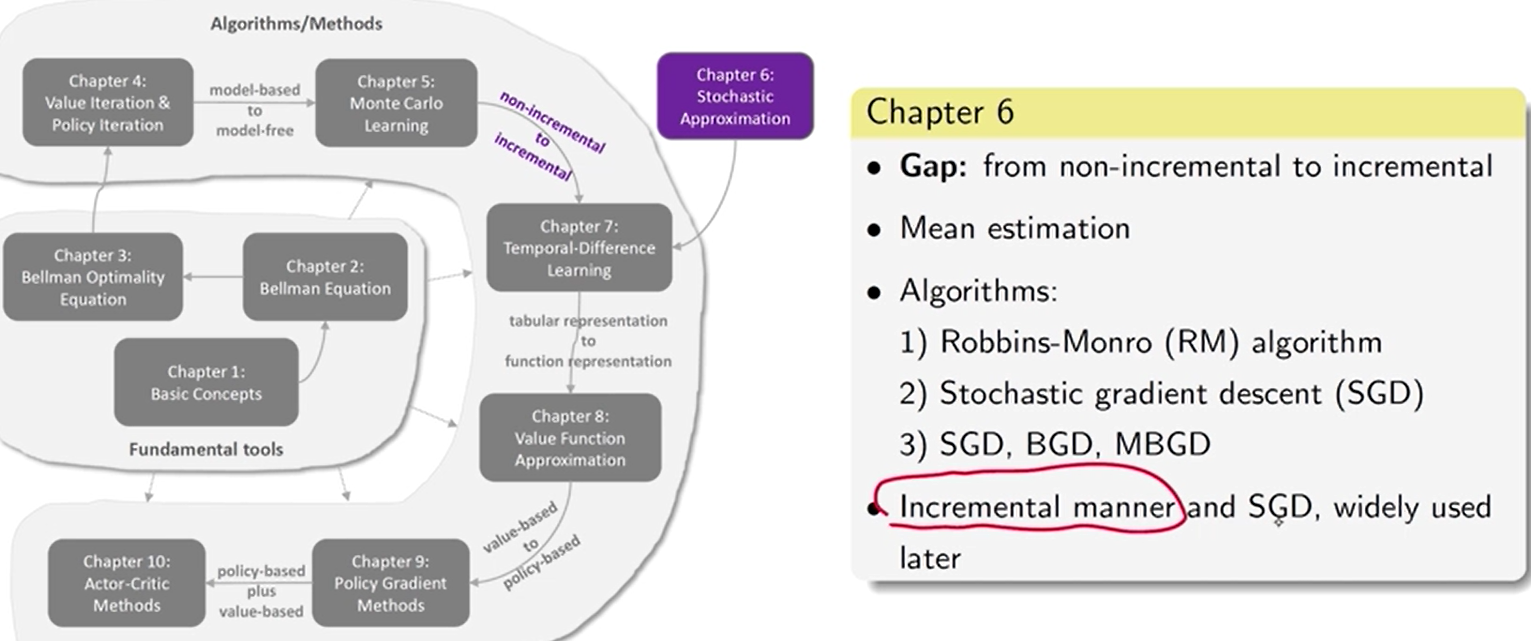
随机逼近是指解决 寻根 或 优化问题 的一类广泛的随机迭代算法。经典的 Robbins-Monro 算法和 随机梯度下降 算法 是特殊的 随机逼近 算法。
第 7 章 时序差分方法 【增量】
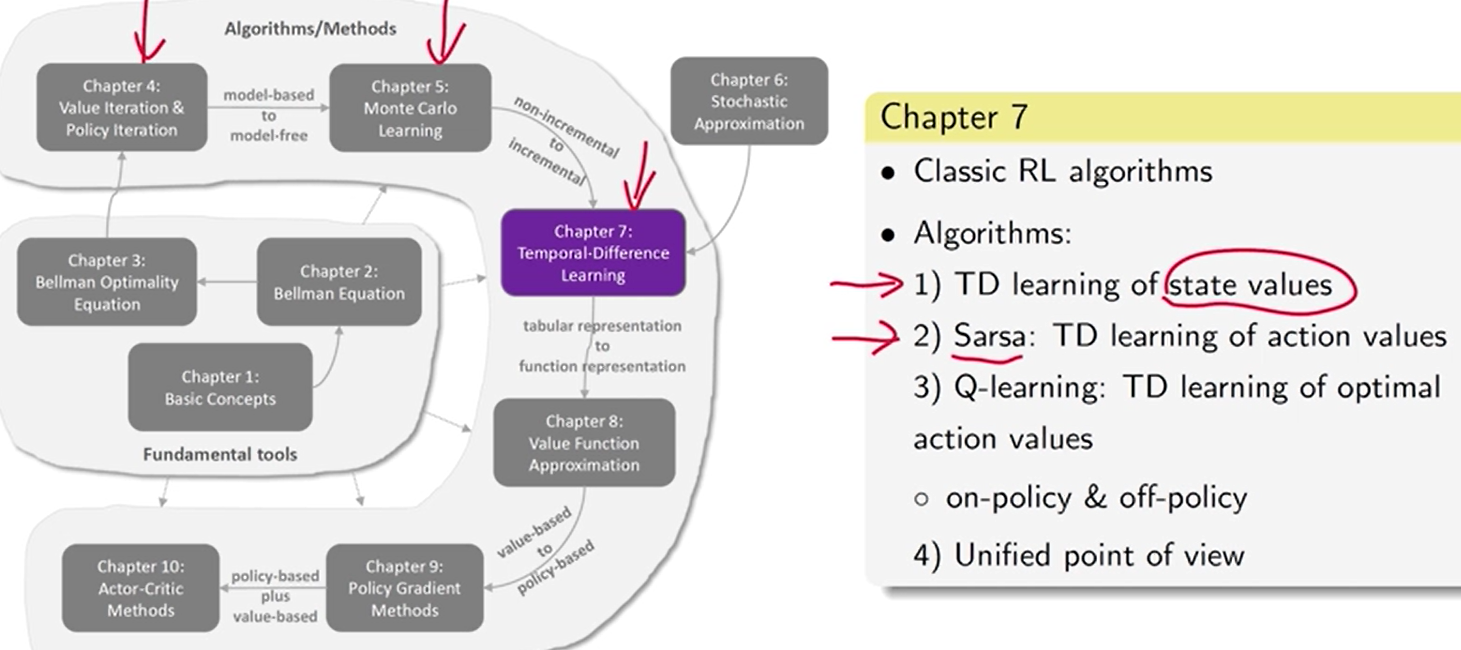
学习 状态值:用模型来计算(第 4 章)、用蒙特卡洛方法学习(第 5 章),用 TD 方法学习(第 7 章)。
Q-learning: 离线 直接学习最优动作值
两种策略: behavior policy, 生成经验数据的。target policy, 不断改进目标策略
off-policy: behavior policy 和 target policy 可以不同。
- 可用 之前别的策略所生成的数据。
on-policy: behavior policy 和 target policy 相同。
- 每次接收到 经验样本时 更新值估计。
TD 算法:求解 Bellman 或 Bellman最优性方程 的随机逼近算法。
model-free、增量。
第 8 章 值函数 近似 [神经网络]
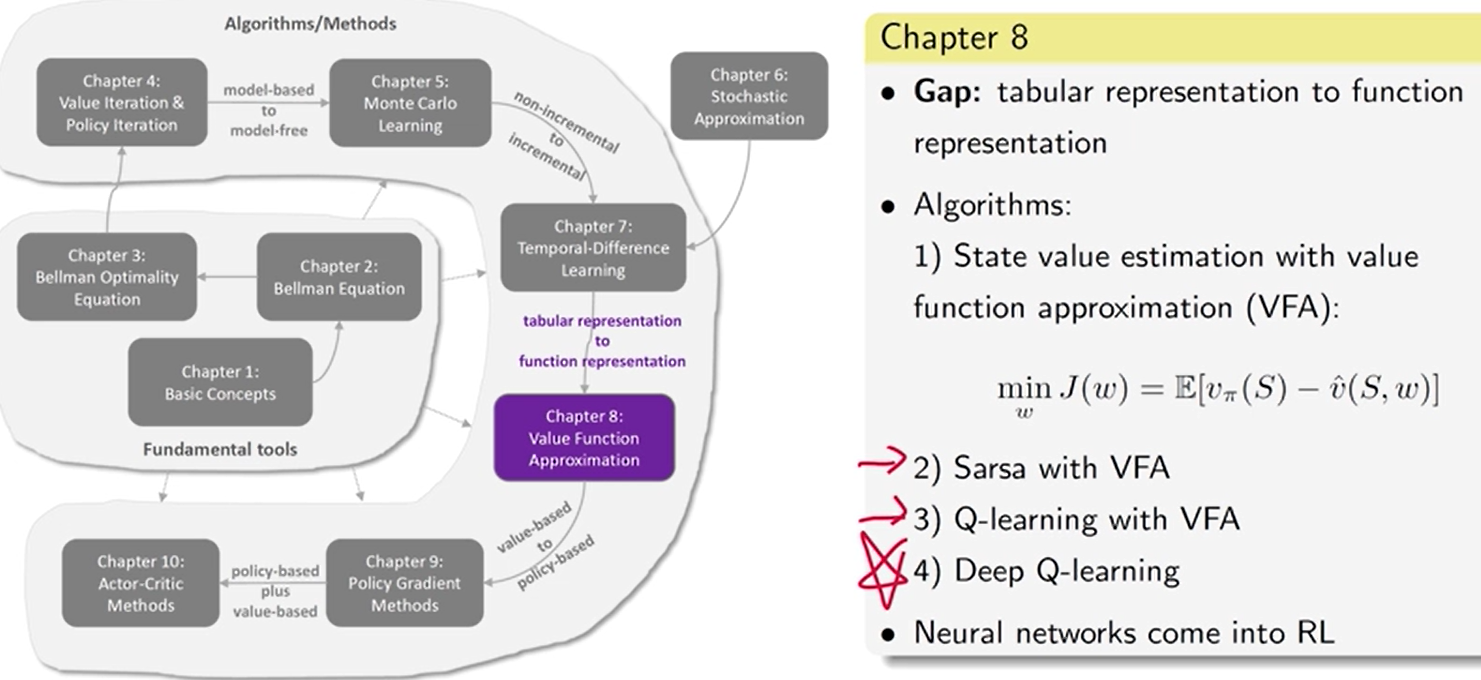
表格 或 向量 形式的状态值
状态非常多 或 状态连续。 表格效率低下——> 函数 (神经网络)
状态值 估计步骤:
1、明确 目标函数 定义最优策略
2、求 目标函数 梯度
3、用 梯度上升 或 下降 对 目标函数 进行优化
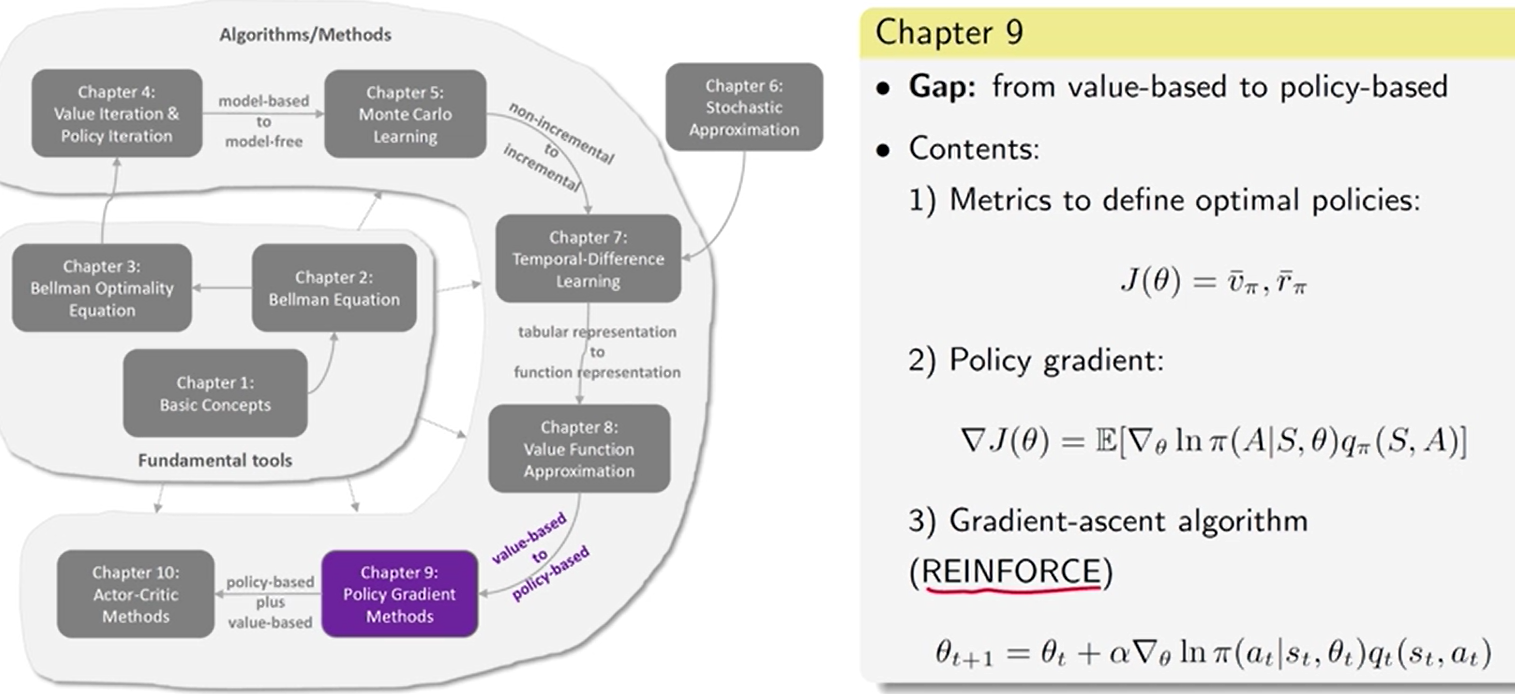
9 - 10 章 policy-based 方法
value-based VS policy-based
value-based:目标函数 J ( w ) J(w) J(w),w 是值函数的参数,更新值函数的参数使得这个值函数能够很好地近似或者估计出来 一个策略 所对应的值, 在此基础上再更新策略,得到新的策略,然后再估计它的值。不断迭代找到最优的策略。
policy-based:目标函数 J ( θ ) J(\theta) J(θ), θ \theta θ 是 策略的参数, 直接优化 θ \theta θ , 直接改变策略,慢慢找到最优的策略
三步走:
1、找 目标函数
2、目标函数 梯度
3、用梯度上升 或 下降 优化 目标函数
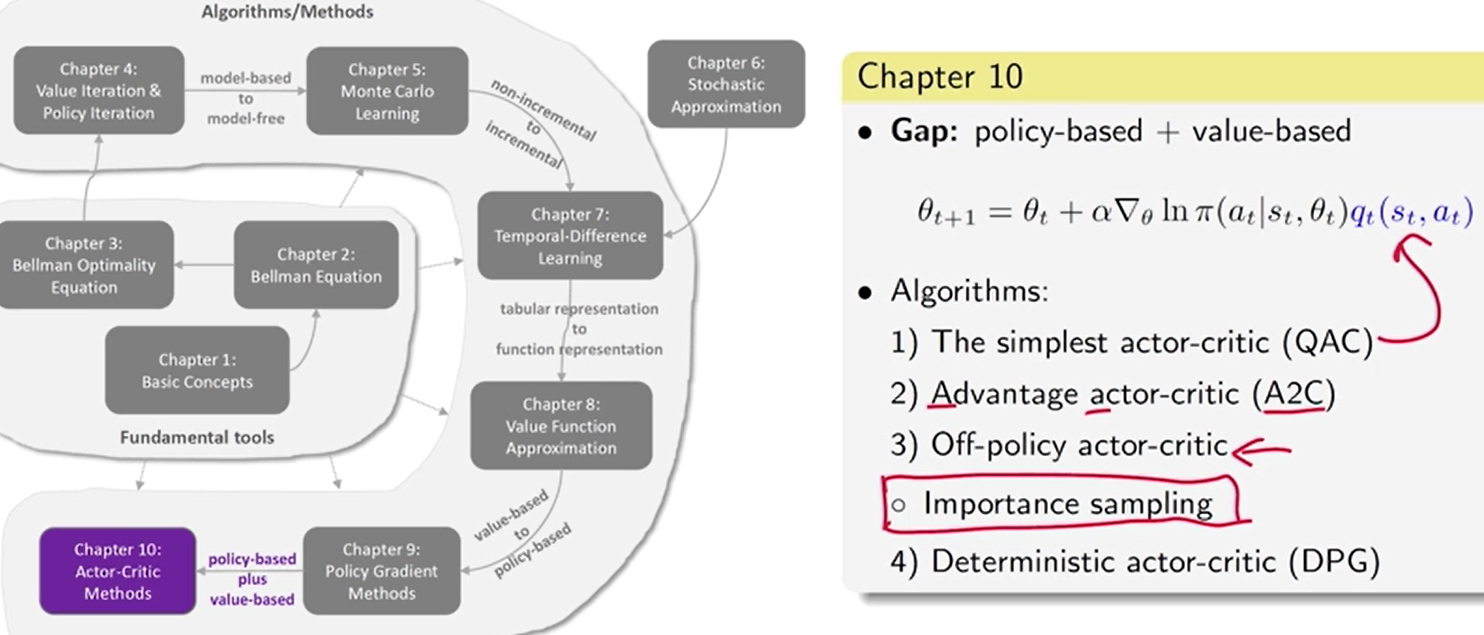
策略 和 值 交叉迭代
求出值 ——> 更新策略 ——> 求值 ——> 更新策略…