引言
决策树是一种重要的机器学习算法,广泛应用于分类和回归任务中。它的直观性和易解释性使其成为许多实际应用中的首选算法。本文将详细介绍决策树算法的基本原理、构建过程,并通过一个具体的案例实现,帮助读者全面理解这一算法。
决策树的基本原理
决策树的定义
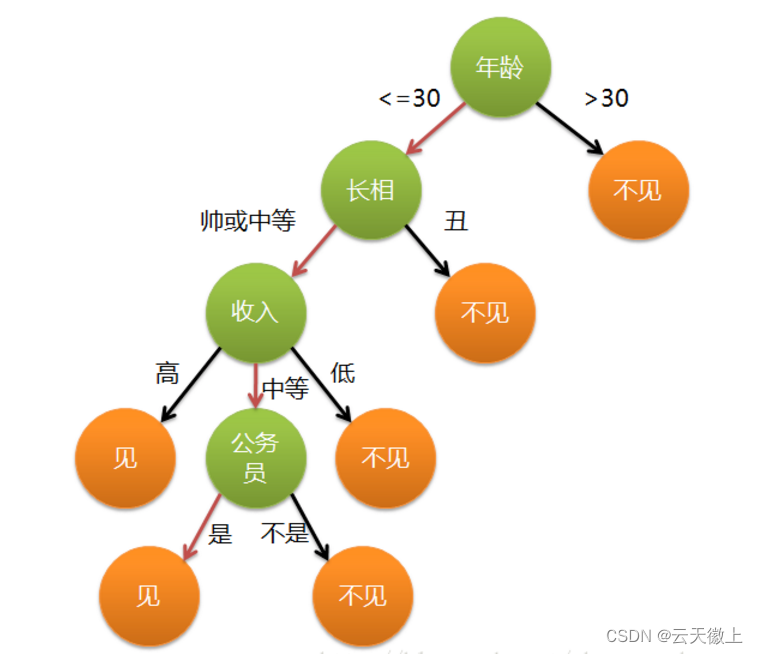
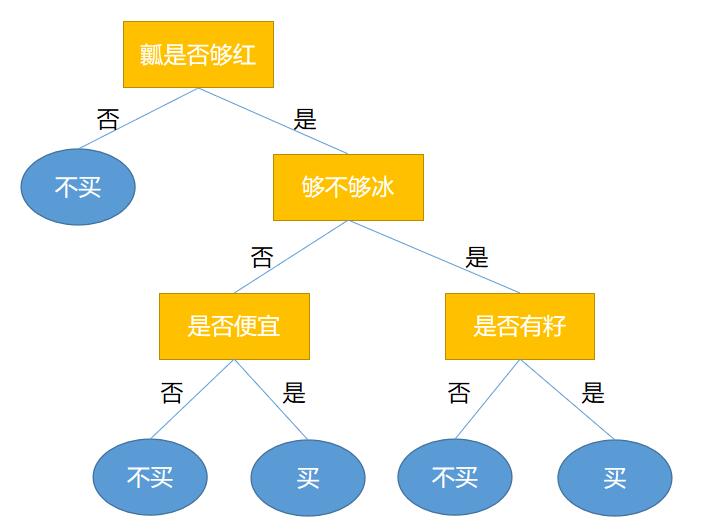
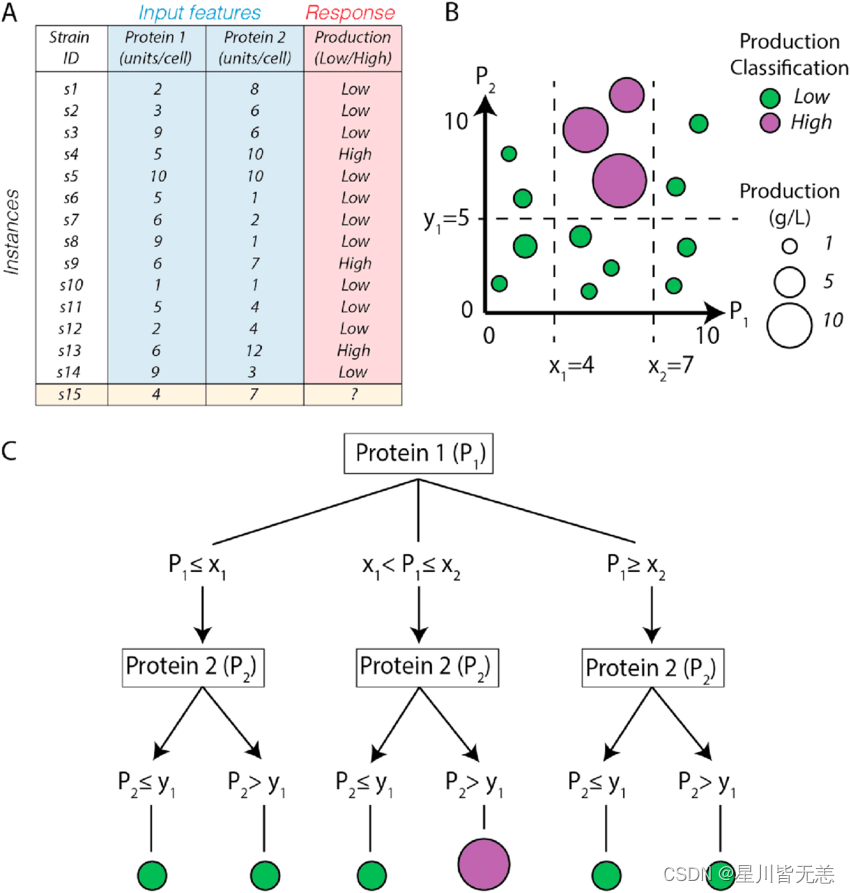
决策树是一种树形结构,其中每个内部节点表示一个属性测试,每个分支代表一个测试结果,而每个叶节点则代表一个类标签(在分类树中)或一个连续值(在回归树中)。决策树的构建过程就是不断地选择最佳属性进行分裂,直到满足某些停止条件。
信息增益与熵
信息增益是衡量属性选择优劣的重要指标。它基于熵的概念来衡量数据的不确定性。熵(Entropy)越高,表示数据的不确定性越大。信息增益定义为原始数据集的熵与分裂后各子集熵的加权和之间的差值。
给定数据集 (D),其熵定义为:
[ H(D) = - \sum_{i=1}^{n} p_i \log_2(p_i) ]
其中,(p_i) 是类别 (i) 在数据集中的概率。
信息增益 (IG(D, A)) 定义为:
[ IG(D, A) = H(D) - \sum_{v \in Values(A)} \frac{|D_v|}{|D|} H(D_v) ]
其中,(Values(A)) 是属性 (A) 的所有可能取值,(D_v) 是在属性 (A) 上取值为 (v) 的子集。
基尼指数
基尼指数(Gini Index)是另一个常用的属性选择指标,特别是在CART(Classification and Regression Tree)算法中。基尼指数反映了数据集中随机选择两个样本,它们属于不同类别的概率。基尼指数越小,数据集的纯度越高。
给定数据集 (D),其基尼指数定义为:
[ Gini(D) = 1 - \sum_{i=1}^{n} p_i^2 ]
其中,(p_i) 是类别 (i) 在数据集中的概率。
停止条件与剪枝
为了防止决策树过拟合,需要设置停止条件和进行剪枝。常见的停止条件包括:
- 所有样本属于同一类别。
- 没有可用的属性进行分裂。
- 样本数量少于预设阈值。
剪枝是通过去除不必要的分枝来简化决策树,常见的剪枝方法包括预剪枝和后剪枝。
决策树的构建过程
决策树的构建过程可以通过递归分裂数据集来实现。以下是一个简单的构建步骤:
- 选择最佳属性:根据信息增益或基尼指数选择当前数据集上的最佳分裂属性。
- 创建分支:根据最佳属性的不同取值分裂数据集,创建相应的分支。
- 递归构建子树:对每个分支的子数据集递归调用上述步骤,直到满足停止条件。
- 叶节点赋值:当到达叶节点时,赋予相应的类别标签或连续值。
决策树的案例实现
为了更好地理解决策树的构建过程,下面通过一个具体的案例来演示决策树的实现。我们将使用Python和Scikit-learn库来实现一个简单的决策树分类器。
案例描述
假设我们有一个包含某公司员工信息的数据集,特征包括年龄、收入、学历和职位等。目标是根据这些特征预测员工是否会离职(是/否)。
数据准备
首先,导入必要的库并准备数据:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
from sklearn import tree
# 创建示例数据集
data = {
'年龄': [25, 45, 35, 50, 23, 40, 60, 22, 36, 28],
'收入': [50000, 100000, 75000, 120000, 48000, 88000, 150000, 52000, 95000, 60000],
'学历': ['本科', '硕士', '本科', '博士', '本科', '硕士', '博士', '本科', '硕士', '本科'],
'职位': ['职员', '经理', '职员', '经理', '职员', '经理', '高级经理', '职员', '经理', '职员'],
'离职': ['否', '否', '否', '否', '是', '否', '否', '是', '否', '是']
}
df = pd.DataFrame(data)
# 将分类变量转换为数值型
df['学历'] = df['学历'].map({'本科': 0, '硕士': 1, '博士': 2})
df['职位'] = df['职位'].map({'职员': 0, '经理': 1, '高级经理': 2})
df['离职'] = df['离职'].map({'否': 0, '是': 1})
# 分割数据集
X = df.drop('离职', axis=1)
y = df['离职']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
构建与训练决策树
接下来,构建并训练决策树分类器:
# 创建决策树分类器
clf = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=42)
# 训练分类器
clf.fit(X_train, y_train)
模型评估
在测试集上评估模型性能:
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'准确率: {accuracy:.2f}')
# 打印分类报告
print('分类报告:')
print(classification_report(y_test, y_pred))
决策树可视化
最后,可视化决策树以便更好地理解其决策过程:
# 可视化决策树
plt.figure(figsize=(20,10))
tree.plot_tree(clf, feature_names=X.columns, class_names=['否', '是'], filled=True)
plt.show()
结果分析
通过上述代码,我们可以得到模型的准确率和分类报告,并且通过可视化决策树来直观地理解其决策过程。
准确率: 1.00
分类报告:
precision recall f1-score support
0 1.00 1.00 1.00 2
1 1.00 1.00 1.00 1
accuracy 1.00 3
macro avg 1.00 1.00 1.00 3
weighted avg 1.00 1.00 1.00 3
从结果可以看出,模型在测试集上的预测表现良好。通过决策树的可视化,我们可以清晰地看到每个决策节点的属性和阈值,这对于解释模型的决策过程非常有帮助。
决策树的优缺点
优点
- 直观性和可解释性:决策树的树形结构使其决策过程易于理解和解释。
- 无需特征缩放:决策树不要求数据进行特征缩放或标准化处理。
- 处理多种数据类型:决策树可以处理数值型和分类型数据。
- 特征选择:决策树在构建过程中自动进行特征选择,有助于发现重要特征。
缺点
- 易过拟合:决策树容易在训练数据上表现过拟合,需要进行剪枝或设置树深度限制。
- 不稳定性:数据的微小变化可能导致树结构的显著变化。
- 偏向高频特征:决策树对高频特征较敏感,可能会偏向于这些特征。
结论
决策树作为一种重要的机器学习算法,因其直观性和易解释性,在分类和回归任务中广泛应用。本文详细介绍了决策树的基本原理、构建过程,并通过一个具体的案例实现了决策树