Title
题目
Towards a general-purpose foundation model for computational pathology
面向计算病理学的通用基础模型
01
文献速递介绍
组织图像的定量评估对于计算病理学(CPath)任务至关重要,需要从全幻灯片图像(WSIs)中客观表征组织病理学实体。WSIs的高分辨率和形态特征的变异性带来了重大挑战,使得为高性能应用程序大规模标注数据变得复杂。为了解决这一挑战,当前的努力提出了使用预训练的图像编码器,通过从自然图像数据集进行迁移学习或在公开可用的组织病理学数据集上进行自监督学习,但尚未在规模上广泛开发和评估不同组织类型。我们介绍了UNI,这是一个通用的自监督病理模型,使用来自超过100,000个诊断性H&E染色WSIs(>77 TB的数据)的超过1亿张图像进行预训练,涵盖了20种主要组织类型。该模型在34个具有不同诊断难度的代表性CPath任务上进行了评估。除了胜过以前的最先进模型外,我们还展示了CPath中的新建模能力,如与分辨率无关的组织分类、使用少样本类原型进行幻灯片分类,以及在OncoTree分类系统中对多达108种癌症类型进行疾病亚型泛化分类。UNI在CPath中推动了规模上的无监督表示学习,无论是在预训练数据还是下游评估方面,都可以实现数据高效的人工智能模型,能够推广和转移至各种诊断性挑战任务和临床工作流程中的解剖病理学。
Results
结果
Pretraining scaling laws in CPath
A pivotal characteristic of foundation models lies in their capability to deliver improved downstream performance on various tasks when trained on larger datasets. Although datasets such as CAMELYON16 (Cancer Metastases in Lymph Nodes Challenge 2016 (ref. 78) and theTCGA nonsmall cell lung carcinoma subset (TCGA-NSCLC)79 are commonly used to benchmark pretrained encoders using weakly supervised multiple instance learning (MIL) algorithms15,37,40,80, they source tissue slides only from a single organ and are often used for predicting binary disease states81, which is not reflective of the broader array of disease entities seen in real-world anatomic pathology practice.
CPath中的预训练规模定律
基础模型的一个关键特征在于它们能够在训练在更大数据集上时提供改进的下游性能,用于各种任务。虽然诸如CAMELYON16(2016年淋巴结转移癌症挑战赛(ref. 78)和TCGA非小细胞肺癌子集(TCGA-NSCLC)79等数据集通常用于使用弱监督多实例学习(MIL)算法15,37,40,80对预训练编码器进行基准测试,但它们仅从单一器官中获取组织幻灯片,通常用于预测二元疾病状态81,这并不能反映出真实世界解剖病理学实践中看到的更广泛的疾病实体。
Figure
图
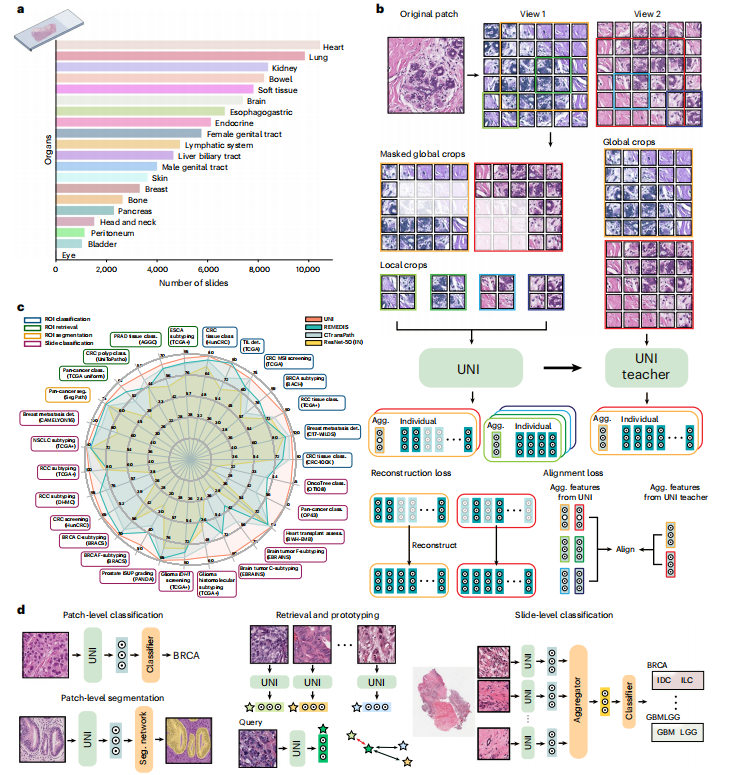
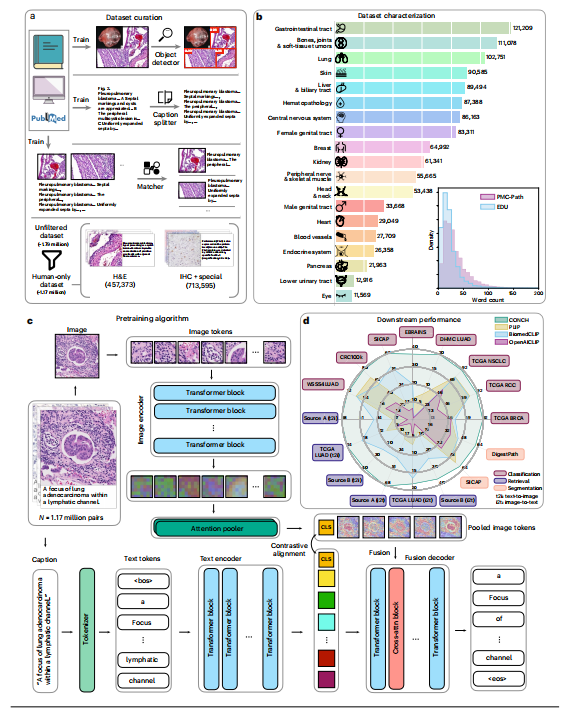
ig. 1 | Overview of UNI. UNI is a general-purpose, self-supervised vision encoder for anatomic pathology based on the vision transformer architecture, achieving state-of-the-art performance across 34 clinical tasks in anatomic pathology. *a, Slide distribution of Mass-100K, a large-scale and diverse pretraining dataset of 100 million tissue patches sampled from over 100,000 diagnostic WSIs across 20 major organ types. b, UNI is pretrained on Mass-100K using the DINOv2 self-supervised training algorithm22, which consists of a mask image modelingobjective118 and a self-distillation objective25. c, UNI generally outperforms other pretrained encoders across 34 clinical tasks in anatomical pathology (average performance of the 8 SegPath tasks reported). d**, The evaluation tasks consist of ROI-level classification, segmentation, retrieval and prototyping, and slide-level classification tasks. Further details are given in Methods. class., classification; seg., segmentation; det., detection; assess., assessment.
图1 | UNI概览。UNI是一种通用的自监督视觉编码器,基于视觉Transformer架构,实现了在解剖病理学中34项临床任务中的最新性能。
a,Mass-100K的幻灯片分布,这是一个大规模且多样化的预训练数据集,由来自20种主要器官类型的超过100,000个诊断WSIs中抽样的1亿个组织块组成。b,UNI使用DINOv2自监督训练算法22在Mass-100K上进行预训练,该算法包括一个掩码图像建模目标118和一个自蒸馏目标25。
c,UNI在解剖病理学的34项临床任务中通常优于其他预训练编码器(报告了8项SegPath任务的平均性能)。
d,评估任务包括ROI级别的分类、分割、检索和原型制作,以及幻灯片级别的分类任务。方法中提供了更多详细信息。
class.,分类;seg.,分割;det.,检测;assess.,评估

Fig. 2 | Slide-level tasks for OT-43 and OT-108, and slide-level task performance.a, Organ and OncoTree code distribution for the slide-level OT-43 and OT-108 classification tasks. All comparisons with UNI are evaluated on 43-way cancer type classification and 108-way OncoTree code classification tasks with OT-43 and OT-108, respectively. Further details regarding data distribution are provided in Supplementary Table 4. Gen., genitalia; GI, gastrointestinal. b,d, Comparison of macro-averaged AUROC of UNI and other pretrained encoders for OT-43 (b) and OT-108 (d) (n = 1,620 slides each). c,e, Top-1 accuracy of UNI across different pretraining data scales (Mass-1K, Mass-22K, Mass-100K) for OT-43 (c) and OT-108 (e) (n = 1,620 slides each). f, Supervised performance of UNI and its comparisons across 15 weakly supervised slide-level classification tasks. Dashed lines represent the average performance of each model across all tasks. All data are given as balanced accuracy, except for ISUP grading, which is given as quadratic weighted Cohen’s κ. Error bars represent 95% confidence intervals and the centers correspond to computed values of each metric as specified above. Detailed results for all tasks are provided in Supplementary Tables 12–35. Ext., external test set. g–j, Few-shot slide-level performance with K ∈ {1, 2, 4, 8, 16, 32}
slides per class reported for four tasks. g, RCC subtyping (train, TCGA; test, CPTAC-DHMC; n = 872 slides). h, BRCA fine-grained subtyping (BRACS, n = 87 slides). i, Brain tumor coarse-grained subtyping (EBRAINS, n = 573 slides). j, ISUP grading (PANDA, n = 954 slides). Boxes indicate quartile values of model performance (n = 5 runs), and whiskers extend to data points within 1.5-fold the interquartile range. Few-shot results for all tasks are given in Extended Data Fig. 1.
图2 | OT-43和OT-108的幻灯片级任务及其幻灯片级任务性能。
a,幻灯片级OT-43和OT-108分类任务的器官和OncoTree代码分布。与UNI的所有比较均在OT-43和OT-108的43种癌症类型分类和108种OncoTree代码分类任务上进行评估。有关数据分布的更多详细信息,请参见补充表4。Gen.,生殖器;GI,胃肠道。b、d,UNI和其他预训练编码器的OT-43(b)和OT-108(d)的宏平均AUROC比较(每个均为n=1,620张幻灯片)。
c、e,UNI在不同预训练数据规模(Mass-1K、Mass-22K、Mass-100K)下的OT-43(c)和OT-108(e)的Top-1准确度(每个n=1,620张幻灯片)。
f,UNI及其在15个弱监督幻灯片级分类任务中的对比的监督性能。虚线表示每个模型在所有任务中的平均性能。所有数据均以平衡准确度给出,除了ISUP分级,其以二次加权Cohen's κ给出。误差线表示95%置信区间,中心值对应于上述每个指标的计算值。所有任务的详细结果请参见补充表12–35。Ext.,外部测试集。g–j,针对四个任务报告的每个类别为K ∈ {1, 2, 4, 8, 16, 32}的少样本幻灯片级性能。g,RCC亚型(训练,TCGA;测试,CPTAC-DHMC;n=872张幻灯片)。h,BRCA细粒度亚型(BRACS,n=87张幻灯片)。i,脑肿瘤粗粒度亚型(EBRAINS,n=573张幻灯片)。j,ISUP分级(PANDA,n=954张幻灯片)。方框表示模型性能的四分位数值(n=5次运行),须延伸至距离四分位范围的1.5倍内的数据点。所有任务的少样本结果请见扩展数据图1。

Fig. 3 | ROI-level tasks.a, Supervised linear probe performance of UNI and its comparisons across 11 ROI-level classification tasks. All results are givenas balanced accuracy except for PRAD tissue classification, which is given as weighted F1 score. Dashed lines represent the average performance of each model across all tasks. Error bars represent 95% confidence intervals and the centers correspond to computed values of each metric as specified above. Detailed results for all tasks are provided in Supplementary Tables 39–60. b, Examples of UNI on ROI classification for PRAD tissue classification in AGGC. Left: ground-truth ROIlevel labels overlaid on the WSI. Right: predicted patch labels. ROIs are enlarged for better visualization, with further comparisons shown in Extended Data Fig. 2. c, ROI retrieval performance of UNI on PRAD tissue classification (AGGC, n = 345,021 ROIs). We report Recall@K for K∈ {1, 3, 5} and the mean recall, with error bars representing 95% confidence intervals and the centers corresponding to computed values of each metric. d, Supervised KNN probe performance of UNI across various image resolutions (res., in pixels) in BRCA subtyping in BACH (n = 80 ROIs). Retrieval performance for all tasks is provided in Extended Data Fig. 3 and Supplementary Tables 63–68. e, Multi-head self-attention (MHSA) heatmap visualization of UNI across different image resolutions (in pixels) in BACH. Each colored square represents a 16 × 16 pixel patch token encoded by UNI, with heatmap color corresponding to the attention weight of that patch token to the global [CLS] (that is, classification) token of the penultimate layer in UNI. Top and bottom, respectively: visualizations for the invasive- and normal-labeled images, with further visualizations and interpretations provided in Extended Data Figs. 4–6. Scale bars: b, ground truth and prediction, 2 mm; prediction(1) and prediction(2), 200 µm; insets, 30 µm; e, ROI image, 32 µm; 2242 , 64 pixels; 4482 , 128 pixels; 8962 , 256 pixels; 1,3442 , 384 pixels.
图3 | ROI级任务。a,UNI及其在11个ROI级分类任务中的监督线性探测性能对比。所有结果均以平衡准确度给出,除了PRAD组织分类,其以加权F1分数给出。虚线表示每个模型在所有任务中的平均性能。误差线表示95%置信区间,中心值对应于上述每个指标的计算值。所有任务的详细结果请参见补充表39–60。b,UNI在AGGC中PRAD组织分类的ROI分类示例。左:叠加在WSI上的地面真实ROI级别标签。右:预测的块标签。为了更好地可视化,ROI被放大,进一步的比较见扩展数据图2。c,UNI在PRAD组织分类(AGGC,n=345,021 ROIs)中的ROI检索性能。我们报告K∈{1, 3, 5}的Recall@K和平均召回率,误差线表示95%置信区间,中心值对应于上述每个指标的计算值。d,UNI在不同图像分辨率(res.,以像素表示)下的BRCA亚型(在BACH中)的监督KNN探测性能(n=80 ROIs)。所有任务的检索性能请见扩展数据图3和补充表63–68。e,UNI在BACH中不同图像分辨率下的多头自注意力(MHSA)热图可视化(以像素表示)。每个彩色方块表示UNI编码的一个16×16像素块标记,热图颜色对应于该块标记对UNI倒数第二层中的全局[CLS](即分类)标记的注意权重。上部和下部分别是侵袭性和正常标记图像的可视化,更多的可视化和解释请参见扩展数据图4–6。比例尺:b,地面真实和预测,2毫米;预测(1)和预测(2),200微米;插图,30微米;e,ROI图像,32微米;2242,64像素;4482,128像素;8962,256像素;1,3442,384像素。

Fig. 4 | Few-shot ROI- and slide-level prototyping. a, Prototypical few-shot ROI classification via SimpleShot. A class prototype is constructed by averaging the extracted features from ROIs of the same class. For a test ROI, SimpleShot assigns the class of the most similar class prototype (smallest Euclidean distance) as the predicted ROI label. b, Prototypical few-shot slide classification via MISimpleShot. Using a pre-computed set of ROI-level class prototypes (sharing the same class labels as the slide), MI-SimpleShot predicts the slide label using the class prototype with the highest average similarity of top-K patches queried from the WSI. The similarity heatmap visualizes the similarity between the groundtruth class prototype and each patch in the WSI. c–e, Few-shot ROI classification performance via SimpleShot on three tasks, with boxes indicating quartiles of model performance (n = 1,000 runs) and whiskers extending to data points within 1.5-fold the interquartile range. c, Pan-cancer tissue classification (TCGA, n* = 55,360 ROIs). d, CRC polyp classification (UniToPatho, n = 2,399 ROIs). *e, PRAD tissue classification (AGGC, n = 345,021 ROIs). Few-shot ROI performances for all tasks are provided in Extended Data Fig. 8. f,g, Few-shot slide classification performance and similarity heatmaps via MI-SimpleShot for NSCLC subtyping (train, TCGA; test, CPTAC; n = 1,091 slides) (f) and RCC subtyping (train, TCGA; test, CPTAC-DHMC; n = 872 slides) (g). In both tasks, using pre-extracted features from UNI, we compare MI-SimpleShot in the same few-shot settings as ABMIL (boxes indicate quartile values of model performance with n = 5 runs and whiskers extend to data points within 1.5-fold the interquartile range), and visualize similarity heatmaps and the top-5 similar patches (indicated in red bounding boxes) for a LUSC (f) and CCRCC (g**) slide. Scale bars: WSI, 2 mm; top-5 retrieved patches, 56 µm. Further details, comparisons and visualizations are provided in Methods and Extended Data Figs. 8–10.
图4 | 少样本ROI-和幻灯片级原型制作。a,通过SimpleShot的原型式少样本ROI分类。通过对相同类别的ROI提取特征并求平均值来构建类原型。对于测试ROI,SimpleShot将最相似的类原型(欧氏距离最小)的类别作为预测的ROI标签。b,通过MI-SimpleShot的原型式少样本幻灯片分类。使用预先计算的ROI级类原型集(与幻灯片具有相同的类别标签),MI-SimpleShot使用从WSI查询的前K个补丁的平均相似度最高的类原型来预测幻灯片标签。相似度热图可视化了地面真实类原型与WSI中每个补丁之间的相似度。
c–e,通过SimpleShot在三个任务中的少样本ROI分类性能,方框表示模型性能的四分位数值(n=1,000次运行),须延伸至距离四分位范围的1.5倍内的数据点。c,泛癌组织分类(TCGA,n=55,360 ROIs)。d,CRC息肉分类(UniToPatho,n=2,399 ROIs)。e,PRAD组织分类(AGGC,n=345,021 ROIs)。所有任务的少样本ROI性能请见扩展数据图8。f、g,通过MI-SimpleShot的少样本幻灯片分类性能和相似度热图,用于NSCLC亚型(训练,TCGA;测试,CPTAC;n=1,091张幻灯片)(f)和RCC亚型(训练,TCGA;测试,CPTAC-DHMC;n=872张幻灯片)(g)。在这两个任务中,使用UNI的预先提取特征,我们将MI-SimpleShot与ABMIL在相同的少样本设置下进行比较(方框表示模型性能的四分位数值,n=5次运行,须延伸至距离四分位范围的1.5倍内的数据点),并可视化相似度热图和前5个相似补丁(用红色边框表示)的LUSC (f) 和CCRCC (g) 幻灯片。比例尺:WSI,2毫米;前5个检索的补丁,56微米。方法和扩展数据图8–10提供了更多详细信息、比较和可视化。