一、串
1、串的定义
串是一个线性表,但其节点中的内容只能为字符,所以也称为字符串。
字符串中可以有多个字符,也可以没有字符。没有字符的叫作:空串。
空串:""。
有值的串:"1123"。
只有空格串的值: " "。
注意:空格也是值,它和空串不是同一个
2、主串与子串
S1 = "abcde"
S2 = "abc"
此时就可以说 S2为S1的子串,而S1为S2的主串。
3、串的创建方式
顺序表
我们可以用顺序表的方式模拟串,它依然是通过数组的方式创建,数组的每个元素为一个字符,无论这个串是用什么方式表示的,其在计算机内存中,也是这样存储的。
#define MAX_SIZE 1024
typedef struct {
char data[MAX_SIZE+1]; //字符串的数据,一般数据为了和长度对应,从索引1开始存放,而不是0
int Length; //字符串的长度
} SString;
链表
当我们需要对字符串进行大量的插入与删除时,我们就可以通过链表的方式模拟串,由于其通过指针去定位下一个节点,所以插入与删除时,不会像顺序表一样,要移动大量的节点。
下面的方式每个节点存储两个信息,数据与指针。

但这样有些浪费空间,可以用下面的方式优化。我们每个节点存储4个信息,3个用于存储数据,一个用于存储指针,这样就增加了信息密度。当然,实际每个节点的信息量可以看自己而定。

#define chunksize 80
typedef struct chunk{
char ch[chunksize];
struct chunk *next;
}chunk;
typedef struct{
chunk *head,*tail;
int curlen;
}lstring;4、常规操作
在主串中查找子串
在主串中查找子串,找到则返回子串的第一个字符在主串中的索引,没有找到则返回-1.
一般情况下有两种方式,一个是暴力匹配算法,一个是KMP算法。
暴力匹配算法
在字符串"aaabaaacaaad"中查找是否存在模式串"aaad" :
1、先比较字符串 与 模式串 第一个是否相等,相等则匹配下一个

2、比较第二个字符是否相等,相等则匹配下一个
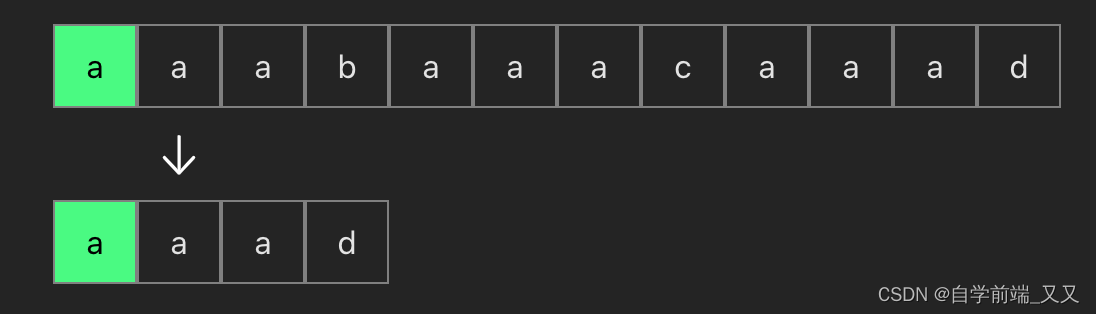
3、比较第三个字符是否相等,相等则匹配下一个
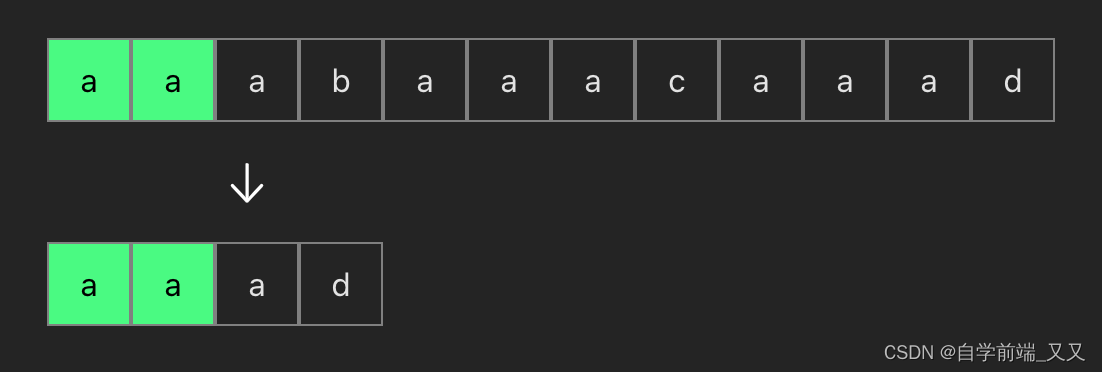
4、比较第四个字符是否相等,这时发现不相等

5、开始重新匹配,依次再和字符串的下一个字符相比较

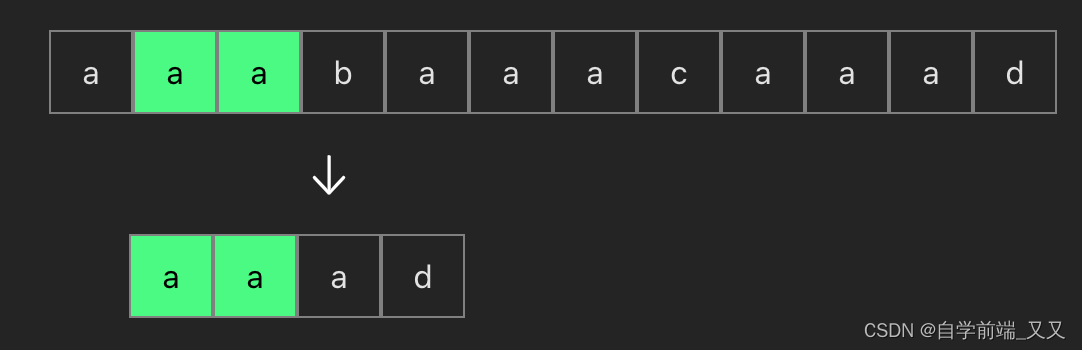
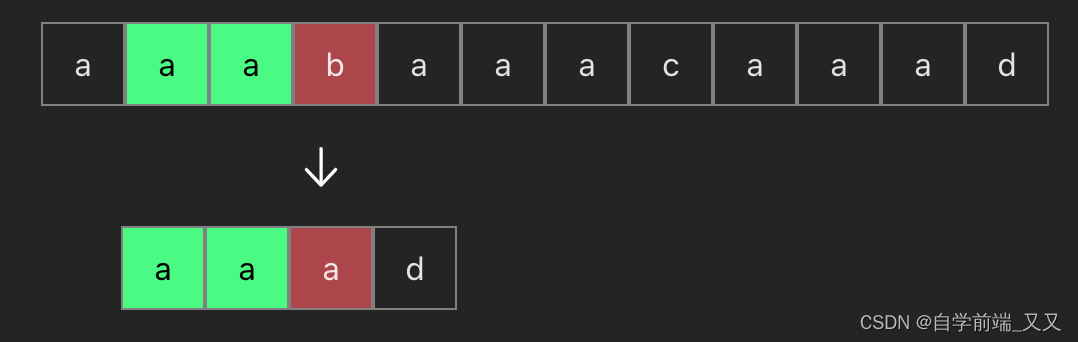

可以看到当我们第一次匹配了前三个aaa相等时,而在第四位不等时,前面四个就根本不用再反复比较了,因为在模式串中根本没有b这个字符(模式串就是下面的 aaad)
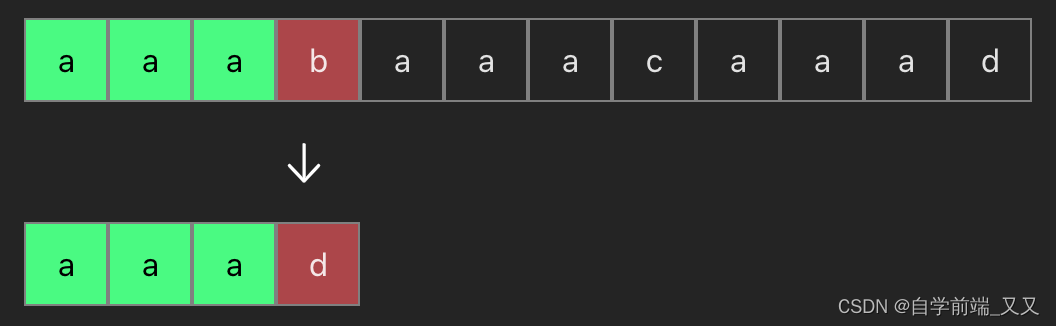
所以当我们比较完上面这个后,应该直接进行下面的比较
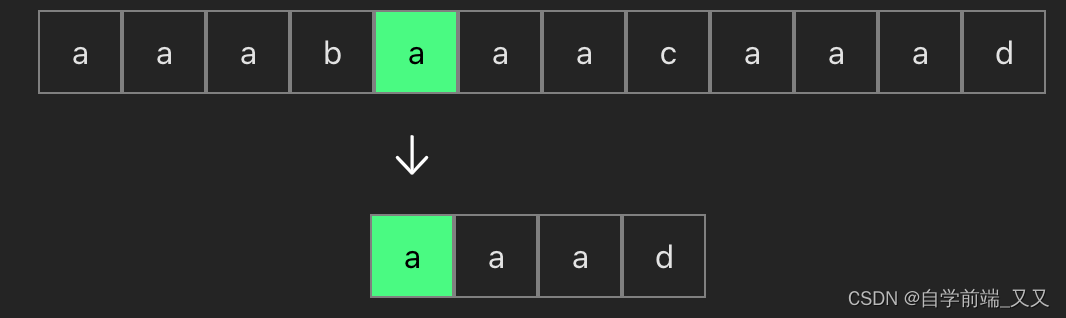
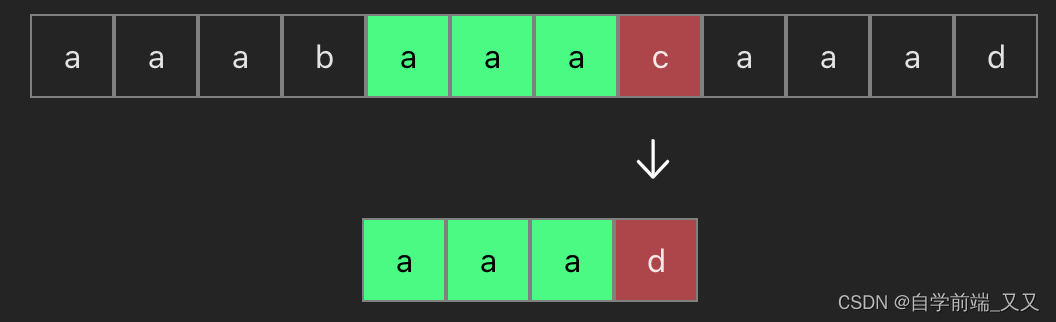
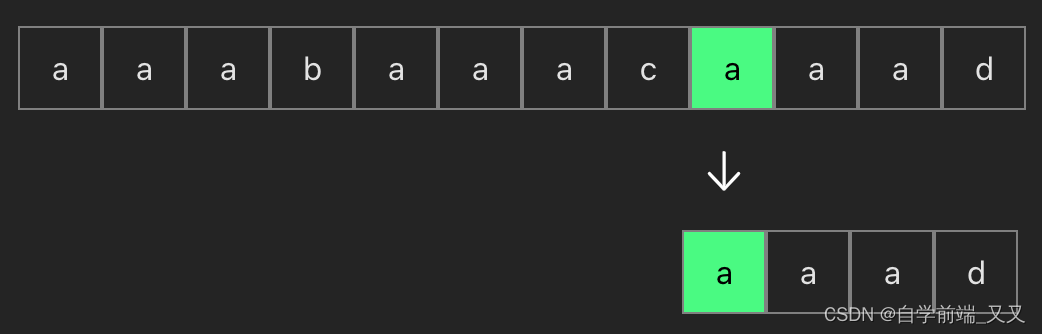

上面的这种算法效率很低,我们可以一眼就看出来有哪些是不必要的比较,程序又该如何描述呢?又或者说,当匹配不成功时,究竟下一个要比较的字符是谁,我们如何知道?
KMP算法
KMP算法,全称Knuth-Morris-Pratt算法,由这个三个作者共同创作 Donald Knuth、James H. Morris、Vaughan Pratt。
其核心在于next数组,就是在模式串中,寻找最大相同前后缀,并在字符比较时遇到错误的匹配,主字符串不用回溯到最初的位置+1,只需要停留在原位,而模式串则根据next数组确定要移动的位置。
我们来详细解释上面的话。
1、在模式串中,寻找最大相同前后缀。
现在我们要在字符串 “abcab??????”(注意: ? 代表暂时不知道为什么字符) 中查找是否有模式串 “abcabd”。
第一步,比较 字符串第一个字符 与 模式串第一个字符 是否相等。

发现相等, 继续向后检查

我们一直向下检查到了b字符,还是相等,继续检查最后一个字符。我们用大致这样方式判断,
if(字符串[i] == 模式串[i])
这时发现不相等,下一步我们是否该让模式串再重头开始,用a和字符串b相比较,其实这是没意义的。我们可以发现,当我们比较d和 ?发现不相等时,其实 字符串前面5个字符 和 模式串前面的 5个字符 一定是相等的,可是怎么利用这个信息呢?

现在我们假设按照之前的做法,当重新开始匹配时,想要比较 ?== 模式串[i],
则先要将前面的四个字符( b 、c、a、b)重新再匹配一遍,直到都匹配成功。而这里很明显会匹配失败,所以我们右移。

这个也匹配失败,继续右移

这个时候,发现已经匹配成功了,可以比较 ?== 模式串[i] 了。我们发现当匹配失败时,字符串不断的重新匹配前面的字符,只是为了之后可以比较新的字符(?== 模式串[i] )。而这一步则是判断 字符串的尾部 与 模式串的头部是否相等。如果前面可以预知其相等,则可以跳过前端的反复比较,直接比较 ?== 模式串[i] 。

通过上面的一步一步进行,可以发现当出现匹配失败时,我们其实就是在寻找 其匹配成功的内容中相同的首尾部。
如 当 字符串 ? != 模式串[i] , 我们开始用 字符串 ?前面字符的后缀 与 模式串前面字符的前缀 比较 。
字符串 bcab == 模式串 abca。 不等则各-1.
字符串 cab == 模式串 abc。 不等则各-1.
字符串 ab == 模式串 ab。 相等,开始匹配 ?
这就是所谓的最大相同前后缀。这里还不对,再看下面。
2、主字符串不用回溯到最初的位置+1,只需要停留在原位
当我们匹配失败时,我们开始找已经匹配过的字符串最大后缀 与 模式串最大前缀 ,这样就因为知道其前后缀相等,则不需要再一一比较,从而直接开始从 ? 比较,则字符串就不需要向前回溯了。
因为匹配过的说明这部分的字符串与模式串是相等的。也就是说在已经匹配过的部分中,字符串 = 模式串。而比较字符串最大后缀 与 模式串最大前缀,其实就是比较 模式串最大后缀 与 模式串最大前缀。

原本是想找出它们相等

可是由于它们是相等的

现在变成了找出它们相等

这才是最大相同前后缀。这样有一个很大的好处,就是我们的最大前后缀只通过模式串就可以完成,所以我们不需要知道字符串是什么,就可以知道当模式串匹配失败时,其最大前后缀是什么。
我举的这个例子,是当匹配失败时,其最大前后缀为 ab,当其他位置匹配失败时,也同样可以算出来。我们如果一开始就把模式串的每一个位置匹配失败时,都算出其最大相同前后缀。
如:d匹配失败时,其最大前后缀为2,其他的也这样算,并将每一个算出来的值都存入一个数组中,其数组一一对应模式串。这个数组就是next数组。
3、next数组。
既然找出 最大相同前后缀,可以让字符串的指针不用回溯。并且只需要 模式串就可以找出,那我们来看下吧。
等下,这里还要再补充一下最大相同前后缀的作用。其目的是为了在匹配失败时,字符串的指针不用回溯,通过移动模式串来进行重新匹配。
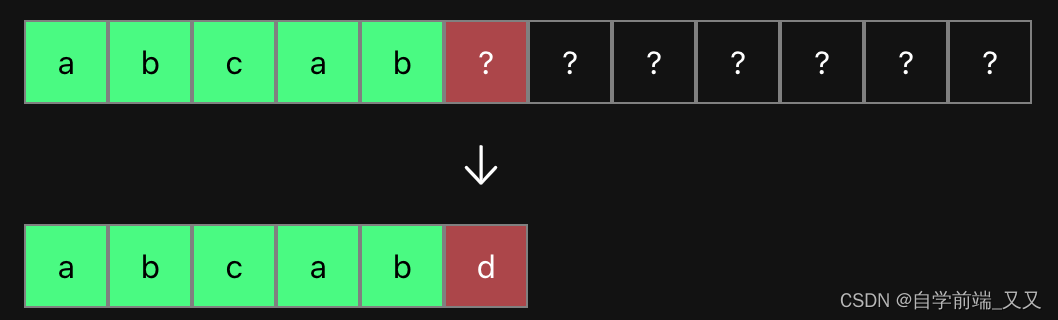
如上面的情况,当 ?与 d 匹配失败时,移动模式串,让 ?与 c 开始匹配。这个时候虽然 ab 为最大相同前后缀,但我们其实是想让最大相同前后缀的后面一个元素与 ?匹配,所以其对应next数组的值 不是 2,而是 3 。这也是为什么叫next数组,因为其中保存的值是下一个要匹配的位置(next的意思为下一个)(可既然是数组,为什么不按照索引来一一对应呢?如c的索引就是2啊。)
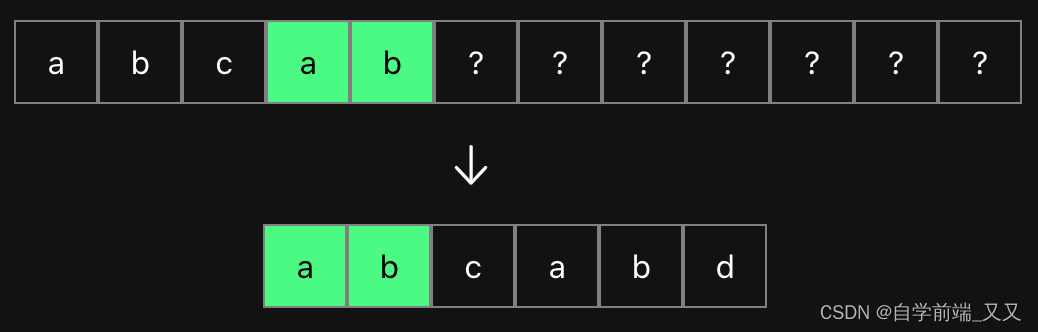
为什么不按照索引,看下面这种情况。当第一个字符就配置失败时,其实我们需要移动的是字符串,将其向后移动一格,但为了与其他情况保持一致,我们依旧要移动模式串使其可以再次匹配。

我们在next[0]的位置设置值为 -1,其实设置任何一个特别的值都行,-10/-9999都可以,这只是为了在代码中好判断它,这里还是用-1,当第一个字符匹配失败时,原先的 ?将指向 0,之后将让 i++,j++。使字符串指针与模式串指针向后移动一格,匹配新字符。

计算next数组 :(匹配的字符不能等于自身)
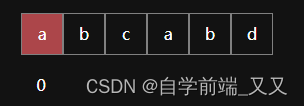
当第一个位置匹配失败时,其中没有匹配成功的串.注意:第一个位置的next值始终都是0,也就没有最大相同前后缀。
最大相同前后缀: 0
其next数组对应的值为:0
next数组此时为: [ -1 , 0 ]
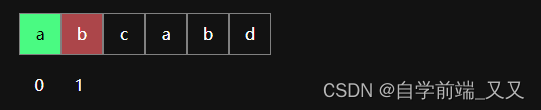
当第二个位置匹配失败时,其中有一个匹配成功的字符,但它是和自身比较的,不算。注意:第二个位置的next值始终都是1(图片的水印占的地方太大了,难受)
最大相同前后缀: 0
其next数组对应的值为:1
next数组此时为: [ -1 , 0 , 1 ]
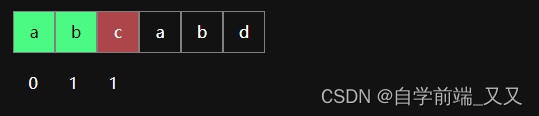
当第三个位置匹配失败时,其中有二个匹配成功的字符,有0相同前后缀。
最大相同前后缀: 0
其next数组对应的值为:1
next数组此时为: [ -1 , 0 , 1 , 1 ]
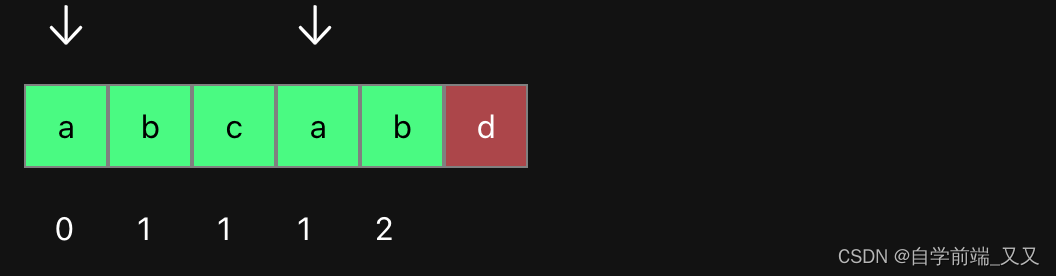
当第四个位置匹配失败时,其中有3个匹配成功的字符,有0个相同前后缀。
最大相同前后缀: 0
其next数组对应的值为:1
next数组此时为: [ -1 , 0 , 1 , 1 , 1]

当第5个位置匹配失败时,其中有四个匹配成功的字符,有 1 个相同前后缀。
最大相同前后缀: 1
其next数组对应的值为:2
next数组此时为: [ -1 , 0 , 1 , 1 , 1 , 2 ]

当第6个位置匹配失败时,其中有五个匹配成功的字符,有 3 个相同前后缀。
第一个相同前后缀 = 1 (a)
第二个相同前后缀 = 1 (b)

第三个相同前后缀 = 2 (ab)
最大相同前后缀: 2
其next数组对应的值为:3
next数组此时为: [ -1 , 0 , 1 , 1 , 1 , 2 , 3]

4、模式串则根据next数组确定要移动的位置。
现在我们已经得到了 next 数组,注意当我们在创建next数组时,只用到了模式串,而此时这个next数组,在和任何字符串匹配时都同样有效。
下面是模式串与next数组的情况。
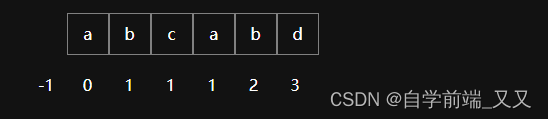
再说一下next数组的作用,当某一个位置匹配失败时,不用移动字符串指针,只需要找到模式串的next数组,并按照失败位置的next值,将其值赋值给 模式串指针 j ,将模式串移动到 next[ j ] 即可。
当第一个位置匹配失败时
令 模式串指针 j = 0
匹配 模式串的 next[ j ] 的位置, 位置为 a 前面的字符,-1,在代码层面会做处理,暂时先不用管。

当第二个位置匹配失败时
令 模式串指针 j = 1
匹配 模式串的 next[ j ] 的位置, 也就是 a。

当第三个位置匹配失败时
令 模式串指针 j = 1
匹配 模式串的 next[ j ] 的位置, 也就是 a。

当第四个位置匹配失败时
令 模式串指针 j = 1
匹配 模式串的 next[ j ] 的位置, 也就是 a。

当第五个位置匹配失败时
令 模式串指针 j = 2
匹配 模式串的 next[ j ] 的位置, 也就是 b。(其实next数组也有不足之处,这里匹配b已经失败了,结果重新匹配的位置又是 b ,肯定还会匹配失败。别急,那是下一章要讲的 nextval 数组。先学懂 这章吧 !)

当第六个位置匹配失败时
令 模式串指针 j = 3
匹配 模式串的 next[ j ] 的位置, 也就是 c。

好了,说了这么多了,下面开始上代码。
/**
* T 为 模式串, char *T 为字符数组指针,
* const:表示不能修改字符串的值(但可以修改指针指向地址)。
* next[] : 为 整数数组,用于存储匹配表
* length: 模式串的长度
*/
void get_next(const char *T, int next[], int length) {
int i = 0, j = -1;
next[0] = -1;
// i < length,这里用 < 而不是 <=,是因为如果 = length,则字符就匹配成功了,
while (i < length) {
if (j == -1 || T[i] == T[j]) {
i++;
j++;
next[i] = j;
} else {
// 回溯,i 不变,让j-1.
j = next[j];
}
}
}
//kmp
int get_index_kmp(const char *S, const char *T) {
int i = 1, j = 1;
int sLength = strlen(T);
int tLength = strlen(T);
int next[tLength + 1];
get_next(T, next, tLength);
while (i <= sLength && j <= tLength) {
if (i == 0 || S[i] == T[j]) {
i++;
j++;
} else {
j = next[j];
}
}
if (j > tLength) {
return i - tLength; // 匹配成功
}
return 0;
}添加字符
顺序表方式
#include <stdbool.h>
#include <stdlib.h>
#define INITSIZE 10
typedef struct {
int *data; // 动态数据
int Length; // 顺序表的长度(数据量)
int MaxSize; // 顺序表的最大容量
} List;
/** 插入操作 */
bool InsertList(List *list, int i, int element) {
// 如果 i 的值 不在顺序表的范围内,则操作失败
if (i < 0 || i > list->Length) return false;
// 如果长度不小于最大容量,则插入一条数据后,必然溢出,操作失败
if (list->Length >= list->MaxSize) return false;
// 逆向循环,直到i的位置
for (int j = list->Length; j >= i; j--) {
// 依次将数据向后移动一格
list->data[j] = list->data[j - 1];
}
// 插入位置是索引,所以要-1
list->data[i - 1] = element;
// 长度+1
list->Length++;
return true;
}
链表方式
判断插入的位置是否合理。
创建链表指针和指针在链表所在的位置。
位置指针,并判断其位置是否是要插入的位置,如果是则进入下一步,否则移动指针至下一个节点。
创建新节点,为其赋值,并将指针指向原位置的下一个节点(a2)。
将原位置(a1)的指针指向新节点。
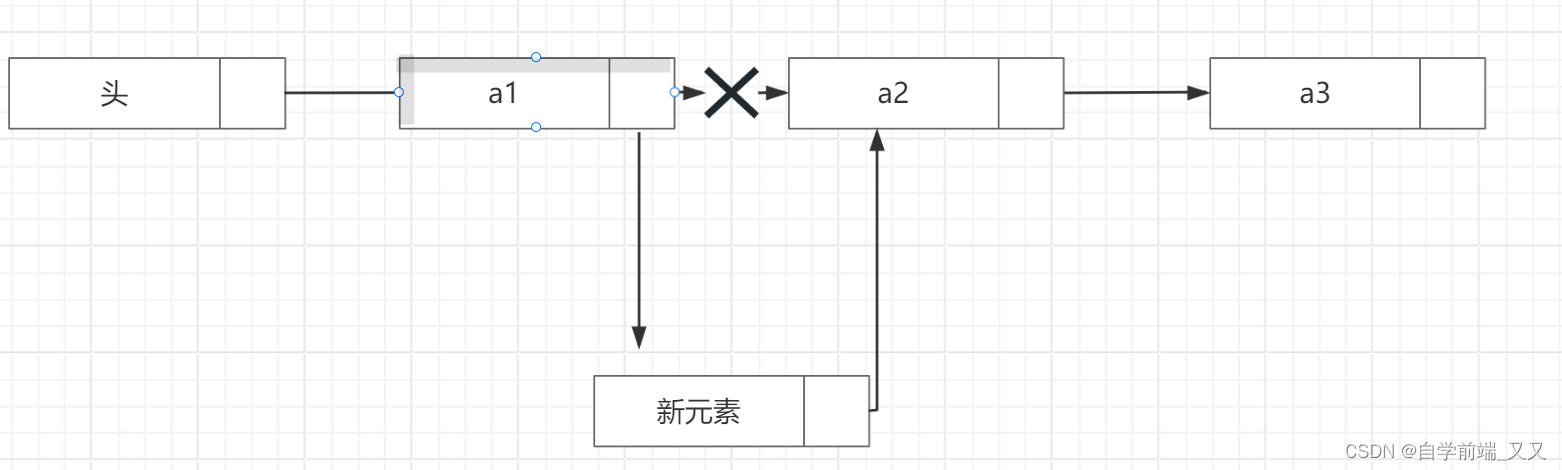
// 定义单链表节点结构体类型
typedef struct LNode {
int data; // 数据域
struct LNode* next; // 指针域(指向下一个节点的指针)
} LNode, *LinkList;
/** 按位序插入 */
bool InsertList(LinkList list, int i, int e) {
// 插入位置超过最小,返回false
if (i < 1) {
return false;
}
LNode* p = list; // 链表的指针,移动指向每个节点
int j = 0; // 当前指针所在链表的位序
// 指向的节点的位序不是 i,则进入循环
while (p != NULL && j < i - 1) {
p = p->next; // 指针移向下一位
j++;
}
// 插入位置超过最大,值为空,则返回false
if (p == NULL) {
return false;
}
// 创建新节点并分配内存
LNode* t = (LNode*)malloc(sizeof(LNode));
t->data = e; // 为新节点赋值
t->next = p->next; // 将新节点的指针指向原位序的下一位
p->next = t; // 将新节点插入该位序
return true;
}
删除字符
顺序表方式
将下标为 i 索引位置删除,并将其后继元素向前移动一个索引。操作成功返回true,否则返回false。成功后需要将被删除的元素赋值给 element 。
时间复杂度:
/** 删除操作 */
bool DeleteList(List *list, int i, int *element) {
// 如果 i 的值 不在顺序表的范围内,则操作失败
if (i < 0 || i >= list->Length) return false;
// 将被删除的元素赋值给 element
element = list->data[i - 1];
// 从i的位置开始,将后继元素向前移动一格
for (int j = i - 1; j < list->Length; j++) {
list->data[j] = list->data[j + 1];
}
// 长度-1
list->Length--;
return true;
}链表方式
1、通过位序找到节点 p。
2、创建新节点,并将其指向 p 的下一个节点(用于临时保存数据)。
3、将 p 的下一个节点的信息(数据和指针)赋值到新节点。
4、释放新节点内存。
// 定义单链表节点结构体类型
typedef struct LNode {
int data; // 数据域
struct LNode* next; // 指针域(指向下一个节点的指针)
} LNode, *LinkList;
/** 删除操作 */
bool DeleteList(LinkList list, int i) {
// 找到该位序的节点
LNode* p = FindIdxList(list, i);
// 节点不存在,返回false
if (p == NULL) return false;
// 创建新节点,为要删除节点的下一个节点
LNode* s = p->next;
// 将要删除节点的下一个节点数据 赋值给p,相当于覆盖了p的数据(删除)
p->data = s->data;
p->next = s->next;
// 释放内存
free(s);
return true;
}二、数组
数组的定义
数组是一个有序集合,其成员类型相同,如int、char、double等等。在逻辑存储中,其每个元素都是相邻的,通过索引定位成员。在计算机内存中,数组的每个元素依然相邻。获取成员位置则通过索引*成员大小而得到。
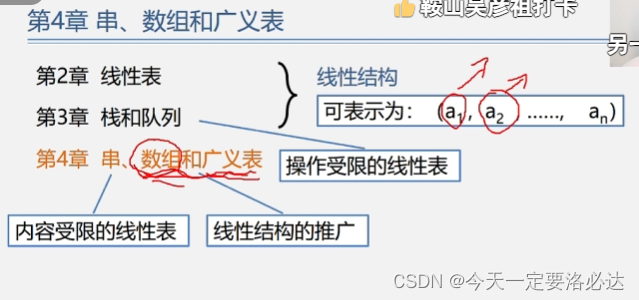
常用数组结构可以分为 一维数组、二维数组、三维数组。
一维数组: [1,2,3]
二维数组:[ [1,2,3] , [4,5,6] , [7,8,9] ]
三维数组:[
[ [1,2,3] , [4,5,6] ] ,
[ [1,2,3] , [4,5,6] ]
]
不同维数的数组也可以实现转换,如一维数组 [1,2,3,4 ,5,6,7,8]。如果我们以4个元素为一个集合,则就相等于二维数组。 [ [1,2,3,4] , [5,6,7,8] ]。
对称矩阵的压缩
可以看到下面的数组,它的数据沿着对角线一分为二,而两边的数据成对称数据,这时候就可以只存一半的数据。

三角矩阵的压缩
可以看到下面的数组,它的数据沿着对角线一分为二,而其中一边的数据都是一样的,这时候就可以将这些数据只存一份。

对角矩阵的压缩
可以看到下面的数组,它的数据沿着对角线区域块切分,而边上的数据都是0,这时候就可以只存储中间数据值不为0的部分。

稀疏矩阵
当数组中的数据不为0的数据量很少时,被称为稀疏矩阵,这时候也可以只存储数据不为0的值,只是同时要在节点内保存其 x轴与y轴的坐标。
又或者保存节点时,在节点内存储其右边相邻的数据不为0的指针,和其下边相邻的数据不为0的指针。这种也被称为十字链表法。
[
[ 1 , 0 , 0 , 0 ] ,
[ 0 , 0 , 6 , 0 ] ,
[ 0 , 0 , 0 , 0 ] ,
[ 0 . 0 , 5 , 0 ]
]三、广义表
广义表是线性表的推广,它的元素既可以是普通元素,也可以是广义表。这样就可以定义递归结构的广义表。
广义表与线性表的区别:线性表的元素只能是不可分割的单元,而广义表的元素还可以是子表。
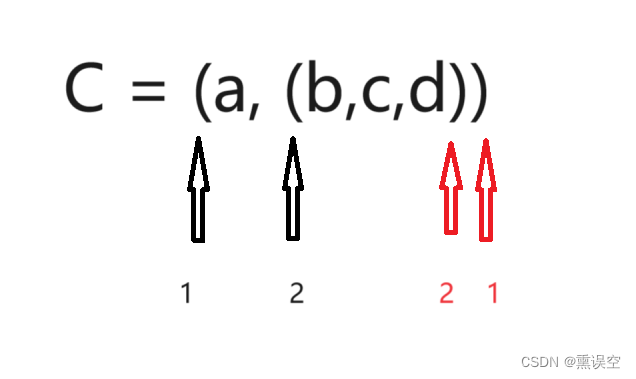
广义表的长度:广义表的元素个数,不统计嵌套的元素。
广义表的深度:广义表的子表可展开的最大层数。
广义表的表尾:非空广义表的表头为表头元素,表尾为除表头外所有元素合成的一个表。
广义表的存储结构
由于广义表可以嵌套定义,所以它并不算是一个线性结构,也就不好用数组去定义。一般都用链表定义。