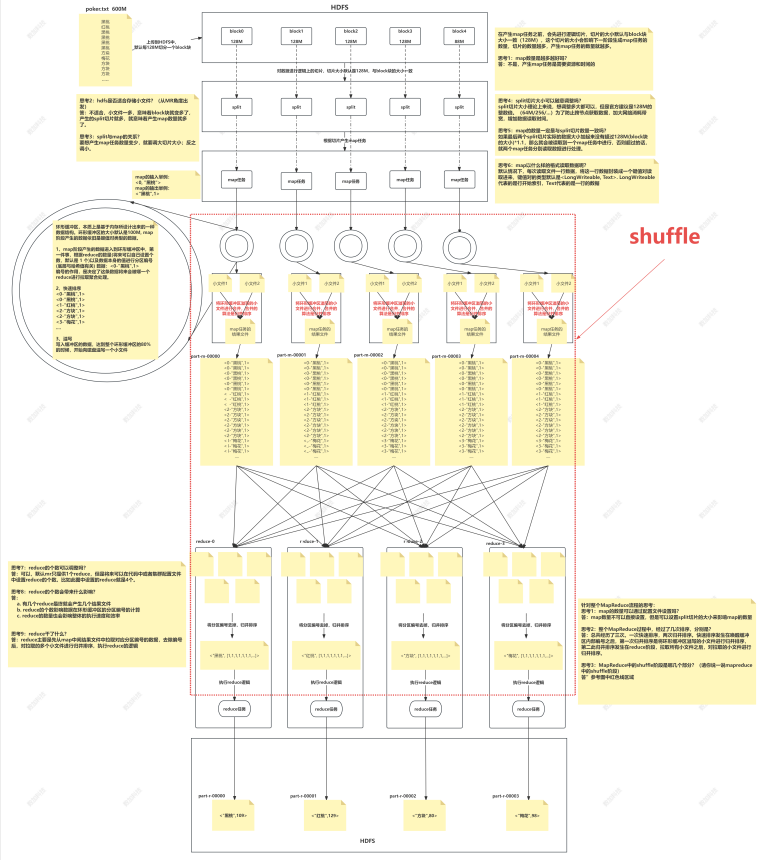
Shuffle 的本义是洗牌、 混洗, 把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。 MapReduce 中的 Shuffle 更像是洗牌的逆过程, 把一组无规则的数据尽量转换成一组具有一定规则的数据。
为什么 MapReduce 计算模型需要 Shuffle 过程?
我们都知道 MapReduce 计算模型一般包括两个重要的阶段: Map 是映射, 负责数据的过滤分发; Reduce 是规约, 负责数据的计算归并。
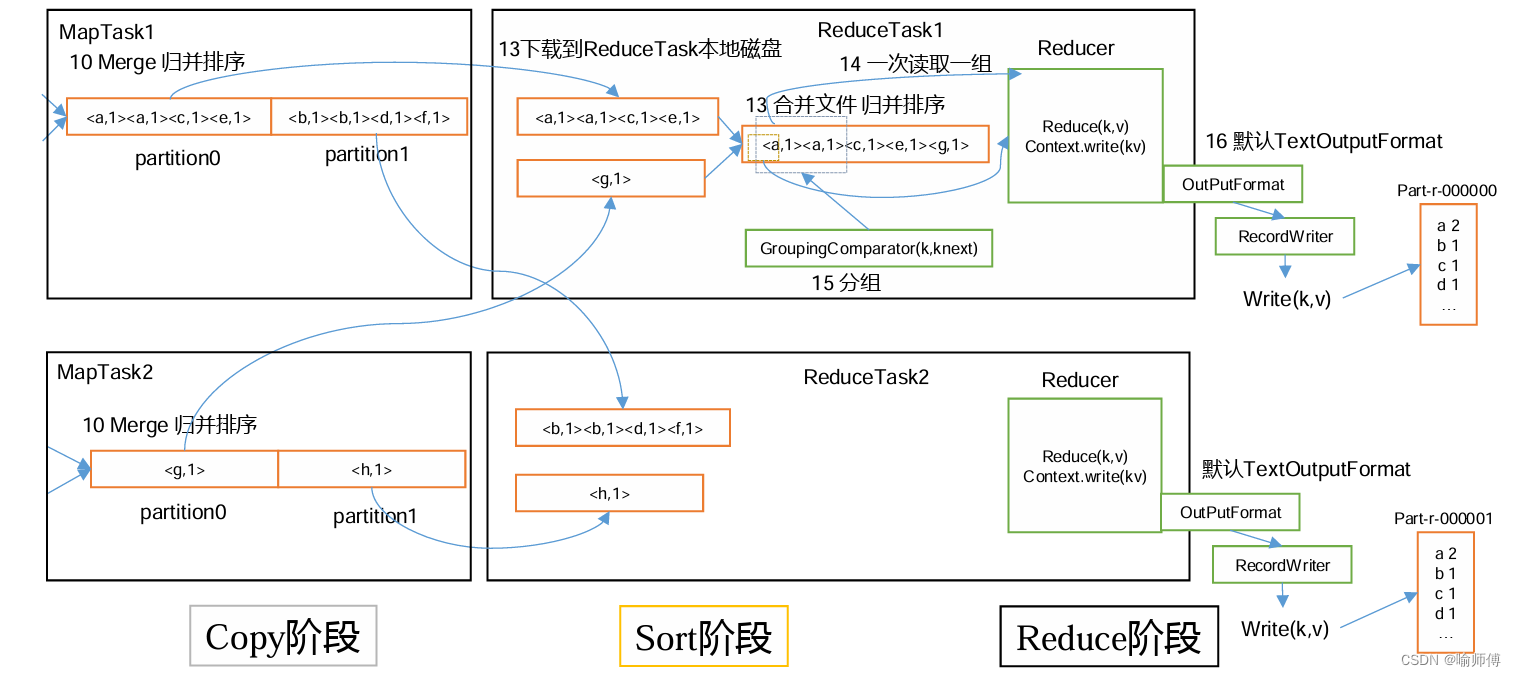
Reduce 的数据来源于 Map, Map 的输出即是 Reduce 的输入, Reduce 需要通过 Shuffle 来获取数据。从 Map 输出到 Reduce 输入的整个过程可以广义地称为 Shuffle。
Map Shuffle
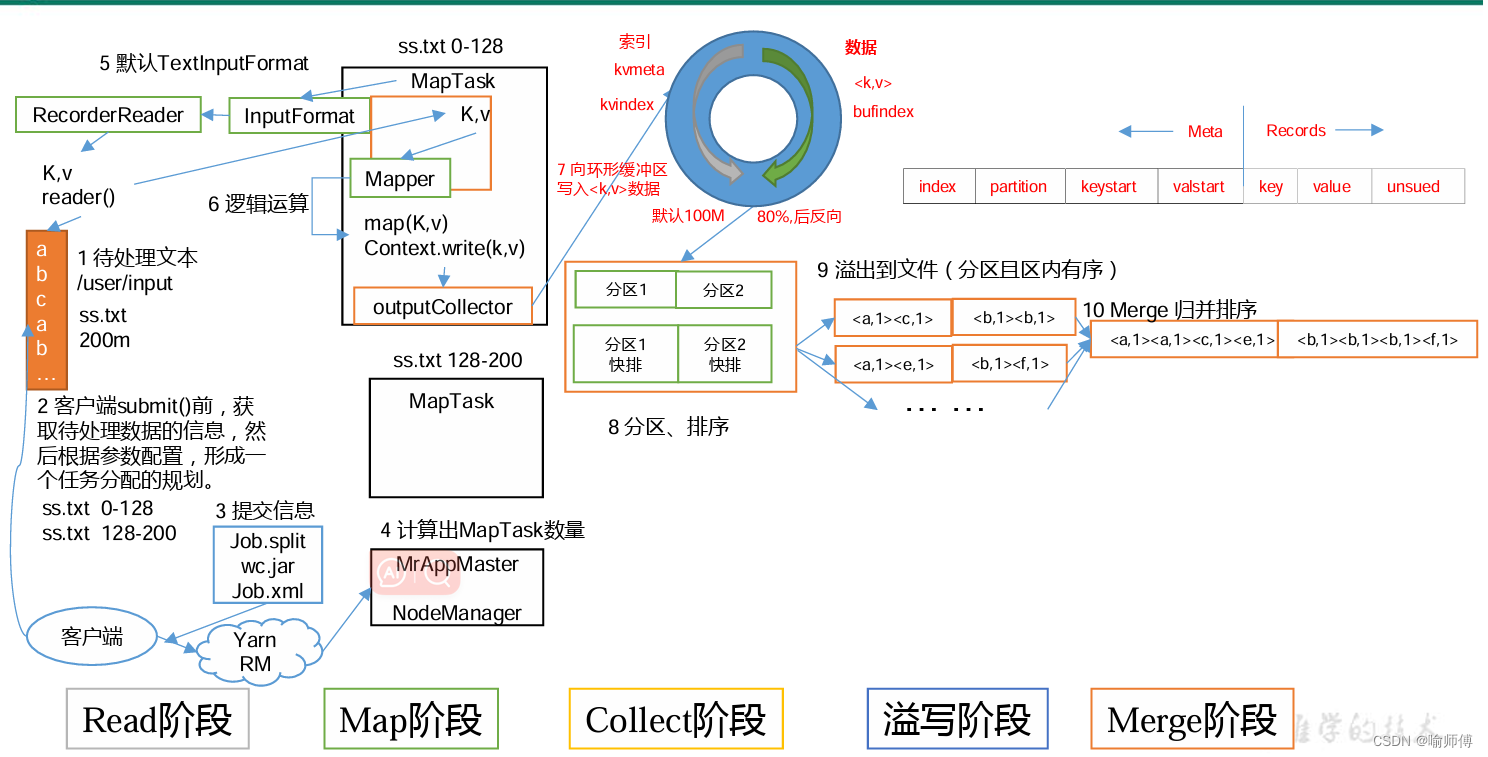
在Map端的shuffle过程是对Map的结果进行分区、排序、分割,然后将属于同一划分(分区)的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件。分区有序的含义是map输出的键值对按分区进行排列,具有相同partition值的键值对存储在一起,每个分区里面的键值对又按key值进行升序排列(默认)。
其流程大致如下:
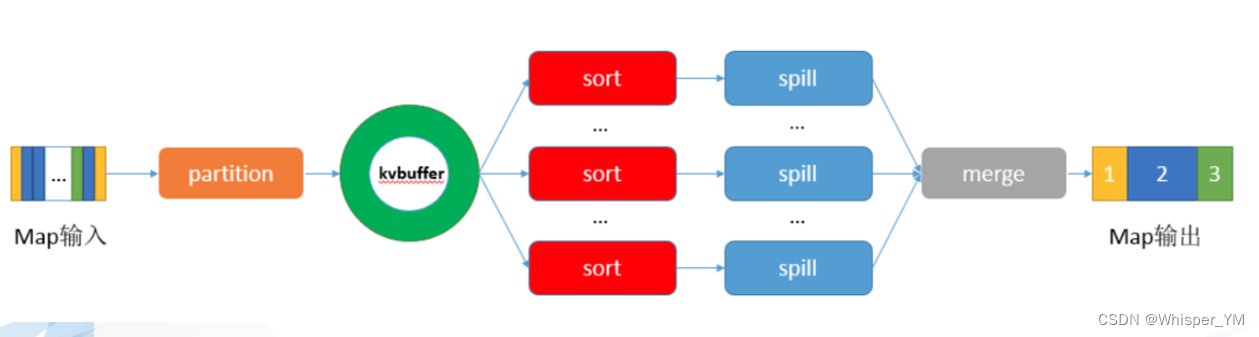
Partitioner
Partition分区是Shuffle的一部分功能,它的作用是按照条件把结果输出到不同的文件(分区)中。 如果通过job.setNumReduceTasks(x)设置多个分区,Partition的默认实现是根据key的hashCode对ReduceTask个数取模得到的,用户没法控制哪个key存储到哪个分区。
Partition的默认实现代码是:

如果不设置ReduceTask个数,它默认分区个数为1个。
自定义Partitioner
1 新建自定义分区类MyPartition
2 MyPartition继承Partiton抽象类,实现getPartition()方法
3 在Driver类中指定自定义分区类,设置reduce task个数
案例实现可看上一篇博客
自定义Partitioner的总结
1.如果ReduceTask的数量> getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
2.如果1< ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会Exception;
3.如果ReduceTask的数量=1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件part-r-00000;
4.分区号必须是从零开始,逐一累加。
内存缓存区
完成数据分区后,maptask会通过收集器 collector将数据写入内存缓存区,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。key/value对以及Partition的结果都会被写入缓冲区。在写入之前,key与value值都会被序列化成字节数组。
内存缓存区默认大小限制为100MB,它存在一个溢写比例(默认是0.8),所谓溢写(spill),就是把内存缓冲区的数据写入本地磁盘。当缓冲区的数据达到阈值时,就会启动溢写线程。

内存缓存区的工作原理
1>环形缓冲区默认大小为100M,可以配置 mapred-site.xml:mapreduce.task.io.sort.mb 来配置大小;
2>环形缓冲区阈值为 80%,超过就会开始spill溢写到磁盘。可以配置 mapred-site.xml:mapreduce.map.sort.spill.percent 来配置阈值的百分比;
3>环形缓冲区存储两种数据, 一种是元数据:KV的分区号,key的起始位置,value的起始位置,value长度。每个元数据长度固定为4个int长度 ;一种是原始数据:存储key和value原本的数据;
4>当环形缓冲区超过80%时,会将这80%的数据锁定,然后溢写到磁盘中变成小文件,并且这个过程中,这80%的空间不能写入数据(由后台一个新的线程来执行溢写)。同时剩下的20%可以继续写入数据。直到溢写结束,解除80%的空间锁定。
spill
当缓冲器空间超过80%时,一个后台线程会启动,开始溢写成小文件,写入磁盘。在这个过程中,会对缓冲区中的元数据根据先根据分区号(每个分区一个溢写文件),然后同一分区内根据key进行排序(这里的排序算法使用快速排序)。接着根据排好序的元数据,溢写相应的原始数据。最后得到已经分区且分区内已根据key排好序的溢写文件。
同时在溢写最后一步,可以加入combine过程(可选的)

![Hadoop(2):常见<span style='color:red;'>的</span><span style='color:red;'>MapReduce</span>[在Ubuntu<span style='color:red;'>中</span>运行!]](https://img-blog.csdnimg.cn/direct/634bd4d90e294429a091fc7da005c308.png)