重头戏lxml库里面的xpath
一段代码给各位开开胃

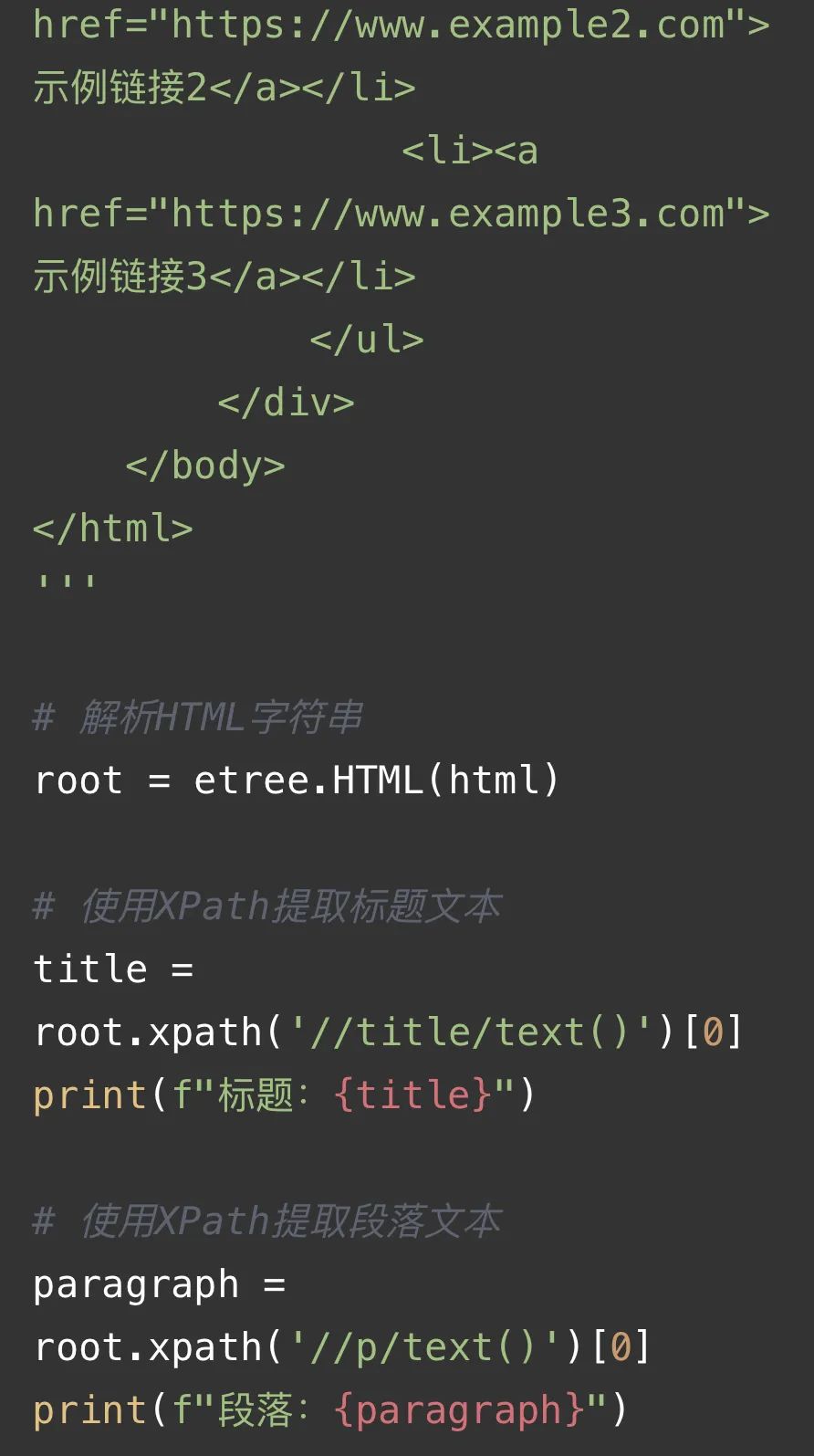

这段代码首先导入了`lxml`库中的`etree`模块,然后定义了一个包含HTML内容的字符串`html`。接着,我们使用`etree.HTML()`函数解析这个HTML字符串,得到一个表示整个HTML文档的树形结构。最后,我们使用`xpath()`方法提取所需的信息。
1. 提取标题文本:我们使用XPath表达式`//title/text()`来定位到`<title>`标签,并提取其文本内容。
2. 提取段落文本:我们使用XPath表达式`//p/text()`来定位到`<p>`标签,并提取其文本内容。
3. 提取所有链接的文本和URL:我们使用XPath表达式`//a`来定位到所有的`<a>`标签,然后分别提取每个链接的文本和URL。注意,这里我们使用了相对路径(以`.`开头)来在当前节点下继续查找子节点。
下面是有关爬虫xpath的定位
1. 选取所有节点:`//`
2. 选取当前节点:`.`
3. 选取子节点:`/`
4. 选取父节点:`..`
5. 选取属性:`@属性名`
6. 选取文本:`text()`
接下来简要介绍一下HTML结构:
HTML的基本结构包括DOCTYPE声明、html元素、head元素和body元素等。以下是这些基本结构的具体介绍:
1. DOCTYPE声明:DOCTYPE声明位于HTML文档的最前面,它告诉浏览器当前文档所使用的HTML版本。这是为了确保浏览器正确解释和呈现网页内容,遵循相应的标准。
2. html元素:html元素是整个HTML页面的根元素,它包含了文档的所有其他元素。它通常以`<html>`开始,以`</html>`结束标签闭合。这个元素中可以包含语言声明,如`lang="en"`,指定页面的主要语言。
3. head元素:在HTML中,`<head>`元素包含了所有不可见的元数据信息,比如编码声明`<meta charset="utf-8">`、页面标题`<title>`、链接到外部资源如CSS和JavaScript文件等。虽然`<head>`中的内容不会直接显示出来,但对于搜索引擎优化(SEO)和页面的适当功能至关重要。
4. body元素:`<body>`元素包含了所有用户在浏览器上可见的实际内容。这包括文本、图片、链接、列表、表格等内容。在这个区域,可以使用各种HTML标签来结构化内容,如`<p>`用于段落,`<h1>`到`<h6>`用于不同级别的标题,`<a>`用于超链接等。
此外,HTML文档还具有一些高级特性,例如属性可以用来添加更多信息到元素中。例如,`<a>`标签的`href`属性指定了链接的目标地址。同时,HTML5引入了一些新的语义化元素,如`<header>`、`<footer>`、`<article>`和`<section>`,它们可以帮助更好地定义网页内容的结构。
HTML图例如下:
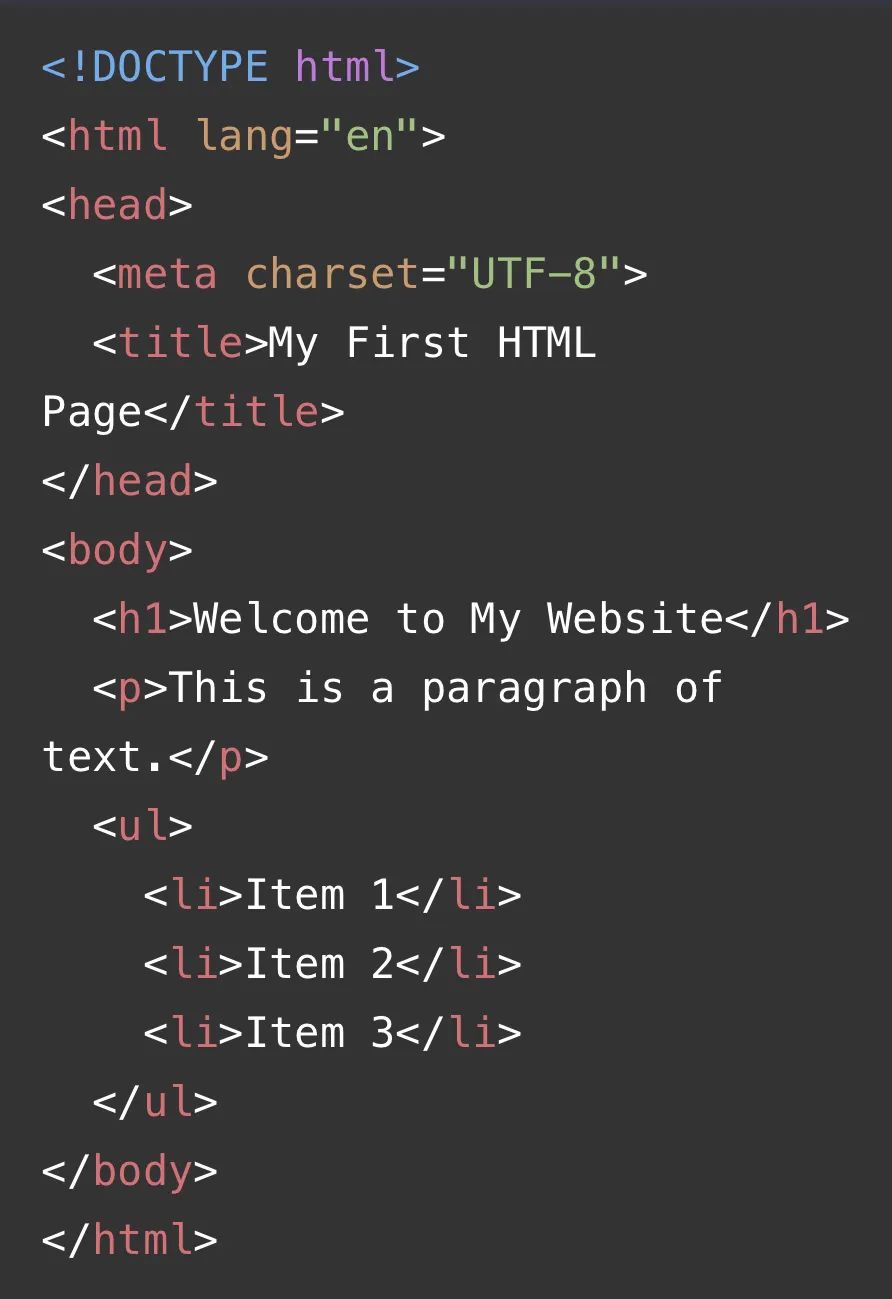
综上所述,掌握HTML的基本结构和相关标签对于前端开发是非常重要的基础。合理地使用这些标签不仅可以提高页面的可读性和可维护性,也有助于搜索引擎更好地理解和索引网页内容。
以上的相关应用可以通过小蜜蜂AI的GPT问答获取更多的示例。网址:https://zglg.work。
(文章对你有用的话。记得点赞➕在看哦😯😯😯😯分享知识也是一种美德)
如有学习上的困惑或问题欢迎评论区留言告诉我们,让我们一起解决共同进步: