前缀统计
题目描述
给定 N N N 个字符串 S 1 , S 2 ⋯ S N S_1,S_2\cdots S_N S1,S2⋯SN,接下来进行 M M M 次询问,每次询问给定一个字符串 T T T,求 S 1 ∼ S N S_1 \sim S_N S1∼SN 中有多少个字符串是 T T T 的前缀。
输入字符串的总长度不超过 1 0 6 10^6 106,仅包含小写字母。
输入格式
第一行输入两个整数 N , M N,M N,M。
接下来 N N N 行每行输入一个字符串 S i S_i Si。
接下来 M M M 行每行一个字符串 T T T 用以询问。
输出格式
对于每个询问,输出一个整数表示答案。
每个答案占一行。
样例 #1
样例输入 #1
3 2
ab
bc
abc
abc
efg
样例输出 #1
2
0
提示
数据范围满足 1 ≤ N , M ≤ 1 0 5 1 \le N,M \le 10^5 1≤N,M≤105
原题
思路
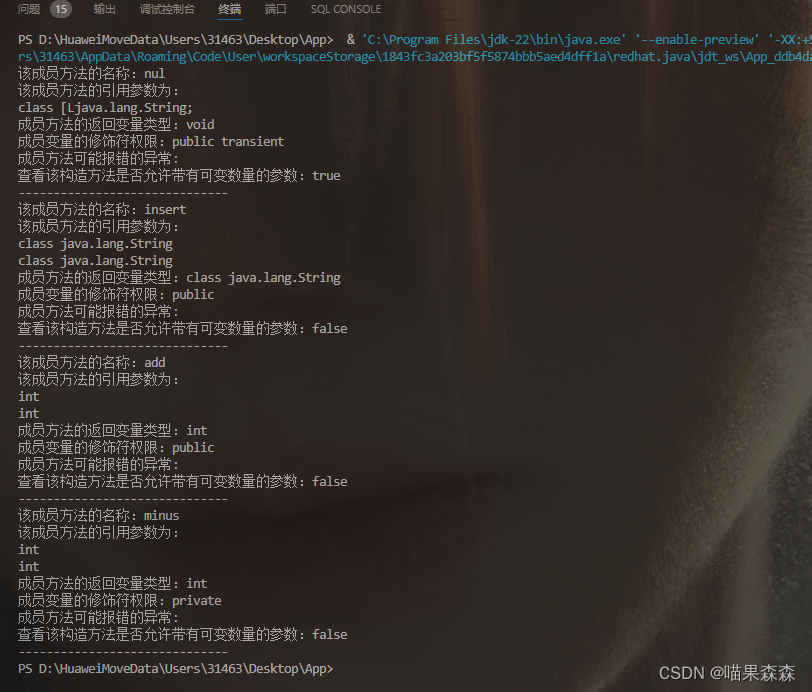
将 S 1 , S 2 ⋯ S N S_1,S_2\cdots S_N S1,S2⋯SN 插入字典树中,每当遍历到 S i S_i Si 的最后一个字符,令当前位置的计数器即 c n t [ u ] cnt[u] cnt[u] 加 1。处理询问的字符串时,在字典树中遍历,并在每个位置统计前缀的个数。例如,对于询问的字符串 b b c bbc bbc,初始化一个总和 r e s = 0 res=0 res=0,在字典树中字符串 b 、 b b 、 b b c b、bb、bbc b、bb、bbc 结尾所在的三个位置 u u u 都令 r e s = r e s + c n t [ u ] res=res+cnt[u] res=res+cnt[u]。
代码
#include <bits/stdc++.h>
using namespace std;
using i64 = long long;
typedef long long ll;
const int MAXN = 1e6 + 6;
struct Trie
{
int ch[MAXN][63], cnt[MAXN], idx = 0;
map<char, int> mp;
void init()
{
i64 id = 0;
for (char c = 'a'; c <= 'z'; c++) // 为小写字母编号
mp[c] = ++id;
}
void insert(string s)
{
int u = 0;
for (int i = 0; i < s.size(); i++)
{
int v = mp[s[i]];
if (!ch[u][v])
ch[u][v] = ++idx; // 给孩子节点赋予新编号
u = ch[u][v];
if (i == s.size() - 1) // 在模式串结束时计数
cnt[u]++;
}
}
i64 query(string s)
{
i64 res = 0;
int u = 0;
for (int i = 0; i < s.size(); i++)
{
int v = mp[s[i]];
if (!ch[u][v]) // 已经不可能再出现前缀字符串,直接返回
return res;
u = ch[u][v];
res += cnt[u]; // 在询问串的每个位置都统计前缀个数
}
return res; // 返回总的前缀字符串个数
}
} trie;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
trie.init();
int n, q;
cin >> n >> q;
string s;
for (int i = 0; i < n; i++)
{
cin >> s;
trie.insert(s); // 在字典树中加入模式串
}
for (int i = 0; i < q; i++)
{
cin >> s;
cout << trie.query(s) << '\n'; // 输出询问字符串的前缀模式串数量
}
return 0;
}
![<span style='color:red;'>洛</span><span style='color:red;'>谷</span><span style='color:red;'>P</span><span style='color:red;'>1047</span> [NOIP2005 普及组] 校门外的<span style='color:red;'>树</span>(C语言)](https://img-blog.csdnimg.cn/direct/ae8e8dd5eaa74bb8bb56e7018e736204.png)