在大数据领域,数据回溯是一项至关重要的任务,它涉及到对历史数据的重新处理以确保数据的准确性和一致性。

数据回溯的定义与重要性
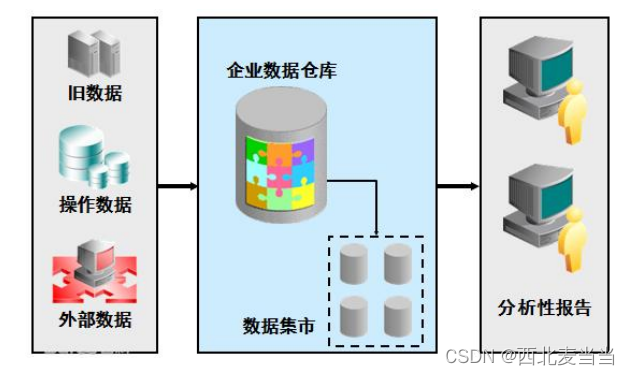
数据回溯,也称为数据补全,是指在数据模型迭代或新模型上线后,对历史数据进行重新处理,以满足业务方对历史数据的分析需求。这一过程对于进行年环比等统计分析至关重要,能够为业务发展提供准确的数据支持。
数据回溯的实施策略
1. 代码检查与适配
在进行数据回溯之前,首先需要检查现有代码是否需要修改以适应新的数据需求。
主要检查表是否有回溯日期的数据,有时候数据采集是新的口径,表中没有历史的数据,要回溯,页做不到…
SHOW PARTITIONS table_name;
2. 上游任务的数据分区适配
数据回溯往往需要处理跨越多个时间分区的数据。在确定回溯的时间范围后,必须检查上游任务是否提供了所需的历史数据分区。如果上游表只包含2023年1月1日之后的数据,而需要回溯到2022年1月1日,就必须考虑是否需要对上游数据进行补充或使用最近的数据进行回刷。
3. 并行度的合理配置
资源的合理分配对于数据回溯任务至关重要。在资源紧张的情况下,盲目增加并行度不仅会浪费资源,还可能导致任务执行效率降低。需要根据任务的依赖关系和资源队列的实际情况,合理设置并行度,以实现资源的最优利用1。
考虑任务依赖和资源限制,设置合适的并行度参数:
如:`mapreduce.job.reduces=10
4. 队列资源的监控与调度
在数据回溯过程中,持续监控队列资源的使用情况是必不可少的。当队列资源充足时,可以适当增加并发任务以提高效率。
查看Yarn队列资源:
yarn application -list
根据资源使用情况调整并发任务数。
数据回溯是大数据开发中一项复杂且关键的任务。
通过合理的代码适配、上游数据分区的检查、并行度的优化配置以及队列资源的监控,可以有效地提高数据回溯的效率和准确性。
随着大数据技术的不断进步,数据回溯的方法和工具也在不断发展,为企业提供更加高效和可靠的数据支持
以前可能自己写shell脚本,现在用dolphinscheduler这样的调度工具,通过可视化的操作就能实现
总结一下: