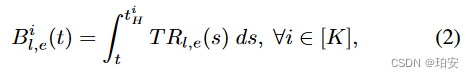摘要
https://arxiv.org/pdf/2404.06395
随着开发具有高达数万亿参数的大型语言模型(LLMs)的兴趣激增,关于资源效率和实际成本的担忧也随之而来,特别是考虑到实验的巨大成本。这一情形突显了探索小型语言模型(SLMs)作为资源高效替代方案的潜力。在此背景下,我们介绍了MiniCPM,特别是其1.2B和2.4B非嵌入参数变体,这些变体不仅在各自的类别中表现出色,而且在能力上与7B-13B的LLMs不相上下。尽管我们专注于SLMs,但我们的方法在模型和数据维度上都表现出可扩展性,为未来LLM的研究提供了可能。
在模型扩展方面,我们进行了广泛的模型风洞实验,以实现稳定和最优的扩展。对于数据扩展,我们引入了一种Warmup-Stable-Decay(WSD)学习率调度器(LRS),这有利于持续训练和领域适应。我们对WSD LRS中出现的引人入胜的训练动态进行了深入分析。使用WSD LRS,我们现在能够在模型和数据两个维度上高效研究数据-模型扩展定律,而无需在任一维度上进行大量的重新训练实验,从中我们得出了比Chinchilla Optimal更高的计算最优数据-模型比。
此外,我们介绍了MiniCPM家族,包括MiniCPM-DPO、MiniCPM-MoE和MiniCPM-128K,这些模型的卓越性能进一步巩固了MiniCPM在多样化SLM应用中的基础。MiniCPM模型现已公开可用 1 ^{1} 1。
1、引言
随着扩展法则(Kaplan et al., 2020)的揭示,大型语言模型(LLMs)领域出现了蓬勃的发展势头(Hoffmann et al., 2022; Bai et al., 2023; Gemini et al., 2023; Chowdhery et al., 2023; Achiam et al., 2023),其中涵盖了参数数量惊人的模型,甚至达到了数万亿个参数(Fedus et al., 2022)。这些模型已成为人工智能发展的重要推动力。
然而,训练如此大规模的模型既耗资巨大又操作低效。一方面,目前对于支撑LLMs训练机制的实证理解仍然难以捉摸。考虑到巨大的经济和环境成本,对于大多数研究人员和公司来说,进行LLMs的实验成本过高。另一方面,在日常场景中部署这些庞大的模型,例如在个人电脑或智能手机上,要么效率低下,要么根本不可行。
这两个方面都突显出必须重新将精力集中在全面探索更小但强大的语言模型(SLMs)上。这些模型一方面为实际部署提供了有效的解决方案,另一方面,如果采用可扩展的策略进行训练,它们有可能指导未来更大模型的开发。
最近,人们对SLMs领域的兴趣重新兴起,一系列创新模型的出现证明了这一点,如Phi系列(Gunasekar et al., 2023; Li et al., 2023b; Javaheripi & Bubeck, 2023)、TinyLlama(Zhang et al., 2024a)、MobileLLM(Liu et al., 2024)和Gemma(Banks & Warkentin, 2024)等。虽然这些模型为SLM领域的扩展和多样化做出了重大贡献,但在两个关键领域,这些模型尚未完全满足当前的利益需求:(1)开发类似于LLMs所展现的综合能力;(2)制定
在本文中,我们介绍了MiniCPM,一系列的小型语言模型(SLMs),它们主要基于两个模型,分别拥有 2.4 B 2.4 \text{B} 2.4B和 1.2 B 1.2 \text{B} 1.2B的非嵌入参数,并在各自 2 B 2 \text{B} 2B和 1 B 1 \text{B} 1B规模类别中占据领先地位。MiniCPM还展示了与7B和13B等大型语言模型(如Llama2-7B(Touvron等人,2023)、Mistral-7B(Jiang等人,2023)、Gemma-7B(Banks和Warkentin,2024)以及Llama-13B(Touvron等人,2023)等)相媲美的能力。尽管这些模型的规模较小,但我们的训练方法经过精心设计,以促进模型规模和数据范围的无缝扩展。这通过我们的模型风洞实验得到了体现,这些实验包括全面的超参数优化(第3节),以及使用WSD(Warmup-Stable-Decay)学习率调度器(第4节)。后者针对未预定义预训练标记数量的连续训练进行了定制,使得模型中间检查点的重复使用变得高度可行。我们对MiniCPM的训练动态进行了详细分析,表明WSD调度器揭示了模型预训练的有趣损失景观。使用WSD调度器,我们现在能够以线性努力在模型轴上研究数据-模型扩展定律,而在数据轴上几乎不需要付出努力,而传统的方法则需要考虑模型和数据轴上的二次努力。扩展定律的结果表明,与Chinchilla Optimal(Hoffmann等人,2022)相比,数据大小/模型大小的比率要高得多。
此外,我们介绍了MiniCPM家族,包括MiniCPM-DPO、MiniCPM-128K和MiniCPM-MoE。我们对MiniCPM家族进行了与既定基准的对比评估,并展示了它们作为SLMs的令人印象深刻的能力:(1)基础模型超越了Mistral-7B和LLama-13B。(2)DPO模型在MTBench(Zheng等人,2024)上超越了zephyr-7B(Tunstall等人,2023)。(3) 2.4 B 2.4\text{B} 2.4B的MiniCPM-128K模型的性能要么超越要么与Yarn-Mistral-7B-128K(Peng等人,2023)和ChatGLM3-6B-128K(Du等人,2021)等模型的性能相匹配。(4)具有 4 B 4\text{B} 4B激活参数的MiniCPM-MoE与Llama2-34B(Touvron等人,2023)相当。
综上所述,MiniCPM开启了小型语言模型发展的新阶段,展示了SLMs的潜在潜力,并倡导采用更科学和可持续的方法来扩展LLMs。
2、相关工作
小型语言模型(SLMs):“小型语言模型”(SLMs)是一个不断发展的概念,它随着时间的推移经历了重大的转变。目前,与知名的LLMs(大型语言模型)相比,SLMs通常被理解为规模较小的模型,其参数通常不超过70亿。这些模型的特点是可以在最终用户设备上部署,如个人电脑和智能手机,即使在没有图形处理器(GPU)的情况下也可以运行。
在当前SLMs领域中,值得注意的例子包括Phi系列(Gunasekar等人,2023;Li等人,2023b;Javaheripi和Bubeck,2023)、TinyLlama(Zhang等人,2024a)、MobileLLM(Liu等人,2024)和Gemma(Banks和Warkentin,2024)等。已经探索了多种方法来提高SLMs的效能。其中包括融入高质量数据(Gunasekar等人,2023;Li等人,2023b;Javaheripi和Bubeck,2023)、应用结构化剪枝技术(Xia等人,2023)和重新配置模型架构(Liu等人,2024)等。MiniCPM通过精心结合超参数优化、战略训练方法论、架构设计以及使用高质量数据,进一步提升了SLMs的能力。
可扩展的预训练策略。自从发现扩展法则(Kaplan等,2020;Rae等,2021;Aghajanyan等,2023)以来,人们开始从不同角度科学地、可预测地(Achiam等,2023;Hu等,2023;Du等,2024)寻求扩大大型语言模型(LLMs)的规模,特别是在预训练阶段。在训练稳定性方面,引入了Tensor Program系列(Yang等,2022;2023)来确保不同模型规模之间最优超参数的一致性,这是训练CerebrasGPT(Dey等,2023)时采用的一种技术。此外,Wortsman等(2023)建议利用较小的模型来预测和缓解较大型模型训练中的不稳定性。从训练数据的角度来看,人们提倡各种以数据为中心的策略(Xie等,2024;Shi等,2023;Ye等,2024)。在训练方法领域,先前的研究已经深入探讨了不同的学习率调度器(LRS)(Howard&Ruder,2018;Raffel等,2020;Hundt等,2019),其中余弦学习率调度器(Cosine LRS)(Loshchilov&Hutter,2016)已成为LLMs中的主要选择。Kaplan等(2020)和Hoffmann等(2022)对Cosine LRS的超参数进行了细致的研究,从而为后续的预训练工作奠定了基础。其中,DeepSeek(Bi等,2024)与我们提出的WSD LRS最为相似。关于批量大小调度,Smith等(2017)主张增加批量大小,以此作为降低学习率的替代方法,这一策略最近被Yi-9B(Young等,2024)采用。
3、模型风洞实验
虽然我们旨在训练能够快速部署到终端设备的小型语言模型(SLMs),但我们预见模型训练的许多方面在不同规模上都是通用的。在将经验转移到大型语言模型(LLMs)之前,应该通过SLM进行广泛的实验来探索SLM的极限。这些实验借鉴了飞机开发中风洞测试的精神,因此我们将其命名为模型风洞实验(MWTE)。在本文中,MWTE包含三个部分:(1)超参数;(2)最优批量大小缩放;(3)最优学习率稳定性。
3.1、缩放超参数的不变语言模型
超参数对模型的性能有重大影响。然而,在传统训练中为每个模型调整超参数对于LLMs来说是不可行的。即使是像MiniCPM这样的SLM,对超参数的广泛搜索实验也需要大量资源。Tensor Program(Yang等,2022;2023)提出了一个框架,用于稳定不同规模模型的超参数。Tensor Program的主要部分是宽度缩放(Yang等,2022)和深度缩放(Yang等,2023)。前者技术支持CerebrasGPT(Dey等,2023)更准确地预测LLMs的损失。在MiniCPM中,我们同时使用了这两种缩放技术。具体的缩放操作列在表7中。我们没有应用注意力softmax缩放技术(Yang等,2022)。尽管Yang等(2023)观察到对于块深度大于2的网络,深度缩放并不理想,但我们通过经验发现,由此产生的最优学习率是稳定的。超参数和Tensor Program操作的详细信息在附录A.1中。
3.2、最优批量大小
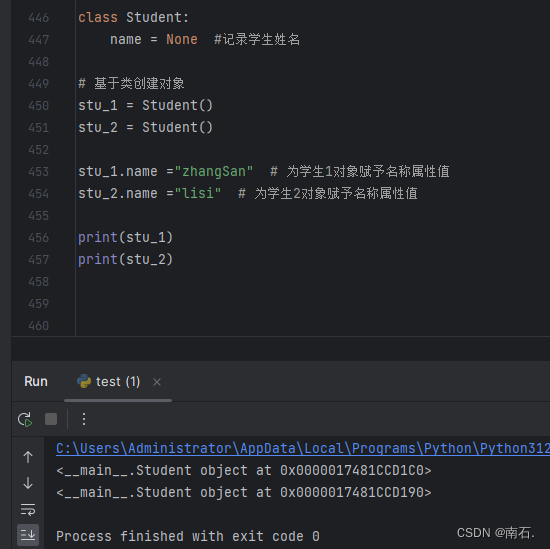
批量大小决定了模型收敛速度和计算资源消耗之间的平衡。如果批量大小过大,将会导致大量的数据和计算成本。另一方面,如果批量大小过小,则需要大量的训练步骤,并可能导致损失函数的下降有限。我们遵循Kaplan等人的方法(2020)根据预期损失来确定批量大小,并对他们的设置进行了略微修改(见附录A.2)。为了实现这一目标,我们分别对0.009B、0.03B和0.17B的模型进行了实验。每种模型大小都在6个批量大小上进行训练,全局学习率为0.01,并使用余弦学习率调度器。我们观察了C4(Raffel等,2019)数据集上损失与最优批量大小的趋势(图1中的红线)。
如图1所示,我们在x轴上绘制批量大小,在y轴上绘制令牌消耗,点的颜色代表损失。因此,由彩色点形成的水平线表示训练曲线。我们使用抛物线来拟合等损失点,并用红线连接抛物线的最小值。这些线表明,随着损失的减少,最优批量大小会变大。然后,我们将三条线连接起来(见图2),发现这些线在对数空间中很好地连接成线性关系,由此我们得到了批量大小 b s b_s bs和C4损失 L L L之间的关系: b s = 1.21 × 1 0 9 L 6.24 b_s = \frac{1.21 \times 10^{9}}{L^{6.24}} bs=L6.241.21×109。我们注意到,从训练后才能得到的粗略损失预测来估计批量大小可能看起来很奇怪。我们在附录A.2中提供了我们的评论。
3.3 最优学习率
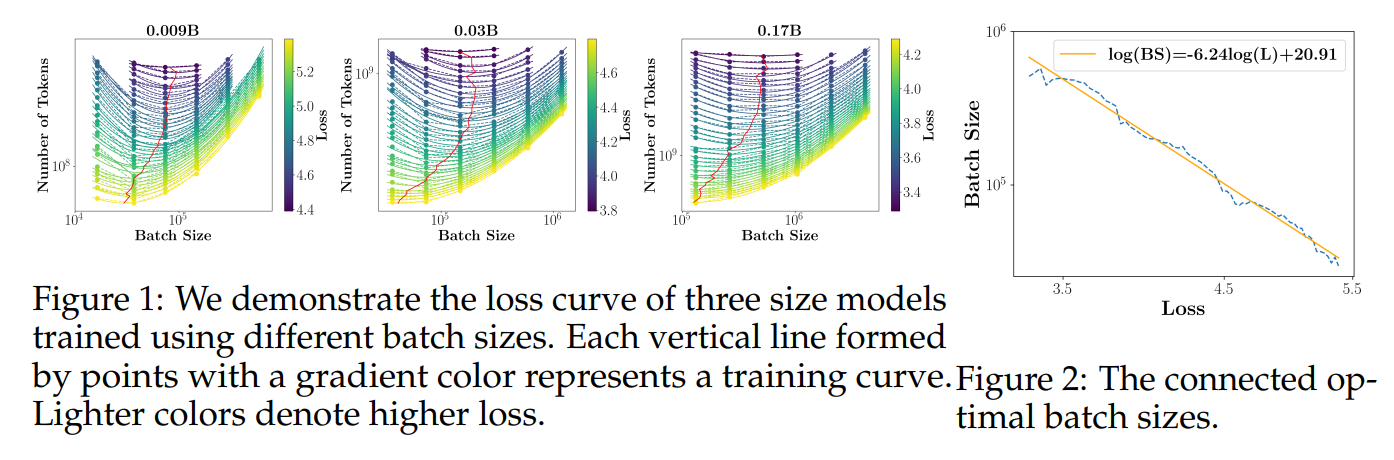
由于我们使用了Tensor Program(Yang等人,2022;2023),我们预测在模型缩放过程中,学习率不会发生显著变化。为了验证这一点,我们在0.04B、0.1B、0.3B和0.5B的模型上进行了六组学习率实验。在图3中,我们发现尽管模型大小增加了十倍,但最优基础学习率 2 {}^{2} 2并没有出现明显的偏移,仍然保持在0.01左右。我们进一步在2.1B的模型规模上进行了简单的验证,并确认0.01的学习率确实达到了最低的损失。
4、WSD学习率调度器
4.1、分析余弦学习率调度器
学习率调度器(LRS),用于调整训练不同阶段使用的学习率,对模型性能至关重要。目前常用的学习率策略是余弦LRS(Kaplan等,2020;Hoffmann等,2022;Rae等,2021;Touvron等,2023;Bai等,2023;Almazrouei等,2023),在预热阶段达到最大值后,按照余弦曲线逐渐降低学习率。
余弦LRS中的一个关键超参数是步长 T T T,即余弦首次降至最小值时的步长。通常,对于具有预定义训练步长的训练, T T T被设置为总训练步长 S S S。一般认为,学习率应该较高,以便进行充分的探索。例如,Kaplan等人(2020)表明,当整个训练过程中的学习率总和增加时,损失会减少(见其论文中的图22)。这表明设置 T < S T<S T<S并非最优选择。另一方面,Hoffmann等人(2022)观察到一个关键现象,即设置 T > S T>S T>S会导致性能下降,而设置 S = T S=T S=T则会提高训练效率,这证实了在整个训练过程中学习率不应保持较高水平。为了重现这些观察结果,我们在 0.036 B 0.036B 0.036B模型上进行了实验。我们尝试了余弦 ( T ) (T) (T)和余弦循环 ( T ) (T) (T) LRS,遵循附录B.1中给出的公式。结果如图4所示。我们可以看出,当训练步长为 S = 20 N , 40 N , 60 N , 80 N S=20N, 40N, 60N, 80N S=20N,40N,60N,80N时,最低损失总是由 T = S T=S T=S时的余弦 ( T ) (T) (T)实现。 T < S T<S T<S和 T > S T>S T>S都不是最优选择。
我们假设当 T = S T=S T=S时,余弦学习率(Cosine LR)表现得特别好,原因如下两点:(1) 与 T < S T<S T<S和其他如线性学习率调度器(Linear LRS)相比, T = S T=S T=S的余弦学习率调度器具有更长时间的高学习率训练阶段。这种高学习率可能有助于模型找到更好的全局最优解。(2) 与 T > S T>S T>S的余弦学习率调度器和恒定学习率调度器(Constant LRS)相比, T = S T=S T=S的余弦学习率调度器具有更彻底的学习率衰减阶段。这种学习率衰减可能涉及到独特的训练动态,使模型能够找到更好的局部最优解。
4.2、WSD学习率调度器
鉴于上述观点,我们提出明确地将训练阶段分为高学习率阶段和学习率衰减阶段。我们将其称为Warmup-StableDecay (WSD)学习率调度器。特别是,WSD学习率调度器包含三个阶段:预热阶段(结束步数由 W W W表示)、稳定训练阶段(结束步数由 T T T表示)和剩余的衰减阶段。WSD的函数形式为:
WSD ( T ; s ) = { s W η , if s < W η , if W < s < T f ( s − T ) η , if T < s < S \text{WSD}(T; s) = \begin{cases} \frac{s}{W} \eta, & \text{if } s < W \\ \eta, & \text{if } W < s < T \\ f(s-T) \eta, & \text{if } T < s < S \end{cases} WSD(T;s)=⎩ ⎨ ⎧Wsη,η,f(s−T)η,if s<Wif W<s<Tif T<s<S
其中, 0 < f ( s − T ) ≤ 1 0 < f(s-T) \leq 1 0<f(s−T)≤1是关于 s s s的递减函数, η \eta η是最大学习率。通常,只要预热阶段足够,它对性能的影响就很小,因此,在后续讨论中我们省略 W W W。为了简化表示,我们将使用具有明确停止点的WSD来标记。
4.3、实验
接下来,我们介绍WSD LRS(Weight Stagewise Decay Learning Rate Schedule,权重分阶段衰减学习率调度)的几个实验发现。
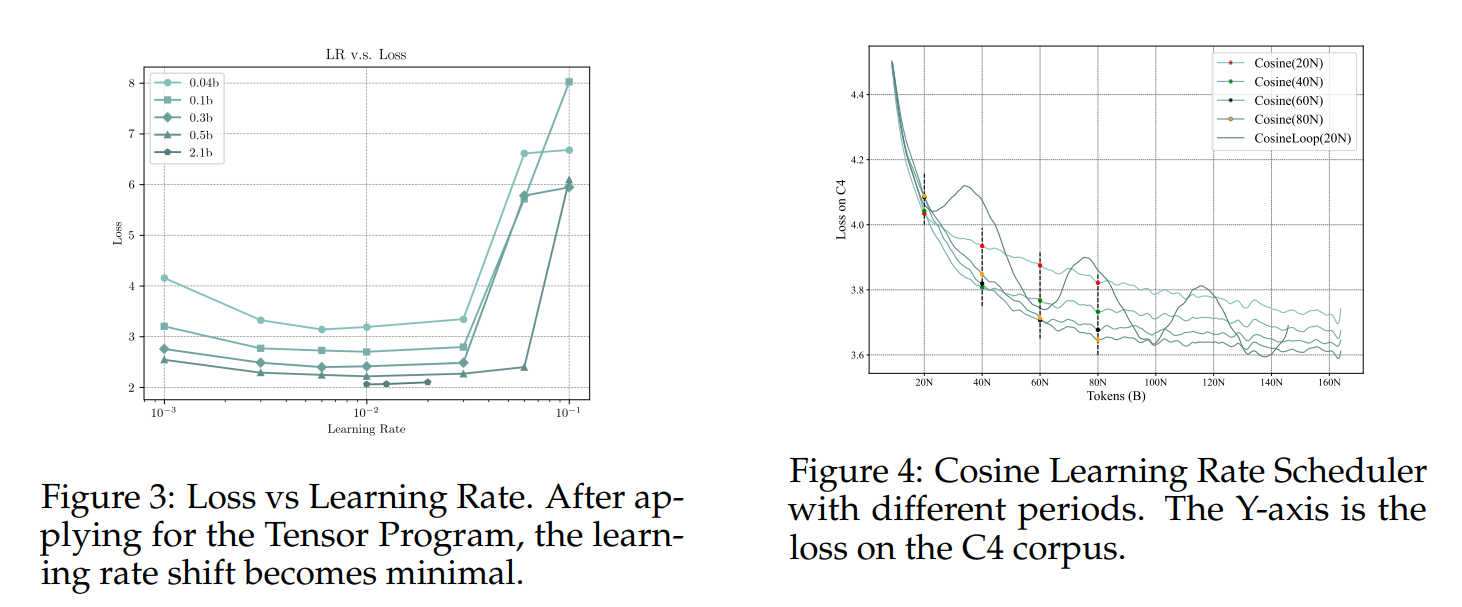
衰减阶段损失大幅下降。我们在0.036B的模型上尝试了WSD LRS。如图5所示,在衰减阶段,随着学习率开始下降,损失经历了一个显著的快速下降,并迅速降低到等于或低于在步骤 T = S T=S T=S时的余弦学习率调度(Cosine LRS)的水平。同时,我们可以在衰减前重用模型,并以之前的高学习率继续训练。经过更多的训练步骤 S ′ S^{\prime} S′后,我们也可以通过退火达到与余弦学习率调度在Cosine(KaTeX parse error: Expected group as argument to '\right' at end of input: …^{\prime}\right)时相同的损失。这验证了我们的假设,即训练阶段可以明确地分为稳定训练和衰减阶段。
10 % 10\% 10%的步骤就足够了。从两阶段训练的视角来看,缩短衰减阶段将极大地有利于快速测试稳定训练的不同模型检查点。因此,我们进行了实验,这些实验从相同的稳定训练检查点开始,但具有不同的衰减步数。同样如图5所示,在所有三个稳定训练检查点(使用 40 N 40 \mathrm{~N} 40 N, 60 N 60 \mathrm{~N} 60 N,和 80 N 80 \mathrm{~N} 80 N的训练数据)中,大约 10 % 10\% 10%的总标记衰减就足够达到最佳结果,而总标记的 2.5 % 2.5\% 2.5%衰减则不够。因此,在后续的训练实验中,我们使用大约 10 % 10\% 10%的衰减来确保充分收敛。
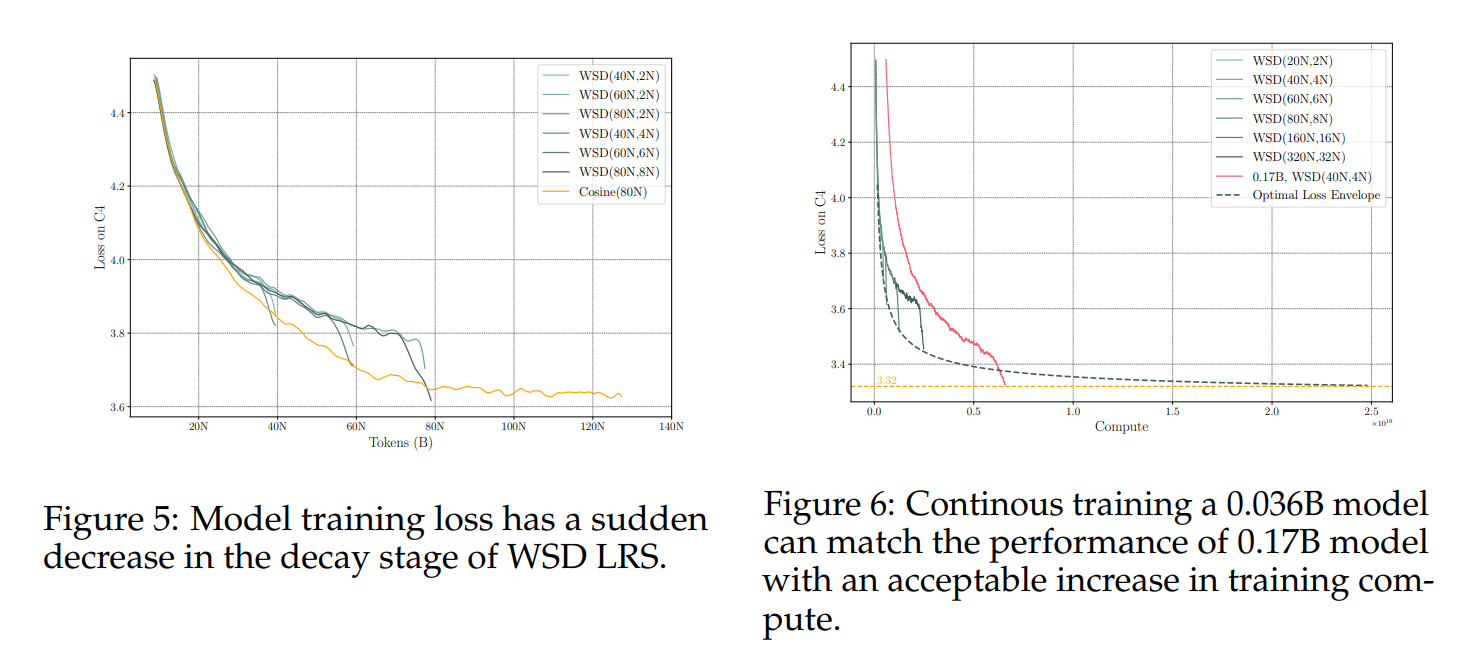
使用WSD LRS进行有效数据扩展。通过WSD LRS,我们可以持续训练语言模型至极端收敛。为了进一步展示将固定大小的模型训练至收敛的潜力,我们将持续训练的 0.036 B 0.036 \mathrm{~B} 0.036 B语言模型与 0.17 B 0.17 \mathrm{~B} 0.17 B模型在40N数据上进行比较。在图6中,绿色线条代表使用不同稳定训练标记量训练的 0.036 B 0.036 \mathrm{~B} 0.036 B模型。尽管 0.036 B 0.036 \mathrm{~B} 0.036 B系列的最后一个点比Chinchilla Optimal(Hoffmann等人,2022年)训练了更多的标记,但它仍然有性能提升的空间。
为了找到持续训练这个固定大小语言模型的极限,我们估计了模型在持续训练过程中的最优性能如何随其计算量变化。这里的最优性能是指使用 W S D ( D , 0.1 D ) WSD(D, 0.1D) WSD(D,0.1D)训练的 D D D个标记所能达到的损失。通过一系列 D D D值,损失将形成最优损失包络线。由于损失包络线的函数形式不确定,我们尝试了两个拟合公式:(1)指数型: L ( C ) = α e − β C + L 0 L(C) = \alpha e^{-\beta C} + L_{0} L(C)=αe−βC+L0 和(2)幂律型: L ( C ) = β C − α + L 0 L(C) = \beta C^{-\alpha} + L_{0} L(C)=βC−α+L0。两个函数的拟合结果见附录B.2。我们发现幂律型拟合得更好(类似于余弦学习率调度(Kaplan等人,2020年))。在图6中,拟合曲线以绿色虚线显示。为了直观地估计和理解持续训练这种固定大小模型的效果,我们还使用 W S D ( 40 N , 4 N ) WSD(40N, 4N) WSD(40N,4N)训练了一个 0.17 B 0.17 \mathrm{~B} 0.17 B模型,该模型在图6中以粉色显示。我们可以看到,一个 0.036 B 0.036 \mathrm{~B} 0.036 B模型可以在训练计算量适度增加(约4倍)的同时,匹配 0.17 B 0.17 \mathrm{~B} 0.17 B模型的性能,同时节省了大量的推理计算(Sardana & Frankle, 2023年)(每次推理调用节省约5倍),这表明了更好的推理-计算优化设置(Sardana & Frankle, 2023年)。
4.4、衰减阶段的分析
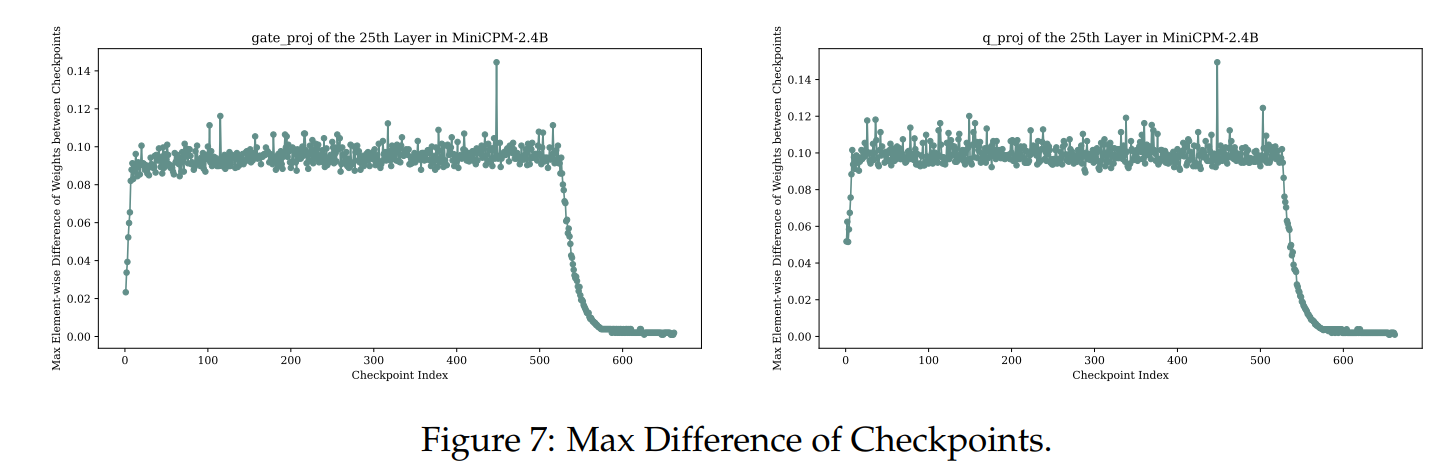
在本节中,我们通过对检查点更新和梯度信息的分析,简要探讨了衰减阶段损失下降的情况。我们计算了MiniCPM-2.4B(在第6节中介绍)中所有权重矩阵的最大权重元素更新量 max i j ( W i j ( t + 1 ) − W i j ( t ) ) \max _{i j}\left(W_{i j}^{(t+1)}-W_{i j}^{(t)}\right) maxij(Wij(t+1)−Wij(t))。如图7所示,这些更新量与学习率的大小呈现强烈的相关性。尽管图中仅展示了第25层的两个子模块(gate_proj和q_proj模块),但这种模式在网络中的每一层和每个子模块中都是普遍存在的。这一观察结果可能并不简单:在学习率衰减之前,模型检查点经历了显著的更新,但损失却几乎没有减少。相反,在衰减阶段,尽管权重变化的幅度较小,但损失却出现了加速下降。
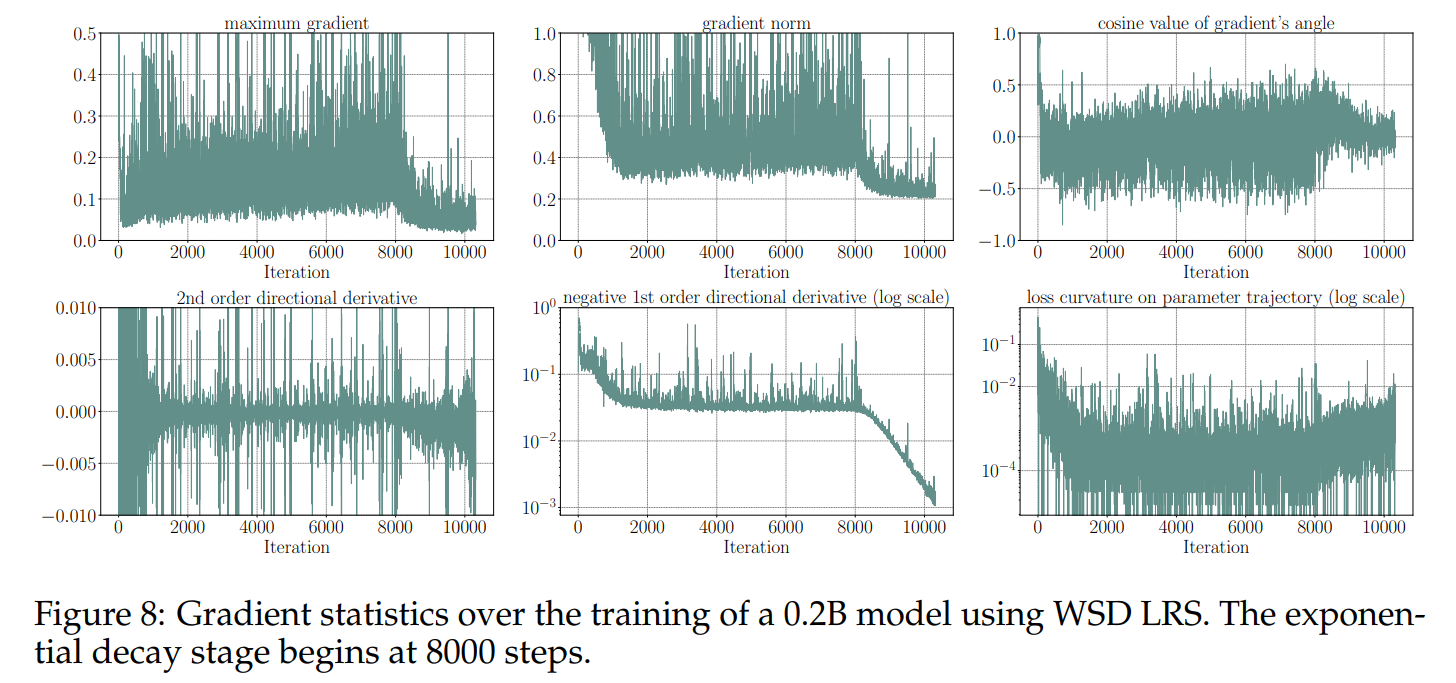
通过训练一个 0.2 B 0.2 \mathrm{~B} 0.2 B模型,我们对梯度数据进行了进一步的分析。我们仔细记录了每一步的梯度信息,并评估了连续步骤之间的差异,从而提供了二阶梯度信息的近似值。我们将第 t t t步的梯度视为一个扁平化向量 g ( t ) \mathbf{g}^{(t)} g(t),而第 t t t步和第 t + 1 t+1 t+1步之间的参数(也作为向量 x ( t ) \mathbf{x}^{(t)} x(t)扁平化)更新为 v ( t ) = x ( t + 1 ) − x ( t ) \mathbf{v}^{(t)}=\mathbf{x}^{(t+1)}-\mathbf{x}^{(t)} v(t)=x(t+1)−x(t)。梯度范数取梯度的 L 2 L_2 L2范数 ∥ g ( t ) ∥ \left\|\mathbf{g}^{(t)}\right\| g(t) ,梯度内积为 g ( t + 1 ) ⋅ g ( t ) \mathbf{g}^{(t+1)} \cdot \mathbf{g}^{(t)} g(t+1)⋅g(t),梯度的角度余弦由 g ( t + 1 ) ⋅ g ( t ) ∥ g ( t + 1 ) ∥ ∥ g ( t ) ∥ \frac{\mathbf{g}^{(t+1)} \cdot \mathbf{g}^{(t)}}{\left\|\mathbf{g}^{(t+1)}\right\|\left\|\mathbf{g}^{(t)}\right\|} ∥g(t+1)∥∥g(t)∥g(t+1)⋅g(t)给出。将优化过程想象成在高维流形上的轨迹,我们计算了沿轨迹的一阶方向导数 D 1 = g ( t + 1 ) ⋅ v ( t ) ∥ v ( t ) ∥ D_{1}=\frac{\mathbf{g}^{(t+1)} \cdot \mathbf{v}^{(t)}}{\left\|\mathbf{v}^{(t)}\right\|} D1=∥v(t)∥g(t+1)⋅v(t),以及二阶方向导数 D 2 = ( g ( t + 1 ) − g ( t ) ) ⋅ v ( t ) ∥ v ( t ) ∥ 2 D_{2}=\frac{\left(\mathbf{g}^{(t+1)}-\mathbf{g}^{(t)}\right) \cdot \mathbf{v}^{(t)}}{\left\|\mathbf{v}^{(t)}\right\|^{2}} D2=∥v(t)∥2(g(t+1)−g(t))⋅v(t)。 D 1 , D 2 D_1, D_2 D1,D2使得我们可以近似估计轨迹上的损失曲率,即 K = ∣ D 2 ∣ ( 1 + D 1 2 ) 3 2 K=\frac{\left|D_{2}\right|}{\left(1+D_{1}^{2}\right)^{\frac{3}{2}}} K=(1+D12)23∣D2∣。这些统计结果随时间的变化如图8所示。我们可以看到,在衰减阶段,梯度范数减小,并且在这一阶段开始时,梯度之间的余弦值主要呈现正值,这表明在衰减阶段,模型参数在步骤之间经历了持续的变化。关于方向导数,值得注意的是,一阶方向导数随着每一步的进行呈指数级减小,与学习率紧密对齐,而二阶方向导数的绝对值则略有增加。损失函数的曲率也增加了一个数量级,表明接近局部最优解。这些发现可能为优化空间的形状提供更深入的见解,这是一个未来探索的主题。
4.5、使用WSD LRS测量缩放定律
缩放定律在大型语言模型(LLMs)的开发中起着基本的指导原则作用。尽管由于不同模型系列之间的配置差异,这些缩放定律在特定系数上表现出可变性,但计算最优数据到模型的比率仍然是一个有意义的度量,它跨越了不同的缩放定律函数,从而“边缘化”了损失的具体值。关于这个比率,Kaplan等人(2020年)提出,模型规模增加十倍应等同于数据规模增加一倍。相反,Hoffmann等人(2022年)则主张模型大小和数据大小之间具有相同的缩放率。此外,当前的模型如LLama 2(Touvron等人,2023年)训练的数据量远超过Hoffmann等人(2022年)所声称的,但仍然获得了显著的性能提升,这表明了更高的数据到模型比率。
这种未解决的不确定性源于在传统缩放实验中训练多个不同大小和数据量的模型所面临的挑战。以前,如果在一个数据量上训练一个模型大小的平均成本是 C C C,那么使用 m m m个模型大小和 m m m个数据量进行缩放实验大约需要 O ( m 2 ) C O\left(m^{2}\right) C O(m2)C的成本。
在本节中,我们介绍了利用WSD调度器作为有效方法来探索具有线性成本 O ( m C ) O(m C) O(mC)的缩放定律。由于WSD调度器具有从任何步骤的稳定阶段检查点开始衰减后达到余弦LRS最优损失的优势,我们现在能够精确地测量最优缩放属性,而无需从头开始重新训练模型以适应不同的标记量,从而沿数据轴使缩放定律的测量更加高效。
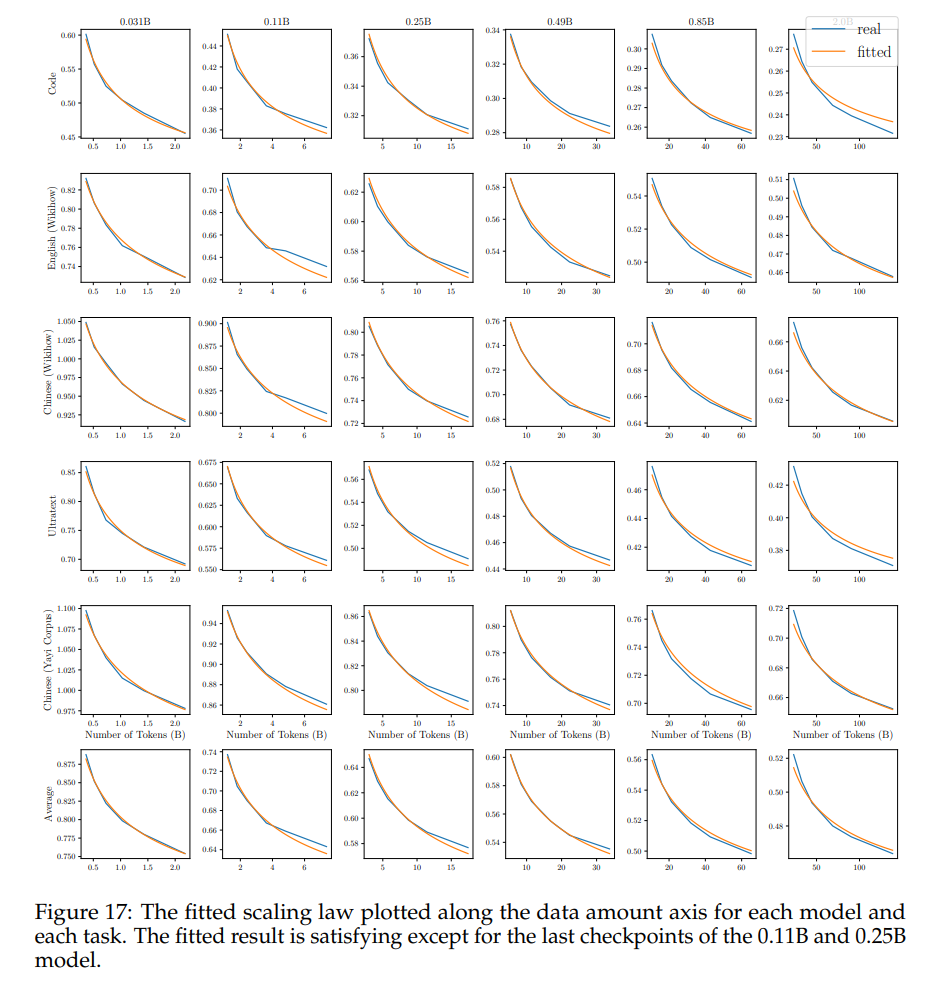
我们通过训练6种不同大小的SLMs(从小型0.04B到大型2B)来测量数据和模型轴上的缩放定律,每种大小都从稳定训练阶段的检查点开始,训练6个从10N到60N数据的衰减模型。最终损失在五个保留的评估数据集上进行评估。为了潜在地比较模型使用不同分词器时的损失,我们按照Achiam等人(2023年)的方法,使用字节数而不是标记数来计算损失的平均值。每个数据大小和模型大小对的最终损失在图17中用蓝色线表示。
然后,我们按照Hoffmann等人(2022年)的方法,使用scipy的curvefit函数,根据模型大小 N N N和数据大小 D D D来拟合损失:
L ( N , D ) = C N N − α + C D D − β + L 0 L(N, D) = C_{N} N^{-\alpha} + C_{D} D^{-\beta} + L_{0} L(N,D)=CNN−α+CDD−β+L0
每个数据集和每个检查点沿数据轴的拟合曲线在图17中用橙色线表示。然后,在给定固定计算量 C = 6 N D C=6ND C=6ND(Rae等人,2021年)的情况下,我们有最优模型大小 N opt N_{\text{opt}} Nopt和数据集大小 D opt D_{\text{opt}} Dopt:
N opt D opt = K 2 ( C 6 ) η \frac{N_{\text{opt}}}{D_{\text{opt}}} = K^{2}\left(\frac{C}{6}\right)^{\eta} DoptNopt=K2(6C)η
其中, K = ( α C N β C D ) 1 α + β K = \left(\frac{\alpha C_{N}}{\beta C_{D}}\right)^{\frac{1}{\alpha+\beta}} K=(βCDαCN)α+β1,且 η = β − α α + β \eta = \frac{\beta-\alpha}{\alpha+\beta} η=α+ββ−α。 N opt N_{\text{opt}} Nopt的推导与Hoffmann等人(2022年)类似,通过在等式2中将 D D D替换为 C 6 N \frac{C}{6N} 6NC,并在给定 C C C的情况下最小化 L ( N ) L(N) L(N)。类似的方法也被用于 D opt D_{\text{opt}} Dopt。从等式3中,当 α = β \alpha=\beta α=β时, N opt / D opt N_{\text{opt}}/D_{\text{opt}} Nopt/Dopt是一个常数,这支持了Hoffmann等人(2022年)的主张;而当 α < β \alpha<\beta α<β时,我们应该更多地强调参数缩放(Kaplan等人,2020年),反之亦然。
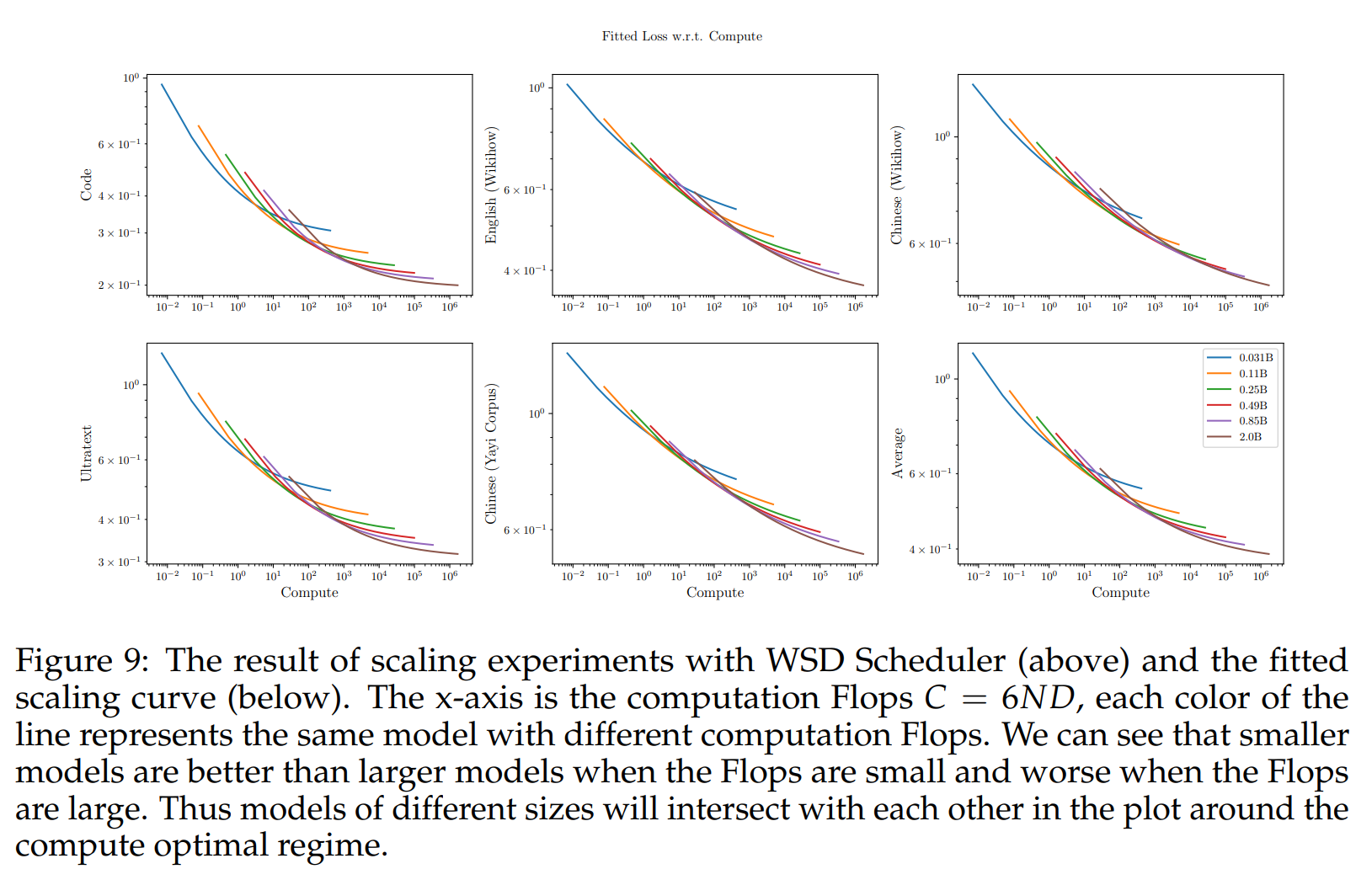
在我们的实验中,损失与 N N N(模型大小)、 D D D(数据大小)之间的拟合关系显示在图10的等损失等高线图中。每个子图中的第一个文本框显示了拟合缩放定律的方程。我们可以看到,在所有评估语料库中,我们都有 β < α \beta<\alpha β<α。更具体地说,平均而言,我们得到 α = 0.29 \alpha=0.29 α=0.29, β = 0.23 \beta=0.23 β=0.23, K 2 = 0.01 K^{2}=0.01 K2=0.01, η = − 0.10 \eta=-0.10 η=−0.10。由于 α \alpha α略大于 β \beta β,这一结果表明在计算规模上,我们应该稍微更强调数据缩放而不是模型缩放,这与Hoffmann等人(2022年)的研究结果相一致。
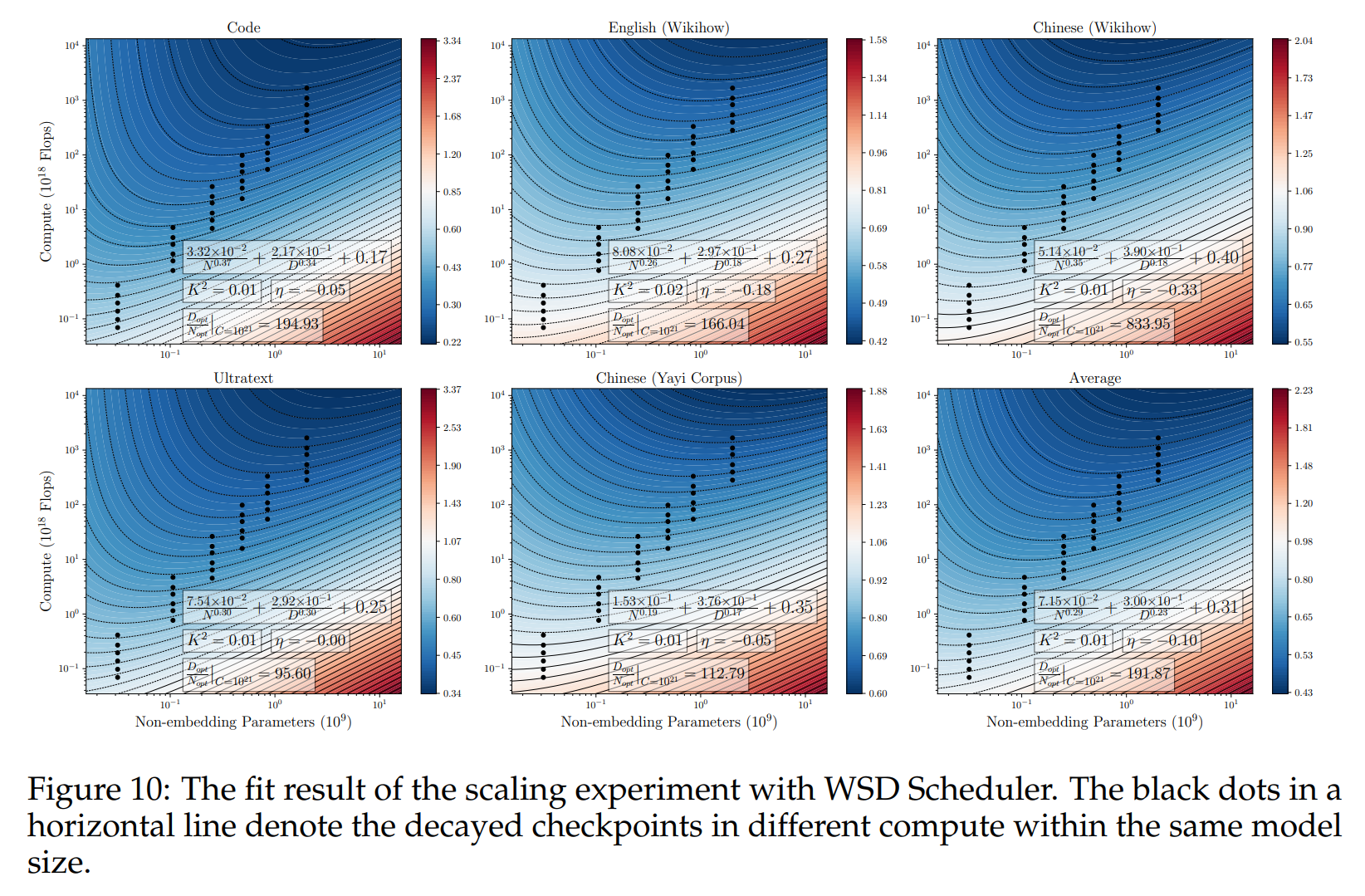
至于具体的数据与模型比例 D opt N opt \frac{D_{\text{opt}}}{N_{\text{opt}}} NoptDopt,我们注意到我们的结果与Hoffmann等人(2022年)在计算最优区域内的差距很大,尽管我们与他们之间关于 D opt ′ N opt \frac{D_{\text{opt}}'}{N_{\text{opt}}} NoptDopt′随计算量 C C C变化的趋势是一致的。具体来说,平均而言,数据大小应该是模型大小的192倍,而Hoffmann等人(2022年)的结果是20倍。我们注意到这与第4.3节和图6中的观察结果一致。
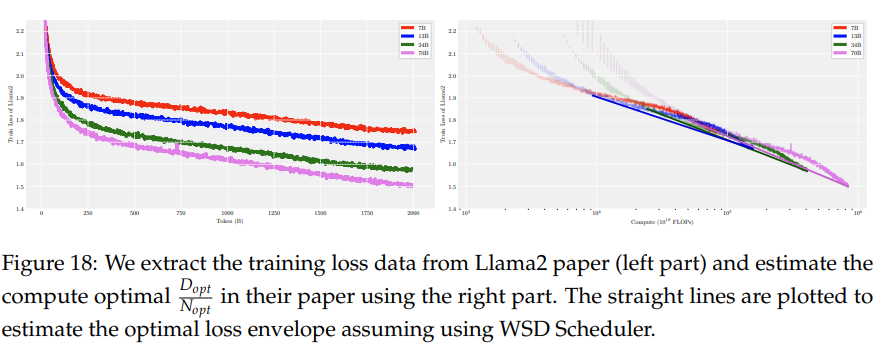
关于与Chinchilla最优 N opt D opt \frac{N_{\text{opt}}}{D_{\text{opt}}} DoptNopt 的较大偏差,我们注意到他们的缩放实验是在不太近的配置下进行的。为了与更近期的配置(如Llama2,Touvron等人,2023年)进行比较,我们从Llama2论文中提取了训练损失数据(附录图18的左部分),并使用图18的右部分来估计他们论文中的计算最优 D opt N opt \frac{D_{\text{opt}}}{N_{\text{opt}}} NoptDopt。由于他们使用了余弦学习率调度(Cosine LRS),训练过程中的损失在中期并不是最优的,这由图18右图中的凹形曲线所描绘。我们用一条直线填充凹形部分来估计如果他们使用权重标准化衰减(WSD LRS)的最优损失包络线。之后,计算模型大小应该大致是模型损失曲线即将与更大模型的损失曲线相交的区间。基于这种直觉, 13 B 13 \mathrm{~B} 13 B 模型在 1 0 5 10^{5} 105 EFlops( 1 0 18 10^{18} 1018 Flops)时即将与 34 B 34\mathrm{~B} 34 B 模型相交,而 34 B 34 \mathrm{~B} 34 B 模型在 5 × 1 0 5 5 \times 10^{5} 5×105 EFlops 时即将与 70 B 70 \mathrm{~B} 70 B 模型相交。因此,我们估计 D opt N opt \frac{D_{\text{opt}}}{N_{\text{opt}}} NoptDopt 大致为 5 × 1 0 5 6 × 3 4 2 ∼ 1 0 5 6 × 1 3 2 \frac{5 \times 10^{5}}{6 \times 34^{2}} \sim \frac{10^{5}}{6 \times 13^{2}} 6×3425×105∼6×132105,即 70 ∼ 100 70 \sim 100 70∼100。因此,在这种近似比较下,他们的数据-模型比例更接近我们的。与之前的配置相比,我们的配置可以将更多的数据吸收到较小的模型中。然而,我们注意到上述估计只是粗略的。
一个较大的数据到模型的比例意味着我们可以将更多的数据吸收到较小的模型中,这比我们先前的想法更为高效,对于推理和部署来说也更为有利。我们希望权重标准化衰减(WSD LRS)能帮助更多研究者更轻松地探索 L ( N , D ) L(N, D) L(N,D),并使大型语言模型(LLMs)中的这种关系更加清晰。
5、两阶段预训练策略
通常,遵循指令的大型语言模型(LLMs)的训练包含预训练阶段和监督微调(SFT)阶段(Zhang等人,2023;Wei等人,2021)。在预训练阶段,数据由大规模未标记数据组成,而在SFT阶段,高质量标记数据成为优化目标。鉴于在WSD LRS的衰减阶段观察到的显著损失下降,我们推测在这一阶段融入高质量标记数据具有双重优势:
- 除了在SFT阶段引入这些数据外,在退火阶段引入这些数据有助于模型进行更全面的学习。具体来说,它促进了与SFT数据分布相关的更显著的损失减少,而不是与预训练数据分布相关。这种方法更符合实际用户场景。
- 与在整个预训练过程中均匀分布高质量数据的方法相比,这种方法通过集中数据和持续预训练来增强训练。如果我们不预先确定训练步骤,我们会在持续的预训练过程中重复小数据集,这可能导致负面影响。
基于这两个假设,我们提出以下训练策略:在预训练阶段,仅使用大规模、粗质量的预训练数据,这种数据是丰富的,并且在提供更多计算资源的情况下可以支持持续训练。在退火阶段,我们使用多样化和高质量的知识和能力导向的SFT数据,将其混入预训练数据中。
为了验证我们训练策略的优势,我们进行了对比实验,使用了(A)MiniCPM-2.4B在稳定阶段的中间检查点;(B)MiniCPM1.2B在稳定阶段的最后检查点。具体来说,我们比较了以下情况:
- A-1:2.4B模型,仅使用预训练数据进行衰减,之后进行 4 B 4 \mathrm{~B} 4 B标记的SFT。
- A-2:2.4B模型,在衰减阶段使用上述高质量的无标签数据和SFT数据混入预训练数据,之后也进行 4 B 4 \mathrm{~B} 4 B标记的SFT。
- B-1:1.2B模型,仅使用预训练数据进行衰减,之后进行 6 B 6\mathrm{~B} 6 B标记的SFT。
- B-2:1.2B模型,仅使用预训练数据进行衰减,之后进行 12 B 12\mathrm{~B} 12 B标记的SFT。
- B-3:1.2B模型,在退火阶段使用上述高质量数据+SFT数据混入预训练数据,之后也进行 6 B 6\mathrm{~B} 6 B标记的SFT。
实验的结果如表1所示。我们可以看到,尽管A-2和A-1经历了相同的SFT分布,但在衰减阶段添加SFT数据推动了边界。B-2和B-3之间的比较表明,仅进行SFT的不足并不是由于SFT阶段训练标记的不足造成的。
结果显示,在衰减阶段开始时引入高质量数据的益处远高于仅在SFT阶段添加这些数据。因此,我们建议模型能力的专业化和增强应该从衰减阶段开始。
6、模型
本节开始介绍融合了上述观察和技术的MiniCPM模型。
6.1、模型细节
词汇表。对于MiniCPM-2.4B,我们使用两个标记器,词汇表大小为122,753;对于MiniCPM-1.2B,我们使用词汇表大小为73,440。对于1.2B模型,使用较小的词汇表有利于提高效率,同时不会对性能造成太大损害。标记器的详细信息见附录C。包括嵌入参数后,总参数分别增加了 0.3 B 0.3 \mathrm{~B} 0.3 B和 0.2 B 0.2 \mathrm{~B} 0.2 B。
共享输入输出层。对于序列到序列模型(SLM),嵌入层占据了很大的参数空间。为了减小模型参数,我们在MiniCPM-2.4B和MiniCPM-1.2B中都使用了嵌入共享技术。
深且窄的网络。在训练MiniCPM-1.2B之前,我们先训练了MiniCPM-2.4B。在训练MiniCPM-2.4B时,我们采用了比Phi-2(Javaheripi & Bubeck, 2023)更深且更窄的架构(40层相比32层)。最近,Liu等人(2024)提出为SLM训练深且窄的网络,这与我们的观点一致。因此,我们进一步为MiniCPM-1.2B设计了更深且更窄的架构。
分组查询注意力。我们在不修改注意力层的情况下训练了MiniCPM-2.4B。然而,受Liu等人(2024)的启发,我们在MiniCPM-1.2B上应用了分组查询注意力(Group Query Attention,Ainslie等人,2023),以进一步减少参数数量。
6.2、训练阶段
MiniCPM基础模型的整体训练包括三个阶段:稳定训练阶段、衰减阶段、SFT阶段(Zhang等人,2023;Wei等人,2021)。在整个训练过程中,我们都使用Adam优化器(Kingma & Ba, 2014)。
稳定训练阶段。我们使用了大约1T的数据(数据分布见第11节),其中大部分数据来源于公开数据集。我们使用在模型风洞实验中发现的最佳配置WSD LRS,批量大小为393万,最大学习率为0.01。
衰减阶段。我们使用了预训练数据和高质量SFT数据的混合。对于WSD调度器的特定退火形式,我们采用了指数退火,即 f ( s − T ) = 0. 5 ( s − S ) / T f(s-T)=0.5^{(s-S) / T} f(s−T)=0.5(s−S)/T,其中 T T T被设置为5000步(200B标记)。
SFT阶段。我们发现仍然有必要进行单独的SFT阶段。我们使用与退火阶段类似但不包括预训练数据的SFT数据,并使用大约60亿标记进行训练。SFT的学习率与退火结束时的学习率保持一致,并且也使用了具有指数衰减的WSD调度器。
6.3、训练数据分布
我们在图11中介绍了我们的训练数据分布。在图中,中文语料库中的CommonCrawl_Chn来源于CommonCrawl原始语料库,并经过了彻底的清洗。Dolma(Soldaini等人,2024)、C4(Raffel等人,2019)和Pile(Gao等人,2020;Biderman等人,2022)是英文语料库。它们使用MinHash算法(Broder,1997)在语料库内部和跨语料库进行了去重。代码预训练数据包含stack(Kocetkov等人,2022)和StarCoder(Li等人,2023a),同样进行了内部去重和跨语料库去重。在衰减阶段,数据混合包含了更多样化的数据和专有数据,包括UltraChat(Ding等人,2023)、SlimOrca(Lian等人,2023a;b)、OssInstruct(Wei等人,2023)和EvolInstruct(Xu等人,2023)。带有SFT后缀的数据是我们的专有数据,包括LeetCode问题、幼儿园到12年级(K12)的教科书和题目等。
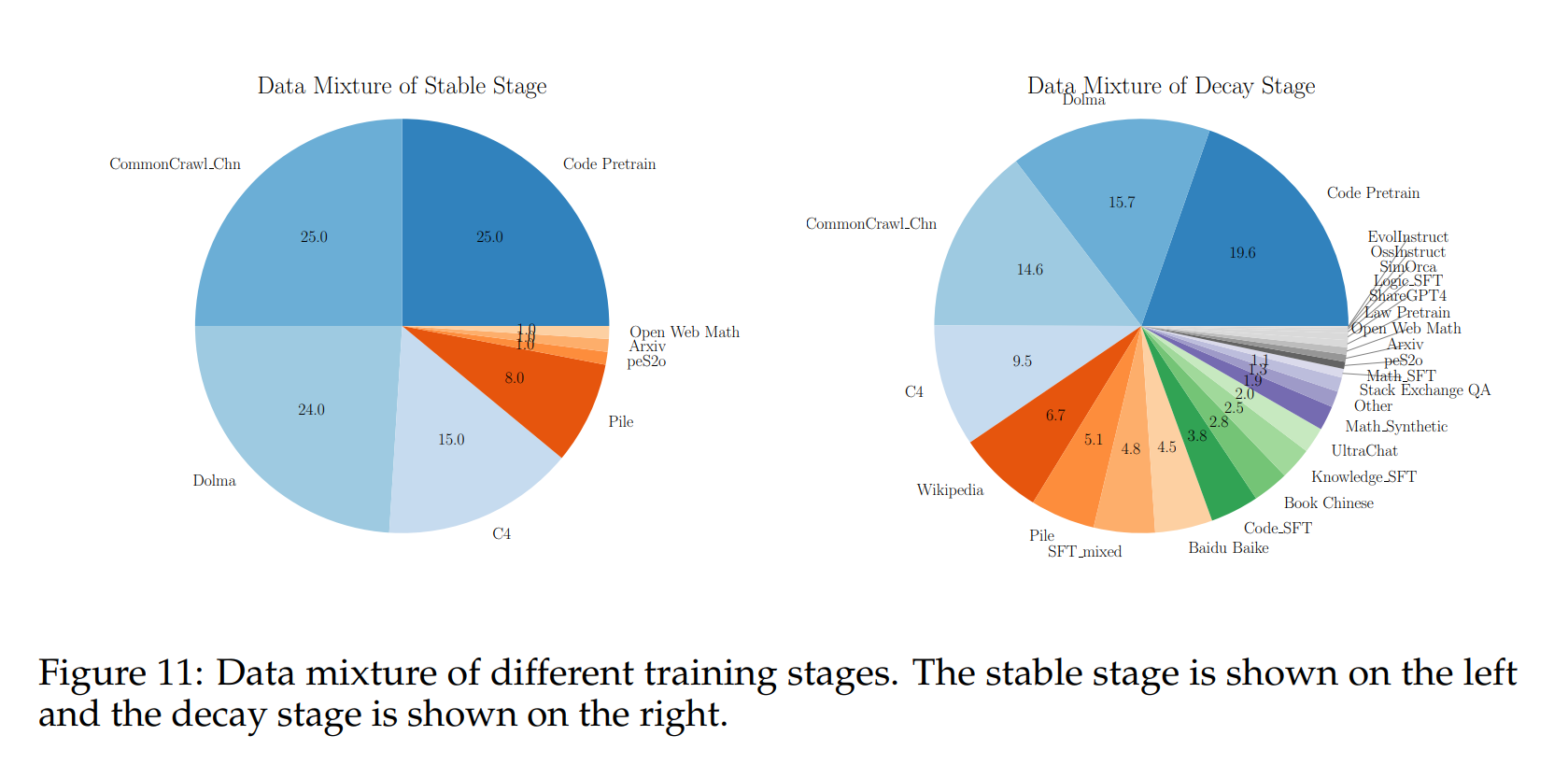
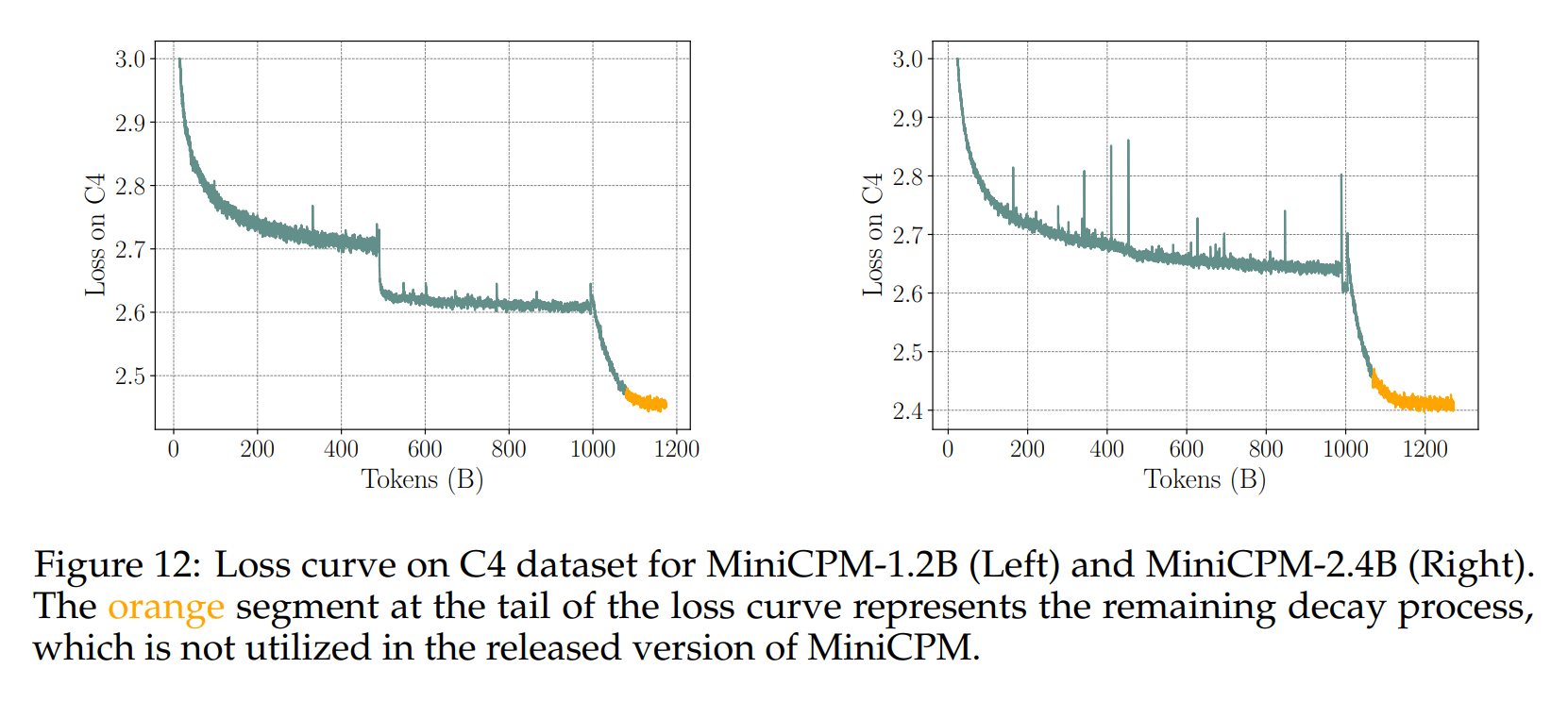
图12展示了C4数据集上的整体训练损失。我们可以看到,正如在初步实验中所预期的那样,在衰减阶段损失急剧下降。由于我们使用了指数衰减,即使学习率下降到最大学习率的 10 % 10\% 10%以下,损失仍然继续下降。然而,由于我们在衰减阶段之后继续对模型进行SFT(Supervised Fine-Tuning),我们并没有使用最终的检查点。我们从暗绿色段的最后一个检查点开始微调。MiniCPM-1.2B中的第一次下降是由于增大了批量大小,这可能与降低学习率有类似的效果(Smith等人,2017)。
6.5、评估
整体评估利用了我们的开源工具UltraEval 3 {}^{3} 3。UltraEval是一个用于评估基础模型能力的开源框架。它提供了一个轻量级且用户友好的评估系统,支持主流大型模型的性能评估,并满足模型训练团队的快速评估需求。其底层的推理和加速使用了开源框架vLLM(Kwon等人,2023),并且数据集包括了一些常用的数据集:MMLU(Hendrycks等人,2020)用于英语知识评估,CMMLU(Li等人,2024)和C-Eval(Huang等人,2024)用于中文知识评估,HumanEval(Chen等人,2021)和MBPP(Austin等人,2021)用于编程能力评估,GSM8K(Cobbe等人,2021)和MATH(Hendrycks等人,2021)用于数学能力评估,HellaSwag(Zellers等人,2019)、ARC-e(Clark等人,2018)和ARC-c(Clark等人,2018)用于常识推理能力评估,以及BBH(Suzgun等人,2022)用于逻辑推理能力评估。
在测试问答任务(ARC-e、ARC-c、HellaSwag)时,通常使用两种方法。第一种方法涉及使用困惑度(Perplexity, PPL):我们将每个选项作为问题的延续,并使用选项的PPL作为选择标准。第二种方法是直接生成,模型直接输出答案选项。我们观察到使用这两种方法得到的结果存在显著差异。MiniCPM在直接生成和PPL测试中表现相似,且在直接生成中表现更好。另一方面,Mistral-7B-v0.1在PPL测试中表现更好,但在直接生成中表现较差。为了解决这一现象,在报告每个模型的分数时,我们采用了产生最高分数的评估方法的分数,以确保比较的公平性。
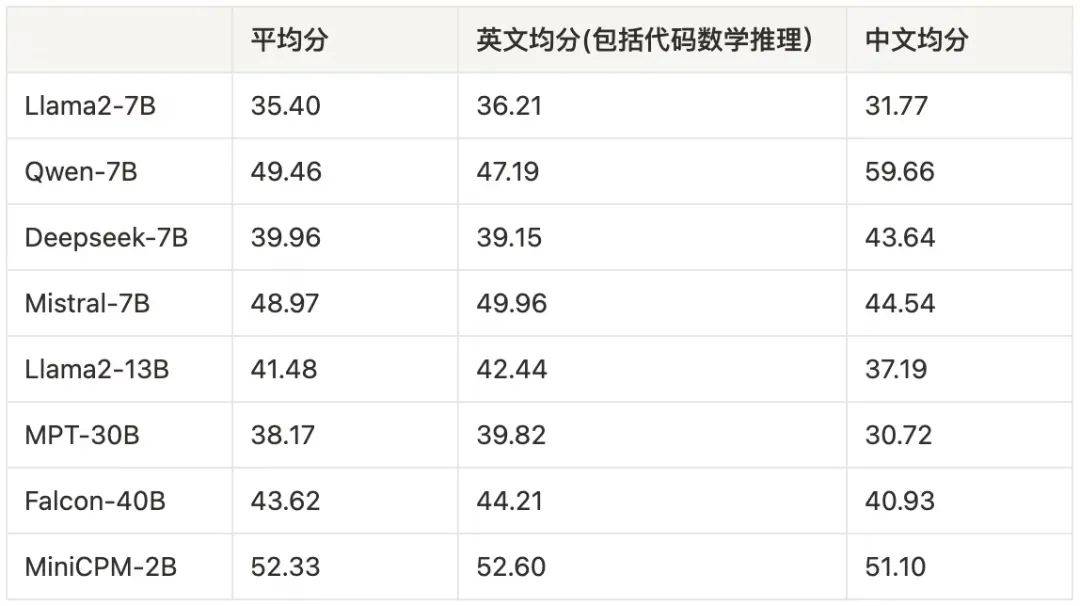
整体评估结果如表4所示。总体而言,在提到的数据集上,我们观察到以下几点。(1) 平均而言,MiniCPM-2.4B在所有SLM(小型语言模型)中排名第一。(2) MiniCPM-2.4B在英语上表现与Mistral-7B-v0.1相似,但在中文上显著优于Mistral-7B-v0.1。(3) MiniCPM-2.4B在MMLU、BBH和HellaSwag之外的数据集上都优于Llama2-13B,而MiniCPM-1.2B在HellaSwag之外的数据集上都优于Llama2-7B。(4) 一般来说,与其他知识导向的数据集相比,BBH对SLM来说比LLM更难,这表明推理能力可能更依赖于模型大小而不是知识。(5) 在SLM中,Phi-2在面向学术的数据集上的表现与MiniCPM相当。这可能是因为它们的训练数据主要涉及强调教育和学术场景的教科书式数据。由于我们的预训练数据覆盖了更广泛的分布,我们认为MiniCPM在知识和能力覆盖方面表现更好,这在附录F中可以看到。
7、MiniCPM系列
在本节中,我们将介绍基于MiniCPM基础模型构建的其他模型。具体来说,我们为MiniCPM 2.4B训练了对齐模型、长上下文模型和MoE模型。
7.1、MiniCPM-DPO
在SFT之后,我们采用DPO(Rafailov等人,2024)进行模型的人类偏好对齐。在此阶段,UltraFeedback(Cui等人,2023)被用作主要的对齐数据集,并构建了一个专有的偏好数据集,以增强模型的代码和数学能力。我们进行了一个周期的DPO训练,学习率为 1 × 1 0 − 5 1 \times 10^{-5} 1×10−5,由于我们有预定义的训练步骤,因此使用了Cosine LRS。
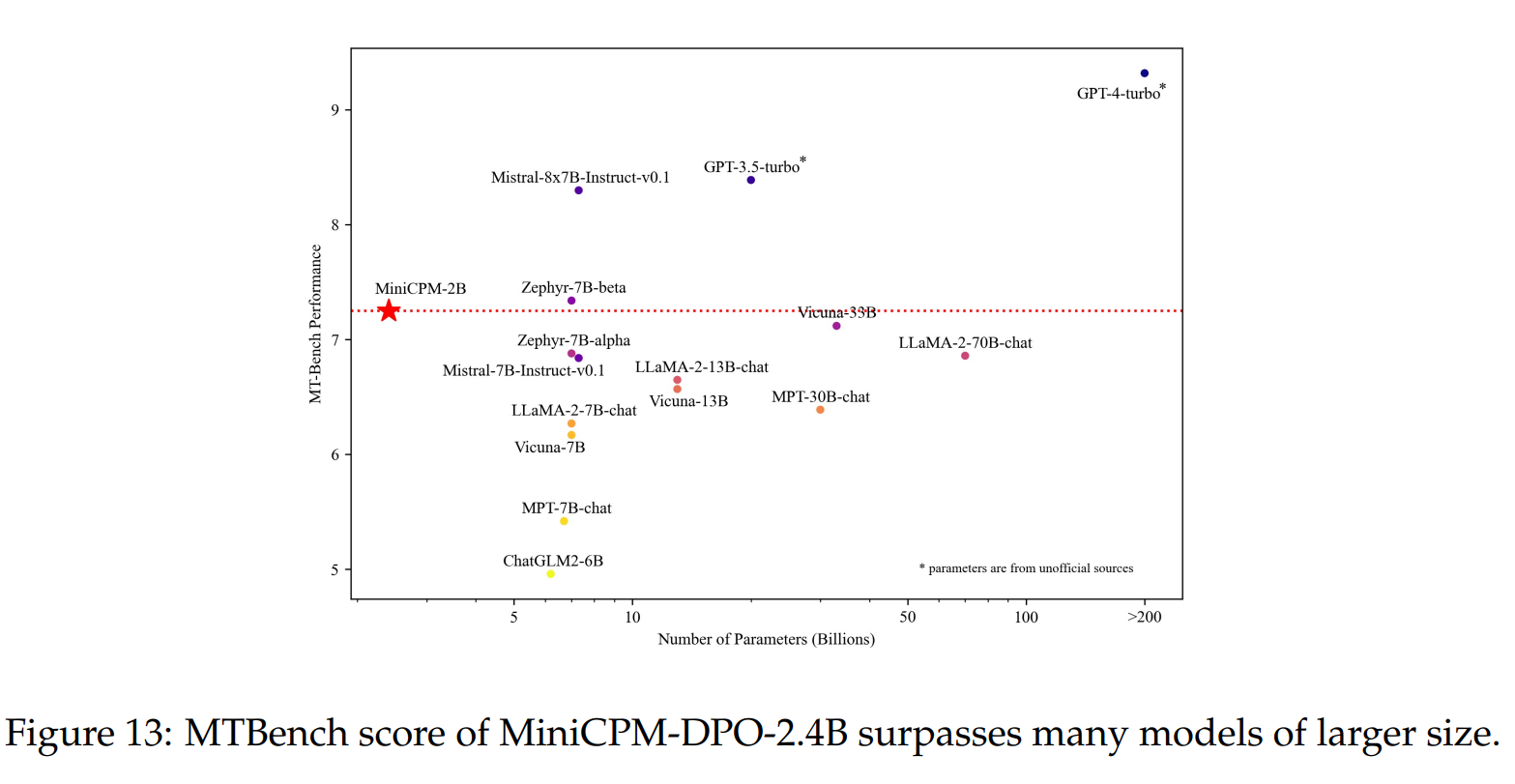
在应用DPO进行偏好对齐后,模型在MTBench(Zheng等人,2024)上的得分从SFT后的6.89提高到7.25,甚至超过了像Llama270B-Chat这样的大型模型(见图13)。然而,我们也注意到基准测试的性能略有下降,这被称为对齐税(Askell等人,2021)。
7.2、MiniCPM-128K
涉及冗长上下文的任务依赖于这些上下文中的隐含信息,从而避免了小型语言模型中通常缺乏的广泛知识。在本节中,我们将MiniCPM-2.4B的上下文长度从4,096扩展到128,000个标记,展示了小型语言模型有效处理长上下文的能力。
初始化。在初始化过程中,我们禁用了输入和输出之间的嵌入共享,主要是为了适应长上下文训练所需的词汇并行性。LM头是从输入嵌入初始化的。
训练。与MiniCPM类似,MiniCPM-2.4B-128K采用WSD作为其学习率调度器,并重用MiniCPM-2.4B稳定训练阶段的最后一个检查点。关于训练数据,我们将第6.3节中详细描述的数据集分布分为“短数据”和“长数据”。我们将书籍、维基百科和论文归类为“长数据”,其他则归类为“短数据”。训练包括 44 % 44\% 44%的长数据和 56 % 56\% 56%的短数据,用于继续训练。对于长上下文的扩展,我们在 4 K 4 \mathrm{~K} 4 K到 32 k 32 \mathrm{k} 32k的范围内应用了Adjusted Base Frequency (ABF)(Xiong等人,2023),并在 32 K 32 \mathrm{~K} 32 K到 128 K 128 \mathrm{~K} 128 K的范围内采用了NTK-Aware RoPE Scaling(bloc 97,2023)和课程学习。这两个阶段都涉及未来的训练。此外,如Yi Tech Report(Young等人,2024)和Zebra(Song等人,2023)所示,我们使用了合成的长QA数据,这显著提高了模型在上下文感知任务中的性能。
评估。我们在 ∞ \infty ∞ Bench(Zhang等人,2024b)上评估了MiniCPM-2.4B-128K,这是一个针对长上下文评估的开创性基准。 ∞ \infty ∞ Bench(Zhang等人,2024b)中的任务超越了典型的检索任务,并通过长上下文推理挑战模型。从表5中我们可以看到,我们在Mistral-7B-Instruct-v0.2 (ABF1000w)上取得了相当的结果,并且尽管比ChatGLM3-6B-128K小2.5倍,但表现更好。
7.3 MiniCPM-MoE
我们进一步使用混合专家(Mixture-of-Expert, MoE)扩展了MiniCPM的能力。
初始化。MiniCPM-MoE通过Sparse Upcycling(Komatsuzaki等人,2022)进行初始化。从MiniCPM稳定阶段获得的密集模型检查点经历了一个转换过程,其中每个MLP层都被一个MoE层所替代。这些新的MoE层是密集检查点中原始MLP层的精确副本。路由器参数按照均值为0、方差为0.01的正态分布进行随机初始化。
路由机制。MiniCPM-MoE的总非嵌入参数数量为13.6B。在训练和推理过程中,每个标记激活了八个专家中的两个,导致激活的参数数量大约为4B。为了防止训练崩溃,我们在最终的训练目标上应用了一个额外的负载均衡损失(Fedus等人,2022)。这个辅助损失乘以0.01,这个值足够大,可以确保分配给不同专家的标记分布均衡。
训练。与MiniCPM类似,我们采用WSD作为学习率调度器。关于训练数据,我们严格遵循第6.3节中指定的分布。在稳定训练和衰减阶段,训练批次大小保持在4M标记,并在SFT阶段减少到2M标记。预训练阶段(包括继续预训练和衰减阶段)持续了130K步,之后我们注意到改进开始减少。基准测试的结果详见表6。
8、结论
本文介绍了MiniCPM,它包含两个非嵌入参数分别为2.4B和1.2B的SLM(序列到序列模型)。这些模型相较于其更大的同类模型表现出了优越的性能。我们的训练方法在模型和数据规模上都是可扩展的,为开发大型语言模型(LLMs)提供了潜在的适用性。我们引入的WSD调度器在促进持续训练、展现引人注目的训练动态以及有效研究缩放定律方面表现显著。此外,我们还介绍了MiniCPM家族,包括DPO(数据并行优化)、长上下文和MoE(混合专家)版本。未来的研究方向包括深入分析衰减阶段的损失减少情况,以及通过同时扩展模型大小和数据规模来增强MiniCPM的能力。
作者贡献
所有作者都对MiniCPM项目做出了实质性贡献。盛鼎胡(Shengding Hu)领导和参与了项目的各个方面。这包括缩放实验(与涂宇格(Yuge Tu)一起进行)、监管MiniCPM基础模型的训练,以及为研究的其他部分做出贡献。盛鼎胡撰写了本文。何超群(Chaoqun He)负责评估MiniCPM,而崔甘曲(Ganqu Cui)负责RLHF(Reinforcement Learning from Human Feedback)训练。龙翔(Xiang Long)、郑智(Zhi Zheng)、张新荣(Xinrong Zhang)和盛鼎胡将上下文窗口扩展到128K。MoE(混合专家)研究由方业伟(Yewei Fang)和郑智进行。赵伟林(Weilin Zhao)和张凯华(Kaihuo Zhang)为训练和推理基础设施做出了贡献。黄玉祥(Yuxiang Huang)和盛鼎胡为MiniCPM的开源准备了工作。盛鼎胡与赵晨阳(Chenyang Zhao)还对WSD调度器的训练动态进行了分析。郑冷泰(Zheng Leng Thai)开发了分词器。MiniCPM-V的开发由王重义(Chongyi Wang)和姚远(Yuan Yao)进行。MiniCPM的训练语料库由周杰(Jie Zhou)、蔡杰(Jie Cai)、盛鼎胡、郑智和翟中武(Zhongwu Zhai)准备。张新荣和何超群对本文进行了校对。徐涵(Xu Han)、丁宁(Ning Ding)和刘知远(Zhiyuan Liu)为MiniCPM的训练提供了深入的指导。最后,刘知远、孙茂松(Maosong Sun)、曾国阳(Guoyang Zeng)、贾超(Chao Jia)和李大海(Dahai Li)为MiniCPM的训练提供了必要的资源。
限制
尽管我们已经对使用序列到序列模型(SLMs)的缩放定律进行了全面的研究,但本文并未扩展到训练大型语言模型(LLMs)以验证缩放定律。目前,关于在LLMs上应用WSD学习率调度器(WSD LRS)的研究尚未完全展开。然而,我们仍然对其潜在的优势持乐观态度。
致谢
MiniCPM最初于2024年2月1日作为一篇技术博客发布。自那时以来,我们收到了来自社区的众多深入见解的反馈,这些反馈对本论文的发展做出了重大贡献。我们感谢周春婷(Chunting Zhou)和亚美·阿加哈扬(Armen Aghajanyan)与他们进行的宝贵讨论。特别感谢孙培琴(Peiqin Sun)和王岩(Yan Wang)对博客中模糊之处的细致反馈,帮助我们澄清。此外,我们感谢开源社区在将MiniCPM集成到如llama.cpp等推理框架中的努力。
A、模型风洞实验中的额外结果
A.1、μP超参数搜索
我们在一组预定义的参数空间上进行了广泛的贝叶斯搜索。为了提高效率,我们针对 N=0.009B 的模型进行了搜索。在我们的初步实验中,我们确认当使用放大10N和20N倍的数据集进行超参数优化时,超参数的有效性是一致的。因此,我们使用 |D|=10N=0.09B 的标记量来训练模型。同时,我们也尝试了QK-Norm(Henry et al., 2020)和独立权重衰减(Loshchilov & Hutter, 2017)来稳定学习率。整体结果如图14所示。
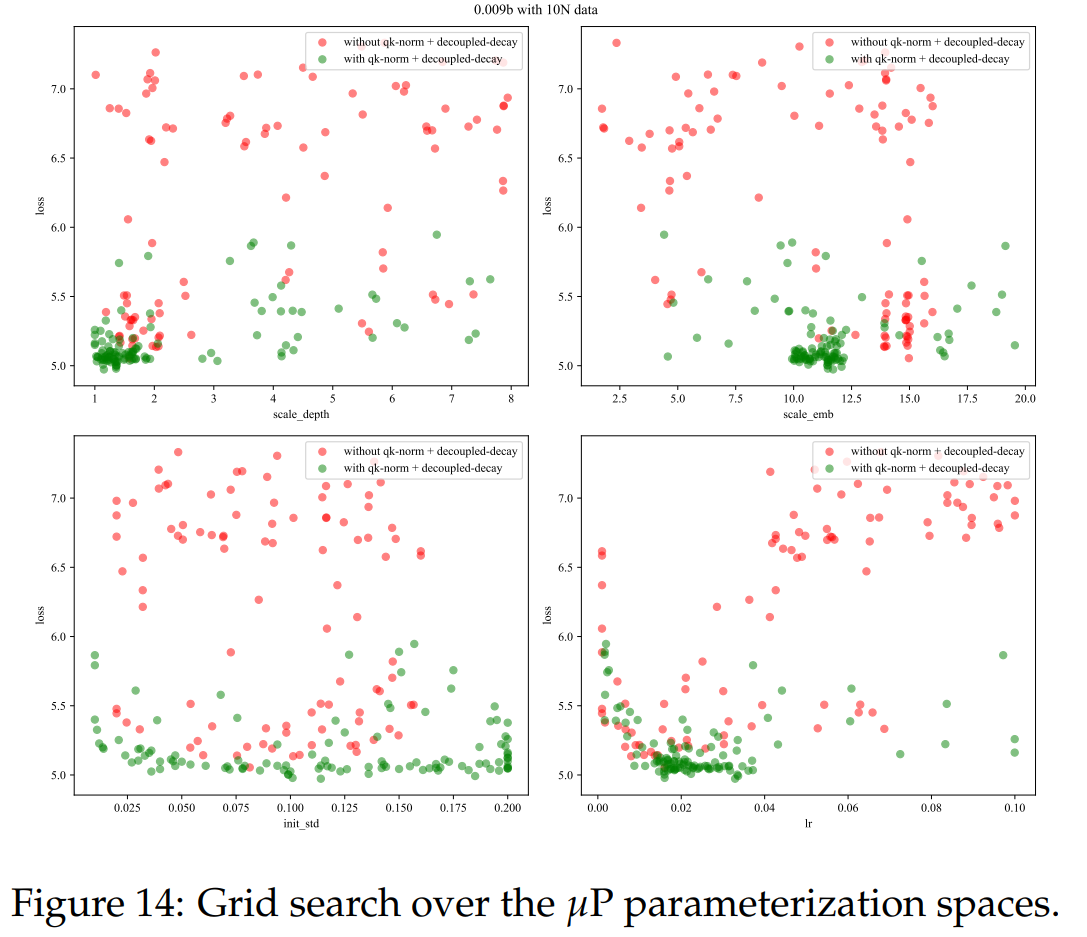
在应用QK-Norm后,我们观察到学习率敏感性显著降低,这与Wortsman等人(2023)的结果类似。然而,由于MiniCPM项目本身是一个序列到序列模型(SLM),我们不需要像TensorProgram(Yang et al., 2022; 2023)那样寻找最低学习率敏感性,只要我们能找到最佳学习率即可。因此,在后续的MiniCPM实验中,我们没有引入QK-Norm和独立权重衰减。在图14中,我们确定了最佳的超参数为 scale_depth=1.4, scale_emb=12, init_std=0.1, 和 lr=0.01。
A. 2、关于最佳批处理大小的讨论
在Kaplan等人(2020)的研究中,OpenAI探讨了损失函数与标记数量之间的关系。在他们的实验中,他们假设消耗更多的步骤等同于消耗更多的时间。基于这个假设,OpenAI定义了一个关键的批处理大小,该大小可以在不消耗过多步骤或标记的情况下达到一定的损失。如果实验中有无限的GPU资源(至少在实验范围内),这个推理是有效的。由于GPU资源是无限的,增加批处理大小不会增加单步时长,但会减少总步骤数。然而,在我们的实验中,由于我们拥有固定的资源(GPU数量),我们观察到,将批处理大小加倍几乎等同于将单步时间加倍。因此,通过增加批处理大小来减少总训练步骤对总训练时间的影响微乎其微。鉴于这一观察,我们放弃了“不消耗过多步骤”的目标,转而致力于通过最小化标记数量来实现最低损失。
关于损失与估计最佳批处理大小之间的观察类似于“先有鸡还是先有蛋”的悖论。在实践中,对于给定的模型大小,通常有一个基于初步实验先验知识的可实现损失的初步估计。然而,未来有可能发展出更精细的估计程序。
最佳批处理大小和最佳学习率可能不是独立的。为了克服这种相关性,我们首先对学习率进行初步研究,然后选择最佳学习率进行批处理大小实验,并使用批处理大小缩放再次进行学习率实验。这有点像坐标下降优化方法。然而,未来的工作中欢迎更严格的方法。
A. 3、模型风洞实验中的模型架构
我们在表8中列出了模型风洞实验中所使用的模型配置。"模型"的形状,即模型宽度与模型深度的比例,尽可能保持相似,以避免任何潜在的性能变化。
B 关于WSD LRS的额外说明
B.1、不同LRS的学习率范式
在本文中,我们描述了三种LRS(学习率调度器),即Cosine ( T ) (T) (T),CosineLoop ( T ) (T) (T) 和 W S D ( T , D ) WSD(T, D) WSD(T,D)。Cosine和Cosine Loop的形式如下所述:
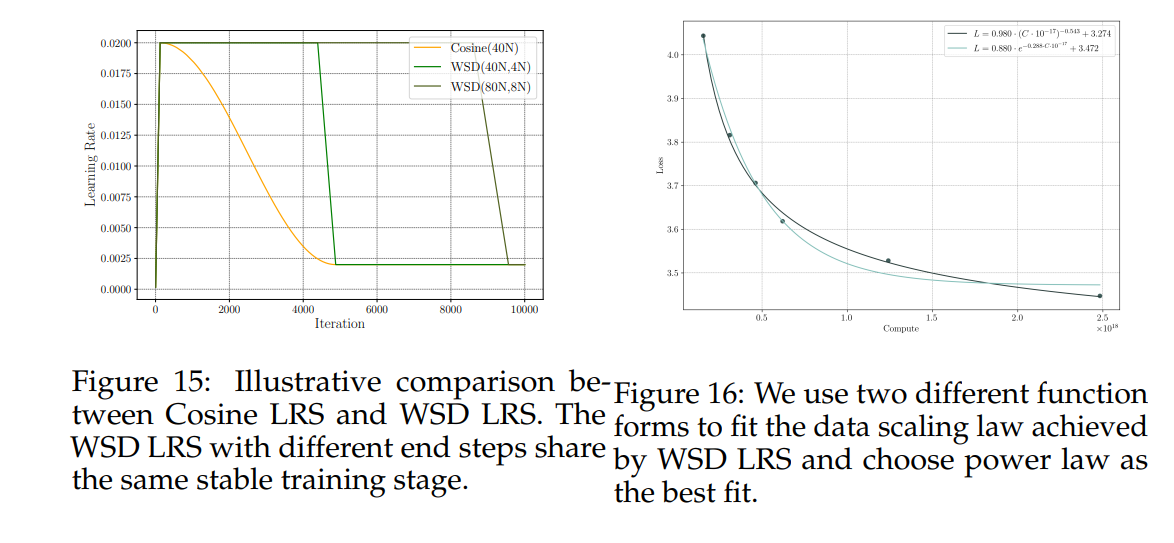
图15展示了WSD和Cosine调度器的学习率示意图。
B.2 拟合数据缩放定律
在本节中,我们描述了使用WSD LRS进行继续训练时拟合的数据缩放定律。图16中的每个点都是WSD LRS中不同结束步骤的衰减阶段的结束点。我们尝试了两种函数形式:指数和多项式。拟合结果表明,对于继续训练来说,多项式缩放定律仍然是最优的。
B.3、模型-数据缩放定律的单独图表
对于每个任务和模型,我们绘制了沿着数据轴的缩放定律 L ( N , D ) L(N, D) L(N,D) 与实际损失值的拟合度,如图17所示。
B.4、Llama2的数据到模型比率分析
如第4.5节所述,我们基于Llama2的训练损失曲线分析了其数据到模型的比率。提取的损失绘制在图18的左侧。我们将 x \mathrm{x} x轴转换为计算FLOPs,以便在图的右侧部分比较计算出的最优区域。
C、MiniCPM的词汇表
尽管MiniCPM的参数规模较小,但它旨在模拟多样化的数据分布,在英语和中文方面表现出色。因此,我们的词汇表相对较大。对于24亿参数的模型,我们使用了包含122,753个标记(标记为MiniCPMTokenizer 120K)的分词器。这个词汇表是从广泛且多样化的语言数据中构建的,利用了sentencepiece库进行字节对编码(BPE)(Sennrich等人,2016年),并包含了特殊符号,如传统中文字符、罕见字符、表情符号以及特殊符号,如希腊字母、西里尔字母等。
对于SLM(自我学习模型),如果词汇表很大,嵌入参数将占用大量参数空间。因此,对于我们的12亿参数模型,我们使用了较小的词汇表MiniCPMTokenizer-70K。
与MiniCPMTokenizer-120K分词器相比,我们在相同的文档上重新训练了分词,同时设置最大词汇数为64,000。对于特殊字符,我们只添加了传统中文字符、表情符号和特殊符号,但省略了中文中的罕见字符。
我们在中文、英文、代码和学术论文的300,000篇文档上进行了评估,这些文档不包含在分词器的训练集中。MiniCPM-120K分词器实现了最高的压缩率(字节/标记)。
D、量化
我们对模型进行了4位量化。我们不量化嵌入层和层归一化的参数,因为模型对这些参数很敏感。因此,我们只需要量化每个权重矩阵。设权重矩阵为 W ∈ R d out × d in \mathbf{W} \in \mathbb{R}^{d_{\text{out}} \times d_{\text{in}}} W∈Rdout×din。我们在 d in d_{\text{in}} din维度上将每 G G G个连续参数分组,形成 d in / G d_{\text{in}} / G din/G个组。然后,我们分别量化每个参数组。对于每个组参数 w \mathbf{w} w,我们计算量化比例和零点如下:
scale = max ( w ) − min ( w ) 2 4 − 1 , zero = − min ( w ) scale − 2 3 \text{scale} = \frac{\max(\mathbf{w}) - \min(\mathbf{w})}{2^{4} - 1}, \text{zero} = -\frac{\min(\mathbf{w})}{\text{scale}} - 2^{3} scale=24−1max(w)−min(w),zero=−scalemin(w)−23
然后,组参数 w \mathbf{w} w被量化为
w ^ = quant ( w ) = round ( w scale + zero ) \hat{w} = \text{quant}(w) = \text{round}\left(\frac{w}{\text{scale}} + \text{zero}\right) w^=quant(w)=round(scalew+zero)
其中round操作将浮点数四舍五入到最近的整数。去量化操作大约是量化方法的反向操作,即
dequant ( w ^ ) = scale ( w ^ − zero ) \text{dequant}(\hat{w}) = \text{scale}(\hat{w} - \text{zero}) dequant(w^)=scale(w^−zero)
最后,矩阵 W ∈ R d out × d in \mathbf{W} \in \mathbb{R}^{d_{\text{out}} \times d_{\text{in}}} W∈Rdout×din被量化为int 4的 W ^ ∈ R d out × d in \hat{\mathbf{W}} \in \mathbb{R}^{d_{\text{out}} \times d_{\text{in}}} W^∈Rdout×din,float类型的比例 scale ∈ R d out × d in G \text{scale} \in \mathbb{R}^{d_{\text{out}} \times \frac{d_{\text{in}}}{G}} scale∈Rdout×Gdin和float类型的零点 zero ∈ R d out × d in G \text{zero} \in \mathbb{R}^{d_{\text{out}} \times \frac{d_{\text{in}}}{G}} zero∈Rdout×Gdin。
为了减少量化损失,我们采用了GPTQ(Frantar等人,2022)来进行权重校准。我们从与SFT数据相似分布的校准数据中采样 X \mathbf{X} X。量化的目标是最小化量化的干扰 ∣ ∣ W X − dequant ( W ^ ) X ∣ ∣ 2 2 ||\mathbf{W} \mathbf{X} - \text{dequant}(\hat{\mathbf{W}}) \mathbf{X}||_{2}^{2} ∣∣WX−dequant(W^)X∣∣22。我们遵循GPTQ的方法,迭代地量化权重,并通过以下方式更新剩余的未量化权重:
其中 q q q是当前迭代的量化位置,而 F F F表示剩余的未量化权重。 H F H_{F} HF是目标函数的Hessian矩阵。
E、边缘设备基准测试
在附录D的Int4量化后,MiniCPM-2.4B的足迹被减少到2GB,从而便于在移动边缘设备上部署。我们使用MLC-LLM(团队,2023b)将模型适配到Android和HarmonyOS,并使用LLMFarm(团队,2023a)进行对iPhone系统的适配。这种适配在各种边缘移动设备上进行了测试。
需要强调的是,我们的工作并未专注于针对移动部署的优化,而是旨在展示MiniCPM在移动平台上推理能力的实用性。我们鼓励开发者社区进行进一步的优化和更新,以增强像MiniCPM这样的大型模型在移动环境中的性能。
表10展示了结果,我们可以看到在最新的iPhone 15 Pro手机上,推理吞吐量高达每秒18个标记。在其他设备上,推理吞吐量也是可以接受的。
F、案例演示
MiniCPM系列与微软等其他强大的大型语言模型(如Phi,Li等人,2023b)相比的一个显著特点是,我们在通用语料库上训练了MiniCPM,这确保了模型在各种任务上的多样性和泛化能力。在本节中,我们展示了几个引人入胜的生成实例,这些实例通常只有更大的模型才能实现,以此来展示MiniCPM的能力。虽然我们没有对训练集中是否存在特定案例进行广泛检查,因为它们的表达方式多种多样,但我们确保没有故意添加与测试案例相似的数据。