本文字数:3027字
预计阅读时间:20分钟
![]()
01
一、导读
• LLM 以及移动平台落地趋势
• 搜狐AI引擎内建集成离线可运行的GPT模型
• Keras 定制预训练模型
• TensorFlow Lite converter 迁移到移动设备
02
二、LLM
1.1什么是LLM
LLM(Large Language Models)大语言模型,是机器学习模型的一种,它由大量的文字数据生成各种的NLP(自然语言处理)任务。比如问答,翻译,补全句子等。
LLM 通常很大,因为它的训练数据通常需要大量的文本。但是它的核心任务只有一个,就是预测句子中下一个“词”是什么。
1.2LLM目前落地到移动端存在的问题
LLM的运算负担很重,一次运算需要服务器运行数秒,性能差的服务器甚至需要数分钟。这对大规模移动端并发商用落地,是巨大的挑战;
就像小白兔面对老狐狸,个体数据隐私在海量数据训练过的大模型面前,十分脆弱,个人隐私一览无余;
当你必须要全裸,你会选择在家里(端上),还是到大街上(云上)?所以行业的共识是:大语言模型端侧离线前置,一定是未来的技术方向;
大语言模型离线前置,目前主要问题在于对内存负担较大,相比普通常见的机器学习模型,大语言模型本身远远超过了移动端设备的可用内存极限。
1.3端侧大语言的趋势
几乎没有一家手机厂商愿意错过将大模型集成到手机中的机会。然而,将参数动辄达到百亿、千亿级的大模型放入小小的手机端并非易事。
2023年8月4日,华为宣布HarmonyOS 4接入AI大模型。通过AI大模型的赋能,华为智慧语音助手小艺在智慧交互、高效生产力和个性化服务三个方向持续增强:

2023年8月,小米官方宣称“小米全面拥抱大模型”后,10月就通过小米集团和顺为资本投资了王小川的大模型公司百川智能:

2023年10月11日,OPPO宣布与联发科技合作,共同推动AndesGPT大语言模型和多模态大模型的应用。 AndesGPT是OPPO自主训练的生成式用户专属AI大模型,基于AndesGPT大模型开发的全新语音助手小布已开始新一轮公测:
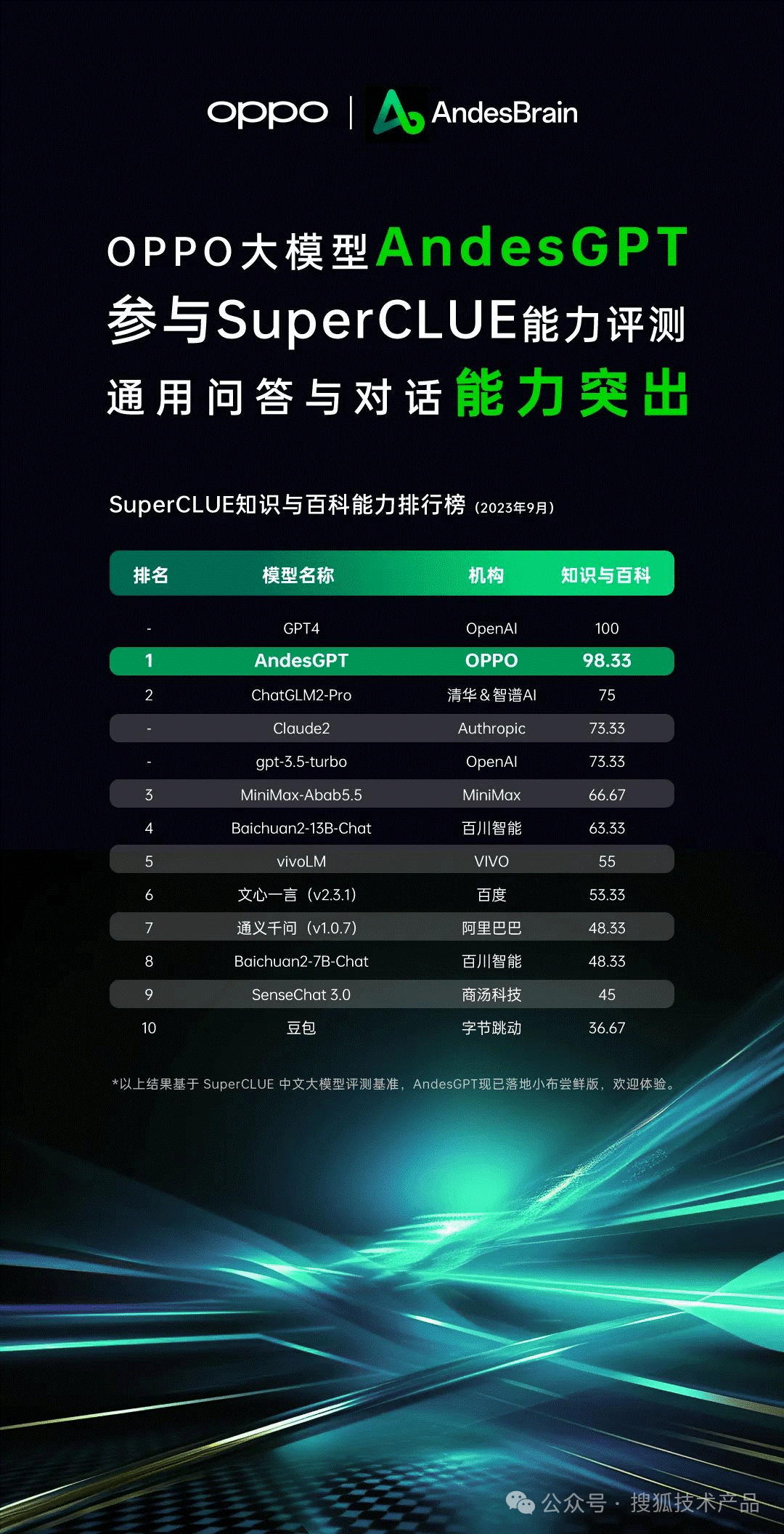
本文发表前,Google发布了他们最新的全端AI解决方案Gemini:

其中,Gemini Nano专门针对Android设备进行了优化,配合Android AICore,用于设备端任务,可以在安卓设备上本地和离线运行。其中,Nano-1的参数为1.8B,Nano-2为3.25B。
03
三、搜狐Hybrid AI基于GPT2的端侧大模型实现
搜狐新闻作为移动端侧AI应用落地的先驱,2019年就开始了端侧离线AI框架的落地探索,并推出了Hybrid AI Engine 助力客户端AI:
从引擎发布以后,我们不断在完善引擎各个子模版的AI能力,赋能产品应用能力开发。如今在生成式大模型火热的今天,我们也基于Tensor Flow Lite,把GPT2集成到了AI框架中,提供了原生离线大语言模型的能力。
2.1why GPT2?
GPT2 相较于后续的GPT3.5和GPT4,模型相对小很多,蒸馏为TensorFlow lite后,大小会缩小1/4只有150m,并且依然可以拥有相对可以接受的性能,对运行时内存影响很小。150m的模型,可以内置到包体,也可以通过Hybrid AI Engine的模型自升级动态下载模块下载,真正的做到了端侧可用的水平:
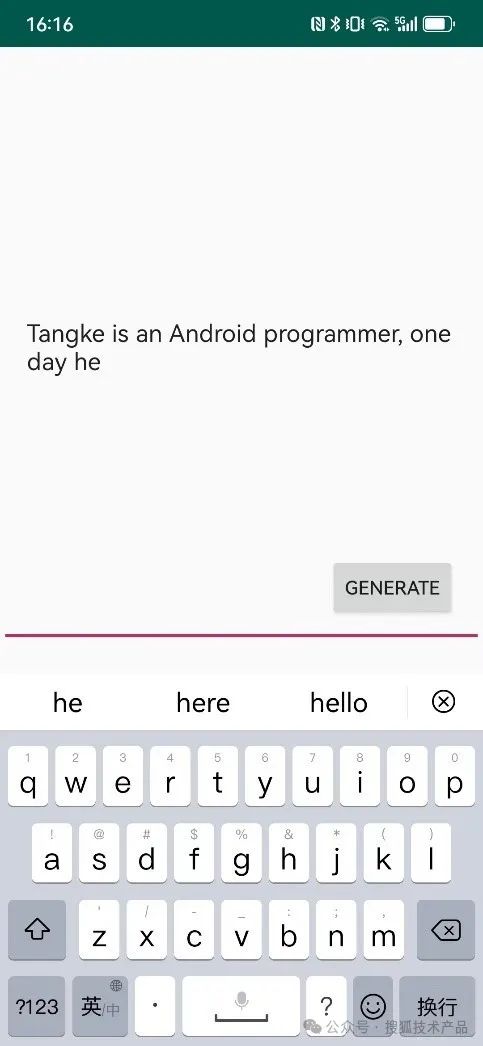
下图是完成集成后的Demo效果,输入一小段话之后,点击“生成”按钮,在移动设备上,只需要10秒就能生成如下图一样的一长段文字,并且前后有明确的逻辑联系:

而这一切功能,引入Hybrid AI Engine的SDK之后,只需要下面这三行代码就可以完成调用方式:
mGPT = AIHelperFactory.getInstance(context).getGPT();
mGPT.generate(prompt, text -> promptView.setText(text));
mGPT.release();
那么,AI Engine SDK 里面,是怎么实现端上GPT功能的呢?
我们来梳理一下相关的核心代码:
1. 初始化:

GPT服务运行在AutoCompleteService中,初始化加载模型到Service中,并通过Impl连接到应用侧。
2. 加载模型文件:

这里是模型加载逻辑,从模型文件中读取mappedByteBuffer,并生成Interpreter对象,之后的模型调用,就直接通过Interpreter对象完成:
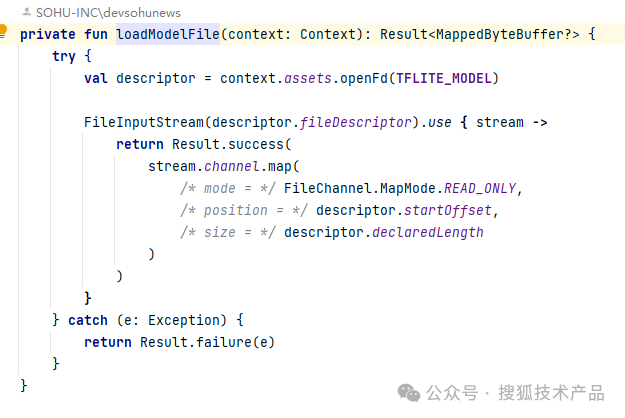
这里是前一步会用到的加载模型文件方法,可以是asset中的内置模型文件,也可以是动态下载的模型文件,甚至是下载流也支持。真正做到模型动态更新。
3.调用获取生成结果:
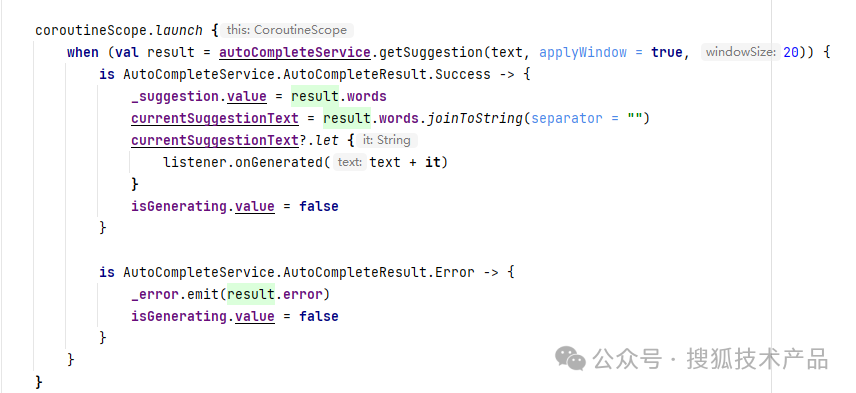
Service的Impl直接调用获取生成结果,并输出到UI中:
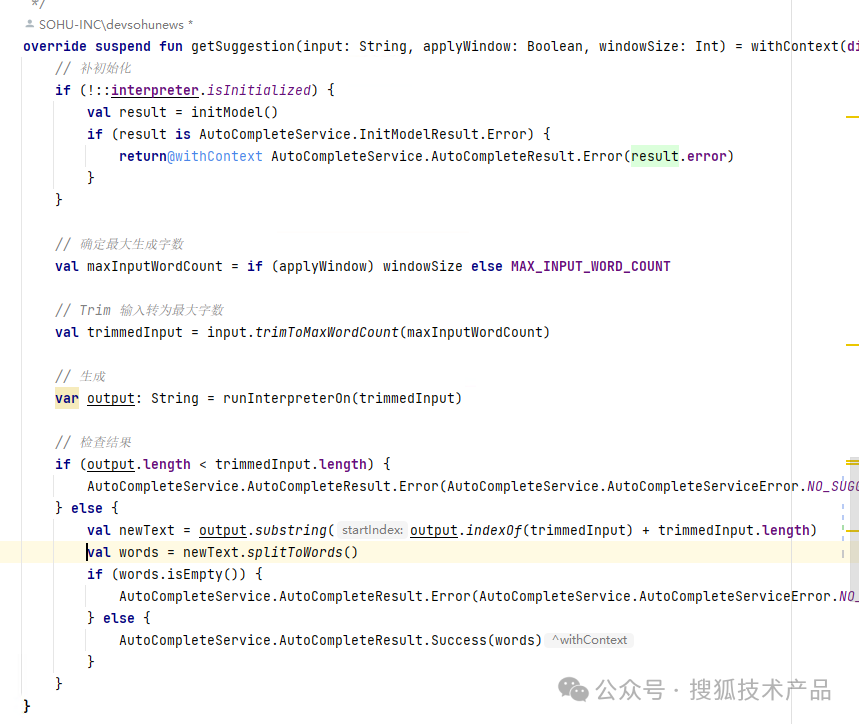
这里调用生成结果时,可以看到我们对书入进行了一些简单的处理,并最后使用Iterpreter实时动态返回。
以上最终实现了GPT模型的端侧部署调用。
看到这里,细心的读者朋友肯定发现了,这些步骤的前提,是有一个可以运行在端上的已经蒸馏好的GPT2模型。
下面,我们再来看,如何使用Keras来定制预训练模型:
2.2使用Keras定制预训练模型
我们使用Keras 把OpnAI的GPT2模型转为TensorFlow格式
KerasNLP
Keras是Python上的一个开源NLP sdk 库,提供了大量预训练的LLM模型,并支持:
-训练数据转为NumPy数组或者tf.data.Dataset对象
-预处理训练数据
-自定义定制构建模型
2.3环境准备
Linux(or Colab) Python3 tensorflow-text 2.12
Colab:https://colab.research.google.com/
pip install git+https://github.com/keras-team/keras-nlp.git tensorflow-text==2.12
Linux/MacOs也可以直接去github 下载keras-nlp,解压之后在Keras目录使用:
pip install . Tensorflow-text==2.12
2.4利用Keras 修改预训练GPT2模型

加载Keras预训练的GPT2模型:

使用预训练的GPT2模型生成结果:
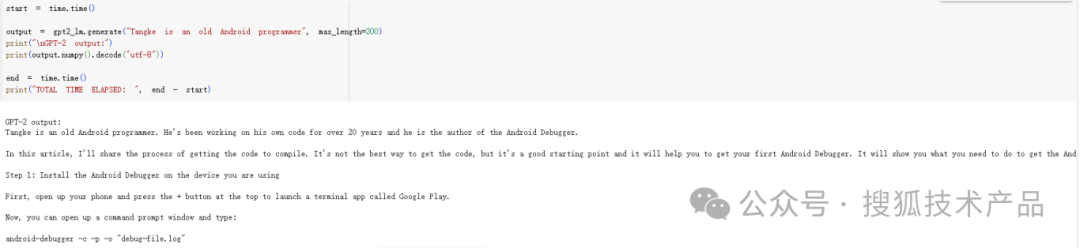
2.5Tokenizer ?Preprocessor ?Backbone ?
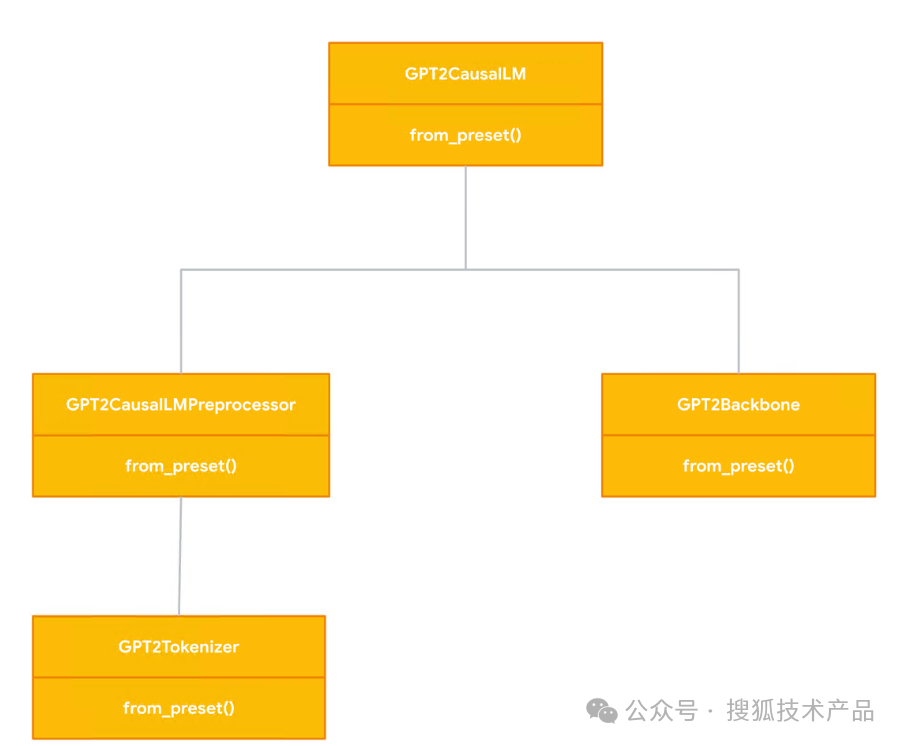
这里我们用到Tokenizer , Preprocessor 以及Backbone。我们简单了解一下他们到底是什么:Tokenizer 把输入文字转换成Token ID,GPT2使用Byte-Pair-Encoding的TokenizerPreprocessor 执行把token ID的张量(多维数组tensor)加上长度,转为(x, y, weight)格式,以传递给Backbone运算。
Backbone 构建的神经网络,执行运算推理:
而运算推理的过程,就是处理Attention的过程,一个查询Query(Q),与K(Key),以及V (Value) 生成Attention:
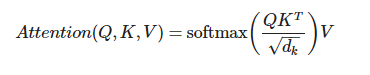
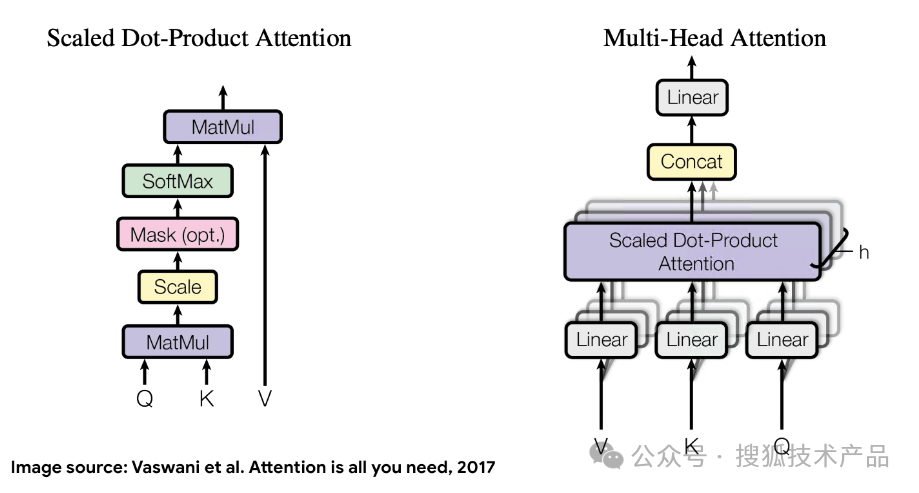
对于没有太熟悉算法的客户端开发工程师来说可能仍然有点难以理解,我们这里用一个例子来说明:
假如你需要回答一个问题,这个问题关乎于一个你完全不了解的领域。比如“混凝土的合理配比”(Query)。你完全不了解它,以至于连问题问的是什么都不明白,所以你只能去查询所有的关于“建筑材料”书;
但是关于“建筑材料”的书太多了,你不可能全部详读一遍。所以你自然而然地,检查书籍的各级“书籍标题”(Key)。标题和你的问题越相似,你就会花更多的“精力”(attention)去查看对应的“书籍内容”(Value);
“书籍标题”就是key,“书籍内容”是value。我们作为有天然智能的人,不自知的自然而然使用了一个评分机制,就是“书籍标题”(key)和我们的问题的相似度,越相似,评分越高,我们就越花“精力”(attention)去了解“书籍的内容”(value),最终的输出,就是解决我们最开始需要问的问题;
这个例子就是一个典型的过程: queries, masking, self-attention vs. cross-attention。
04
四、迁移到移动设备端
截至到这一步,模型已经可以生成预期样式的文本了,但是仍然需要位于云上的强大 GPU 上运行。我们最终是想要在移动设备上看到结果,一种解决方案是使用 Keras NLP 构建后端服务,并将请求从移动设备发送到云端,运算完之后再发回来,但更好的方法是使用设备端机器学习(ODML)纯粹在设备上运行模型。这时候我们就需要用到 TensorFlow Lite:
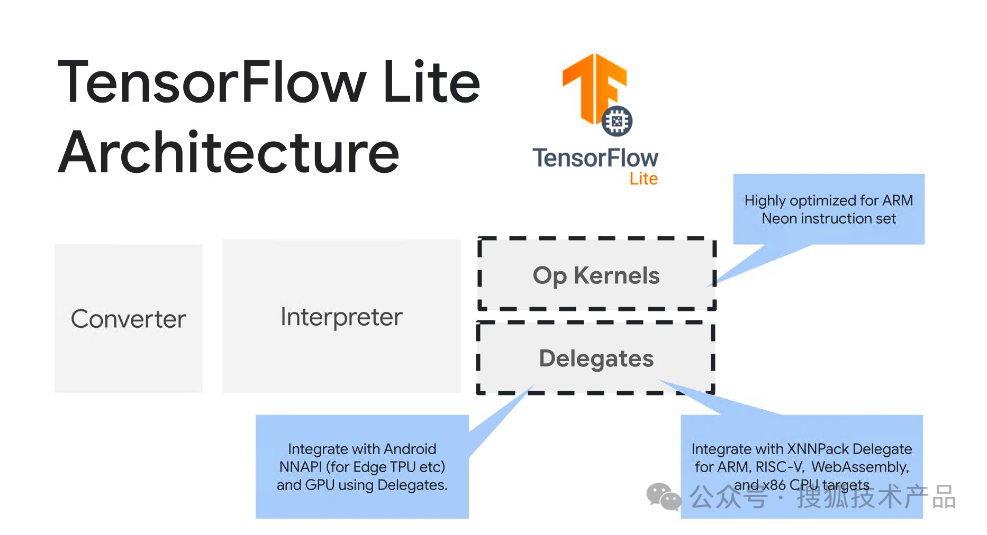
首先使用 TensorFlow Lite 转换器将 TensorFlow 模型转换为更紧凑的 TensorFlow Lite 格式,然后使用 TensorFlow Lite 解释器(针对移动设备进行了高度优化)来运行转换后的模型。在转换过程中,您还可以利用量化等多种技术来进一步优化模型并加速推理。然后把GPT2CauselLM的generate()方法转成tf.function:

再定义一个辅助函数,以使用给定的输入和 TFLite 模型运行推理:
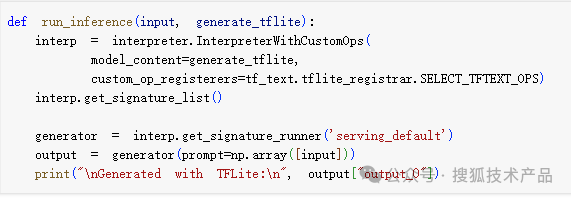
转换模型到TFLite格式,并保存下来:


最后,把得到的模型文件,部署到AI框架SDK中,大功告成:
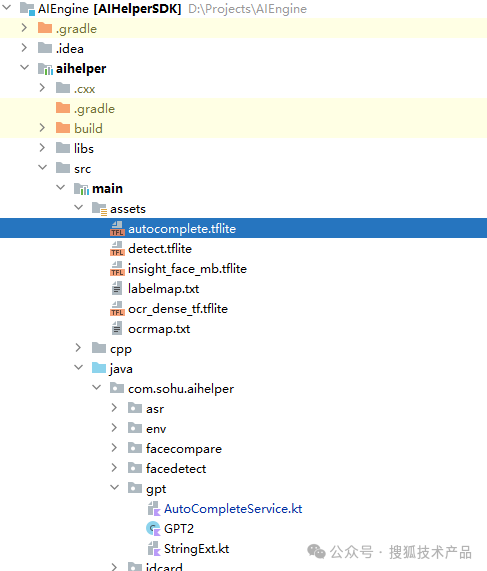
Demo中直接使用了内置到ASSET中,实际开发中,我们可以选择把150M的模型动态下载,完成动态部署升级。
至此,Hybrid AI Engine已经完整的支持了本地离线的端侧GPT功能。
05
五、写在最后
随着人工智能技术的不断发展,大语言模型已经成为了几乎所有移动互联公司落地探索的热点之一。在移动平台实现离线端侧运算大语言模型,必将会为人们的生活带来更多的便利和创新。因为在移动平台实现大语言模型运算,不仅可以为用户提供快速可靠的智能化交互体验,还可以同时保护用户隐私,并且还能节省云端算力,从而节省全链路运算总成本。
今天我们在sdk中内置GPT模型的尝试,只是大语言模型落地探索方向迈出的一小步,期待未来越来越的端侧AI技术的成熟落地。真正的让AI成为改变人类生活方式又一大创新。