一、Hbase的原理讲解
1、hbase介绍
2、hbase集群架构(具体配置见其他文章)
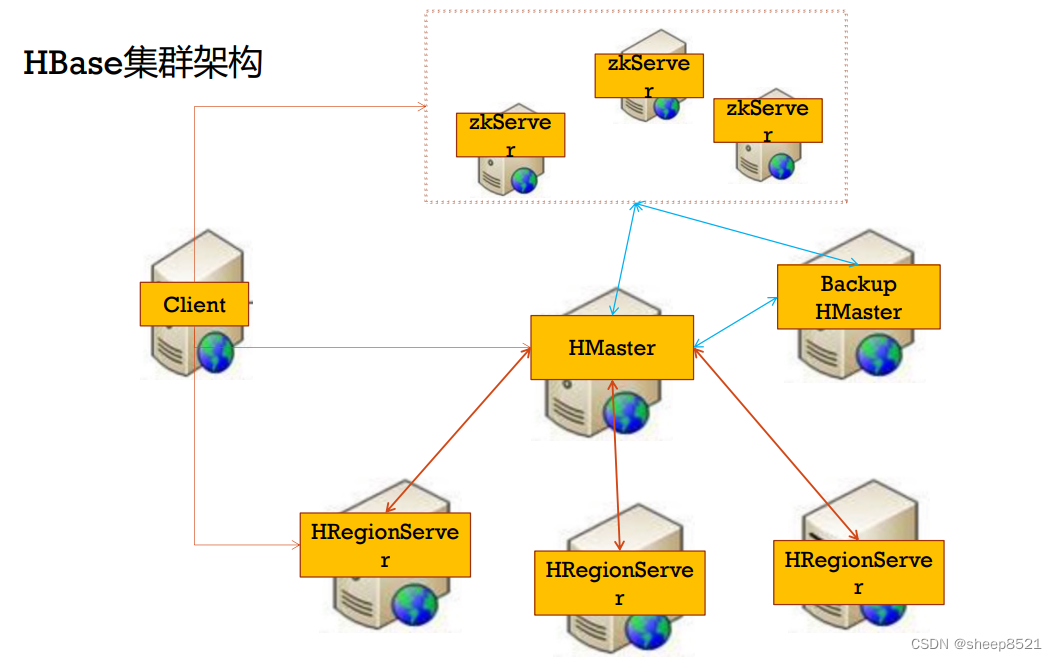
hbase集群的HA配置
(假如有3台机器(同时是regionserver角色),master、slaver1、slaver2)
stop-hbase.sh
cd /home/hadoop-twq/bigdata/hbase-1.2.6/conf
vi backup-masters 在master机器上文件增加如下的记录:
slave1 ---backup master的节点ip
---把backup的信息同步给其余的slave。
scp backup-masters hadoop-twq@slave1:~/bigdata/hbase-1.2.6/conf/
scp backup-masters hadoop-twq@slave2:~/bigdata/hbase-1.2.6/conf/
start-hbase.sh
jps验证
访问: http://slave1:16010
kill掉master上的HMaster,然后slave1上的HMaster成为master了
3、hbase数据模型
hbase是列式数据库,有列簇、命名空间、版本号、TTL等特性。
- namespace:表空间namespace就像MySql中的库的概念一样,库里可以创建表,那么namespace里也可以创建表)
- 列簇:1个列簇是多个列的集合,对应是是不经常变化或者相同类型的列的集合。
创建3个列簇
create 'webtable',{NAME => 'content'},{NAME => 'language'},{NAME => 'link_url'}
- version:该属性让Hbase表支持存储多个VERSIONS的版本列数据
--创建habse表t1,列簇是f1
create 't1',{NAME => 'f1'}
---给1个列簇修改版本号
alter 't1',{NAME => 'f1', VERSIONS => 3}
---给1个列插入多个版本数据
hbase(main):015:0> put 't1','rowkey1','f1:name','chhliu'
0 row(s) in 0.5890 seconds
hbase(main):016:0> put 't1','rowkey1','f1:name','xyh123'
0 row(s) in 0.1900 seconds
hbase(main):017:0> put 't1','rowkey1','f1:name','chhliuxyh'
----命令行获得多个版本的数据
hbase(main):002:0> get 't1','rowkey1',{COLUMN=>'f1:name',VERSIONS=>3}
COLUMN CELL
f1:name timestamp=1482820567560, value=chhliuxyh
f1:name timestamp=1482820541363, value=xyh123
f1:name timestamp=1482820503889, value=chhliu
----命令行获得2个版本(最近2个)的数据
hbase(main):002:0> get 't1','rowkey1',{COLUMN=>'f1:name',VERSIONS=>3}
COLUMN CELL
f1:name timestamp=1482820541363, value=xyh123
f1:name timestamp=1482820503889, value=chhliu
- TTL(Time To Live):数据的生命周期,TTL参数的单位是秒,默认值是Integer.MAX_VALUE,即2^31-1=2 147 483 647 秒,大约68年。使用TTL默认值的数据可以理解为永久保存。
create 'webtable_ttl',{NAME => 'content'},{NAME => 'language', VERSIONS => 1},{NAME => 'link_url', TTL => 5}
put 'webtable_ttl','http://www.51cto.com/','link_url:sina','http://tech.sina.com.cn/'
get 'webtable_ttl','http://www.51cto.com/',{COLUMN => 'link_url:sina'}
alter 'webtable_ttl',{NAME => 'link_url', TTL => 3}
alter 'test',{NAME => 'cf',TTL => 'FOREVER'} ---desc "test" 查看设置(FOREVER永不过期)是否成功
4、hbase读写流程&特性
5、表组成
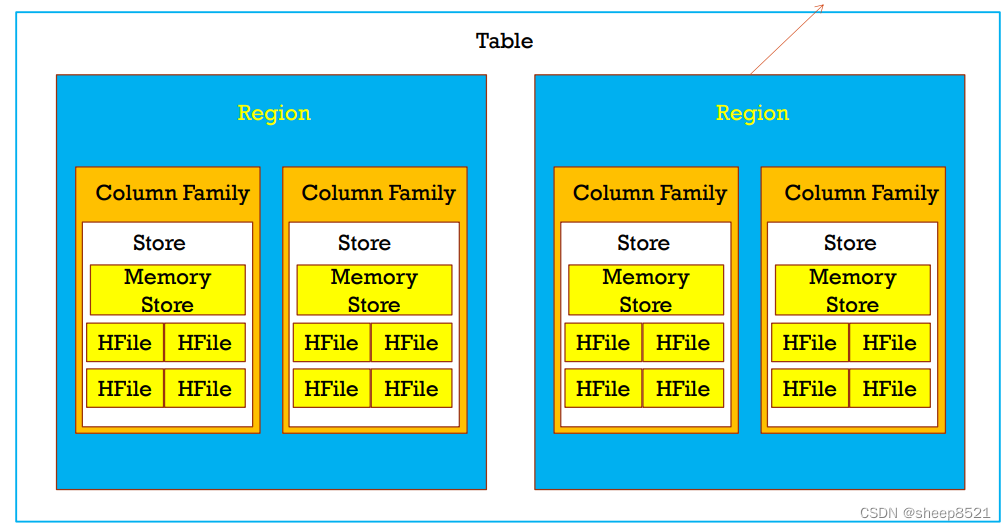
1、Table -> Region 【1对多】
Region都是分布在所有的HRegionServer上的每一个Region负责管理和存储一个Table中的某段数据每一个table的RowKey是按照字符串的自然顺序升序排列的。
2、Region -> Column Family【1对多】
一个Region负责管理和存储一个或者多个Colummn Family的数据
3、Column Family -> Store 【1对多】
一个Column Family对应着一个Store
一个Store中含有一个MemoryStore和若干个HFile
4、HFile ->Block 【1对多】
一个HFile含有若干个不同类型的BlockBlock的大小通常为8K到1MB,默认的大小是64KB的Block的类型有:Data Blocks、Index Blocks、Bloom filter Blocks以及Trailer block。
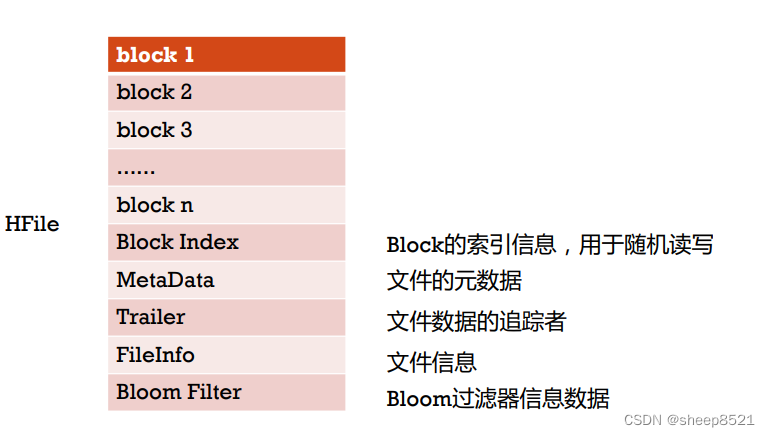
5、Block -> KeyValue 【1对多】
一个Block包含一个magic数字和若干个KeyValue的数据。

HFile在存储每一个Row时,不是把这一条Row的全部Family/Column整合成在一起,保存起来的,如下:
RowKey | Family:Column1 -> value | Family:Column2 -> value ----我们认为的存储格式
它是把这条Row,根据Column拆分成好几个KeyValue,保存起来的,如下:
RowKey/Family:Column1 -> value
RowKey/Family:Column2 -> value
我们可以看到,RowKey需要重复保存很多次,而且Family:Column这个往往都是非常相似的,它也需要保存很多次.这对磁盘非常不友好.当Family:Column越多时,就需要占用越多不必要的磁盘空间。
Block Encoder&Compressors
Compressors压缩:
block常常以一定压缩格式存储,主要为了节约存储空间,默认支持以下压缩格式 none、Snappy、LZO4、LZ4、GZ。大部分的场景下默认使用Snappy或者LZO就好,因为他们提供了更好的性能Block Encoder:
在实际中不是简单对其进行压缩就能提高查询效率的。我们知道当读取hbase数据时,是需要先读MemStore,然后再读BlockCache的.那我们的Block越小,能放到BlockCache中的数据就越多,命中率就越高,对Scan就越友好。
Block Encoder是通过某种算法,对Data Block中的数据进行压缩,这样Block的Size小了,放到Block Cache中的就多了。
这儿提出两个问题:
- 压缩以后,占的Disk/Memory是少了,但是解压的时候,需要更多的CPU时间.如何均衡呢?
- 如果我们的业务,偏重的是随机Get,那放到Block Cache中不一定好吧?不仅放到Block Cache中的Block很容易读不到,对性能并没有什么提升,还会产生额外的开销,比如将其它偏重Scan的业务的Block排挤出Block Cache,导致其它业务变慢。
HBase中提供了五种Data Block Encoding Types,具体有:
NONE
PREFIX
DIFF
FAST_DIFF
PREFIX_TREE
PREFIX
一般来说,同一个Block中的Key(KeyValue中的Key,不仅包含RowKey,还包含Family:Column),都很相似.它们往往只是最后的几个字符不同.例如,KeyA是RowKey:Family:Qualifier0,跟它相邻的下一个KeyB可能是RowKey:Family:Qualifier1。
Prefix
在PREFIX中,相对于NONE,会额外添加一列,表示当前key(KeyB)和它前一个key(KeyA),相同的前缀的长度(记为PrefixLength)。
我们有一些Row,当使用NONE这种Block Encoding时,如下图所示:
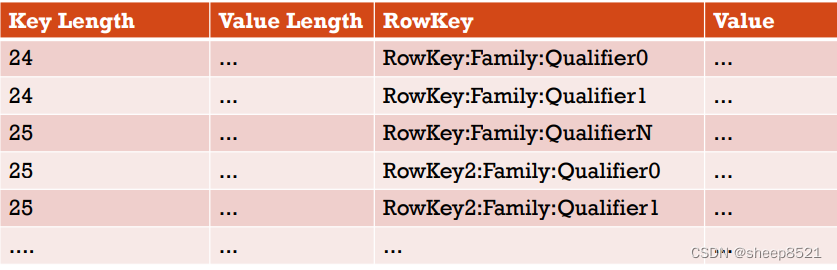
而如果采用PREFIX这种Block Encoding,那就是这样子了:
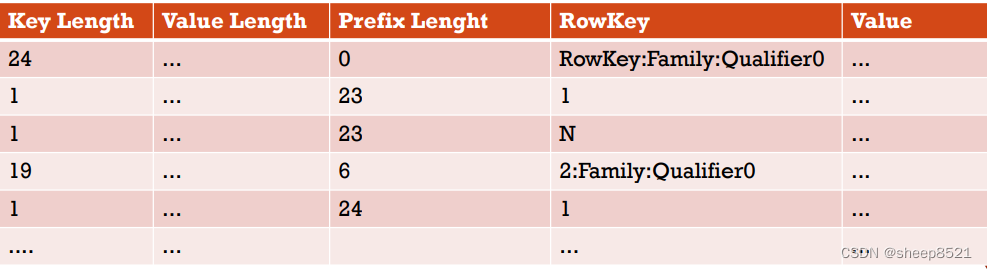
在上面的例子中,如果KeyA是这个Block中的第一个key,那它的PrefixLength就是0.而KeyB的PrefixLength是23。所以对应样例:原来的2条KeyA且key length是24的记录(对应2个列:Qualifier0、Qualifier1,每个列1行),在PREFIX格式下对应3条记录,第1条记录对应表的第1个记录只是PrefixLength为0,将原表2条数据的话按这条记录为参照,不再重复保存rowkey,而是用PrefixLength=23和列名称1、N标识原来的keylength为24的2条记录。
Diff
DIFF是对PREFIX的一种改良.它把key看成很多个部分,对每部分进行压缩,提高效率.它添加了两个新的字段,timestamp和type.如果KeyB的ColumnFamily、key length、value length、type和KeyA相同,那么它就会在KeyB中被省略(对应key length是24的第1行和第2行,第2行就是第1行的key-value, 对应都是第1列的数据,所以重复数据的部分字段省略了)。
另外,timestamp,存储的是相对于前一个Row的偏移量.
默认情况下,DIFF是不启用的。因为它会导致写数据,以及Scan数据更慢.但是,相对于PREFIX/NONE,它会在Block Cache中缓存更多数据.
用DIFF压缩的block如下图所示:
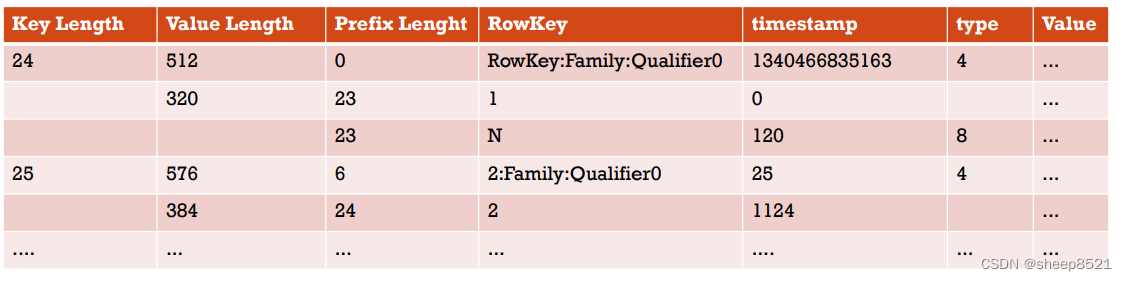
Fast Diff
FAST_DIFF跟DIFF非常相似,所不同的是,它额外增加了一个字段,表示RowB是否跟RowA完全一样,如果是的话,那数据就不需要重复保存了(也就是对应key length是24的第1行和第2行,第2行对应是第1列的数据,所以重复数据的只保留1份即可)。
如果你的rowkey很长,并且有很多的Column的话,则推荐使用Fast Diff。
如何选择压缩算法以及Block Encoding Type?
- 如果Key很长,或者有很多Column,那么推荐使用FAST_DIFF。
- 如果数据是冷数据,不经常被访问,那么使用GZIP压缩格式.因为虽然它比Snappy/LZO需要占用更多而CPU,但是它的压缩比率更高,更节省磁盘。
- 如果是热点数据,那么使用Snappy/LZO压缩格式.它们相比GZIP,占用的CPU更少。
- 在大多数情况下,Snappy/LZO的选择都更好. Snappy比LZO更好。
---建表的属性,考虑表查询效率的提高,可以在java层或者xml下进行调整。
val tableDescriptor = new HTableDescriptor(table)
tableDescriptor.addFamily(new HColumnDescriptor(familyName))
tableDescriptor.setConfiguration("COMPRESSION", "SNAPPY")
tableDescriptor.setConfiguration("VERSIONS", "1")
tableDescriptor.setConfiguration("BLOCKCACHE", "FALSE")
tableDescriptor.setConfiguration("BLOOMFILTER", "ROW")
tableDescriptor.setConfiguration("DATA_BLOCK_ENCODING", "FAST_DIFF")
6、Table Schema的设计和rowkey设计
6.1、建表设计
基于hbase的特性需要对表设计做相关限制。
- 1、每一个region的大小在10到50G。
<property>
<name>hbase.hregion.max.filesize</name> #这个参数的配置控制每一个Region的大小。
<value>52428800</value> #当前设置为50M, 默认是10G
</property>
- 2、每一个table控制在50-100个regions。
注意: HBase 可以进行预分区时,但如果创建的 region 太多 ,集群不堪重负,由此带来了 HBase 的意外宕机。
为什么合理分配 region 数量有益于集群稳定?
1、MSLAB: 有助于防止堆内存的碎片化,减轻 Full GC , GC 的问题,默认是开启的。但每个 MemStore 需要 2MB(一个列簇对应一个写缓存 Memstore )。所以如果每个 region 有 2 个列簇,总有 1000 个 region ,就算不存储数据也要 3.95GB 内存空间
2、过多的 region,导致 Memstore 也过多,内存大小触发 Region Server 级别限制导致 flush,这会对用户请求产生较大的影响,可能阻塞该 Region Server 上的更新操作
3、HMaster 要花大量的时间来分配和移动 Region,且过多 Region 会增加 ZooKeeper 的负担
4、从 HBase 读入数据进行处理的 Mapreduce程序,过多 Region 会产生太多Map任务数量,默认情况下一个 region 对应一个map。因此,如果一个 HRegion 中 Memstore 过多,而且大部分都频繁写入数据,每次 flush 的开销必然会很大,因此也建议在进行表设计的时候尽量减少 ColumnFamily 的个数
Region 数量计算的公式:
((RegionServer Xmx) * hbase.regionserver.global.memstore.size) / (hbase.hregion.memstore.flush.size * (列族数量))
举例:一个 Region Server 有 16GB 内存,则 16384*0.4 / 128 mb 等于 51 个活跃的 region
3、每一个table控制在1到3个column family,且按更新频率对CF进行分开创建。
比如一张hbase表需要存储每个用户的信息(比如名字、年龄等)和这个用户每天访问网站的信息。分以下两种情况:
1)对于用户的信息,不经常变,而且量少
2)对于用户每天访问网站的信息是经常变化且数据量很大的
如果将这两种信息放在同一个column family中的话,用户每天访问网站的信息数据的增大导致会出现
memory store的flush,然后会导致compaction,因为compaction是column family级别的,所以会将
每个用户的信息(比如名字、年龄等)和这个用户每天访问网站的信息都合并到文件中。但是用户的信息不大,且不经常变,没必要每次compaction都要将用户的信息写到磁盘中,导致资源的浪费。
所以将用户的信息和用户每天访问网站的信息分成两个column family来存。4、每一个column family的命名最好要短,因为column family是会存储在数据文件中的。
6.2、RowKey的设计
长度原则:rowkey的长度一般被建议在10-100个字节,不过建议是越短越好。
`1、数据持久化文件HFile是按照keyvalue存储的,如果rowkey过长,比如100个字节,
1000万列数据光Rowkey就要占用100*1000万=10亿个字节,将近1G数据,这会极大影响HFile的存储效率
2、MemStore将缓存部分数据到内存,如果Rowkey字段过长内存的有效利用率会降低,
系统将无法缓存更多的数据,这会降低检索效率。因此Rowkey的字节长度越短越好。
3、目前操作系统是都是64位系统,内存8字节对齐。如果rowkey是8字节的整数倍的话,则利用了操作系统的最佳特性。`
存储顺序: rowkey是按照字典顺序进行存储的,相似的rowkey会存储在同一个Region中。如果rowkey没有设计好的话,还会引发Hotspotting:
解决Hotspotting的三个方法:
- Salting((撒盐似的)散布、加盐)
create 'test_salt', 'f',SPLITS => ['b','c','d']
原始的rowkey: salting rowkey:
boo0001 a-boo0001
boo0002 b-boo0002
boo0003 c-boo0003
boo0004 d-boo0004
boo0005 a-boo0005
boo0006 d-boo0006
2、Hashing
create 'test_hash', 'f', { NUMREGIONS => 4, SPLITALGO => 'HexStringSplit' }
原始的rowkey: md5 hash rowkey:
boo0001 4b5cdf065e1ada3dbc8fb7a65f6850c4
boo0002 b31e7da79decd47f0372a59dd6418ba4
boo0003 d88bf133cf242e30e1b1ae69335d5812
boo0004 f6f6457b333c93ed1e260dc5e22d8afa
3、反转rowkey
时间戳类型的rowkey: 反转rowkey:
1524536830360 0630386354251
1524536830362 2630386354251
1524536830376 6730386354251
多条件查询:
采用 UserID + CreateTime + FileID等多个关键性查询条件组成RowKey,这样既能满足多条件查询,又能有很快的查询速度。
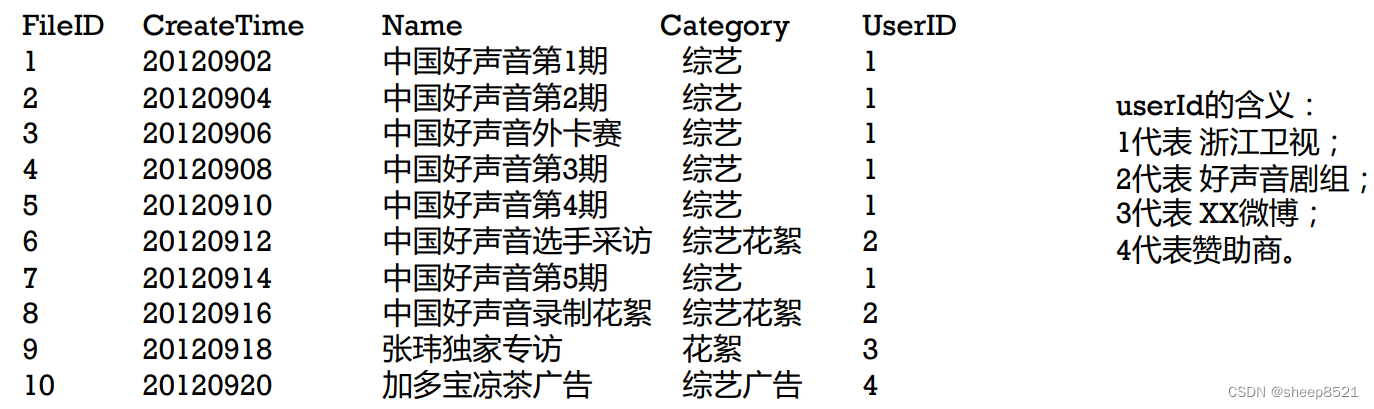
(1)每条记录的RowKey,每个字段都需要填充到相同长度。假如预期我们最多有10万量级的用户,则userID应该统一填充至6位,如000001,000002…
(2)结尾添加全局唯一的FileID的用意也是使每个文件对应的记录全局唯一。避免当UserID与CreateTime相同时的两个不同文件记录相互覆盖。
rowKey(userID 6位 + time 8位 + fileID 6位) name category ….
00000120120902000001
00000120120904000002
00000120120906000003
00000120120908000004
00000120120910000005
00000120120914000007
00000220120912000006
00000220120916000008
00000320120918000009
00000420120920000010
create 'sound','f', SPLITS => ['0','1','2','3','4','5','6','7','8','9'] #根据样例数据进行预分区。
怎么用这张表呢?
1)在建立一个scan对象后,我们setStartRow(00000120120901),setStopRow(00000120120914)。
scan时只扫描userID=1的数据,且时间范围限定在这个指定的时间段内,满足了按用户以及按时间
范围对结果的筛选。并且由于记录集中存储,性能很好。
2)然后使用 SingleColumnValueFilter(org.apache.hadoop.hbase.filter.SingleColumnValueFilter),共4
个,分别约束name的上下限,与category的上下限。满足按同时按文件名以及分类名的前缀匹配
3)如果需要分页还可以再加一个PageFilter限制返回记录的个数。