白月黑羽老师的网站上面还有很多关于软件测试的内容,大家感兴趣的可以结合B站的视频与网站上面的资料一起学习。
目录
find_element 和 find_elements 的区别
安装Selenium
Selenium环境的安装主要就是安装两样东西: 客户端库 和 浏览器驱动
安装客户端库
不同的编程语言选择不同的Selenium客户端库。
对应Python语言来说,Selenium客户端库的安装非常简单。用 pip 命令即可。
打开 命令行程序,运行如下命令
pip install selenium安装完成后,使用如下命令查看是否安装成功
pip show selenium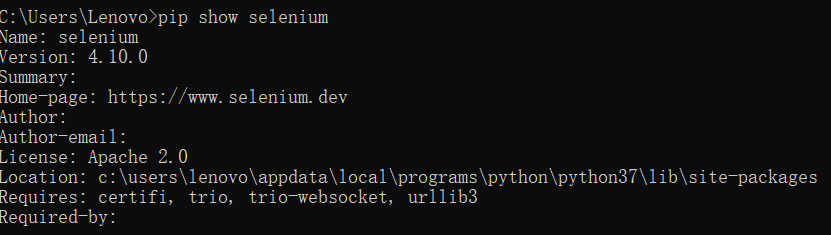
然后进入Pycharm,点击file->setting
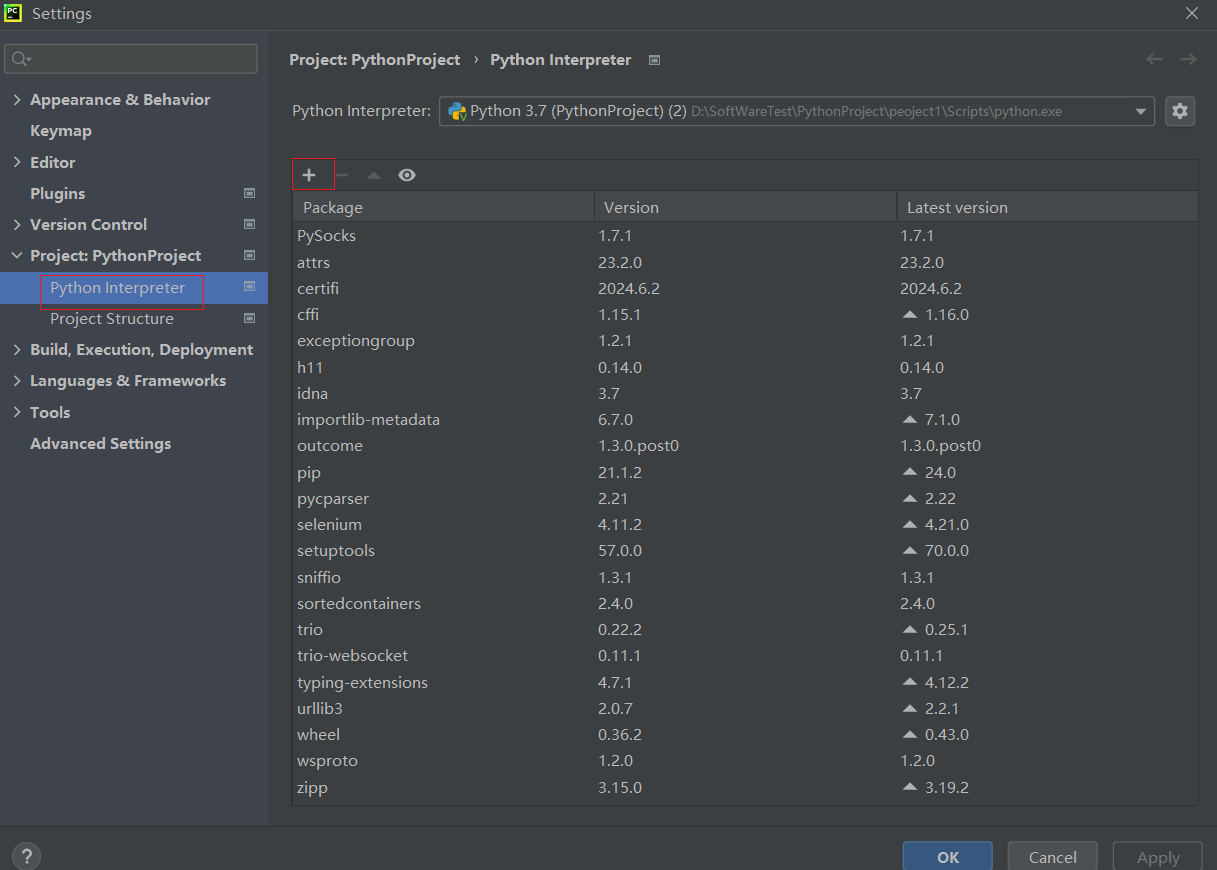
这样我们就可以在python文件中import与Selenium相关的库了。
安装驱动
安装Chrome浏览器驱动
查看Chrome浏览器版本
安装Edge浏览器的驱动
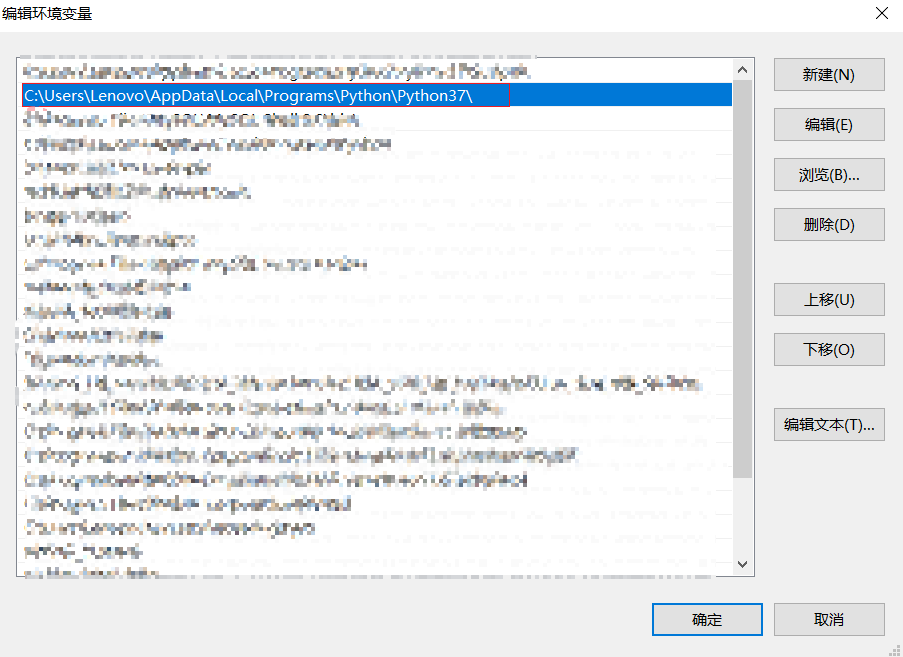
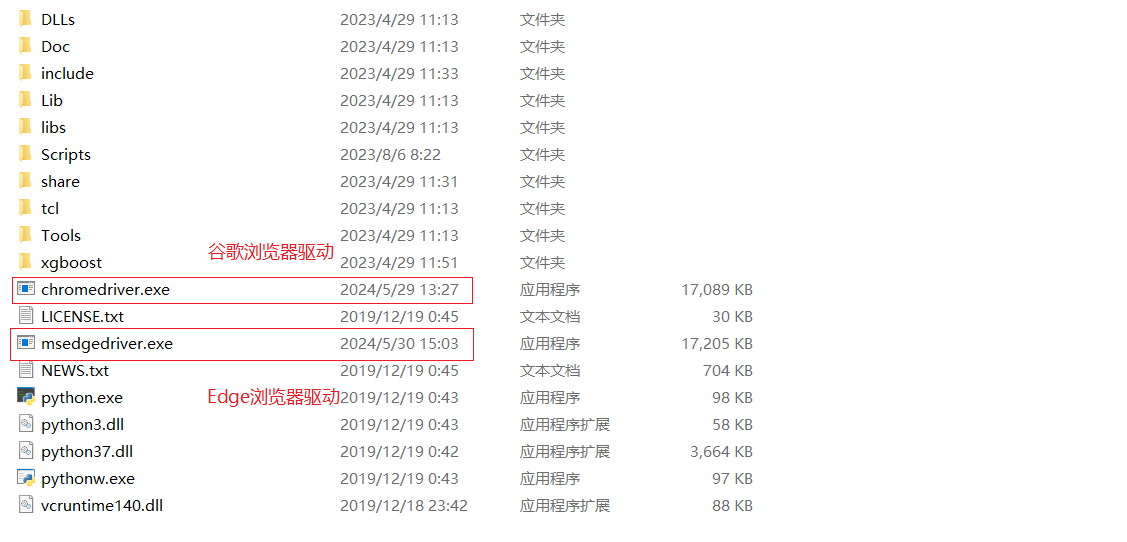
安装完驱动之后,建议将.exe文件放到python的环境变量的路径下面
查看路径:
这样在编写程序的时候就不许要引入路径。
简单示例
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd = webdriver.Chrome(service=Service(r'd:\tools\chromedriver.exe'))
# 或者 如果将浏览器驱动的.exe文件放到了python环境变量的路径下面,就可以使用下面的方式
wd = webdriver.Chrome()
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get('https://www.baidu.com')
# 程序运行完会自动关闭浏览器,就是很多人说的闪退
# 这里加入等待用户输入,防止闪退
input('等待回车键结束程序')执行完自动化代码,如果想关闭浏览器窗口可以调用WebDriver对象的 quit 方法,wd.quit()。
基本操作
选择元素的基本方法
对于web自动化来说,需要先找到元素,才能操作元素
根据 id属性 选择元素
在浏览器中点击F12,打开浏览器的开发者工具
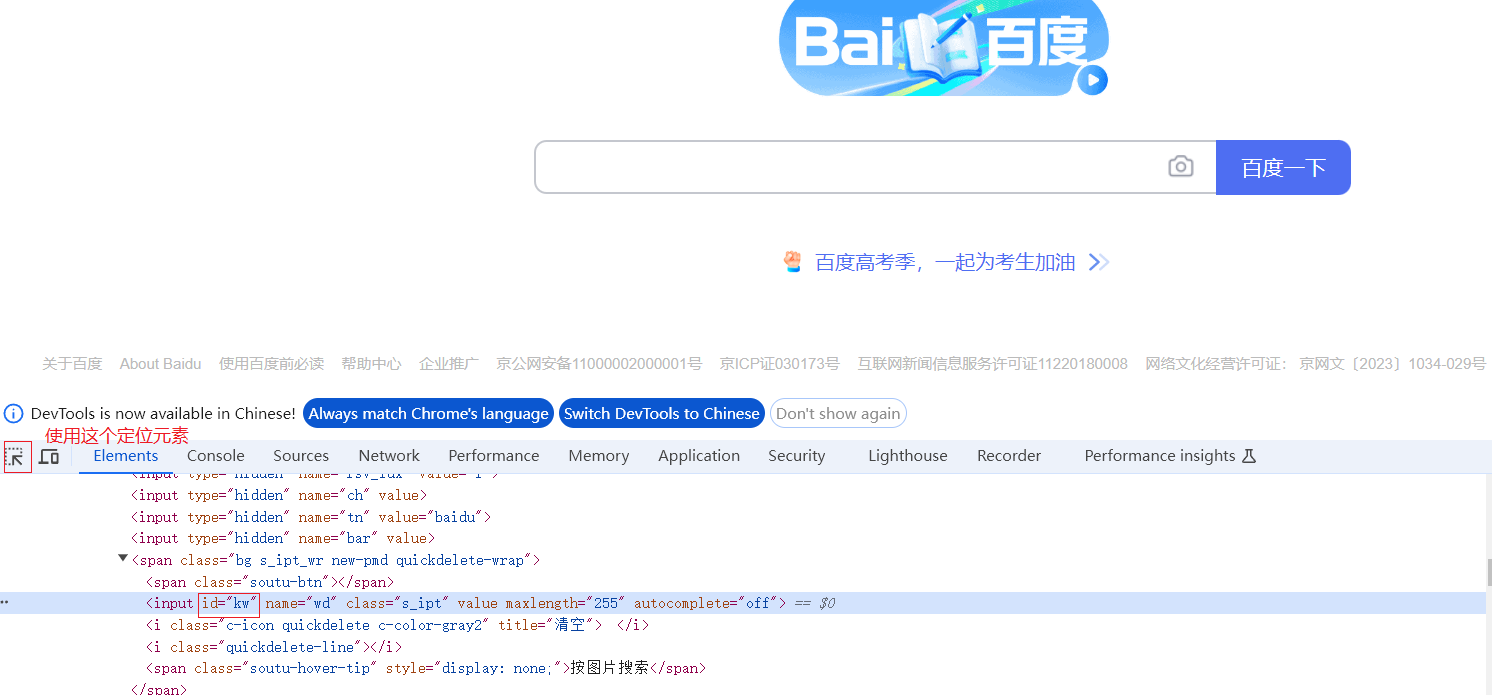
可以看到百度的搜索框对应的input标签中有一个id属性,值是kw,对于css来说,id类型的一般都是唯一的,所以我们就可以通过id来定位到这个input元素,然后对他进行操作。代码如下
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 创建 WebDriver 对象,指明使用chrome浏览器驱动 r表示‘\’不转义
# wd = webdriver.Chrome(service=Service(r'D:\SoftWareTest\engine\chromedriver-win64\chromedriver.exe'))
wd = webdriver.Chrome()
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get('https://www.baidu.com')
# 根据id选择元素,返回的就是该元素对应的WebElement对象
element = wd.find_element(By.ID, 'kw')
# 通过该 WebElement对象,就可以对页面元素进行操作了
# 比如输入字符串到 这个 输入框里
#调用这个对象的 send_keys 方法就可以在对应的元素中 输入字符串,
# 调用这个对象的 click 方法就可以 点击 该元素。
#element.send_keys('白月黑羽')
# 点击button按钮
#element = wd.find_element(By.ID,'su')
#element.click()
#\n就相当于搜索框中一个enter操作,和上面的代码效果相同
element.send_keys('白月黑羽\n')
# 程序运行完会自动关闭浏览器,就是很多人说的闪退
# 这里加入等待用户输入,防止闪退
input('等待回车键结束程序')根据 class属性 选择元素
除了根据元素的id ,我们还可以根据元素的 class 属性选择元素。
我们可以通过指定 参数为 By.CLASS_NAME,选择所有指定的class属性的元素,如下所示
比如打开这个网站(白月黑羽老师提供的):网站
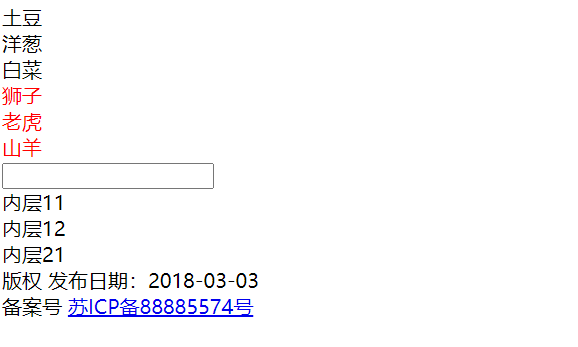
点击F12,打开开发者工具
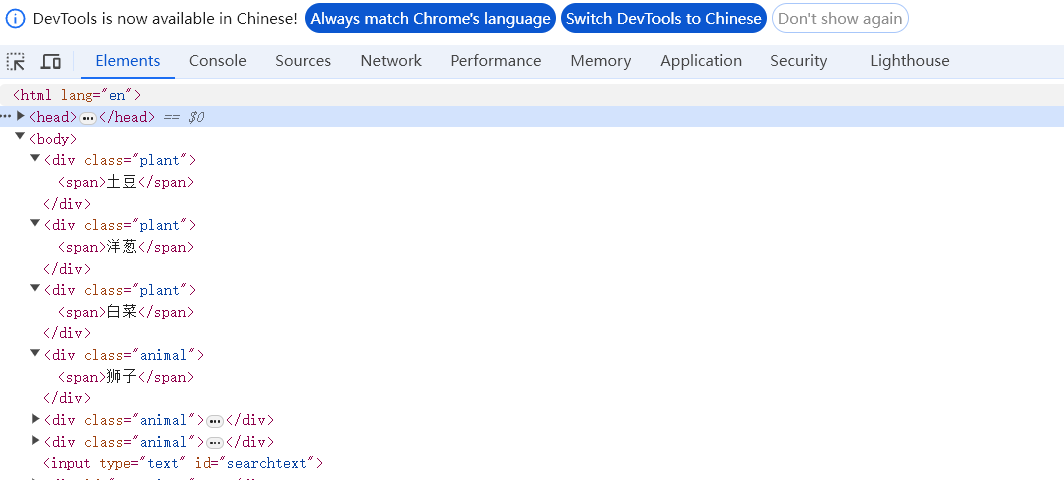
接下来,我们通过class属性定位到class="plant"的元素,代码如下
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
# 如果根据class值找到的元素不止一个,就会返回一个数组,如果找不到,返回一个空数组
elements=wd.find_elements(By.CLASS_NAME,'plant')
for e in elements:
print(e.text) # e.text:获取元素对应的文本值
input("等待回车键结束程序")控制台输出:
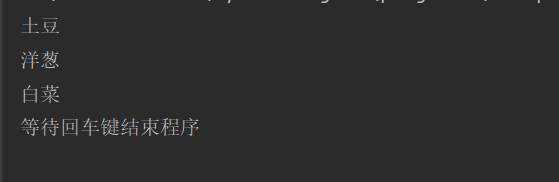
注意:如果我们把上面的elements修改为element
elements = wd.find_elements(By.CLASS_NAME, 'plant')那么就会找到class属性为plant的第一个元素返回,如果找不到,报错
元素也可以有 多个class类型 ,多个class类型的值之间用 空格 隔开,比如
<span class="chinese student">张三</span>
注意,这里 span元素 有两个class属性,分别 是 chinese 和 student, 而不是一个 名为 chinese student 的属性。
我们要用代码选择这个元素,可以指定任意一个class 属性值,都可以选择到这个元素,如下
element = wd.find_elements(By.CLASS_NAME,'chinese')
或者
element = wd.find_elements(By.CLASS_NAME,'student')
而不能这样写
element = wd.find_elements(By.CLASS_NAME,'chinese student')根据Tag名选择元素
我们可以通过指定 参数为 By.TAG_NAME ,选择所有指定的tag名的元素,如下所示
依旧是访问上面那个网站
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
elements=wd.find_elements(By.TAG_NAME,'div')
for e in elements:
print(e.text)
input("等待回车键结束程序")控制台输出
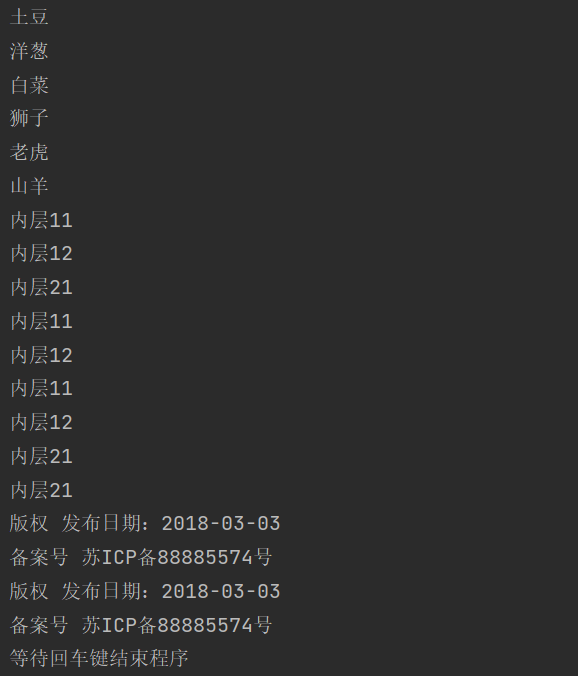
find_element 和 find_elements 的区别
使用 find_elements 选择的是符合条件的 所有 元素, 如果没有符合条件的元素, 返回空数组
使用 find_element 选择的是符合条件的 第一个 元素, 如果没有符合条件的元素, 抛出 NoSuchElementException 异常
通过WebElement对象选择元素
不仅 WebDriver对象有 选择元素 的方法, WebElement对象 也有选择元素的方法。
WebElement对象 也可以调用 find_elements, find_element 之类的方法。
WebDriver 对象 选择元素的范围是 整个 web页面, 而WebElement 对象 选择元素的范围是 该元素的内部。
依旧访问上面那个网站
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
element=wd.find_element(By.ID,'container')
elements=element.find_elements(By.TAG_NAME,'div')
for e in elements:
print(e.text)
input("等待回车键结束程序")控制台输出结果:

等待界面元素出现
在我们进行网页操作的时候, 有的元素内容不是可以立即出现的, 可能会等待一段时间。
比如我们在百度页面搜索示例时, 在输入框输入一个内容, 我们点击搜索后, 浏览器需要把这个搜索请求发送给服务器, 服务器进行处理后,再把搜索结果返回给我们。得到这个结果后,我们才能找得到这个页面中的元素。
所以,从点击搜索到得到结果,需要一定的时间,只是通常 服务器的处理比较快,我们感觉好像是立即出现了搜索结果。
实现方式:
方法1:使用sleep 来等待几秒
# 等待 1 秒
from time import sleep
sleep(1)方法2:
Selenium提供了一个更合理的解决方案,当发现元素没有找到的时候, 并不立即返回 找不到元素的错误。而是周期性(每隔半秒钟)重新寻找该元素,直到该元素找到,或者超出指定最大等待时长,这时才 抛出异常(如果是 find_elements 之类的方法, 则是返回空列表)。
Selenium 的 Webdriver 对象 有个方法叫 implicitly_wait ,可以称之为 隐式等待 ,或者 全局等待 。
该方法接受一个参数, 用来指定 最大等待时长。只需要加入如下代码
wd.implicitly_wait(10)
那么后续所有的 find_element 或者 find_elements 之类的方法调用 都会采用上面的策略:
如果找不到元素, 每隔 半秒钟 再去界面上查看一次, 直到找到该元素, 或者 过了10秒 最大时长。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 创建 WebDriver 对象,指明使用chrome浏览器驱动 r表示‘\’不转义
# wd = webdriver.Chrome(service=Service(r'D:\SoftWareTest\engine\chromedriver-win64\chromedriver.exe'))
wd = webdriver.Chrome()
# 如果找不到对应的元素,每隔半秒钟再去找一次,知道时间到达10秒,如果还没有找到,就继续执行下面的语句
wd.implicitly_wait(10)
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get('https://www.baidu.com')
# 根据id选择元素,返回的就是该元素对应的WebElement对象
element = wd.find_element(By.ID, 'kw')
# 通过该 WebElement对象,就可以对页面元素进行操作了
# 比如输入字符串到 这个 输入框里
#调用这个对象的 send_keys 方法就可以在对应的元素中 输入字符串,
# 调用这个对象的 click 方法就可以 点击 该元素。
#\n就相当于搜索框中一个enter操作,和上面的代码效果相同
element.send_keys('白月黑羽\n')
elements = wd.find_elements(By.TAG_NAME,'em')
for e in elements:
e.click()
element.clear() # 清除输入框已有的字符串
# 程序运行完会自动关闭浏览器,就是很多人说的闪退
# 这里加入等待用户输入,防止闪退
input('等待回车键结束程序')操作元素的基本方法
选择到元素之后,我们的代码会返回元素对应的 WebElement对象,通过这个对象,我们就可以 操控 元素了。
操控元素通常包括
点击元素
在元素中输入字符串,通常是对输入框这样的元素
获取元素包含的信息,比如文本内容,元素的属性
点击元素
点击元素 非常简单,就是调用元素WebElement对象的 click方法。
当我们调用 WebElement 对象的 click 方法去点击 元素的时候, 浏览器接收到自动化命令,点击的是该元素的 中心点 位置
输入框
输入字符串 就是调用元素WebElement对象的send_keys方法。
如果我们要 把输入框中已经有的内容清除掉,可以使用WebElement对象的clear方法
获取元素信息
获取元素的文本内容
通过WebElement对象的 text 属性,可以获取元素 展示在界面上的 文本内容。
比如:
element = wd.find_element(By.ID, 'animal')
print(element.text)获取元素文本内容2
通过WebElement对象的 text 属性,可以获取元素 展示在界面上的 文本内容。
但是,有时候,元素的文本内容没有展示在界面上,或者没有完全完全展示在界面上。 这时,用WebElement对象的text属性,获取文本内容,就会有问题。
出现这种情况,可以尝试使用 element.get_attribute('innerText') ,或者 element.get_attribute('textContent')
使用 innerText 和 textContent 的区别是,前者只显示元素可见文本内容,后者显示所有内容(包括display属性为none的部分)
获取元素属性
通过WebElement对象的 get_attribute 方法来获取元素的属性值
比如要获取元素属性class的值,就可以使用 element.get_attribute('class')
如下:
element = wd.find_element(By.ID, 'IdValue')
print(element.get_attribute('class'))
获取整个元素对应的HTML
要获取整个元素对应的HTML文本内容,可以使用 element.get_attribute('outerHTML')
如果,只是想获取某个元素 内部 的HTML文本内容,可以使用 element.get_attribute('innerHTML')
获取输入框里面的文字
对于input输入框的元素,要获取里面的输入文本,用text属性是不行的,这时可以使用 element.get_attribute('value')
比如
element = wd.find_element(By.ID, "input1")
print(element.get_attribute('value')) # 获取输入框中的文本通过CSS表达式选择元素
前面我们看到了根据 id、class属性、tag名 选择元素,但是这些选择元素的操作都比较不灵活。
如果我们要选择的 元素 没有id、class 属性,或者有些我们不想选择的元素 也有相同的 id、class属性值,怎么办呢?
这时候我们通常可以通过 CSS selector 语法选择元素。
CSS Selector 语法就是用来选择元素的。
既然 CSS Selector 语法天生就是浏览器用来选择元素的,selenium自然就可以使用它用在自动化中,去选择要操作的元素了。
只要 CSS Selector 的语法是正确的, Selenium 就可以选择到该元素。
CSS Selector 非常强大,学习Selenium Web自动化一定要学习 CSS Selector
通过 CSS Selector 选择单个元素的方法是
find_element(By.CSS_SELECTOR, CSS Selector参数)
选择所有元素的方法是
find_elements(By.CSS_SELECTOR, CSS Selector参数)根据 tag名、id、class 选择元素
根据 tag名 选择元素的 CSS Selector 语法非常简单,直接写上tag名即可,
比如 要选择 所有的tag名为div的元素,就可以是这样
elements = wd.find_elements(By.CSS_SELECTOR, 'div')
等价于
elements = wd.find_elements(By.TAG_NAME, 'div')根据id属性 选择元素的语法是在id号前面加上一个井号: #id值
比如 请打开这个网址
有下面这样的元素:
<input type="text" id='searchtext' />
就可以使用 #searchtext 这样的 CSS Selector 来选择它。
比如,我们想在 id 为 searchtext 的输入框中输入文本 你好 ,代码如下
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
element = wd.find_element(By.CSS_SELECTOR, '#searchtext')
element.send_keys('你好')根据class属性 选择元素的语法是在 class 值 前面加上一个点: .class值
比如还是上面那个网址,要选择所有 class 属性值为 animal的元素,除了这样写
elements = wd.find_elements(By.CLASS_NAME, 'animal')
还可以这样写
elements = wd.find_elements(By.CSS_SELECTOR, '.animal')
因为是选择 所有 符合条件的 ,所以用 find_elements 而不是 find_element
选择 子元素和后代元素
HTML中, 元素 内部可以 包含其他元素, 比如 下面的 HTML片段
<div id='container'>
<div id='layer1'>
<div id='inner11'>
<span>内层11</span>
</div>
<div id='inner12'>
<span>内层12</span>
</div>
</div>
<div id='layer2'>
<div id='inner21'>
<span>内层21</span>
</div>
</div>
</div>
layer1是container的直接子元素,inner11是container的后代元素。直接子元素也是后代元素。
如果 元素2 是 元素1 的 直接子元素, CSS Selector 选择子元素的语法是这样的
元素1 > 元素2
中间用一个大于号 连接
注意,最终选择的元素是 元素2, 并且要求这个 元素2 是 元素1 的直接子元素
也支持更多层级的选择, 比如
元素1 > 元素2 > 元素3 > 元素4
就是选择 元素1 里面的子元素 元素2 里面的子元素 元素3 里面的子元素 元素4 , 最终选择的元素是 元素4
如果 元素2 是 元素1 的 后代元素, CSS Selector 选择后代元素的语法是这样的
元素1 元素2
中间是一个或者多个空格隔开
最终选择的元素是 元素2 , 并且要求这个 元素2 是 元素1 的后代元素。
也支持更多层级的选择, 比如
元素1 元素2 元素3 元素4
最终选择的元素是 元素4。
根据属性选择
id、class 都是web元素的 属性 ,因为它们是很常用的属性,所以css选择器专门提供了根据 id、class 选择的语法。那么其他的属性呢?
比如
<a href="http://www.miitbeian.gov.cn">苏ICP备88885574号</a>
想要根据 href选择对应的元素,应该怎么做呢?
css 选择器支持通过任何属性来选择元素,语法是用一个方括号 [] 。
比如要选择上面的a元素,就可以使用 [href="http://www.miitbeian.gov.cn"] 。
这个表达式的意思是,选择 属性href值为 http://www.miitbeian.gov.cn 的元素。
完整代码如下
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
# 根据属性选择元素
element = wd.find_element(By.CSS_SELECTOR, '[href="http://www.miitbeian.gov.cn"]')
# 打印出元素对应的html
print(element.get_attribute('outerHTML'))
前面也可以加上标签名的限制,比如 div[class='SKnet'] 表示 选择所有 标签名为div,且class属性值为SKnet的元素。
根据属性选择,还可以不指定属性值,比如 [href] , 表示选择 所有 具有 属性名 为href 的元素,不管它们的值是什么。
CSS 还可以选择 属性值 包含 某个字符串 的元素
比如, 要选择a节点,里面的href属性包含了 miitbeian 字符串,就可以这样写
a[href*="miitbeian"]
还可以 选择 属性值 以某个字符串 开头 的元素
比如, 要选择a节点,里面的href属性以 http 开头 ,就可以这样写
a[href^="http"]
还可以 选择 属性值 以某个字符串 结尾 的元素
比如, 要选择a节点,里面的href属性以 gov.cn 结尾 ,就可以这样写
a[href$="gov.cn"]
如果一个元素具有多个属性
<div class="misc" ctype="gun">沙漠之鹰</div>
CSS 选择器 可以指定 选择的元素要 同时具有多个属性的限制, div[class=misc][ctype=gun]
表示选择div标签中class属性值为misc,ctype属性为gun的元素
在浏览器中验证 CSS Selector语句的正确性
在浏览器中,按F12打开开发者工具,点击 Elements 标签后, 同时按 Ctrl 键 和 F 键, 就会出现下图所示的搜索框
选择语法联合使用
CSS selector的另一个强大之处在于: 选择语法 可以 联合使用
比如, 我们要选择 网页 html 中的元素 <span class='copyright'>版权</span>
<div id='bottom'>
<div class='footer1'>
<span class='copyright'>版权</span>
<span class='date'>发布日期:2018-03-03</span>
</div>
<div class='footer2'>
<span>备案号
<a href="http://www.miitbeian.gov.cn">苏ICP备88885574号</a>
</span>
</div>
</div>
CSS selector 表达式 可以这样写:
div.footer1 > span.copyright
表示选择一个class属性为footer1的div节点的儿子节点,要求这个儿子节点必须是class属性为copyright的span节点。
组选择
如果我们要 同时选择所有class 为 plant 和 class 为 animal 的元素。怎么办?
这种情况,css选择器可以 使用 逗号 ,称之为 组选择 ,像这样
.plant , .animal
再比如,我们要同时选择所有tag名为div的元素 和 id为BYHY的元素,就可以像这样写
div,#BYHY
对应的selenium代码如下
elements = wd.find_elements(By.CSS_SELECTOR, 'div,#BYHY')
for element in elements:
print(element.text)
按次序选择子节点
对应的html如下,关键信息如下
<body>
<div id='t1'>
<h3> 唐诗 </h3>
<span>李白</span>
<p>静夜思</p>
<span>杜甫</span>
<p>春夜喜雨</p>
</div>
<div id='t2'>
<h3> 宋词 </h3>
<span>苏轼</span>
<p>赤壁怀古</p>
<p>明月几时有</p>
<p>江城子·乙卯正月二十日夜记梦</p>
<p>蝶恋花·春景</p>
<span>辛弃疾</span>
<p>京口北固亭怀古</p>
<p>青玉案·元夕</p>
<p>西江月·夜行黄沙道中</p>
</div>
</body>选择父元素的第n个节点
我们可以指定选择的元素 是父元素的第几个子节点
使用 nth-child
比如:
我们要选择 唐诗 和 宋词 的第一个 作者,
也就是说 选择的是 第2个子元素,并且是span类型
所以可以这样写 span:nth-child(2) ,
如果你不加节点类型限制,直接这样写:nth-child(2)
就是选择所有位置为第2个的所有元素,不管是什么类型
选择父元素的倒数第n个节点
也可以反过来, 选择的是父元素的 倒数第几个子节点 ,使用 nth-last-child
比如:p:nth-last-child(1)
就是选择第倒数第1个子元素,并且是p元素
选择父元素的第几个某类型的子节点
我们可以指定选择的元素是父元素的第几个某类型的子节点
使用 nth-of-type
比如,
我们要选择 唐诗 和宋词 的第一个 作者,
可以像上面那样思考:选择的是 第2个子元素,并且是span类型
所以可以这样写 span:nth-child(2) ,
还可以这样思考,选择的是 第1个span类型 的子元素
所以也可以这样写 span:nth-of-type(1)
选择父元素的倒数第几个某类型的子节点
当然也可以反过来, 选择父元素的 倒数第几个某类型 的子节点
使用 nth-last-of-type
像这样:p:nth-last-of-type(2)
选择奇数节点和偶数节点
如果要选择的是父元素的 偶数节点,使用 nth-child(even)
比如:p:nth-child(even)
如果要选择的是父元素的 奇数节点,使用 nth-child(odd)
比如:p:nth-child(odd)
如果要选择的是父元素的 某类型偶数节点,使用 nth-of-type(even)
如果要选择的是父元素的 某类型奇数节点,使用 nth-of-type(odd)
选择兄弟节点
选择相邻兄弟节点
上面的例子里面,我们要选择 唐诗 和 宋词 的第一个作者
还有一种思考方法,就是选择 h3 后面紧跟着的兄弟节点 span。
这就是一种 相邻兄弟 关系,可以这样写 h3 + span
表示元素 紧跟关系的 是 加号
选择后续所有兄弟节点
如果要选择是 选择 h3 后面所有的兄弟节点 span,可以这样写 h3~span
frame切换
如果我们想要选择的元素是在一个iframe标签下的,那么我们就不可以用以前的方法直接定位这个元素。
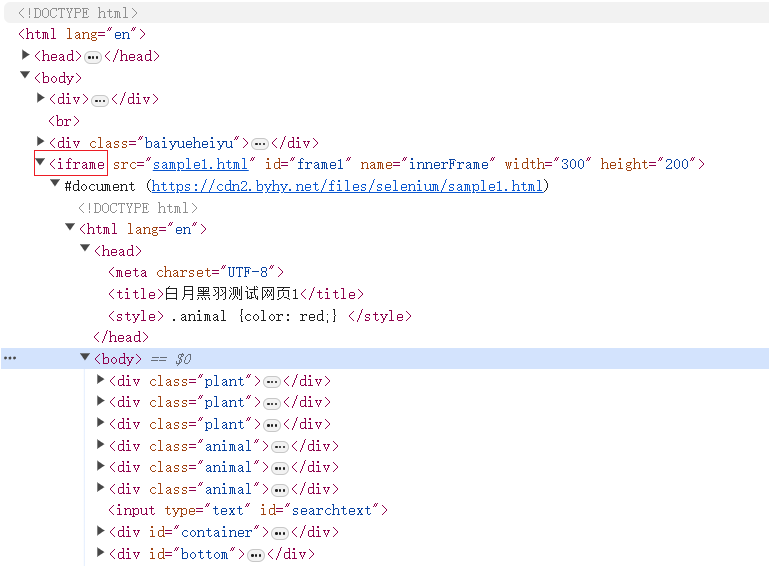
这个 iframe 元素非常的特殊, 在html语法中,frame 元素 或者iframe元素的内部 会包含一个 被嵌入的 另一份html文档。
在我们使用selenium打开一个网页,我们的操作范围是当前的 html , 并不包含被嵌入的html文档里面的内容。
如果我们要 操作 被嵌入的 html 文档 中的元素, 就必须 切换操作范围 到 被嵌入的文档中。
使用 WebDriver 对象的 switch_to 属性,像这样
wd.switch_to.frame(frame_reference)
其中, frame_reference 可以是 frame 元素的属性 name 或者 ID 。
比如这里,就可以填写 iframe元素的id 'frame1' 或者 name属性值 'innerFrame'。
像这样
wd.switch_to.frame('frame1')
或者
wd.switch_to.frame('innerFrame')
也可以填写frame 所对应的 WebElement 对象。
我们可以根据frame的元素位置或者属性特性,使用find系列的方法,选择到该元素,得到对应的WebElement对象
比如,这里就可以写
wd.switch_to.frame(wd.find_element(By.TAG_NAME, "iframe"))
然后,就可以进行后续操作frame里面的元素了。
如果我们已经切换到某个iframe里面进行操作了,那么后续选择和操作界面元素 就都是在这个frame里面进行的。
这时候,如果我们又需要操作 主html(我们把最外部的html称之为主html) 里面的元素了呢?
怎么切换回原来的主html呢?
很简单,写如下代码即可
wd.switch_to.default_content()举例:
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/sample2.html')
# 先根据name属性值 'innerFrame',切换到iframe中
wd.switch_to.frame('innerFrame')
# 根据 class name 选择元素,返回的是 一个列表
elements = wd.find_elements(By.CLASS_NAME, 'plant')
for element in elements:
print(element.text)
# 切换回 最外部的 HTML 中
wd.switch_to.default_content()
# 然后再 选择操作 外部的 HTML 中 的元素
wd.find_element_by_id('outerbutton').click()
wd.quit()窗口切换
在网页上操作的时候,我们经常遇到,点击一个链接 或者 按钮,就会打开一个 新窗口 。
在测试网站中,点击 链接 访问bing网站 , 就会弹出一个新窗口,访问bing网址。
如果我们用Selenium写自动化程序 在新窗口里面 打开一个新网址, 并且去自动化操作新窗口里面的元素,会有什么问题呢?
问题就在于,即使新窗口打开了, 这时候,我们的 WebDriver对象对应的 还是老窗口,自动化操作也还是在老窗口进行,
我们可以运行如下代码验证一下
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.implicitly_wait(10)
wd.get('https://cdn2.byhy.net/files/selenium/sample3.html')
# 点击打开新窗口的链接
link = wd.find_element(By.TAG_NAME, "a")
link.click()
# wd.title属性是当前窗口的标题栏 文本
print(wd.title)
运行完程序后,最后一行 打印当前窗口的标题栏 文本, 输出内容是
白月黑羽测试网页3
说明, 我们的 WebDriver对象指向的还是老窗口,否则的话,运行结果就应该新窗口的标题栏 "微软Bing搜索"
如果我们要到新的窗口里面操作,该怎么做呢?
可以使用Webdriver对象的switch_to属性的 window方法,如下所示:
wd.switch_to.window(handle)
其中,参数handle需要传入什么呢?
WebDriver对象有window_handles 属性,这是一个列表对象, 里面包括了当前浏览器里面所有的窗口句柄。
所谓句柄,大家可以想象成对应网页窗口的一个ID,
那么我们就可以通过 类似下面的代码,
for handle in wd.window_handles:
# 先切换到该窗口
wd.switch_to.window(handle)
# 得到该窗口的标题栏字符串,判断是不是我们要操作的那个窗口
if '微软Bing搜索' in wd.title:
# 如果是,那么这时候WebDriver对象就是对应的该该窗口,正好,跳出循环,
break
上面代码的用意就是:
我们依次获取 wd.window_handles 里面的所有 句柄 对象, 并且调用 wd.switch_to.window(handle) 方法,切入到每个窗口,
然后检查里面该窗口对象的属性(可以是标题栏,地址栏),判断是不是我们要操作的那个窗口,如果是,就跳出循环。
同样的,如果我们在新窗口 操作结束后, 还要回到原来的窗口,该怎么办?
我们可以仍然使用上面的方法,依次切入窗口,然后根据 标题栏 之类的属性值判断。
还有更省事的方法。
因为我们一开始就在 原来的窗口里面,我们知道 进入新窗口操作完后,还要回来,可以事先 保存该老窗口的 句柄,使用如下方法
# mainWindow变量保存当前窗口的句柄
mainWindow = wd.current_window_handle
切换到新窗口操作完后,就可以直接像下面这样,将driver对应的对象返回到原来的窗口
#通过前面保存的老窗口的句柄,自己切换到老窗口
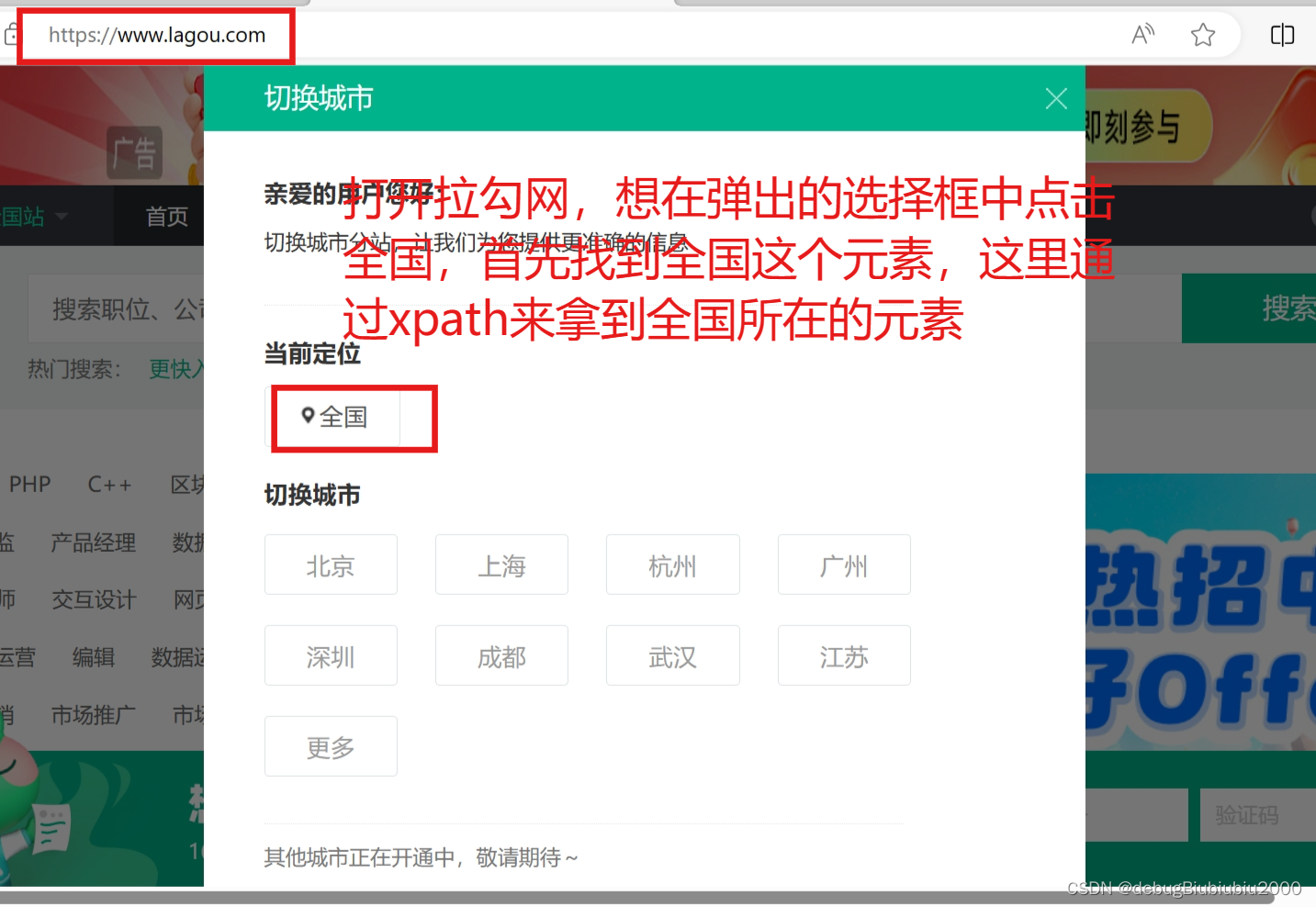
wd.switch_to.window(mainWindow)定位选择框元素
Radio单选框
radio框选择选项,直接用WebElement的click方法,模拟用户点击就可以了。
比如, 我们要在下面的html中:
- 先打印当前选中的老师名字
- 再选择 小雷老师
<div id="s_radio">
<input type="radio" name="teacher" value="小江老师">小江老师<br>
<input type="radio" name="teacher" value="小雷老师">小雷老师<br>
<input type="radio" name="teacher" value="小凯老师" checked="checked">小凯老师
</div>
对应的代码如下
# 获取当前选中的元素
element = wd.find_element(By.CSS_SELECTOR, '#s_radio input[name="teacher"]:checked')
print('当前选中的是: ' + element.get_attribute('value'))
# 点选 小雷老师
wd.find_element(By.CSS_SELECTOR, '#s_radio input[value="小雷老师"]').click()其中 #s_radio input[name="teacher"]:checked 里面的 :checked 是CSS伪类选择,表示选择 checked 状态的元素,对 radio 和 checkbox 类型的input有效
CheckBox复选框
对checkbox进行选择,也是直接用 WebElement 的 click 方法,模拟用户点击选择。
需要注意的是,要选中checkbox的一个选项,必须 先获取当前该复选框的状态 ,如果该选项已经勾选了,就不能再点击。否则反而会取消选择。
比如, 我们要在下面的html中:选中 小雷老师
<div id="s_checkbox">
<input type="checkbox" name="teacher" value="小江老师">小江老师<br>
<input type="checkbox" name="teacher" value="小雷老师">小雷老师<br>
<input type="checkbox" name="teacher" value="小凯老师" checked="checked">小凯老师
</div>
我们的思路可以是这样:
- 先把 已经选中的选项全部点击一下,确保都是未选状态
- 再点击 小雷老师
示例代码
# 先把 已经选中的选项全部点击一下
elements = wd.find_elements(By.CSS_SELECTOR, '#s_checkbox input[name="teacher"]:checked')
for element in elements:
element.click()
# 再点击 小雷老师
wd.find_element(By.CSS_SELECTOR, "#s_checkbox input[value='小雷老师']").click()Select选择框
radio框及checkbox框都是input元素,只是里面的type不同而已。
select框 则是一个新的select标签,大家可以对照浏览器网页内容查看一下
对于Select 选择框, Selenium 专门提供了一个 Select类 进行操作。
Select类 提供了如下的方法
- select_by_value
根据选项的 value属性值 ,选择元素。
比如,下面的HTML,
<option value="foo">Bar</option>
就可以根据 foo 这个值选择该选项,
s.select_by_value('foo')
- select_by_index
根据选项的 次序 (从0开始),选择元素
select_by_index(0) ,选择的是 第1个选项,
select_by_index(1) ,选择的是 第2个选项, 依此类推
- select_by_visible_text
根据选项的 可见文本 ,选择元素。
比如,下面的HTML,
<option value="foo">Bar</option>
就可以根据 Bar 这个内容,选择该选项
s.select_by_visible_text('Bar')
- deselect_by_value
根据选项的value属性值, 去除 选中元素
- deselect_by_index
根据选项的次序,去除 选中元素
- deselect_by_visible_text
根据选项的可见文本,去除 选中元素
- deselect_all
去除 选中所有元素
Xpath选择器
前面我们学习了CSS 选择元素,大家可以发现非常灵活、强大。
还有一种 灵活、强大 的选择元素的方式,就是使用 Xpath 表达式。
XPath (XML Path Language) 是由国际标准化组织W3C指定的,用来在 XML 和 HTML 文档中选择节点的语言。
目前主流浏览器 (chrome、firefox,edge,safari) 都支持XPath语法,xpath有 1 和 2 两个版本,目前浏览器支持的是 xpath 1的语法。
既然已经有了CSS,为什么还要学习 Xpath呢? 因为
有些场景 用 css 选择web 元素 很麻烦,而xpath 却比较方便。
另外 Xpath 还有其他领域会使用到,比如 爬虫框架 Scrapy, 手机App框架 Appium。
按F12打开调试窗口,点击 Elements标签。
要验证 Xpath 语法是否能成功选择元素,也可以像 验证 CSS 语法那样,按组合键 Ctrl + F ,就会出现 搜索框
xpath 语法中,整个HTML文档根节点用'/'表示,如果我们想选择的是根节点下面的html节点,则可以在搜索框输入
/html
如果输入下面的表达式
/html/body/div
这个表达式表示选择html下面的body下面的div元素。
注意 / 有点像 CSS中的 > , 表示直接子节点关系。
绝对路径选择
从根节点开始的,到某个节点,每层都依次写下来,每层之间用 / 分隔的表达式,就是某元素的 绝对路径
上面的xpath表达式 /html/body/div ,就是一个绝对路径的xpath表达式, 等价于 css表达式 html>body>div
自动化程序要使用Xpath来选择web元素,应该调用 WebDriver对象的方法 find_element_by_xpath 或者 find_elements_by_xpath,像这样:
elements = driver.find_elements(By.XPATH, "/html/body/div")
相对路径选择
有的时候,我们需要选择网页中某个元素, 不管它在什么位置 。
比如,选择示例页面的所有标签名为 div 的元素,如果使用css表达式,直接写一个 div 就行了。
那xpath怎么实现同样的功能呢? xpath需要前面加 // , 表示从当前节点往下寻找所有的后代元素,不管它在什么位置。
所以xpath表达式,应该这样写: //div
'//' 符号也可以继续加在后面,比如,要选择 所有的 div 元素里面的 所有的 p 元素 ,不管div 在什么位置,也不管p元素在div下面的什么位置,则可以这样写 //div//p
对应的自动化程序如下
elements = driver.find_elements(By.XPATH, "//div//p")
如果使用CSS选择器,对应代码如下
elements = driver.find_elements(By.CSS_SELECTOR,"div p")
如果,要选择 所有的 div 元素里面的 直接子节点 p , xpath,就应该这样写了 //div/p
如果使用CSS选择器,则为 div > p
通配符
如果要选择所有div节点的所有直接子节点,可以使用表达式 //div/*
* 是一个通配符,对应任意节点名的元素,等价于CSS选择器 div > *
代码如下:
elements = driver.find_elements(By.XPATH, "//div/*")
for element in elements:
print(element.get_attribute('outerHTML'))
根据属性选择
Xpath 可以根据属性来选择元素。
根据属性来选择元素 是通过 这种格式来的 [@属性名='属性值']
注意:
属性名注意前面有个@
属性值一定要用引号, 可以是单引号,也可以是双引号
根据id属性选择
选择 id 为 west 的元素,可以这样 //*[@id='west']
根据class属性选择
选择所有 select 元素中 class为 single_choice 的元素,可以这样 //select[@class='single_choice']
如果一个元素class 有多个,比如
<p id="beijing" class='capital huge-city'>
北京
</p>
如果要选它, 对应的 xpath 就应该是 //p[@class="capital huge-city"]
不能只写一个属性,像这样 //p[@class="capital"] 就定位不到这个元素
根据其他属性
同样的道理,我们也可以利用其它的属性选择
比如选择 具有multiple属性的所有页面元素 ,可以这样 //*[@multiple]
属性值包含字符串
要选择 style属性值 包含 color 字符串的 页面元素 ,可以这样 //*[contains(@style,'color')]
要选择 style属性值 以 color 字符串 开头 的 页面元素 ,可以这样 //*[starts-with(@style,'color')]
按次序选择
前面学过css表达式可以根据元素在父节点中的次序选择, 非常实用。
xpath也可以根据次序选择元素。 语法比css更简洁,直接在方括号中使用数字表示次序
比如
某类型 第几个 子元素
比如
要选择 p类型第2个的子元素,就是
//p[2]
注意,选择的是 p类型第2个的子元素 , 不是 第2个子元素,并且是p类型 。
注意体会区别
再比如,要选取父元素为div 中的 p类型 第2个 子元素
//div/p[2]
第几个子元素
也可以选择第2个子元素,不管是什么类型,采用通配符
比如 选择父元素为div的第2个子元素,不管是什么类型
//div/*[2]
某类型 倒数第几个 子元素
当然也可以选取倒数第几个子元素
比如:
- 选取p类型倒数第1个子元素
//p[last()]
- 选取p类型倒数第2个子元素
//p[last()-1]
- 选择父元素为div中p类型倒数第3个子元素
//div/p[last()-2]
范围选择
xpath还可以选择子元素的次序范围。
比如,
- 选取option类型第1到2个子元素
//option[position()<=2]
或者
//option[position()<3]
- 选择class属性为multi_choice的前3个子元素
//*[@class='multi_choice']/*[position()<=3]
- 选择class属性为multi_choice的后3个子元素
//*[@class='multi_choice']/*[position()>=last()-2]
为什么不是 last()-3 呢? 因为
last() 本身代表最后一个元素
last()-1 本身代表倒数第2个元素
last()-2 本身代表倒数第3个元素
组选择、父节点、兄弟节点
组选择
css有组选择,可以同时使用多个表达式,多个表达式选择的结果都是要选择的元素
css 组选择,表达式之间用 逗号 隔开
xpath也有组选择, 是用 竖线 隔开多个表达式
比如,要选所有的option元素 和所有的 h4 元素,可以使用
//option | //h4
等同于CSS选择器
option , h4
再比如,要选所有的 class 为 single_choice 和 class 为 multi_choice 的元素,可以使用
//*[@class='single_choice'] | //*[@class='multi_choice']
等同于CSS选择器
.single_choice , .multi_choice
选择父节点
xpath可以选择父节点, 这是css做不到的。
某个元素的父节点用 /.. 表示
比如,要选择 id 为 china 的节点的父节点,可以这样写 //*[@id='china']/.. 。
当某个元素没有特征可以直接选择,但是它有子节点有特征, 就可以采用这种方法,先选择子节点,再指定父节点。
还可以继续找上层父节点,比如 //*[@id='china']/../../..
兄弟节点选择
前面学过 css选择器,要选择某个节点的后续兄弟节点,用 波浪线
xpath也可以选择 后续 兄弟节点,用这样的语法 following-sibling::
比如,要选择 class 为 single_choice 的元素的所有后续兄弟节点 //*[@class='single_choice']/following-sibling::*
等同于CSS选择器 .single_choice ~ *
如果,要选择后续节点中的div节点, 就应该这样写 //*[@class='single_choice']/following-sibling::div
xpath还可以选择 前面的 兄弟节点,用这样的语法 preceding-sibling::
比如,要选择 class 为 single_choice 的元素的 所有 前面的兄弟节点,这样写
//*[@class='single_choice']/preceding-sibling::*
要选择 class 为 single_choice 的元素的前面最靠近的兄弟节点 , 这样写
//*[@class='single_choice']/preceding-sibling::*[1]
前面第2靠近的兄弟节点 , 这样写
//*[@class='single_choice']/preceding-sibling::*[2]
而 CSS选择器 目前还没有方法选择 前面的 兄弟节点
Xpath注意点
我们来看一个例子
我们的代码:
先选择示例网页中,id是china的元素
然后通过这个元素的WebElement对象,使用find_elements_by_xpath,选择里面的p元素,
# 先寻找id是china的元素
china = wd.find_element(By.ID, 'china')
# 再选择该元素内部的p元素
elements = china.find_elements(By.XPATH, '//p')
# 打印结果
for element in elements:
print('----------------')
print(element.get_attribute('outerHTML'))
运行发现,打印的 不仅仅是 china内部的p元素, 而是所有的p元素。
要在某个元素内部使用xpath选择元素, 需要 在xpath表达式最前面加个点 。
像这样
elements = china.find_elements(By.XPATH, './/p')