😄 19年之后由于某些原因断更了三年,23年重新扬帆起航,推出更多优质博文,希望大家多多支持~
🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志
🎐 个人CSND主页——Micro麦可乐的博客
🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战
🌺《RabbitMQ》本专栏主要介绍使用JAVA开发RabbitMQ的系列教程,从基础知识到项目实战
🌸《设计模式》专栏以实际的生活场景为案例进行讲解,让大家对设计模式有一个更清晰的理解
💕《Jenkins实战》专栏主要介绍Jenkins+Docker+Git+Maven的实战教程,让你快速掌握项目CI/CD,是2024年最新的实战教程
如果文章能够给大家带来一定的帮助!欢迎关注、评论互动~
Spring Boot整合开源 Tess4J 实现OCR图片文字识别
1、前言
之前在某一个项目中,客户要求根据上传的文档图片系统自动识别图片内容,这就需要到了OCR技术,我们公司一般做法通常是使用阿里云或腾讯云的OCR图片识别(大厂的训练量更多更大,识别更精准)无奈客户资金有限,又希望我们满足需求,最后我们决定采用开源Tesseract 文字识别 OCR 引擎来实现
Tesseract 是一个功能强大的 OCR 引擎,其发展经历了多个版本的迭代。最初由惠普实验室开发,后由 Google 维护和发展。Tesseract 通过神经网络和图像处理技术,对图像中的文字进行识别和提取。
2、什么是 Tess4J
Tess4J 是一个 Java 的 OCR(光学字符识别)库,基于 Tesseract OCR 引擎实现。Tess4J 为 Java 开发者提供了一个便捷的接口,能够在 Java 项目中轻松调用 Tesseract 的 OCR 功能。
温馨提示
Tess4J 只是就是封装了Tesseract OCR的API,让Java可以直接调用,千万不要错误以为是Tess4J实现的
3、项目初始化
3.1 引入Tess4J 依赖
创建 Spring Boot 项目,打开 pom.xml 文件,添加 Tess4J 的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- tess4j 最新版5.11.0 -->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.11.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
3.2 配置 Tesseract 数据文件
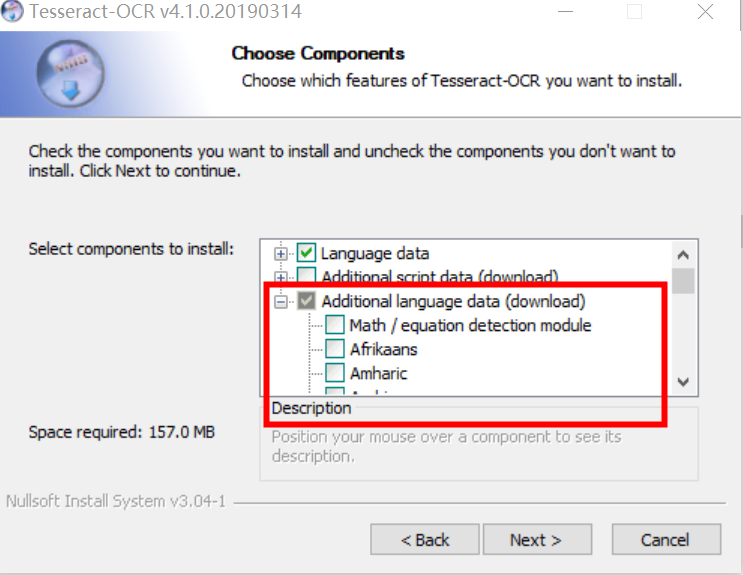
Tess4J 依赖 Tesseract 数据文件来识别不同语言的文本。可以从 Tesseract Github仓库 下载所需语言的训练数据。

如上图所示:Tesseract有三个独立的语言模型存储库 tessdata、tessdata-best、tessdata-fast 他们分别都存储了语言模型,主要有以下区别
| 数据模型存储库 | 描述 | 速度 | 识别精度 | 支持再训练 |
|---|---|---|---|---|
| tessdata_best | 最好(最准确)的训练LSTM模型 | 最慢 | 最高 | 支持 |
| tessdata | 使用“最佳”LSTM模型+遗留模型的快速变体训练模型 | 均衡 | 均衡 | 不支持 |
| tessdata_fast | 训练LSTM模型的快速版本 | 最快 | 最低 | 不支持 |
博主选择Tesseract最高的 tessdata_best 中文数据文件,下载完成后,将数据文件放在项目的资源目录中,src/main/resources/tessdata
如果你只是处理中文、英文的文字识别,无需将整个库下载,找到chi_sim.traineddata 和eng.traineddata下载即可
如果整个存储库下载过大,大家根据自己的需求下载对应语言版本或者特殊的模型(如数学公式:equ.traineddata 模型),语言版本参考官方地址:https://tesseract-ocr.github.io/tessdoc/Data-Files.html

4、代码实现
4.1 创建 OCR 服务类
首先,创建一个 OCR 服务类,用于处理图片文字识别的逻辑
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import org.springframework.stereotype.Service;
import java.io.File;
@Service
public class OCRService {
public String extractTextFromImage(File imageFile) {
Tesseract instance = new Tesseract();
//设置 tessdata 目录
instance.setDatapath("src/main/resources/tessdata");
//设置语言 中文
instance.setLanguage("chi_sim");
try {
return instance.doOCR(imageFile);
} catch (TesseractException e) {
e.printStackTrace();
return "读取图像时出错";
}
}
}
4.2 创建OCRController
创建一个控制器,用于处理前端请求并调用 OCR 服务
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.io.IOException;
@RestController
@RequestMapping("/api/ocr")
public class OCRController {
@Autowired
private OCRService ocrService;
@PostMapping("/extract-text")
public ResponseEntity<String> extractTextFromImage(@RequestParam("file") MultipartFile file) {
if (file.isEmpty()) {
return new ResponseEntity<>("未选择图片!", HttpStatus.BAD_REQUEST);
}
try {
// 将 MultipartFile 转换为 File
File imageFile = convertMultiPartToFile(file);
String result = ocrService.extractTextFromImage(imageFile);
return new ResponseEntity<>(result, HttpStatus.OK);
} catch (Exception e) {
e.printStackTrace();
return new ResponseEntity<>("文件处理错误", HttpStatus.INTERNAL_SERVER_ERROR);
}
}
private File convertMultiPartToFile(MultipartFile file) throws IOException {
File convFile = new File(System.getProperty("java.io.tmpdir") + "/" + file.getOriginalFilename());
file.transferTo(convFile);
return convFile;
}
}
4.3 开始调试
准备一张文字图片,就以本篇文章开头文案图片来测试;
前端代码这里就不贴了,我们使用Apifox或Postman进行调试,博主这里使用Apifox测试效果如下:


5、出现 Unable to load library 'tesseract’问题
如果有小伙伴在测试过程中出现了 Unable to load library 'tesseract'的异常问题,且你也是MacOS系统,原因通常是因为 Tess4J 无法找到或加载 Tesseract OCR 引擎的本地库,需要在Mac上安装Tesseract lib
#使用homebrew安装
brew install tesseract
#或者
sudo apt-get install tesseract
6、总结
通过以上步骤,我们成功地在 Spring Boot 项目中集成了 Tess4J,实现了图片文字识别功能。本文详细介绍了从项目初始化、服务类和控制器的编写到最终测试,希望对大家有所帮助。如果有更复杂的需求,可以进一步优化和扩展此项目。



























![【YOLOv8改进[CONV]】SPDConv助力YOLOv8目标检测效果 + 含全部代码和详细修改方式 + 手撕结构图](https://img-blog.csdnimg.cn/direct/88836ed3e32440c08d4948201c2816c8.png)