文章目录
论文:Improved Baselines with Visual Instruction Tuning
代码:https://github.com/haotian-liu/LLaVA
出处:威斯康星大学麦迪逊分校 | 微软
一、背景
近期对 LMM 模型的研究比较集中于 visual instruction tuning,也就是指令微调,而且很多工作也证明了通过扩大预训练数据[2,9]、扩大指令跟随数据[9,21,45,46]、扩大视觉编码器[2] 或语言模型[31] 等方式能很好的提升 LMM 的能力。
本文主要基于 LLaVA 第一版的模型,但进行了两个改进,可以带来更好的多模态理解能力:
- MLP cross-modal 连接器
- 结合了学术相关的任务数据,如 VQA
LLaVA-v1.5 和 InstructBLIP [9] 或 Qwen-VL [2] 的不同:
- LLaVA-v1.5:使用最简单的 LMM 架构,只使用开源可获得的数据,约 60 万图文对儿训练了一个简单的全连接投影,训练过程在 8 个 A100 上耗时约 1 天即可完成训练
- QWen-VL:使用了数亿甚至数十亿的数据训练,包含很多不公开的数据,训练耗时很长
现有指令跟随 LMM:
一般的模型架构包含这几个模块,如图 1 所示,LLaVA 应该是最简单的 LMM 结构:
- 模块一:预训练好的 visual backbone 来对图像进行编码
- 模块二:预训练好的 LLM 来理解用户的命令并输出反馈
- 模块三:vision-language cross-modal connector 来将 vision encoder 的输出对齐到 language 模型阈
- 可选模块:visual resampler,来降低 visual patches 的数量
一般的模型的训练流程都包含两阶段:
- stage 1:进行图文对齐的 pretraining 阶段,能够让 visual features 和 language model embedding space 对齐
- stage 2:visual instruction tuning 阶段,能够让模型跟随用户的不同指令
多模态指令跟随数据集:
- 在 nlp 中,已经证明了指令跟随数据的质量很大程度上会影响模型的效果
- LLaVA 是最早使用 text-only GPT-4 来扩展 coco bbox 和 cation dataset 的方法,将 coco 的bbox 和 caption 构造成了三种指令跟随数据
- conversational-style QA
- detailed description
- complex reasoning
- 本文作者为了提高模型 VQA 的能力同时不忘记通用对话能力,作者将 VQA 数据集也做成了和对话一样风格的数据
二、方法
2.1 提升点
LLaVA-v1.5 和 LLaVA 相比有什么提升呢,总体如下:
- LLaVA 的特点:LLaVA 在视觉推理上展现了很好的能力,超越了很多方法,但在只需要简短回答的问题上表现的不太好(如只需要 single-word 的回答),这也说明 LLaVA 没有在大量的数据上进行预训练过(而其他的方法都在大量的数据上进行过预训练)
- LLaVA-v1.5的特点:由于 LLaVA 没有在大量数据上进行预训练导致的上述问题,作者在 LLaVA-v1.5 上扩充了数据量、扩大了模型、提高了分辨率
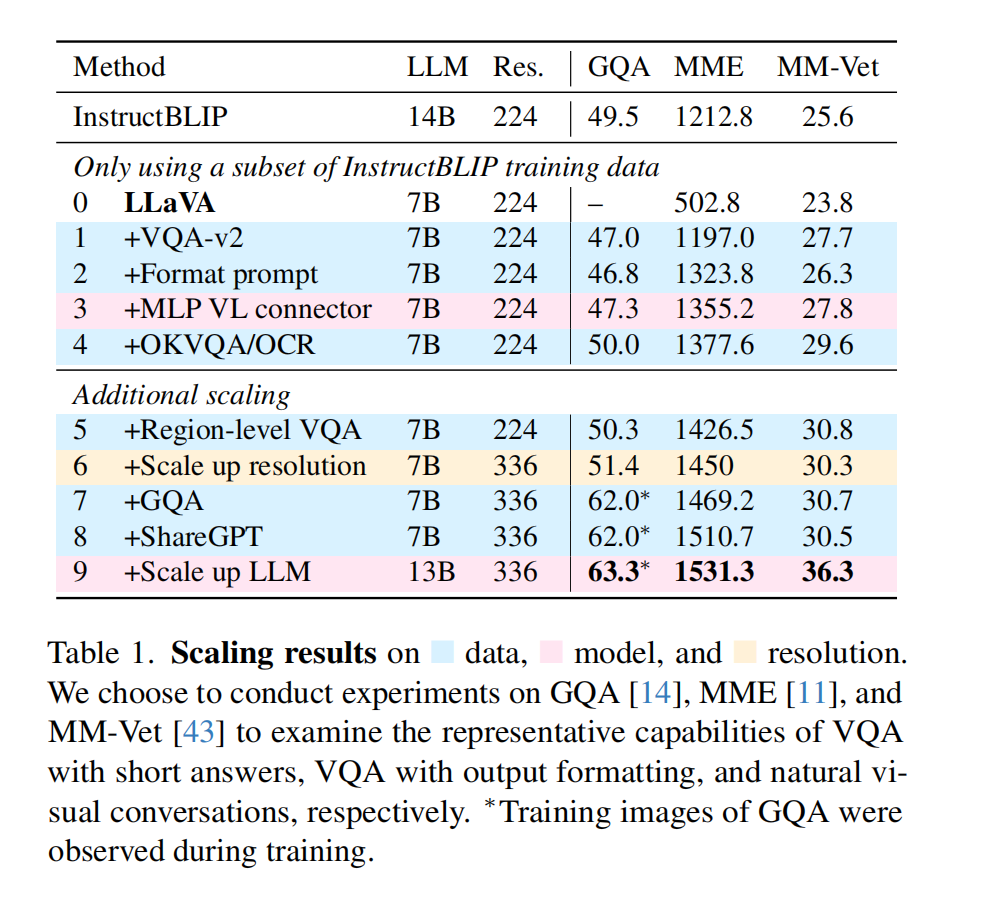
下面是分别描述每个提升:
1、Response formatting prompts:
作者发现,像InstructBLIP [9]这样的方法无法在短格式和长格式的视觉问答(VQA)之间取得平衡,主要原因如下。
- 首先,响应格式提示不明确。例如,Q: {Question} A: {Answer}。这种提示并没有清晰地指示出期望的输出格式,甚至可能导致大语言模型(LLM)行为上过度偏向短格式回答,即使在自然的视觉对话中也是如此。
- 其次,没有对 LLM 进行微调。第一个问题因 InstructBLIP 仅微调 Qformer 以进行指令微调而加剧。它需要Qformer的视觉输出标记来控制LLM的输出长度是长格式还是短格式,如同前缀调优[25],但由于其能力有限,相较于像LLaMA这样的LLM,Qformer可能无法恰当地做到这一点。参见表6中的定性示例。
为了解决这个问题,作者在本文中提出使用一个单一的响应格式提示,该提示清晰地指示出输出格式,并在想要短答案时附加在 VQA 问题的末尾:Answer the question using a single word or phrase。
并且作者通过实验证明,当LLM使用这种提示进行微调时,LLaVA能够根据用户的指示适当地调整输出格式,并且不需要额外处理VQA数据,如使用ChatGPT [5],这进一步支持扩展到各种数据源。如表1所示,仅通过在训练中包含VQAv2 [12],LLaVA在MME上的性能显著提升(1323.8 vs 502.8),并且比InstructBLIP高出 111 points
2、MLP vision-language connector:
受到在自监督学习中从线性投影改为MLP(多层感知机)所带来的性能提升的启发 [7, 8],作者也通过使用两层MLP来增强视觉-语言连接器的表示能力,可以提升LLaVA的多模态能力,相较于原始的线性投影设计。
3、Academic task oriented data:
作者进一步加入了额外的学术任务导向的VQA数据集,用于VQA、OCR和区域级感知,以多种方式增强模型的能力,如表1所示。
首先加入了InstructBLIP中使用的四个额外数据集:
- openknowledge VQA(OKVQA [33], A-OKVQA [37])
- OCR(OCRVQA [34], TextCaps [39])
A-OKVQA 被转换为多项选择题,并使用了一个特定的响应格式提示:直接用给定选项中的字母回答。仅使用InstructBLIP使用的数据集的一部分,LLaVA已经在表1中的所有三个任务上超越了它,这表明了LLaVA设计的有效性。
此外,作者发现进一步添加区域级VQA数据集(Visual Genome [18], RefCOCO [17, 32])可以提高模型定位细粒度视觉细节的能力。
4、Additional scaling:
作者进一步扩大了输入图像的分辨率,以便大语言模型(LLM)能够清晰地“看到”图像的细节,并添加了GQA数据集作为额外的视觉知识来源。作者还整合了ShareGPT [38]数据,并将LLM扩展到13B参数,如[2, 6, 31]中所述。在MM-Vet上的结果显示,当将LLM扩展到13B时,性能提升最显著,这表明基础LLM在视觉对话中的能力至关重要。
总结:包含以上所有这些修改的最终模型称为LLaVA-1.5(表1中的最后两行),显著优于原始的LLaVA [28]。
2.2 训练样本
对 LLaVA-v1.5,作者使用的预训练数据集为 LCS-558K,且将输入分辨率提升到了 336px,训练时间也是 LLaVA 的约 2 倍:
- pretrain:~6h(8× A100s)
- visual instruction tuning:~20h(8× A100s)
三、效果
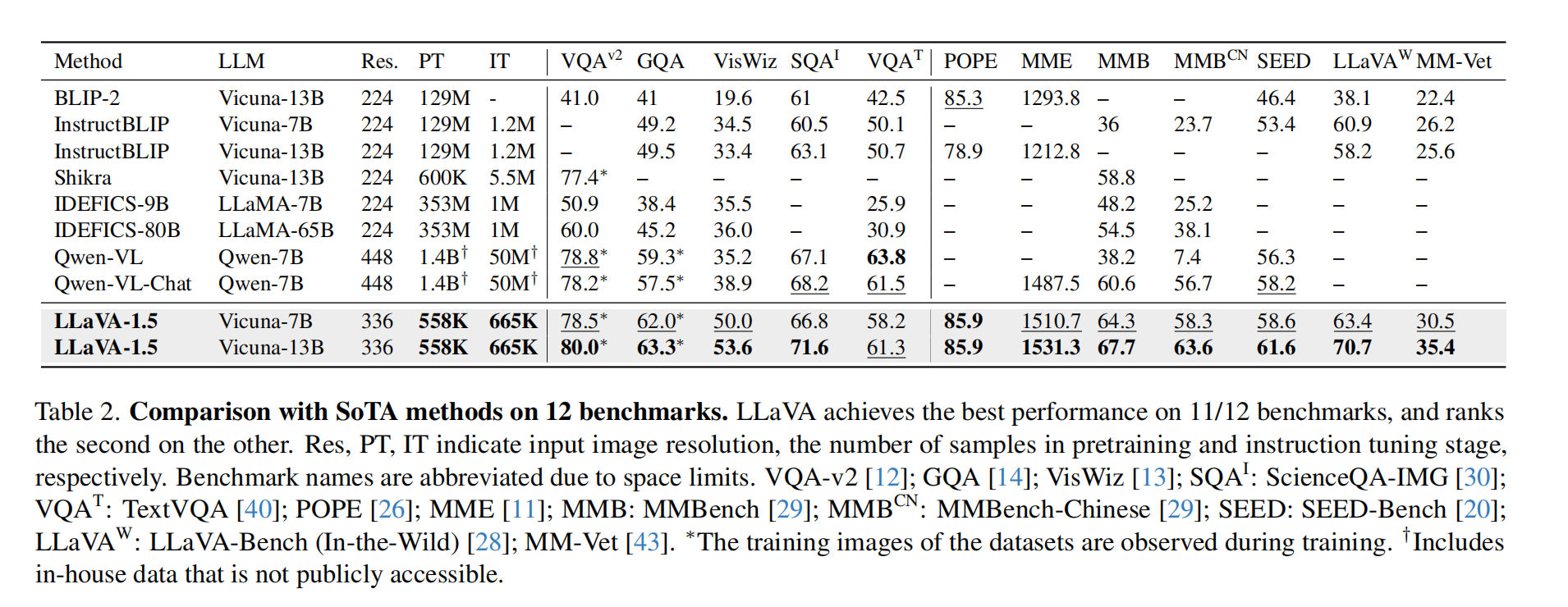
3.1 整体效果对比
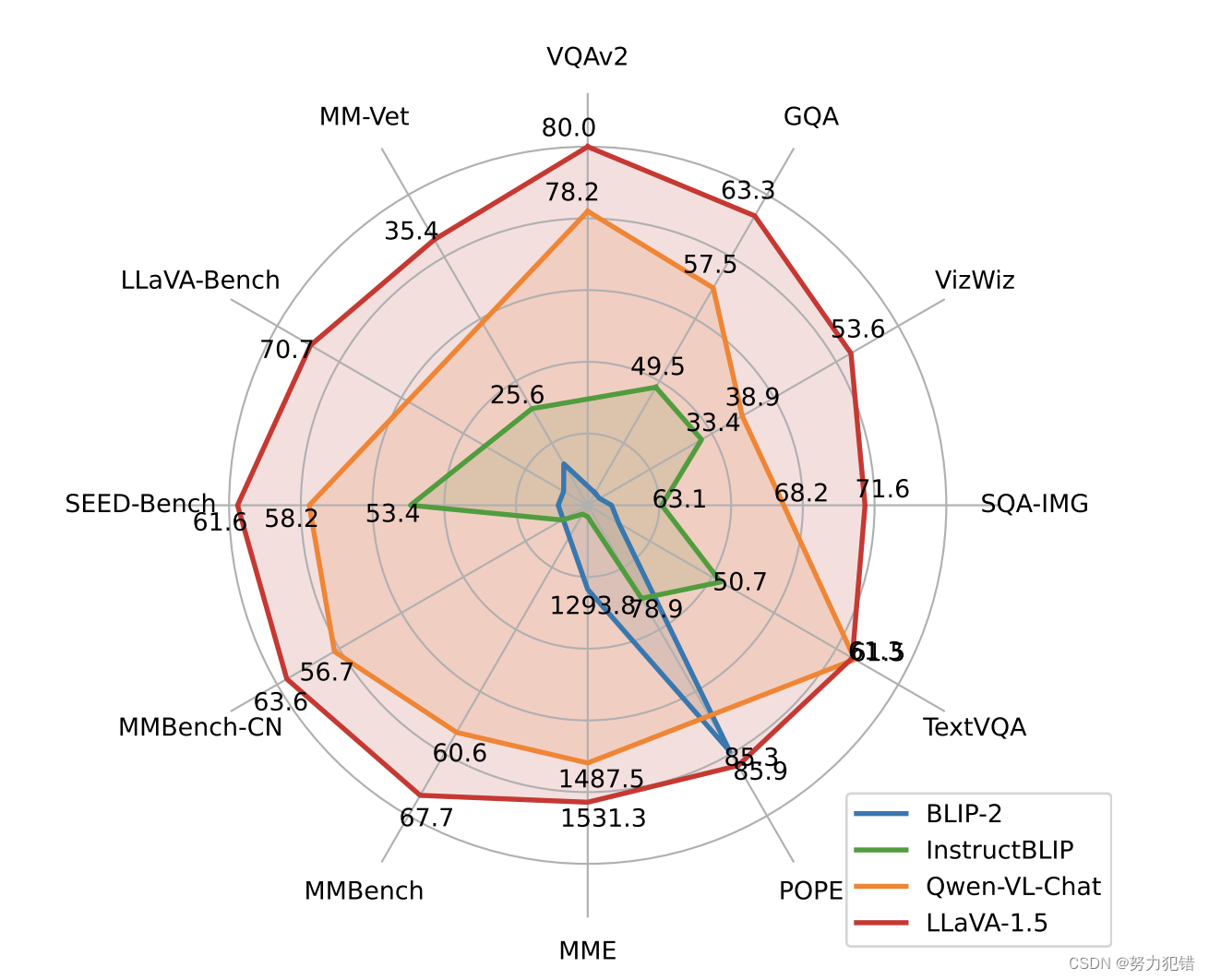
作者对比了不同模型在 12 个 benchmark 上的效果,LLaVA -v1.5 在 11 个 benchmark 上都取得了最优的成绩(而且使用的预训练和微调数据集都是很少的)
LLaVA -v1.5 使用最简单的结构、最少的计算量、开源数据集就取得了很好的效果,这也同样说明 visual instruction 相比 pretrain 来说对提高 LMM 模型的效果更为重要。
这个结论对普遍认为的 LMM 需要大量视觉语言对齐预训练的观点提出了质疑 [2, 9, 24],尽管视觉编码器(如CLIP [36]、OpenCLIP [16]、EVA-CLIP [10]等)已经在网络规模的图像-文本配对数据集上进行了预训练。LLaVA-1.5(即使是7B模型)在性能上超越了具有数十亿可训练参数用于跨模态连接的Flamingo-like LMM——80B IDEFICS [15]。这也促使我们重新思考视觉采样器的好处以及额外的大规模预训练在多模态指令跟随能力方面的必要性。
3.2 模型对于 zero-shot 形式的指令的结果生成能力
LLaVA-v1.5 只在少量形式的指令数据上训练过,但其也能对其他形式的指令来生成回答
比如:
- VizWiz 模型在提供的内容不足以回答问题时输出“无法回答”,我们的响应格式提示(表8)有效地指导模型这样做,使得无法回答的问题的正确率从11.1%提升到67.8%。我们还展示了指示LLaVA-1.5验证棘手问题的定性示例(图3),并以受限的JSON格式进行响应(图4)



3.3 模型对于 zero-shot 多语言的能力
尽管 LLaVA-1.5 完全没有针对多语言多模态指令跟随进行微调,我们发现它能够跟随多语言指令,这部分归功于ShareGPT [38]中的多语言指令。
我们在MMBench-CN [29]上定量评估了模型对中文的泛化能力,其中MMBench的问题被转换为中文。值得注意的是,尽管Qwen在中文多模态指令上进行了微调,但LLaVA-1.5在性能上仍然超越了Qwen-VL-Chat 7.3%(63.6%对56.7%)。
3.4 限制
图像块处理时间长:LLaVA使用完整的图像块进行处理,这可能会延长每次训练迭代的时间。虽然有些视觉重采样器可以减少处理的图像块数量,但这些方法目前还不能像LLaVA那样高效地收敛,可能是因为重采样器中有更多需要训练的参数。
无法处理多张图像:由于缺乏相关的指令跟随数据和上下文长度的限制,LLaVA-1.5目前还不能处理多张图像。这意味着它在处理复杂场景或多图像任务时能力有限。
特定领域问题解决能力有限:尽管LLaVA-1.5在跟随复杂指令方面表现出色,但在某些特定领域,其解决问题的能力仍然有限。这可以通过使用更强大的语言模型和高质量、针对性的视觉指令调优数据来改进。
幻觉和错误信息:尽管LLaVA-1.5产生幻觉(即生成不真实或不准确的信息)的倾向显著减少,但它仍不能完全避免这种情况,并且偶尔会传播错误信息。因此,在关键应用(例如医疗)中使用时需要特别谨慎。
四、训练
4.1 数据
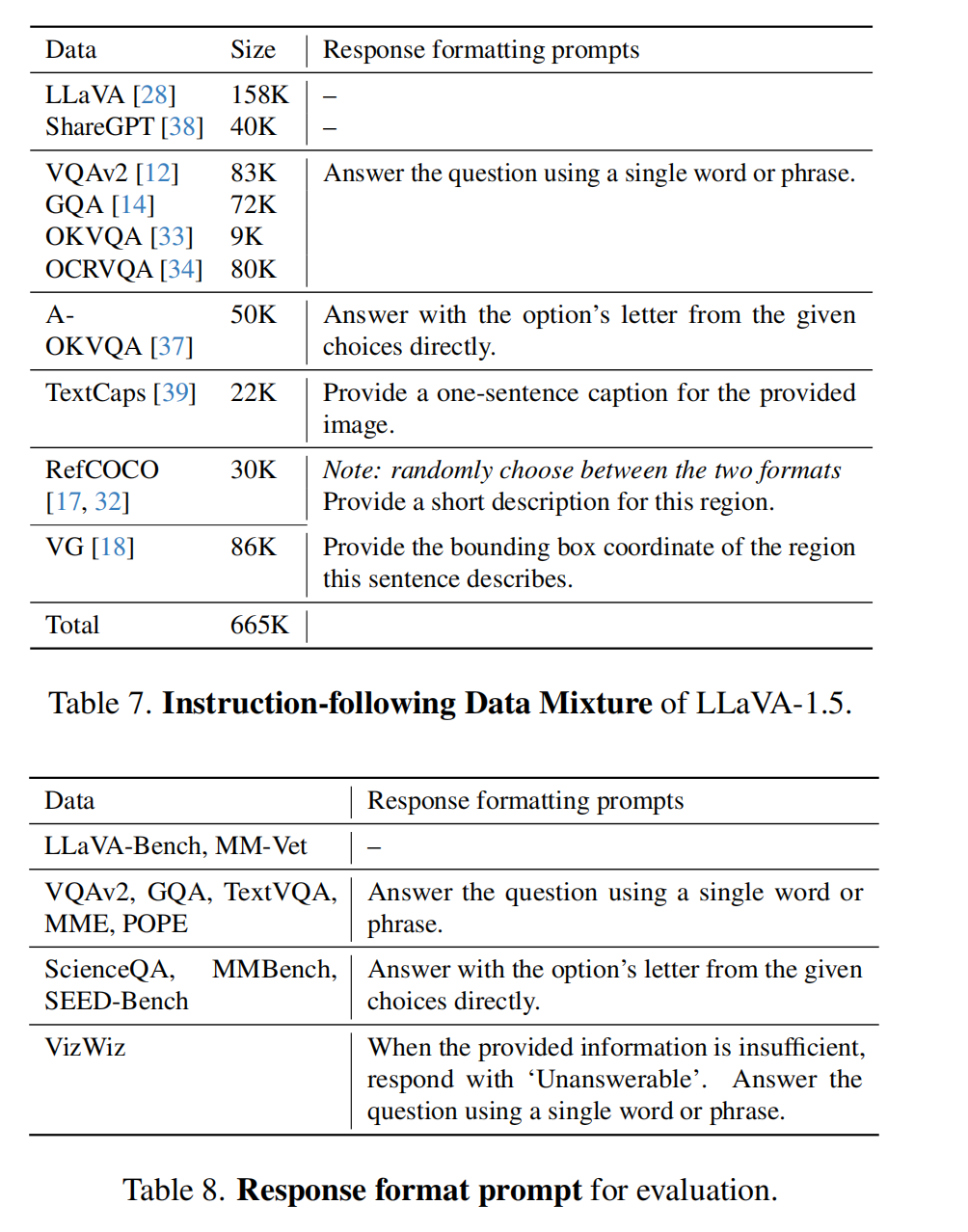
最终的训练数据混合包含各种数据集:VQA [12, 14, 33, 37]、OCR [34, 39]、区域级VQA [17, 18, 32]、视觉对话 [28] 和语言对话 [38] 数据。
采用多种策略来降低训练成本并提高效率,具体如下:
- 对于所有的VQA数据集,将同一训练图像的QA对合并成一个对话。这种方法减少了数据的冗余,提高了训练效率,因为模型可以在一次对话中处理多个问题和答案。
- 对于ShareGPT [38],作者会像 [41] 一样过滤掉无效的对话,超过2048个标记的长对话会被截断(而不是分割成多个对话,Vicuna [41] 就是分割)。这种方法确保了每个对话都在模型能够处理的上下文长度内,并且减少了训练数据中的复杂性,最终产生约40K个有效对话。
- 在A-OKVQA [37]中,每个QA对被增强 k 次,其中 k 是每个问题的选项数,以平衡缺乏多选数据的问题。
从OCRVQA [34]中抽取了80K个对话,这种方法确保了模型在训练过程中能够接触到足够多样化的OCR(光学字符识别)相关问答数据。 - 对于Visual Genome,作者为具有额外注释的图像抽取了10个注释。这种方法增加了训练数据中关于图像内容的细节信息,有助于模型更好地理解和生成与图像相关的回答。
- 对于RefCOCO,将长对话分解成段,每段包含少于10个对话。这种方法使得每段对话更加简洁,便于模型处理和学习。
- 我们观察到语言对话通常比视觉对话更长。在每批次中,我们仅从单一模态(视觉或语言)中抽取对话,这加快了25%的训练速度,并且不影响最终结果。
所有的数据分割被连接在一起并以相同概率进行抽样。在表7中展示了最终指令跟随数据混合的响应格式提示,并在表8中展示了用于每个评估基准的响应格式提示。
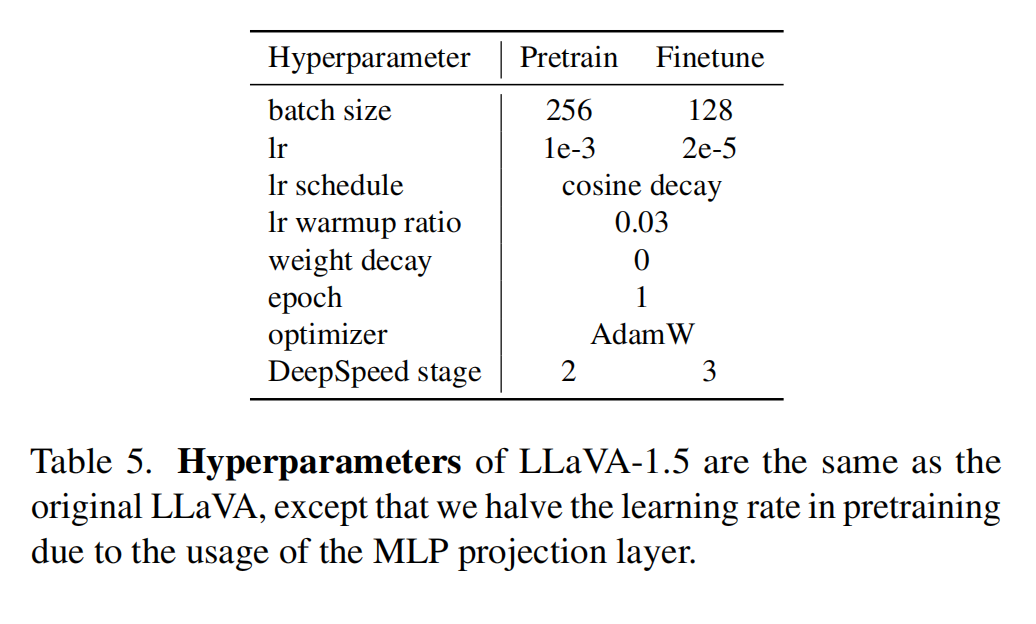
4.2 超参
LLaVA-1.5 的超参和 LLaVA 基本一致,只有在 pretrain 的时候将学习率减半了,因为使用了 MLP 而不是全连接
为什么使用 MLP 学习率就要降低一半:
- 复杂性增加:MLP投影层比线性投影层更复杂。MLP包含多个层和非线性激活函数,而线性投影层仅包含一个线性变换。这种复杂性增加了模型的表达能力,但也使得训练过程更加敏感和不稳定。
- 梯度爆炸或消失:由于MLP的多层结构,梯度在反向传播过程中可能会出现爆炸或消失的情况。较高的学习率会加剧这些问题,从而导致训练不稳定。因此,降低学习率可以帮助缓解这些问题,使训练过程更加平稳。
- 收敛速度:较低的学习率虽然可能会减慢模型的收敛速度,但它可以确保模型更稳定地找到全局最优解或接近全局最优解的位置。对于复杂网络结构,如MLP,较低的学习率有助于避免陷入局部最优解。
- 过拟合风险:高学习率可能导致模型快速拟合训练数据,但这也增加了过拟合的风险。通过降低学习率,可以使模型更逐步地适应数据,从而减少过拟合的可能性。
由于MLP投影层比线性投影层更复杂且更容易引发训练不稳定,因此在预训练阶段将学习率降低一半是为了确保模型能够稳定有效地进行训练。
五、评测
在多模态模型评测中,accuracy 和 img-accuracy 通常有以下区别:
Accuracy:
- 这是整体模型的准确率,表示模型在所有输入数据上的预测准确率。它包括所有模态的数据,例如文本、图像、音频等。
- 计算方式为:Accuracy = (正确预测的总数) / (总预测数)。
IMG-Accuracy:
- 这是专门针对图像输入数据的准确率,表示模型在处理图像数据时的预测准确率。
计算方式为:IMG-Accuracy = (图像数据正确预测的总数) / (图像数据的总预测数)。
这是 SQA 评测结果:
100%|██████████| 4241/4241 [06:24<00:00, 11.04it/s]
2024-06-04T03:03:43.533628014Z Total: 4241, Correct: 3120, Accuracy: 73.57%, IMG-Accuracy: 71.00%
- 总体准确率(Accuracy)是 73.57%,表示模型在所有输入数据上的预测准确率。
- 图像准确率(IMG-Accuracy)是 71.00%,表示模型在处理图像输入数据时的预测准确率。
- 这两者的区别在于评估范围不同,一个是整体评估,一个是特定于图像模态的评估。
六、代码
跑代码之前按 github 教程中安装环境:
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA
conda create -n llava python=3.10 -y
conda activate llava
pip install --upgrade pip # enable PEP 660 support
pip install -e .
pip install -e ".[train]"
pip install flash-attn --no-build-isolation
训练:按 github 教程下载 pretrain 数据和 finetune 数据
- pretrain:
scripts/v1_5/pretrain.sh - finetune:
scripis/v1_5/finetune.sh
# llava/train/train.py line818
if model_args.vision_tower is not None: # go in
# mpt(Multi-Path Transformer)模型可能具有特定的架构特点,例如多路径注意力机制、多头注意力等。这些特点可能需要特殊的配置和加载方式。
if 'mpt' in model_args.model_name_or_path:
config = transformers.AutoConfig.from_pretrained(model_args.model_name_or_path, trust_remote_code=True)
config.attn_config['attn_impl'] = training_args.mpt_attn_impl
model = LlavaMptForCausalLM.from_pretrained(
model_args.model_name_or_path,
config=config,
cache_dir=training_args.cache_dir,
**bnb_model_from_pretrained_args
)
# 非mpt,例如 Llama(Large Language Model Meta AI)模型,通常是标准的因果语言模型,使用单路径注意力机制或者其他较为传统的架构。
else: # go in # model_args.model_name_or_path: vicuna/vicuna-7b-v1.5,这里 model 就是加载从 huggingface 拉取下来的 vicuna 模型
model = LlavaLlamaForCausalLM.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
attn_implementation=attn_implementation,
torch_dtype=(torch.bfloat16 if training_args.bf16 else None),
**bnb_model_from_pretrained_args
)
# model 打印出来如下,也就是这里还没有 vision 相关的模块,只是 llm 相关的模块
LlavaLlamaForCausalLM(
(model): LlavaLlamaModel(
(embed_tokens): Embedding(32000, 4096, padding_idx=0)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaFlashAttention2(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)
# 执行了下面的操作后,initialize_vision_modules 会给核心模块加上 vision_tower 和 mm_projector 等模块
model.get_model().initialize_vision_modules(
model_args=model_args,
fsdp=training_args.fsdp
)
# model 就变成了这样
LlavaLlamaModel(
(embed_tokens): Embedding(32000, 4096, padding_idx=0)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaFlashAttention2(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
(vision_tower): CLIPVisionTower(
(vision_tower): CLIPVisionModel(
(vision_model): CLIPVisionTransformer(
(embeddings): CLIPVisionEmbeddings(
(patch_embedding): Conv2d(3, 1024, kernel_size=(14, 14), stride=(14, 14), bias=False)
(position_embedding): Embedding(577, 1024)
)
(pre_layrnorm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(encoder): CLIPEncoder(
(layers): ModuleList(
(0-23): 24 x CLIPEncoderLayer(
(self_attn): CLIPAttention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(layer_norm1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp): CLIPMLP(
(activation_fn): QuickGELUActivation()
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
)
(layer_norm2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
)
(post_layernorm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
)
(mm_projector): Sequential(
(0): Linear(in_features=1024, out_features=4096, bias=True)
(1): GELU(approximate='none')
(2): Linear(in_features=4096, out_features=4096, bias=True)
)
)
conversation_lib.conv_templates
{'default': Conversation(system="A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", roles=('Human', 'Assistant'), messages=(('Human', 'What are the key differences between renewable and non-renewable energy sources?'), ('Assistant', 'Renewable energy sources are those that can be replenished naturally in a relatively short amount of time, such as solar, wind, hydro, geothermal, and biomass. Non-renewable energy sources, on the other hand, are finite and will eventually be depleted, such as coal, oil, and natural gas. Here are some key differences between renewable and non-renewable energy sources:\n1. Availability: Renewable energy sources are virtually inexhaustible, while non-renewable energy sources are finite and will eventually run out.\n2. Environmental impact: Renewable energy sources have a much lower environmental impact than non-renewable sources, which can lead to air and water pollution, greenhouse gas emissions, and other negative effects.\n3. Cost: Renewable energy sources can be more expensive to initially set up, but they typically have lower operational costs than non-renewable sources.\n4. Reliability: Renewable energy sources are often more reliable and can be used in more remote locations than non-renewable sources.\n5. Flexibility: Renewable energy sources are often more flexible and can be adapted to different situations and needs, while non-renewable sources are more rigid and inflexible.\n6. Sustainability: Renewable energy sources are more sustainable over the long term, while non-renewable sources are not, and their depletion can lead to economic and social instability.\n')), offset=2, sep_style=<SeparatorStyle.SINGLE: 1>, sep='###', sep2=None, version='Unknown', skip_next=False), 'v0': Conversation(system="A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", roles=('Human', 'Assistant'), messages=(('Human', 'What are the key differences between renewable and non-renewable energy sources?'), ('Assistant', 'Renewable energy sources are those that can be replenished naturally in a relatively short amount of time, such as solar, wind, hydro, geothermal, and biomass. Non-renewable energy sources, on the other hand, are finite and will eventually be depleted, such as coal, oil, and natural gas. Here are some key differences between renewable and non-renewable energy sources:\n1. Availability: Renewable energy sources are virtually inexhaustible, while non-renewable energy sources are finite and will eventually run out.\n2. Environmental impact: Renewable energy sources have a much lower environmental impact than non-renewable sources, which can lead to air and water pollution, greenhouse gas emissions, and other negative effects.\n3. Cost: Renewable energy sources can be more expensive to initially set up, but they typically have lower operational costs than non-renewable sources.\n4. Reliability: Renewable energy sources are often more reliable and can be used in more remote locations than non-renewable sources.\n5. Flexibility: Renewable energy sources are often more flexible and can be adapted to different situations and needs, while non-renewable sources are more rigid and inflexible.\n6. Sustainability: Renewable energy sources are more sustainable over the long term, while non-renewable sources are not, and their depletion can lead to economic and social instability.\n')), offset=2, sep_style=<SeparatorStyle.SINGLE: 1>, sep='###', sep2=None, version='Unknown', skip_next=False), 'v1': Conversation(system="A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.", roles=('USER', 'ASSISTANT'), messages=(), offset=0, sep_style=<SeparatorStyle.TWO: 2>, sep=' ', sep2='</s>', version='v1', skip_next=False), 'vicuna_v1': Conversation(system="A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.", roles=('USER', 'ASSISTANT'), messages=(), offset=0, sep_style=<SeparatorStyle.TWO: 2>, sep=' ', sep2='</s>', version='v1', skip_next=False), 'llama_2': Conversation(system="You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.\n\nIf a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.", roles=('USER', 'ASSISTANT'), messages=(), offset=0, sep_style=<SeparatorStyle.LLAMA_2: 5>, sep='<s>', sep2='</s>', version='llama_v2', skip_next=False), 'mistral_instruct': Conversation(system='', roles=('USER', 'ASSISTANT'), messages=(), offset=0, sep_style=<SeparatorStyle.LLAMA_2: 5>, sep='', sep2='</s>', version='llama_v2', skip_next=False), 'chatml_direct': Conversation(system='<|im_start|>system\nAnswer the questions.', roles=('<|im_start|>user\n', '<|im_start|>assistant\n'), messages=(), offset=0, sep_style=<SeparatorStyle.MPT: 3>, sep='<|im_end|>', sep2=None, version='mpt', skip_next=False), 'mistral_direct': Conversation(system='<|im_start|>system\nAnswer the questions.', roles=('<|im_start|>user\n', '<|im_start|>assistant\n'), messages=(), offset=0, sep_style=<SeparatorStyle.MPT: 3>, sep='<|im_end|>', sep2=None, version='mpt', skip_next=False), 'plain': Conversation(system='', roles=('', ''), messages=(), offset=0, sep_style=<SeparatorStyle.PLAIN: 4>, sep='\n', sep2=None, version='Unknown', skip_next=False), 'v0_plain': Conversation(system='', roles=('', ''), messages=(), offset=0, sep_style=<SeparatorStyle.PLAIN: 4>, sep='\n', sep2=None, version='Unknown', skip_next=False), 'llava_v0': Conversation(system="A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", roles=('Human', 'Assistant'), messages=(), offset=0, sep_style=<SeparatorStyle.SINGLE: 1>, sep='###', sep2=None, version='Unknown', skip_next=False), 'v0_mmtag': Conversation(system='A chat between a curious user and an artificial intelligence assistant. The assistant is able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language.The visual content will be provided with the following format: <Image>visual content</Image>.', roles=('Human', 'Assistant'), messages=(), offset=0, sep_style=<SeparatorStyle.SINGLE: 1>, sep='###', sep2=None, version='v0_mmtag', skip_next=False), 'llava_v1': Conversation(system="A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", roles=('USER', 'ASSISTANT'), messages=(), offset=0, sep_style=<SeparatorStyle.TWO: 2>, sep=' ', sep2='</s>', version='v1', skip_next=False), 'v1_mmtag': Conversation(system='A chat between a curious user and an artificial intelligence assistant. The assistant is able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language.The visual content will be provided with the following format: <Image>visual content</Image>.', roles=('USER', 'ASSISTANT'), messages=(), offset=0, sep_style=<SeparatorStyle.TWO: 2>, sep=' ', sep2='</s>', version='v1_mmtag', skip_next=False), 'llava_llama_2': Conversation(system='You are a helpful language and vision assistant. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language.', roles=('USER', 'ASSISTANT'), messages=(), offset=0, sep_style=<SeparatorStyle.LLAMA_2: 5>, sep='<s>', sep2='</s>', version='llama_v2', skip_next=False), 'mpt': Conversation(system='<|im_start|>system\nA conversation between a user and an LLM-based AI assistant. The assistant gives helpful and honest answers.', roles=('<|im_start|>user\n', '<|im_start|>assistant\n'), messages=(), offset=0, sep_style=<SeparatorStyle.MPT: 3>, sep='<|im_end|>', sep2=None, version='mpt', skip_next=False)}
训练前的数据准备:
# llava_llama.py 中调用了 prepare_inputs_labels_for_multimodal
# llava_arch.py 中定义了 prepare_inputs_labels_for_multimodal,这是一个比较复杂的流程
整个训练的链路是靠 transformer/trainer.py 的 _inner_training_loop() 串起来的,关键的就是 training_step 来控制整个过程,loss 的计算也是靠 transformer/trainer.py 中实现的,直接拿来用的
def training_step(self, model: nn.Module, inputs: Dict[str, Union[torch.Tensor, Any]]) -> torch.Tensor:
"""
Perform a training step on a batch of inputs.
Subclass and override to inject custom behavior.
Args:
model (`nn.Module`):
The model to train.
inputs (`Dict[str, Union[torch.Tensor, Any]]`):
The inputs and targets of the model.
The dictionary will be unpacked before being fed to the model. Most models expect the targets under the
argument `labels`. Check your model's documentation for all accepted arguments.
Return:
`torch.Tensor`: The tensor with training loss on this batch.
"""
model.train()
inputs = self._prepare_inputs(inputs)
if is_sagemaker_mp_enabled():
loss_mb = smp_forward_backward(model, inputs, self.args.gradient_accumulation_steps)
return loss_mb.reduce_mean().detach().to(self.args.device)
with self.compute_loss_context_manager():
loss = self.compute_loss(model, inputs)
if self.args.n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu parallel training
if self.use_apex:
with amp.scale_loss(loss, self.optimizer) as scaled_loss:
scaled_loss.backward()
else:
self.accelerator.backward(loss)
return loss.detach() / self.args.gradient_accumulation_steps
def compute_loss(self, model, inputs, return_outputs=False):
"""
How the loss is computed by Trainer. By default, all models return the loss in the first element.
Subclass and override for custom behavior.
"""
if self.label_smoother is not None and "labels" in inputs:
labels = inputs.pop("labels")
else:
labels = None
outputs = model(**inputs)
# Save past state if it exists
# TODO: this needs to be fixed and made cleaner later.
if self.args.past_index >= 0:
self._past = outputs[self.args.past_index]
if labels is not None:
unwrapped_model = unwrap_model(model)
if _is_peft_model(unwrapped_model):
model_name = unwrapped_model.base_model.model._get_name()
else:
model_name = unwrapped_model._get_name()
if model_name in MODEL_FOR_CAUSAL_LM_MAPPING_NAMES.values():
loss = self.label_smoother(outputs, labels, shift_labels=True)
else:
loss = self.label_smoother(outputs, labels)
else:
if isinstance(outputs, dict) and "loss" not in outputs:
raise ValueError(
"The model did not return a loss from the inputs, only the following keys: "
f"{','.join(outputs.keys())}. For reference, the inputs it received are {','.join(inputs.keys())}."
)
# We don't use .loss here since the model may return tuples instead of ModelOutput.
loss = outputs["loss"] if isinstance(outputs, dict) else outputs[0]
return (loss, outputs) if return_outputs else loss