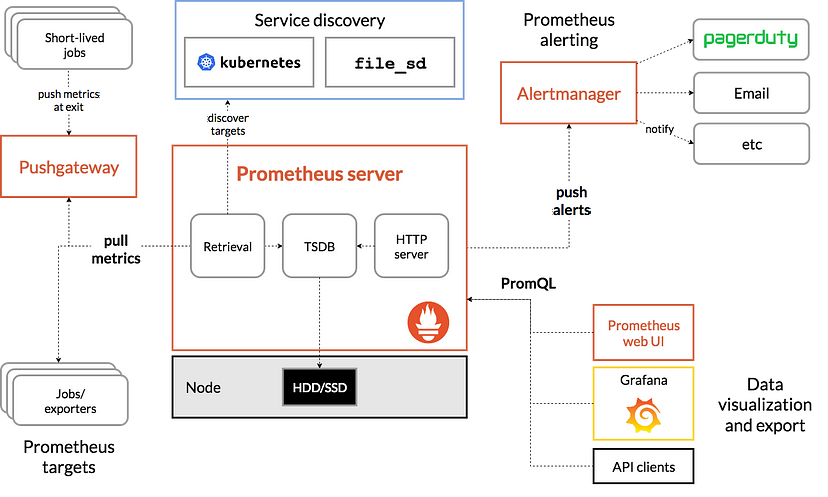
很多小伙伴不知道Prometheus 和 Grafana是做什么的,今天给大家讲解下这两个工具,这两个工具都是用来做性能监控的
当然可以,下面是详细的配置和使用 Prometheus 和 Grafana 进行全链路压测的指南,包括具体的安装步骤、配置方法、常用的 PromQL 查询示例,以及如何使用这些工具来监控你的系统。
全链路压测中的监控工具:Prometheus 和 Grafana
全链路压测是一种模拟全业务流程的压力测试方法,它需要监控系统的资源使用情况,包括 CPU、内存、磁盘和网络等。通过 Prometheus 和 Grafana,可以实现对这些资源的实时监控,从而有效地识别性能瓶颈并进行优化调整。以下是详细的步骤和配置方法。
一、安装 Prometheus
1. 下载 Prometheus
首先,从 Prometheus 的官方网站下载适用于你的操作系统的二进制文件。
- 访问 Prometheus 下载页面。
- 选择适用于你操作系统的版本并下载。例如,下载
prometheus-2.26.0.linux-amd64.tar.gz文件。
2. 解压并安装 Prometheus
下载完成后,解压文件并将 Prometheus 安装到服务器上。
tar xvfz prometheus-*.tar.gz
cd prometheus-*
3. 配置 Prometheus
创建或编辑 prometheus.yml 配置文件,指定需要监控的目标。以下是一个示例配置:
global:
scrape_interval: 15s # 每15秒抓取一次数据
scrape_configs:
- job_name: 'application_metrics'
static_configs:
- targets: ['localhost:9090'] # 替换为实际的监控目标
在这个配置中,scrape_interval 定义了 Prometheus 抓取数据的频率,scrape_configs 指定了需要监控的服务地址。
4. 启动 Prometheus
使用命令行启动 Prometheus。
./prometheus --config.file=prometheus.yml
二、安装 Grafana
1. 下载和安装 Grafana
从 Grafana 官方网站下载适用于你的操作系统的安装包,并按照安装指南进行安装。
- 访问 Grafana 下载页面。
- 下载适用于你的操作系统的版本。
例如,在 Ubuntu 上可以使用以下命令安装:
sudo apt-get install -y adduser libfontconfig1
wget https://dl.grafana.com/oss/release/grafana_7.5.2_amd64.deb
sudo dpkg -i grafana_7.5.2_amd64.deb
2. 启动 Grafana
启动 Grafana 服务。
sudo service grafana-server start
3. 访问 Grafana
在浏览器中访问 http://localhost:3000(或相应的服务器地址和端口),登录 Grafana。默认用户名和密码都是 admin。
4. 添加 Prometheus 数据源
在 Grafana 仪表盘中,点击左侧菜单的齿轮图标(Configuration),选择 Data Sources。
- 点击 “Add data source” 按钮,选择 Prometheus。
- 在 URL 字段中输入 Prometheus 的地址(例如
http://localhost:9090),然后点击 “Save & Test”。
三、创建 Grafana 仪表盘
1. 创建新的仪表盘
在 Grafana 中,点击左侧加号图标,选择 “Dashboard” -> “New Dashboard”。
2. 添加图表
在新仪表盘中,点击 “Add new panel” 按钮,添加一个新的图表。在 Query 部分,选择 Prometheus 数据源,并输入查询语句。例如:
rate(http_requests_total[1m])
你可以根据需要监控的指标,添加更多图表。例如监控 CPU 使用率、内存使用情况、磁盘 IO 等。
3. 保存仪表盘
添加完所有需要的图表后,点击 “Save” 按钮,为仪表盘命名并保存。
四、使用 Prometheus 和 Grafana 监控系统资源
1. 监控 CPU 使用率
以下是监控 CPU 使用率的 PromQL 查询示例:
100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100)
此查询计算系统的 CPU 使用率,node_cpu_seconds_total 指示各个模式下的 CPU 时间,mode="idle" 表示空闲时间。通过计算 100 减去空闲时间的百分比来得到 CPU 使用率。
2. 监控内存使用情况
以下是监控内存使用情况的 PromQL 查询示例:
node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100
此查询计算系统的内存使用率,node_memory_MemAvailable_bytes 表示可用内存,node_memory_MemTotal_bytes 表示总内存。通过计算可用内存占总内存的百分比来得到内存使用率。
3. 监控磁盘 IO
以下是监控磁盘 IO 的 PromQL 查询示例:
rate(node_disk_io_time_seconds_total[1m])
此查询计算磁盘 IO 时间的速率,node_disk_io_time_seconds_total 表示磁盘 IO 时间。通过计算磁盘 IO 时间的速率来监控磁盘的使用情况。
4. 监控网络流量
以下是监控网络流量的 PromQL 查询示例:
rate(node_network_receive_bytes_total[1m])
rate(node_network_transmit_bytes_total[1m])
这两个查询分别计算网络接收和发送流量的速率,node_network_receive_bytes_total 表示接收的字节数,node_network_transmit_bytes_total 表示发送的字节数。通过计算网络流量的速率来监控网络的使用情况。
五、在全链路压测中的应用
全链路压测是模拟用户在真实场景中的操作,通过对整个业务链路进行压力测试,发现系统的性能瓶颈。以下是使用 Prometheus 和 Grafana 在全链路压测中的具体步骤。
1. 准备测试环境
- 确保所有服务都已经部署并运行。
- 在每个服务上配置 Prometheus 客户端,暴露
/metrics端点。
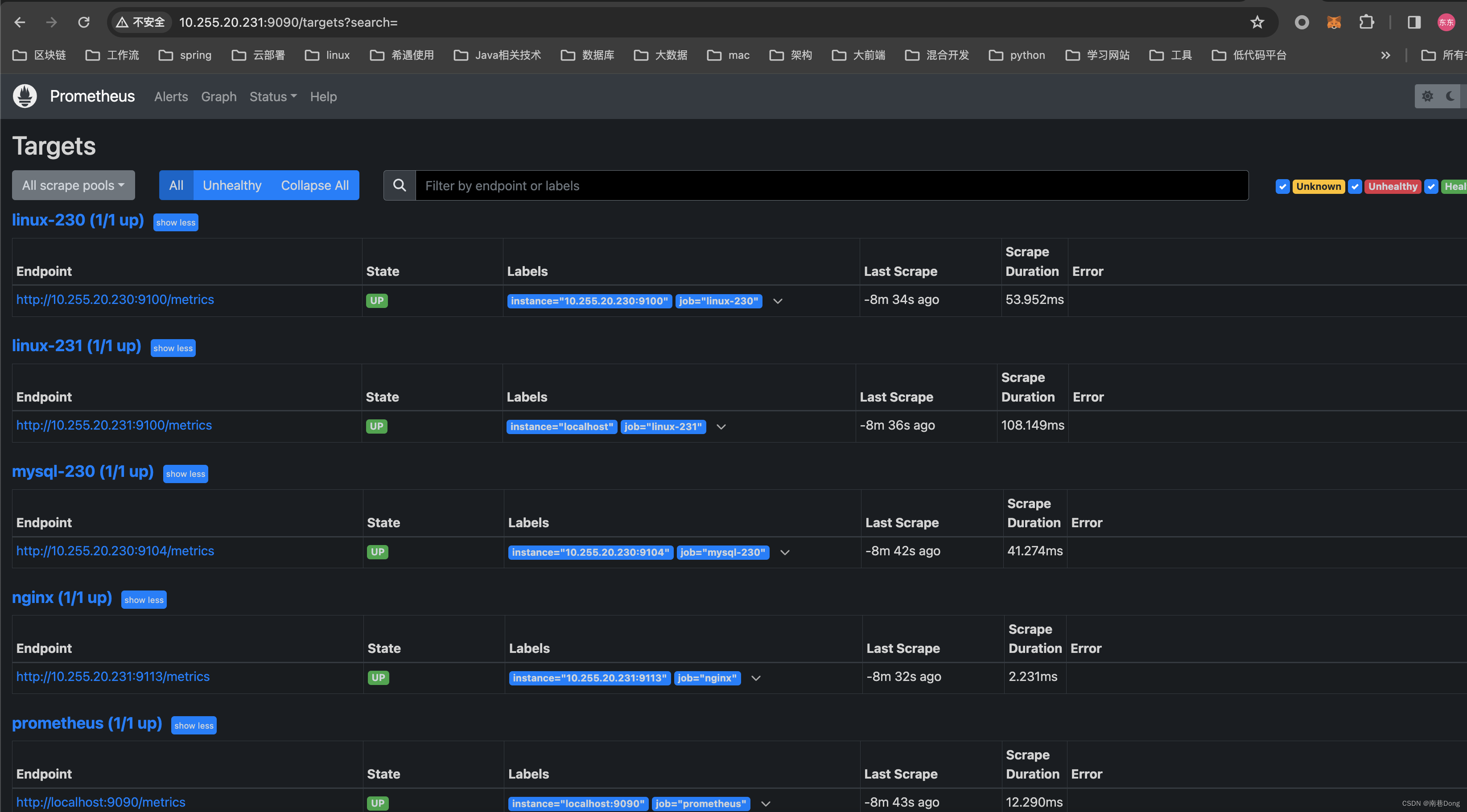
2. 配置 Prometheus 抓取目标
在 prometheus.yml 文件中,添加所有需要监控的服务地址。
scrape_configs:
- job_name: 'service_a'
static_configs:
- targets: ['service_a:9090']
- job_name: 'service_b'
static_configs:
- targets: ['service_b:9090']
- job_name: 'service_c'
static_configs:
- targets: ['service_c:9090']
3. 启动压力测试
使用压测工具(如 JMeter 或 Locust)模拟用户请求,启动全链路压测。确保在测试过程中,系统资源使用情况在预期范围内。
4. 监控系统性能
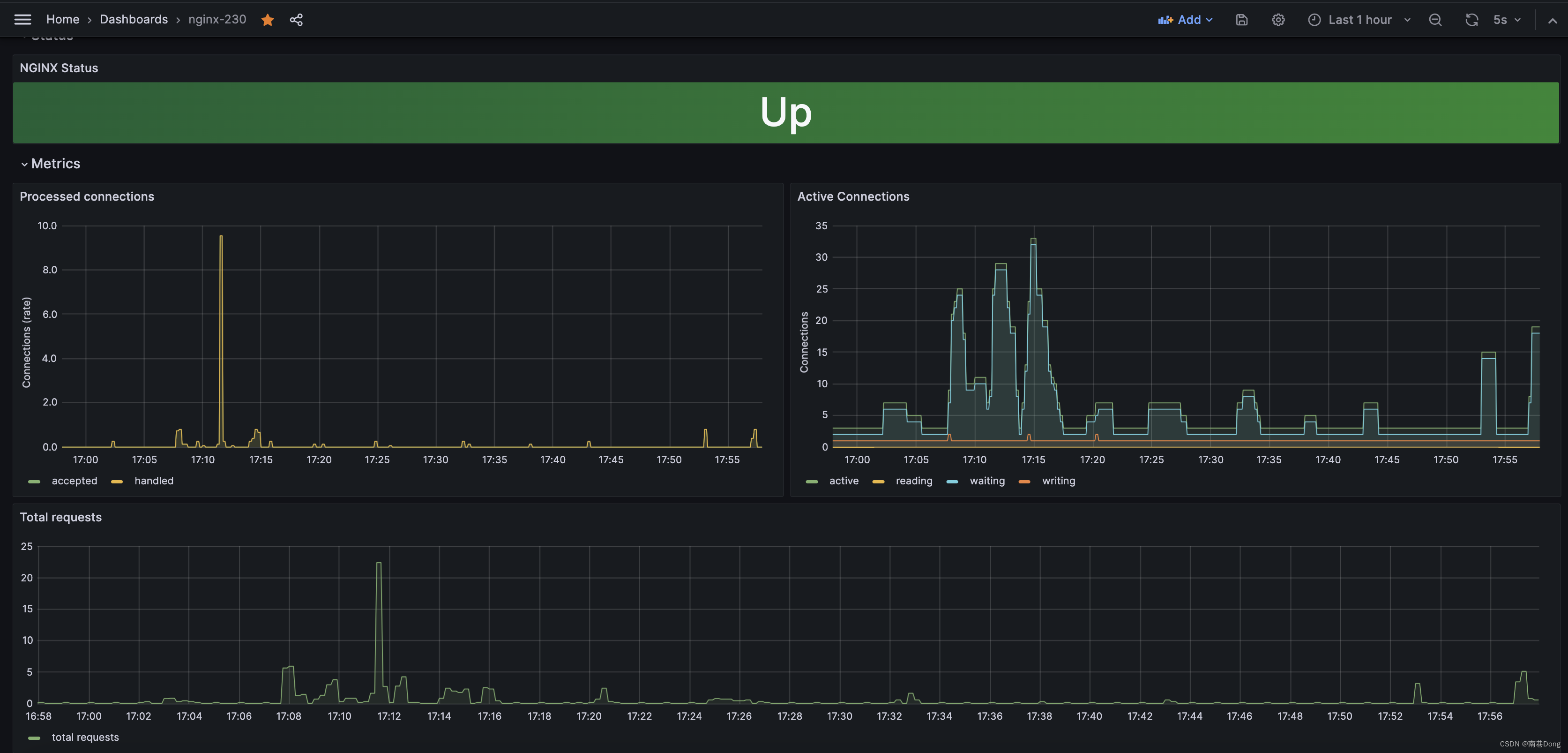
通过 Grafana 实时监控系统的性能指标,观察 CPU、内存、磁盘和网络等资源的使用情况。根据监控数据,识别性能瓶颈并进行优化调整。
5. 分析测试结果
在压测结束后,通过 Grafana 仪表盘分析系统的性能数据,生成测试报告。根据测试结果,制定优化方案并实施。
六、示例配置和使用场景
以下是一个完整的示例,展示如何配置和使用 Prometheus 和 Grafana 进行全链路压测。
1. Prometheus 配置文件
创建 prometheus.yml 配置文件,内容如下:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'application_metrics'
static_configs:
- targets: ['localhost:8080']
- job_name: 'node_metrics'
static_configs:
- targets: ['localhost:9100']
2. Grafana 仪表盘配置
在 Grafana 中,创建新的仪表盘,并添加以下图表:
CPU 使用率:
100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100)内存使用情况:
node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100磁盘 IO:
rate(node_disk_io_time_seconds_total[1m])网络流量:
rate(node_network_receive_bytes_total[1m]) rate(node_network_transmit_bytes_total[1m])
3. 启动全链路压测
使用 JMeter 或 Locust 启动全链路压测。配置测试计划,模拟用户请求,启动压测并
观察 Grafana 仪表盘中的实时数据。
4. 分析和优化
在压测结束后,通过 Grafana 仪表盘分析系统的性能数据,生成测试报告。根据测试结果,识别性能瓶颈并制定优化方案。例如,如果发现 CPU 使用率过高,可以考虑优化代码或增加服务器资源。
七、总结
通过详细的步骤和配置,使用 Prometheus 和 Grafana 可以实现对被测试系统的实时监控,识别性能瓶颈并进行优化调整。在全链路压测中,通过监控系统的 CPU、内存、磁盘和网络等资源的使用情况,可以确保系统在高负载下的稳定性和性能。希望这份详细指南能帮助你更好地进行全链路压测,提高系统的性能和可靠性。