验证集的划分方法:确保机器学习模型泛化能力的关键
目录
在机器学习任务中,我们不仅要关注模型在训练数据上的表现,更重要的是模型在未见数据上的泛化能力。为了评估和提高这种泛化能力,我们通常会将数据集划分为训练集、验证集和测试集。其中,验证集在模型选择和调优过程中起着至关重要的作用。本文将详细介绍验证集的划分方法及其重要性。
一、验证集的作用
验证集主要用于在训练过程中评估模型的性能,并帮助我们进行超参数调整和模型选择。与测试集不同,验证集在模型开发阶段是可以多次使用的,以便我们根据验证集上的性能来调整模型。一旦模型在验证集上表现良好,我们再使用测试集来评估模型的最终性能。
二、验证集的划分方法
- 简单划分:
- 最简单的方法是将整个数据集随机划分为训练集、验证集和测试集。通常,训练集占大部分数据(如70%),验证集和测试集各占一部分(如15%和15%)。这种方法适用于数据量较大的情况,可以确保每个集合都有足够的数据。
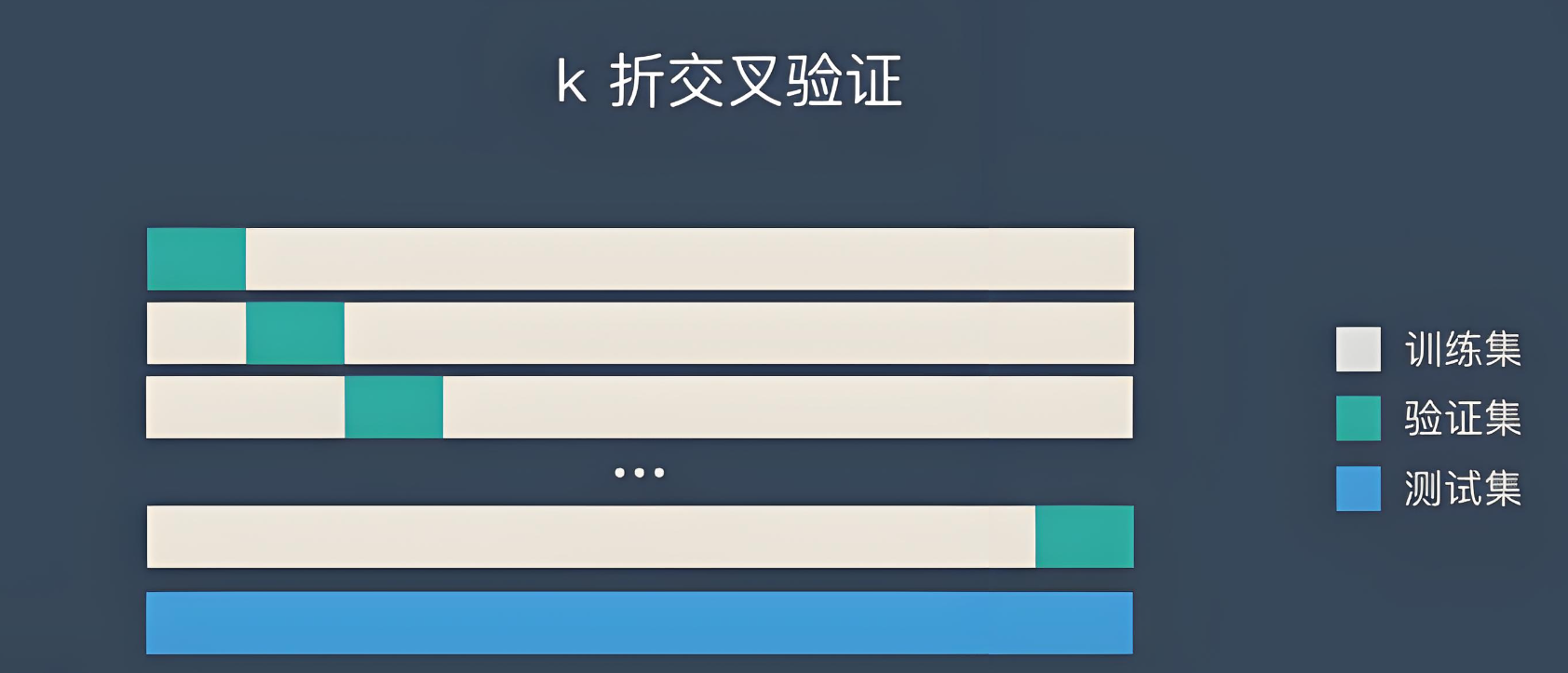
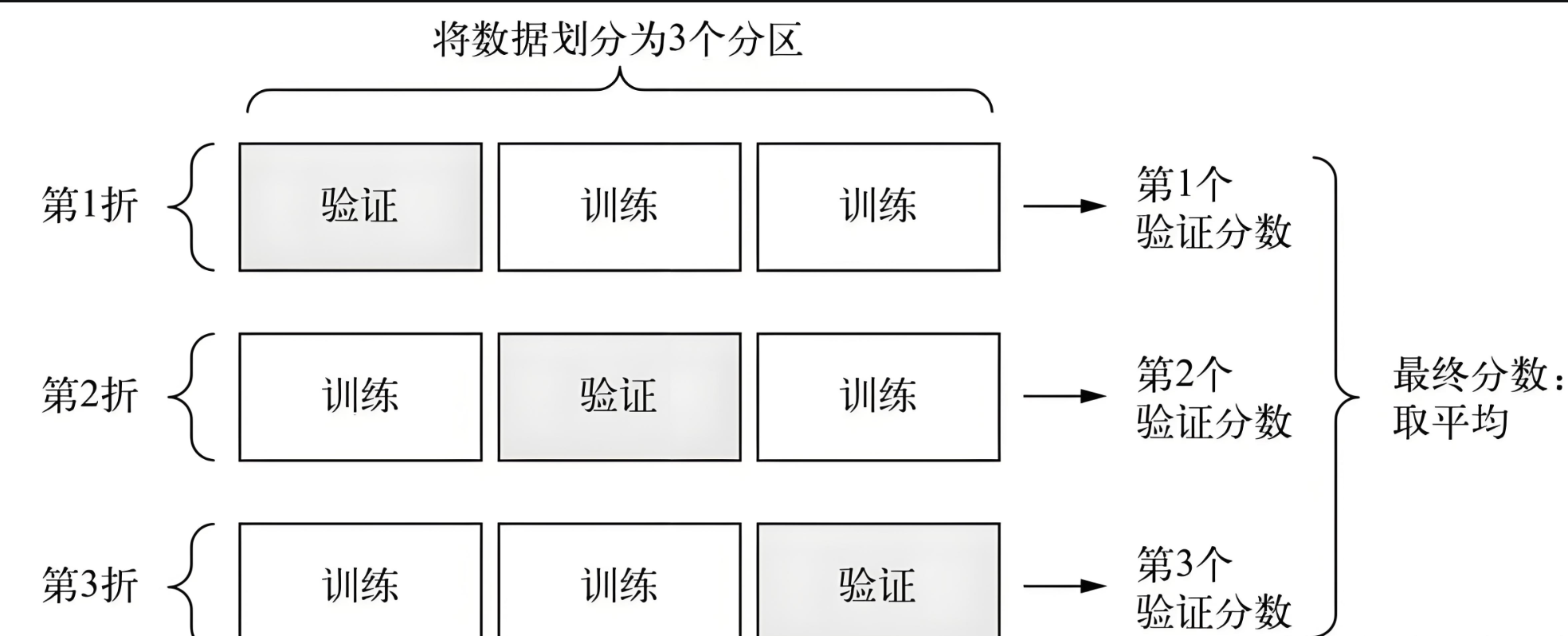
- 交叉验证:
- 当数据量较小时,简单划分可能导致验证集和测试集的数据量不足,无法准确评估模型性能。这时,我们可以使用交叉验证的方法。其中,k折交叉验证是最常用的一种。具体做法是将数据集分成k份,每次使用其中的k-1份作为训练集,剩下的1份作为验证集。这个过程重复k次,每次使用不同的部分作为验证集。最后,我们可以计算k次验证的平均性能作为模型的性能指标。
- 时间序列数据的划分:
- 对于时间序列数据,我们不能简单地随机划分数据集,因为时间序列数据具有时间依赖性。在这种情况下,我们通常会将数据集按时间顺序划分为训练集、验证集和测试集。这样可以确保模型在验证集和测试集上评估时,不会“看到”未来的数据。
- 分层抽样划分:
- 当数据集中存在类别不平衡问题时,为了确保验证集和测试集中各类别的比例与原始数据集相似,我们可以采用分层抽样的方法进行划分。这样可以避免模型在验证集和测试集上受到类别不平衡的影响。

使用以下代码来演示验证集的划分和加载:
import torch
from torch.utils.data import random_split, DataLoader
from torchvision import datasets, transforms
# 设置随机数种子以确保可重复性
torch.manual_seed(42)
# 加载数据集,这里以MNIST数据集为例
transform = transforms.Compose([transforms.ToTensor()])
dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
# 计算每个集合的大小
dataset_size = len(dataset)
train_size = int(0.7 * dataset_size) # 70% 的数据用作训练集
val_size = int(0.15 * dataset_size) # 15% 的数据用作验证集
test_size = dataset_size - train_size - val_size # 剩余的数据用作测试集
# 使用random_split来划分数据集
train_dataset, val_dataset, test_dataset = random_split(dataset, [train_size, val_size, test_size])
# 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 现在你可以使用这些加载器来训练、验证和测试你的模型了。
# 例如,以下是一个简单的训练循环示例:
for epoch in range(5): # 假设我们训练5个epoch
for images, labels in train_loader:
# 在这里添加你的训练代码,例如:
# outputs = model(images)
# loss = criterion(outputs, labels)
# ...
print("Training batch processed.")
# 在每个epoch结束时进行验证
correct = 0
total = 0
with torch.no_grad(): # 不需要计算梯度,节省内存和计算资源
for images, labels in val_loader:
# 在这里添加你的验证代码,例如:
# outputs = model(images)
# _, predicted = torch.max(outputs.data, 1)
# total += labels.size(0)
# correct += (predicted == labels).sum().item()
print("Validation batch processed.")
# 计算验证集上的准确率等指标...示例代码主要是为了演示如何划分和加载数据集。在实际的训练和验证过程中,你需要添加模型的初始化、损失函数的定义、优化器的选择等代码。同时,你可能还需要调整batch_size、epoch数量等超参数来优化模型的训练效果。
三、注意事项
随机性:在划分数据集时,应确保划分过程是随机的,以避免引入偏差。同时,为了实验的可重复性,应设置固定的随机种子。
数据分布:应确保划分后的训练集、验证集和测试集的数据分布与原始数据集相似,以便模型能够更好地泛化到未见数据。
多次实验:由于数据集的划分具有随机性,因此建议进行多次实验并取平均值作为最终性能评估指标,以提高评估的准确性。
四、总结
验证集的划分是机器学习任务中至关重要的一步。通过合理的划分方法,我们可以更准确地评估模型的性能并进行有效的模型选择和调优。在实际应用中,应根据具体的数据集特性和任务需求选择合适的划分方法。