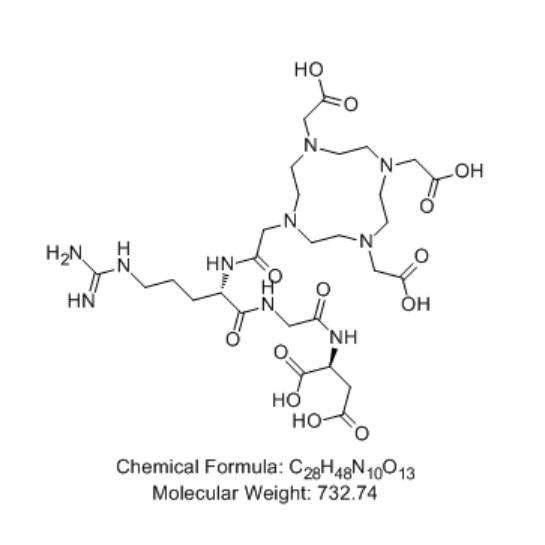
参考:BEHRT/task/MLM.ipynb at ca0163faf5ec09e5b31b064b20085f6608c2b6d1 · deepmedicine/BEHRT · GitHub
class BertConfig(Bert.modeling.BertConfig):
def __init__(self, config):
super(BertConfig, self).__init__(
vocab_size_or_config_json_file=config.get('vocab_size'),
hidden_size=config['hidden_size'],
num_hidden_layers=config.get('num_hidden_layers'),
num_attention_heads=config.get('num_attention_heads'),
intermediate_size=config.get('intermediate_size'),
hidden_act=config.get('hidden_act'),
hidden_dropout_prob=config.get('hidden_dropout_prob'),
attention_probs_dropout_prob=config.get('attention_probs_dropout_prob'),
max_position_embeddings = config.get('max_position_embedding'),
initializer_range=config.get('initializer_range'),
)
self.seg_vocab_size = config.get('seg_vocab_size')
self.age_vocab_size = config.get('age_vocab_size')
class TrainConfig(object):
def __init__(self, config):
self.batch_size = config.get('batch_size')
self.use_cuda = config.get('use_cuda')
self.max_len_seq = config.get('max_len_seq')
self.train_loader_workers = config.get('train_loader_workers')
self.test_loader_workers = config.get('test_loader_workers')
self.device = config.get('device')
self.output_dir = config.get('output_dir')
self.output_name = config.get('output_name')
self.best_name = config.get('best_name')
file_config = {
'vocab':'', # vocabulary idx2token, token2idx
'data': '', # formated data
'model_path': '', # where to save model
'model_name': '', # model name
'file_name': '', # log path
}
create_folder(file_config['model_path'])
global_params = {
'max_seq_len': 64,
'max_age': 110,
'month': 1,
'age_symbol': None,
'min_visit': 5,
'gradient_accumulation_steps': 1
}
optim_param = {
'lr': 3e-5,
'warmup_proportion': 0.1,
'weight_decay': 0.01
}
train_params = {
'batch_size': 256,
'use_cuda': True,
'max_len_seq': global_params['max_seq_len'],
'device': 'cuda:0'
}模型:
BertVocab = load_obj(file_config['vocab'])
ageVocab, _ = age_vocab(max_age=global_params['max_age'], mon=global_params['month'], symbol=global_params['age_symbol'])
data = pd.read_parquet(file_config['data'])
# remove patients with visits less than min visit
data['length'] = data['caliber_id'].apply(lambda x: len([i for i in range(len(x)) if x[i] == 'SEP']))
data = data[data['length'] >= global_params['min_visit']]
data = data.reset_index(drop=True)
Dset = MLMLoader(data, BertVocab['token2idx'], ageVocab, max_len=train_params['max_len_seq'], code='caliber_id')
trainload = DataLoader(dataset=Dset, batch_size=train_params['batch_size'], shuffle=True, num_workers=3)
model_config = {
'vocab_size': len(BertVocab['token2idx'].keys()), # number of disease + symbols for word embedding
'hidden_size': 288, # word embedding and seg embedding hidden size
'seg_vocab_size': 2, # number of vocab for seg embedding
'age_vocab_size': len(ageVocab.keys()), # number of vocab for age embedding
'max_position_embedding': train_params['max_len_seq'], # maximum number of tokens
'hidden_dropout_prob': 0.1, # dropout rate
'num_hidden_layers': 6, # number of multi-head attention layers required
'num_attention_heads': 12, # number of attention heads
'attention_probs_dropout_prob': 0.1, # multi-head attention dropout rate
'intermediate_size': 512, # the size of the "intermediate" layer in the transformer encoder
'hidden_act': 'gelu', # The non-linear activation function in the encoder and the pooler "gelu", 'relu', 'swish' are supported
'initializer_range': 0.02, # parameter weight initializer range
}
conf = BertConfig(model_config)
model = BertForMaskedLM(conf)
model = model.to(train_params['device'])
optim = adam(params=list(model.named_parameters()), config=optim_param)计算准确率:
def cal_acc(label, pred):
logs = nn.LogSoftmax()
label=label.cpu().numpy()
ind = np.where(label!=-1)[0]
truepred = pred.detach().cpu().numpy()
truepred = truepred[ind]
truelabel = label[ind]
truepred = logs(torch.tensor(truepred))
outs = [np.argmax(pred_x) for pred_x in truepred.numpy()]
precision = skm.precision_score(truelabel, outs, average='micro')
return precision开始训练:
def train(e, loader):
tr_loss = 0
temp_loss = 0
nb_tr_examples, nb_tr_steps = 0, 0
cnt= 0
start = time.time()
for step, batch in enumerate(loader):
cnt +=1
batch = tuple(t.to(train_params['device']) for t in batch)
age_ids, input_ids, posi_ids, segment_ids, attMask, masked_label = batch
loss, pred, label = model(input_ids, age_ids, segment_ids, posi_ids,attention_mask=attMask, masked_lm_labels=masked_label)
if global_params['gradient_accumulation_steps'] >1:
loss = loss/global_params['gradient_accumulation_steps']
loss.backward()
temp_loss += loss.item()
tr_loss += loss.item()
nb_tr_examples += input_ids.size(0)
nb_tr_steps += 1
if step % 200==0:
print("epoch: {}\t| cnt: {}\t|Loss: {}\t| precision: {:.4f}\t| time: {:.2f}".format(e, cnt, temp_loss/2000, cal_acc(label, pred), time.time()-start))
temp_loss = 0
start = time.time()
if (step + 1) % global_params['gradient_accumulation_steps'] == 0:
optim.step()
optim.zero_grad()
print("** ** * Saving fine - tuned model ** ** * ")
model_to_save = model.module if hasattr(model, 'module') else model # Only save the model it-self
create_folder(file_config['model_path'])
output_model_file = os.path.join(file_config['model_path'], file_config['model_name'])
torch.save(model_to_save.state_dict(), output_model_file)
cost = time.time() - start
return tr_loss, cost保存结果:
f = open(os.path.join(file_config['model_path'], file_config['file_name']), "w")
f.write('{}\t{}\t{}\n'.format('epoch', 'loss', 'time'))
for e in range(50):
loss, time_cost = train(e, trainload)
loss = loss/data_len
f.write('{}\t{}\t{}\n'.format(e, loss, time_cost))
f.close() 某大模型对上面代码梯度累积的解释:
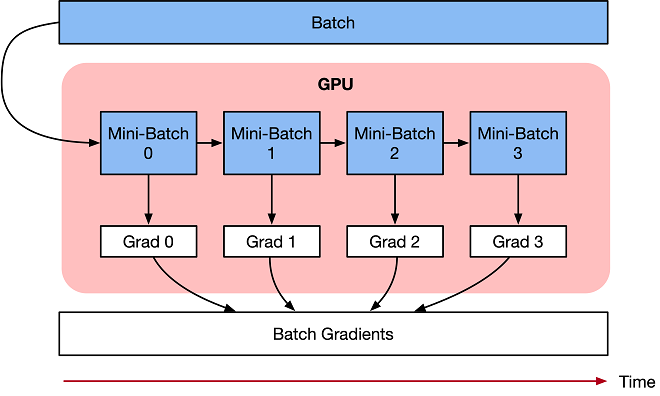
gradient_accumulation_steps 是一个用于在训练过程中累积梯度的参数。它的作用是在每次更新模型参数之前,累积多个 batch 的梯度,然后进行一次参数更新。这个技巧有助于在显存受限的情况下仍能使用较大的 batch size,并且可以稳定模型的训练过程。
对于BERT的MLM任务来说,通常会使用梯度累积,因为BERT是一个比较大的模型,使用较大的batch size可能会导致显存不足的问题,特别是在GPU资源受限的情况下。梯度累积可以帮助解决这个问题。
在你提供的代码中,gradient_accumulation_steps 的值被用来判断是否要对 loss 进行除法操作。如果 gradient_accumulation_steps 大于1,那么会将 loss 除以 gradient_accumulation_steps,以确保在多个batch的梯度累积后对参数进行更新。这是一个常见的做法。
因此,可以说对于BERT的MLM任务,使用梯度累积是一种常见的做法,特别是在资源受限的情况下。