模型验证是数据科学项目的重要组成部分,因为我们希望选择一个不仅在训练数据集上表现良好,而且在测试数据集上具有良好准确性的模型。模型验证帮助我们找到一个具有低方差的模型。
什么是验证曲线
验证曲线是一种重要的诊断工具,它显示了机器学习模型准确性变化与模型超参数变化之间的敏感性。
验证曲线在y轴上绘制模型性能指标(如准确度、F1分数或均方误差),在x轴上绘制超参数值的范围。模型的超参数值通常在对数尺度上变化,并且使用针对每个超参数值的交叉验证技术来训练和评估模型。
验证曲线中存在两条曲线-一条用于训练集得分,一条用于交叉验证得分。默认情况下,scikit-learn库中的验证曲线函数执行3折交叉验证。
验证曲线用于基于超参数评估现有模型,而不是用于调整模型。这是因为,如果我们根据验证分数调整模型,模型可能会偏向于模型调整的特定数据;因此,不是模型泛化的良好估计。
验证曲线说明
解释验证曲线的结果有时可能很棘手。在查看验证曲线时,请记住以下几点:
- 理想情况下,我们希望验证曲线和训练曲线看起来尽可能相似。
- 如果两个分数都很低,则模型可能是欠拟合的。这意味着要么模型太简单,要么特征太少。也可能是模型被正则化得太多。
- 如果训练曲线相对较快地达到高分,而验证曲线滞后,则模型是过拟合的。这意味着模型非常复杂,数据太少,或者它可能只是意味着数据太少。
- 我们希望训练和验证曲线两者的参数值是最接近的。
在Python中实现验证曲线
为了简单起见,在这个例子中,我们将使用非常流行的“digits”数据集,它已经存在于sklearn库的sklearn.dataset模块中。
对于这个例子,我们将使用k-最近邻(KNN)分类器,并将绘制模型在训练集得分和交叉验证得分上的准确性与“k”值的关系,即,要考虑的邻居的数量。代码实现5折交叉验证,并测试从1到10的“k”值。
# Import Required libraries
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import validation_curve
# Loading dataset
dataset = load_digits()
# X contains the data and y contains the labels
X, y = dataset.data, dataset.target
# Setting the range for the parameter (from 1 to 10)
parameter_range = np.arange(1, 10, 1)
# Calculate accuracy on training and test set using the
# gamma parameter with 5-fold cross validation
train_score, test_score = validation_curve(KNeighborsClassifier(), X, y,
param_name="n_neighbors",
param_range=parameter_range,
cv=5, scoring="accuracy")
# Calculating mean and standard deviation of training score
mean_train_score = np.mean(train_score, axis=1)
std_train_score = np.std(train_score, axis=1)
# Calculating mean and standard deviation of testing score
mean_test_score = np.mean(test_score, axis=1)
std_test_score = np.std(test_score, axis=1)
# Plot mean accuracy scores for training and testing scores
plt.plot(parameter_range, mean_train_score,
label="Training Score", color='b')
plt.plot(parameter_range, mean_test_score,
label="Cross Validation Score", color='g')
# Creating the plot
plt.title("Validation Curve with KNN Classifier")
plt.xlabel("Number of Neighbours")
plt.ylabel("Accuracy")
plt.tight_layout()
plt.legend(loc='best')
plt.show()
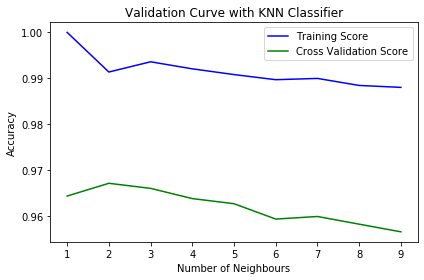
从这个图中,我们可以观察到’k’ = 2将是k的理想值。随着邻居数(k)的增加,训练分数和交叉验证分数的准确性都会降低。