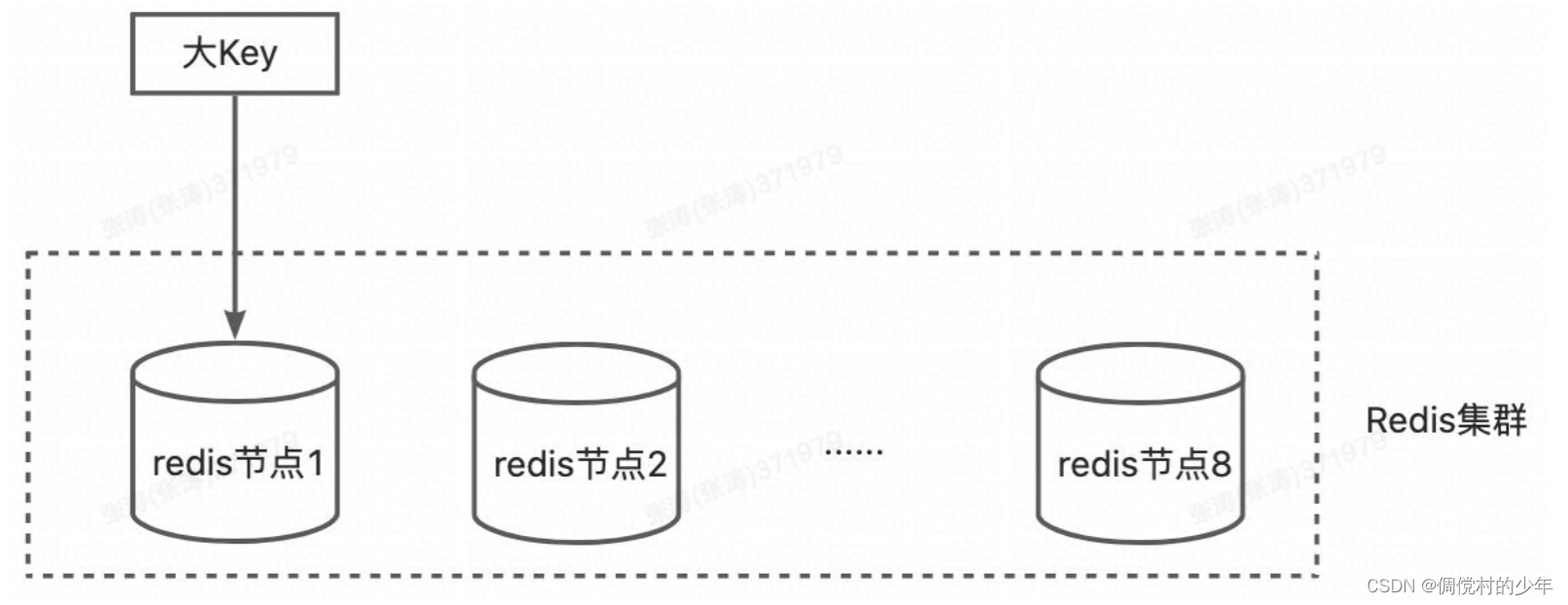
大key的大约标准:
单个string的value>1MB
容器(list,hash,set)元素数量超过1万
要根据场景进行判断
大key的影响;
- 读取时延
- 带宽
- 大key的写可能造成时延(单线程阻塞)
- 主从同步时延(单线程)
- 可能OOM
大key产生原因
- 业务拆分不合理
- 容器没有处理好定期删除
- bug:key的生命周期出问题
举例:
- 例子 1:社交网络中的好友列表
假设在一个社交网络应用中,使用Redis的列表(list)数据结构来存储每个用户的好友列表。对于一些非常受欢迎的用户,他们的好友数可能达到数万甚至更多。如果所有这些好友ID都存储在一个单独的list中,那么这个key就会非常大。
产生的问题:
- 对这个大list进行操作(如添加新好友、查找或删除好友)时会消耗大量的CPU和内存资源,导致性能瓶颈。
- 每次对这个list的操作可能需要加载整个list到内存中,这对内存和网络带宽都是一种压力。
- 例子 2:实时访问记录
考虑一个网站,它使用Redis的哈希表(hash)来存储每个用户对各个页面的访问计数。如果一个网站有成千上万个页面,并且每个用户都可能访问其中的多个页面,那么每个用户的哈希表中可能会包含大量的键值对。
问题:
- 单个hash key过大,导致操作此hash时耗时增加。
- 如果需要频繁更新或检索特定页面的访问计数,可能会因为单个大key导致Redis性能瓶颈。
- 例子 3:实时消息队列
一个应用使用Redis的列表来存储实时消息队列,如果消息生成的速度远大于消费的速度,或者某些消息需要保留较长时间,列表将不断增长。
问题:
- 大量积压的消息会使得list异常庞大。
- 试图读取或者删除列表中的元素,尤其是从列表中间操作时,会非常缓慢,并且占用大量的CPU资源。
如何查找大key
redis命令:
redis-cli --bigkeys
处理大key的流程
识别大keys
首先,需要确定哪些keys是“大”的。可以使用Redis的各种工具和命令来帮助识别:
使用redis-cli --bigkeys命令快速找到数据库中最大的keys。分析原因
一旦识别出大keys,需要分析为什么这些keys会变得这么大:
是因为业务需求本身需要存储大量数据,还是因为设计不当?
数据是否有过期时间,是否进行了适当的数据维护和清理?采取措施
根据大keys的类型和用途,可以采取不同的策略来处理:
对于List、Set、Sorted Set和Hash:
拆分大key:将一个大key拆分成多个小key。例如,可以根据时间或用户ID等逻辑将数据分散到多个keys中。
数据分页处理:如果应用场景允许,通过分页方式只加载需要的部分数据,而不是一次性加载整个key。
对于String:
如果是大型的String,考虑是否可以使用更加压缩的数据格式或者分割存储。
通用策略:
设置过期时间:为数据设置TTL(Time To Live),使得旧数据可以自动被清理,防止无限制地增长。
内存优化:优化数据存储格式,例如使用更紧凑的数据结构或者压缩数据。
监控和警报:持续监控key的大小和增长速度,一旦发现异常及时处理。优化应用设计
评估数据模型:重新评估和设计数据模型,使用更适合的数据结构和存储策略。
客户端缓存:对于读多写少的数据,可以考虑在客户端进行缓存,减少对Redis的访问压力。
负载均衡:对于热点数据,考虑采用负载均衡策略,如一致性哈希等,以均衡各节点负载。
































![【Pip】pip 安装第三方包异常:[SSL:CERTIFICATE_VERIFY_FAILED]解决方案](https://img-blog.csdnimg.cn/direct/a86a587fb65842c3a078c4dd54938aed.jpeg)