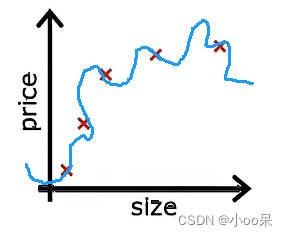
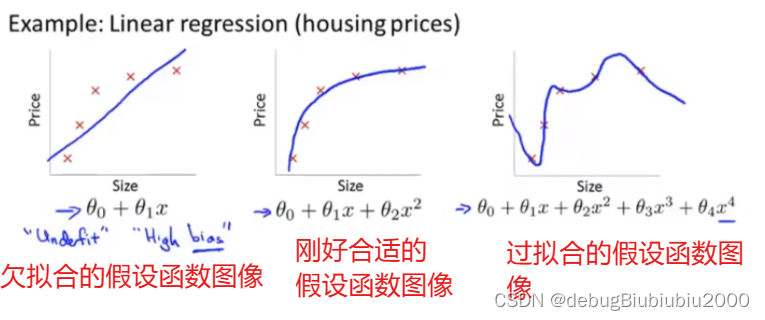
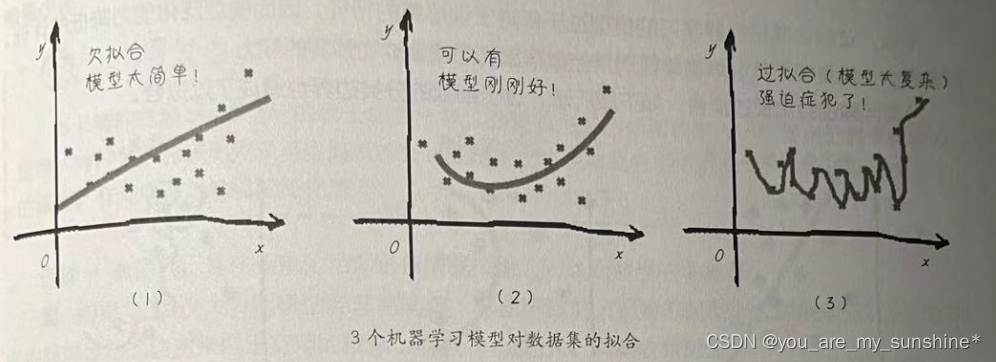
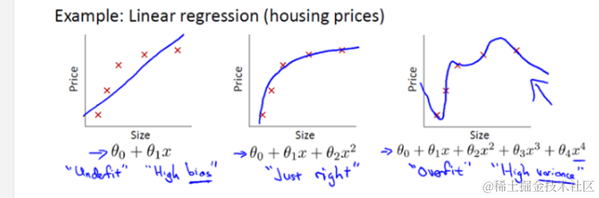
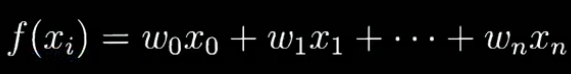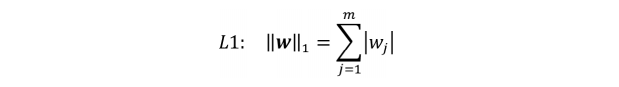在机器学习中,线性回归是一种常见的预测模型,旨在找到一个线性函数来尽可能准确地预测目标值。然而,当模型过于复杂,尤其是参数过多时,就会发生过拟合现象,即模型在训练数据上表现很好,但在新的、未见过的数据上表现不佳。为了控制过拟合,常用的方法之一就是添加正则化项。正则化通过对模型的复杂性加以惩罚,来避免过拟合。主要有两种正则化技术:L1正则化(Lasso回归)和L2正则化(Ridge回归)。
L1正则化(Lasso回归)
L1正则化通过在成本函数中添加权重的绝对值之和来工作。L1正则化的目标函数可以表达为:
J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 + λ ∑ j = 1 n ∣ θ j ∣ J(\theta) = \frac{1}{2m} \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})^2 + \lambda \sum_{j=1}^n |\theta_j| J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2+λj=1∑n∣θj∣
其中, m 是样本数量, h θ ( x ( i ) ) h_\theta(x^{(i)}) hθ(x(i))是假设函数,θ是模型参数, y 是目标值,λ 是正则化参数。
L1正则化的关键在于它倾向于产生稀疏的参数矩阵,即许多参数值会变成零。这样可以实现特征选择,因为模型会丢弃不重要的特征。
L2正则化(Ridge回归)
L2正则化通过在成本函数中添加权重的平方和来工作。L2正则化的目标函数可以表达为:
J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 + λ ∑ j = 1 n θ j 2 J(\theta) = \frac{1}{2m} \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})^2 + \lambda \sum_{j=1}^n \theta_j^2 J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2
与L1正则化类似,λ是控制正则化强度的参数。不同的是,L2正则化倾向于让参数值接近于零但不会完全为零,这有助于处理参数间的共线性问题,并且使模型的输出更加稳定。
推导步骤
对于线性回归的损失函数(均方误差),当我们添加正则化项时,其梯度下降的更新规则会发生变化。以L2正则化为例,求解梯度如下:
∇ θ J ( θ ) = 1 m ( X T ( X θ − y ) ) + λ θ \nabla_\theta J(\theta) = \frac{1}{m} \left(X^T(X\theta - y)\right) + \lambda \theta ∇θJ(θ)=m1(XT(Xθ−y))+λθ
这里, X 是设计矩阵,其中包含了所有的输入特征。
更新规则变为:
θ : = θ − α ( 1 m ( X T ( X θ − y ) ) + λ θ ) \theta := \theta - \alpha \left(\frac{1}{m} \left(X^T(X\theta - y)\right) + \lambda \theta\right) θ:=θ−α(m1(XT(Xθ−y))+λθ)
其中,α 是学习率。
L1正则化的梯度包含了绝对值,因此不可导于零点,通常使用次梯度或专门的优化算法如坐标下降来求解。
通过这些步骤,可以看出正则化如何通过调整成本函数和更新规则来减少模型复杂性,从而帮助控制过拟合。
我们可以通过一个简单的Python代码示例,使用scikit-learn库来实现L1和L2正则化。这个示例将包括生成一些合成数据,并应用Lasso回归(L1正则化)和Ridge回归(L2正则化)来拟合这些数据。下面是具体的步骤和代码:
示例
首先,确保你已经安装了scikit-learn和numpy。如果还没有安装,可以通过以下命令安装:
pip install numpy scikit-learn
生成数据
我们将生成一些合成数据来模拟一个线性关系,并添加一些噪声。
import numpy as np
from sklearn.model_selection import train_test_split
# 生成合成数据
np.random.seed(0)
X = 2.5 * np.random.randn(100, 1) + 1.5 # 生成100个数据点
res = 0.5 * np.random.randn(100, 1) # 噪声
y = 2 + 0.3 * X + res # 真实数据
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
应用Lasso回归(L1正则化)
from sklearn.linear_model import Lasso
# 实例化Lasso模型
lasso_reg = Lasso(alpha=0.1) # alpha是正则化强度
lasso_reg.fit(X_train, y_train)
# 在测试集上评估模型
lasso_train_score = lasso_reg.score(X_train, y_train)
lasso_test_score = lasso_reg.score(X_test, y_test)
lasso_coeff_used = np.sum(lasso_reg.coef_ != 0)
print("Lasso回归训练集分数: ", lasso_train_score)
print("Lasso回归测试集分数: ", lasso_test_score)
print("使用的特征数: ", lasso_coeff_used)
应用Ridge回归(L2正则化)
from sklearn.linear_model import Ridge
# 实例化Ridge模型
ridge_reg = Ridge(alpha=1) # alpha是正则化强度
ridge_reg.fit(X_train, y_train)
# 在测试集上评估模型
ridge_train_score = ridge_reg.score(X_train, y_train)
ridge_test_score = ridge_reg.score(X_test, y_test)
print("Ridge回归训练集分数: ", ridge_train_score)
print("Ridge回归测试集分数: ", ridge_test_score)
这段代码展示了如何通过Lasso和Ridge回归来减少线性模型的过拟合。这些正则化技术有助于在增加模型的泛化能力的同时,减少模型对训练数据的过度拟合。在实际应用中,可以通过调整alpha参数来控制正则化的强度,以达到最佳的模型性能。