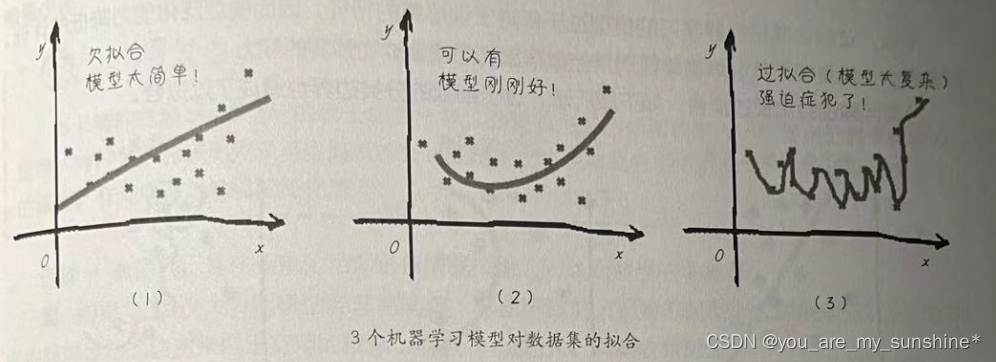
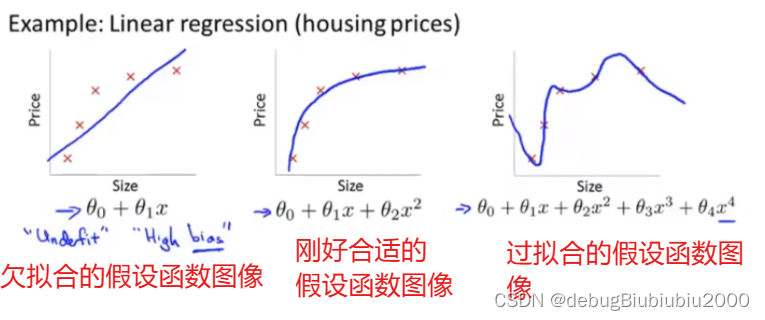
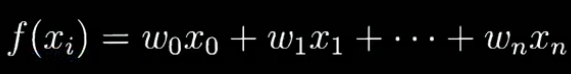如果我们注意到模型在训练集上的表现明显优于模型在测试集上的表现,那么这就是模型过拟合了,也称为 high variance。
产生的过拟合的原因是对于给定的训练集数据来说,模型太复杂了。有几种可以减少过拟合的方法:
收集更多的训练数据(通常可行性不大)
通过正则化引入对模型复杂度的惩罚
选择一个含有较少参数的简单模型
减少数据的维度
假设模型的参数是向量 w,那么 L1 和 L2 正则化的定义如下。
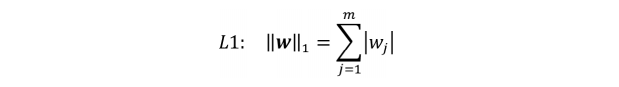
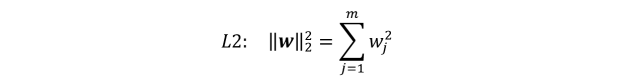
L1 正则化通常会产生更稀疏的特征空间,大部分的特征对应的权重都是 0。
如果我们在处理高维且大多数特征都互不相关的数据集时,稀疏性就会十分有用,尤其是在训练数据集样本数比样本特征数还少时。此时 L1 正则化也可以被视为是一种特征选择工具,我们将在下一课学习特征选择。
我们在训练机器学习模型时的目标是使模型在训练集和测试集上的损失不断降低,损失是通过损失函数计算出来的。L1 正则化和 L2 正则化就是在损失函数后面再加上惩罚模型复杂度的因子,并且还附带一个取值在 [0.0, 1.0] 之前的参数 λ 控制惩罚力度。

在 scikit-learn 库中,我们只需要指定 penalty='l1' 或 penalty='l2' 就可以选择使用 L1 还是 L2 正则化了。注意!solver 参数指定了优化算法,lbfgs 优化算法不支持 L1 正则化。
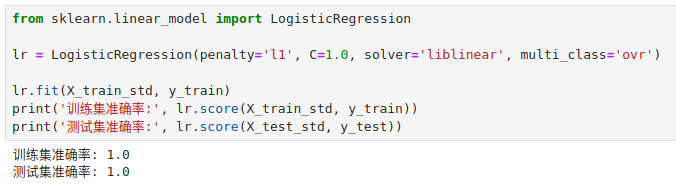
我们用逻辑回归算法拟合了经过标准化的红酒数据集后发现,模型在训练集和测试集上的准确率都达到了 100%!
除此之外,你可能还注意到还有两个参数:
C 就是 λ 的倒数,默认值是 1.0
multi_class='ovr',这表示使用 one-versus-rest 方法将二分类模型应用到多分类
one-versus-rest(OVR)也称为 one-versus-all,是一种将二分类模型应用到多分类任务中的方法。以红酒数据集为例,这是数据集具有三种类别,那么就训练三个二分类器,每个二分类器都将其中一种类别作为正例,其他两种类别作为反例。最终预测时选择得分结果最高的分类器预测的正例对应的类别作为最终的预测类别。
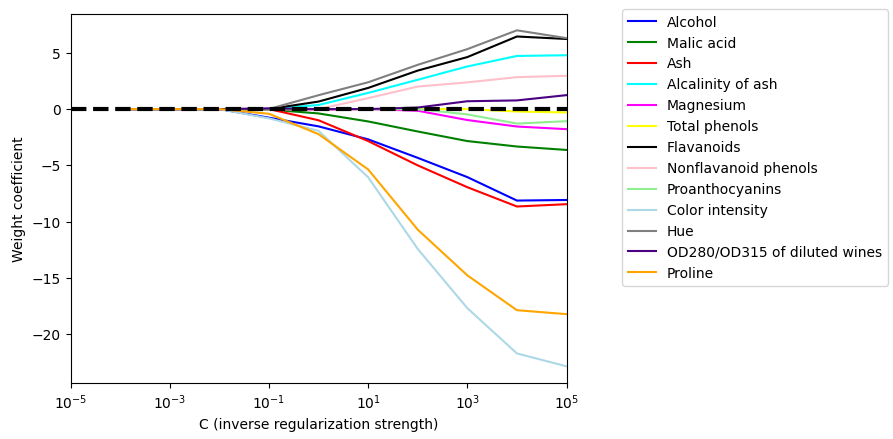
我们可以看到有 3 个权重和对应的偏置(bias)。
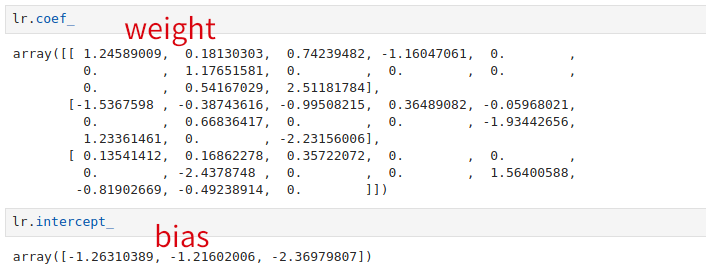
我们也能看到有几个特征对应的权重值为 0,所以 L1 正则化也能用作特征选择。我们可以增大正则化项系数 λ(减小参数 C)时会剔除更多的特征,当 C < 0.01(λ > 100)时,所有特征对应的权重都是 0。