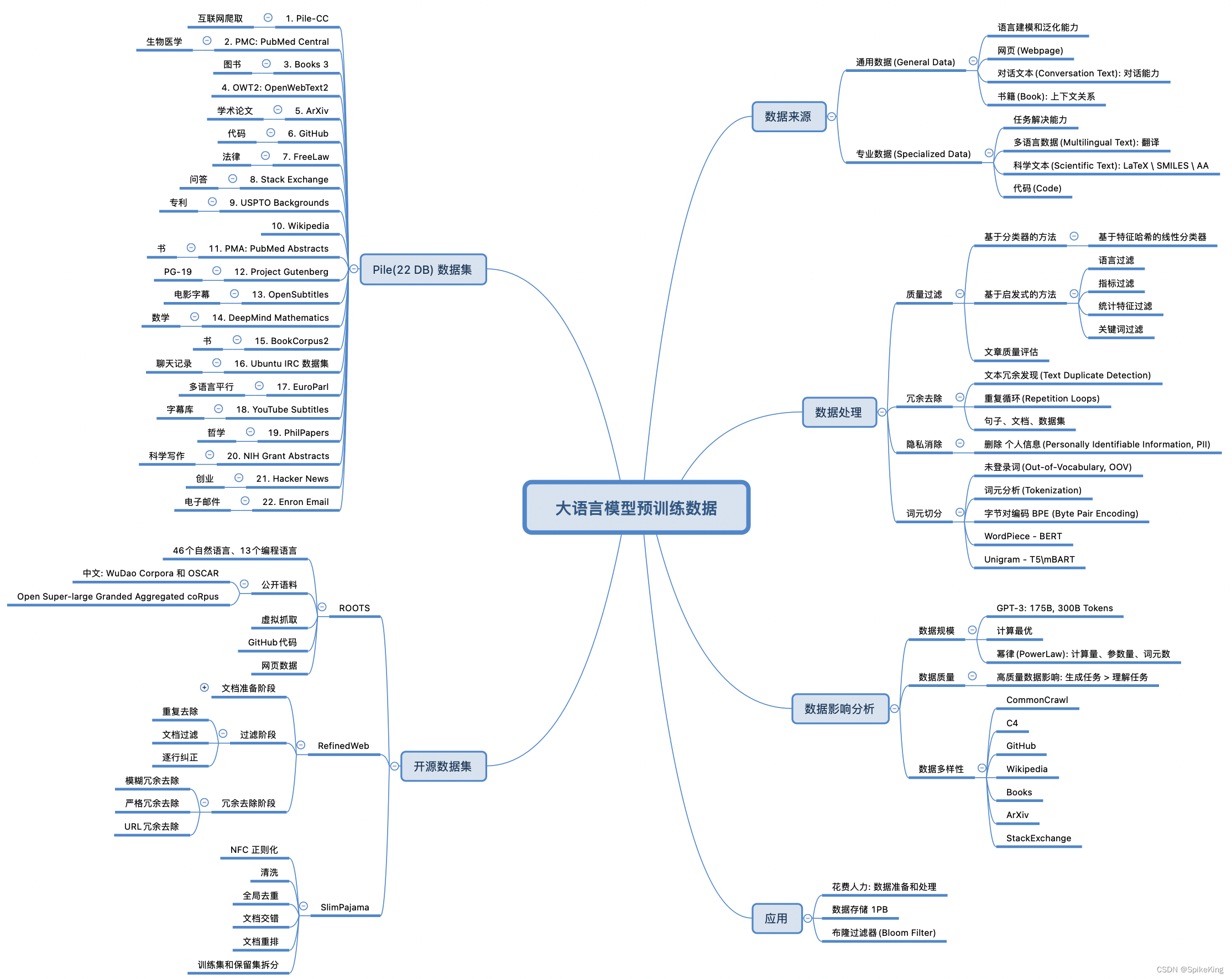
一.预训练模型的基本介绍
预训练模型是一种在大规模数据上训练而得的模型,通常通过无监督学习或自监督学习的方式进行。在预训练阶段,模型被训练来学习数据的内在表示,而无需标注数据或任务特定的目标函数。这种学习能力使得预训练模型可以捕获数据的复杂结构和特征,并且在后续的特定任务上进行微调,从而提高模型在目标任务上的性能。
1.1 预训练过程
- 数据收集与处理:收集大规模的数据,并对数据进行预处理,以便模型训练使用。
- 模型架构选择:选择适合预训练的模型架构,通常采用深度神经网络,如Transformer、CNN或RNN等。
- 无监督/自监督学习:在大规模数据上进行无监督学习或自监督学习。例如,对于语言模型,可以使用大量的文本数据进行语言模型的预训练;对于图像模型,可以使用图像数据进行图像的自监督学习。
- 特征提取或模型训练:根据具体任务,预训练模型可以用于特征提取,也可以在预训练模型的基础上继续训练。
1.2 预训练模型的类型
- 无监督预训练模型:在大规模无标签数据上进行训练,如自编码器、变分自编码器等。
- 自监督预训练模型:利用数据自身的结构进行训练,如语言模型、图像的像素级别预测任务等。
- 监督预训练模型:在大规模有标签数据上进行训练,然后再进行微调,如预训练的卷积神经网络(Pretrained CNN)。
1.3 应用
预训练模型的应用非常广泛,包括但不限于:
- 自然语言处理(NLP):如BERT、GPT等预训练模型在文本分类、命名实体识别、机器翻译等任务上取得了巨大成功。
- 计算机视觉(CV):如ImageNet上预训练的CNN模型在图像分类、目标检测、图像分割等任务中被广泛使用。
- 强化学习:如使用预训练的模型进行策略学习和价值估计等任务。
- 推荐系统:如使用预训练的模型进行用户行为分析和推荐任务。
1.4 优势
提高模型的泛化能力:通过在大规模数据上学习到的通用特征,模型可以更好地适应各种任务和领域。
节省计算资源和时间:预训练模型可以利用大规模数据和大规模计算资源进行训练,然后在特定任务上进行微调,避免了从头开始训练模型所需的大量计算资源和时间。
二.预训练模型huggingface简介
Hugging Face是一个以自然语言处理(NLP)为主要领域的开源社区和平台,致力于开发和分享先进的NLP模型、工具和资源。该平台提供了许多预训练的NLP模型,包括BERT、GPT、RoBERTa等,并提供了易于使用的API和工具,使得研究人员和开发者可以轻松地访问和使用这些模型。
以下是Hugging Face平台的主要特点和功能:
模型库(Model Hub):Hugging Face提供了丰富的预训练NLP模型,用户可以通过Model Hub浏览和搜索各种模型,包括不同架构、不同任务和不同语言的模型。
Transformers库:Hugging Face开发了Transformers库,这是一个用于自然语言处理任务的Python库,提供了一种简单且强大的方式来加载、使用和微调预训练模型。
API和工具:Hugging Face提供了简单易用的API和工具,使得用户可以轻松地使用预训练模型进行文本生成、文本分类、问答等任务。
模型微调:Hugging Face平台支持用户对预训练模型进行微调,以适应特定的任务和数据集。
社区贡献:Hugging Face是一个开源社区,用户可以贡献自己的模型、工具和资源,并与其他研究人员和开发者进行交流和合作。
教育资源:Hugging Face提供了丰富的教育资源,包括教程、文档、示例代码等,帮助用户快速上手和使用NLP模型和工具。
三.ALBERT的中文命名实体识别
ALBERT是一种基于Transformer架构的预训练模型,在自然语言处理领域取得了很好的成绩。虽然ALBERT本身没有专门针对命名实体识别(Named Entity Recognition, NER)任务进行预训练,但可以利用ALBERT模型进行NER任务。在使用ALBERT进行中文命名实体识别时,一种常见的做法是使用ALBERT模型作为特征提取器,然后在其上构建一个用于NER任务的特定模型。下面是一种实现方法:
数据准备:准备包含标注的中文文本数据集,其中包含了命名实体的标注信息(如人名、地名、组织名等)。
模型构建:使用Hugging Face提供的ALBERT预训练模型,加载预训练参数,并在其之上构建一个用于NER任务的模型。在这个模型中,通常会加入一个用于NER的输出层,例如线性层或条件随机场(Conditional Random Field, CRF)等。
微调:使用准备好的数据集对ALBERT模型进行微调,即通过在NER任务上对模型进行训练,使其学会识别中文文本中的命名实体。
评估:使用评估集对微调后的模型进行评估,以衡量其在命名实体识别任务上的性能。常用的评估指标包括精确率(Precision)、召回率(Recall)和F1分数(F1-score)等。
推理:使用微调后的模型对新的未标注文本进行命名实体识别,识别其中的命名实体并给出其类别。
在实践中,可以使用Hugging Face提供的Transformers库来加载和使用ALBERT模型,同时结合其他Python库(如PyTorch或TensorFlow)来构建和训练用于NER任务的模型。
以下是一个使用 Hugging Face Transformers 库和 PyTorch 实现 ALBERT 模型进行中文命名实体识别的简单示例代码。这个示例代码假设您已经准备好了适用于命名实体识别任务的数据集,并且每个样本都是一个中文句子,并且包含标注的命名实体信息。
import torch
from transformers import AlbertTokenizer, AlbertForTokenClassification
from torch.utils.data import DataLoader, TensorDataset
from sklearn.metrics import classification_report
import numpy as np
# 加载 ALBERT 模型和分词器
model_name = "voidful/albert_chinese_base"
tokenizer = AlbertTokenizer.from_pretrained(model_name)
model = AlbertForTokenClassification.from_pretrained(model_name, num_labels=5) # 5 是标签的数量,根据实际情况进行更改
# 数据集准备
# 假设您已经准备好了适用于命名实体识别任务的数据集,每个样本都是一个句子,并且包含标注的命名实体信息
# 这里假设您将数据集格式化为了一个列表,每个列表元素包含一个句子和对应的标签
dataset = [
("小明和张三在北京开了一家公司。", ["PER", "PER", "LOC", "O", "O", "O", "O", "O", "O"]),
# 其他样本...
]
# 将文本和标签转换为模型所需的输入格式
inputs = []
labels = []
for text, text_labels in dataset:
tokenized_text = tokenizer.tokenize(text)
encoded_text = tokenizer.encode(text, add_special_tokens=False)
encoded_labels = [0] # CLS 标签
for i, label in enumerate(text_labels):
encoded_labels.extend([int(label)] * len(tokenizer.tokenize(text.split()[i])))
inputs.append(encoded_text)
labels.append(encoded_labels)
# 将输入和标签转换为 PyTorch 张量并创建数据加载器
inputs = torch.nn.utils.rnn.pad_sequence([torch.tensor(seq) for seq in inputs], batch_first=True)
labels = torch.nn.utils.rnn.pad_sequence([torch.tensor(seq) for seq in labels], batch_first=True)
attention_mask = (inputs != 0).type(torch.uint8)
dataset = TensorDataset(inputs, attention_mask, labels)
loader = DataLoader(dataset, batch_size=8)
# 模型微调
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.train()
model.to(device)
for epoch in range(3): # 假设进行 3 个 epochs 的训练
for batch in loader:
input_ids, attention_mask, labels = batch
input_ids, attention_mask, labels = input_ids.to(device), attention_mask.to(device), labels.to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
# 评估模型
model.eval()
predictions = []
true_labels = []
for batch in loader:
input_ids, attention_mask, labels = batch
input_ids, attention_mask, labels = input_ids.to(device), attention_mask.to(device), labels.to(device)
with torch.no_grad():
outputs = model(input_ids, attention_mask=attention_mask)
predictions.extend(torch.argmax(outputs.logits, dim=2).cpu().numpy())
true_labels.extend(labels.cpu().numpy())
# 打印分类报告
flat_predictions = np.concatenate(predictions)
flat_true_labels = np.concatenate(true_labels)
print(classification_report(flat_true_labels, flat_predictions))