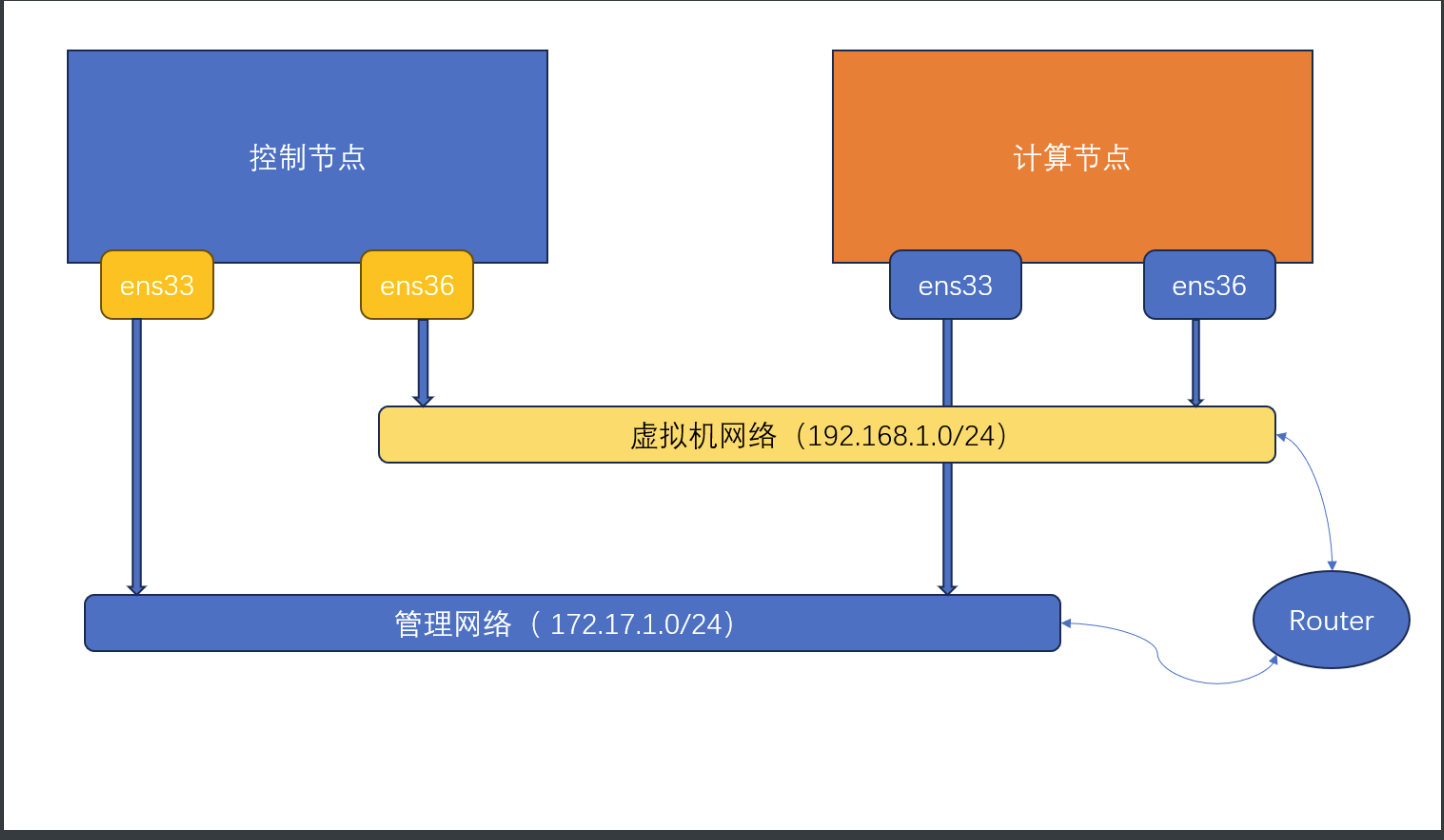
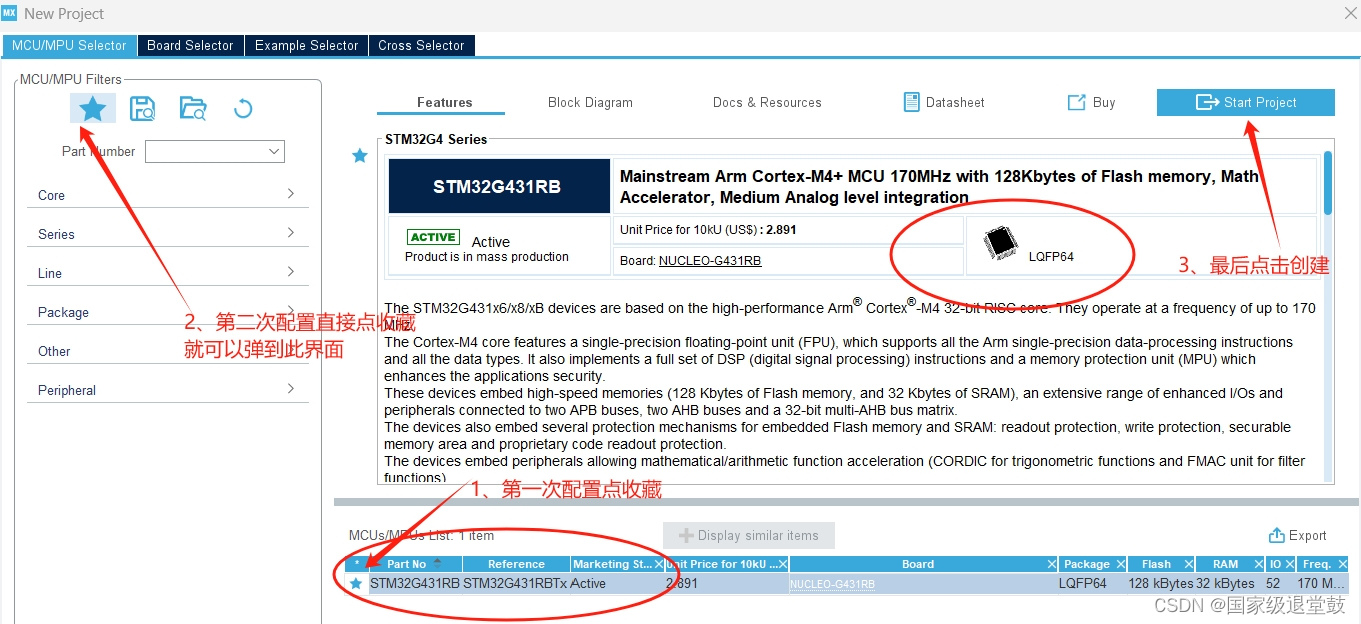
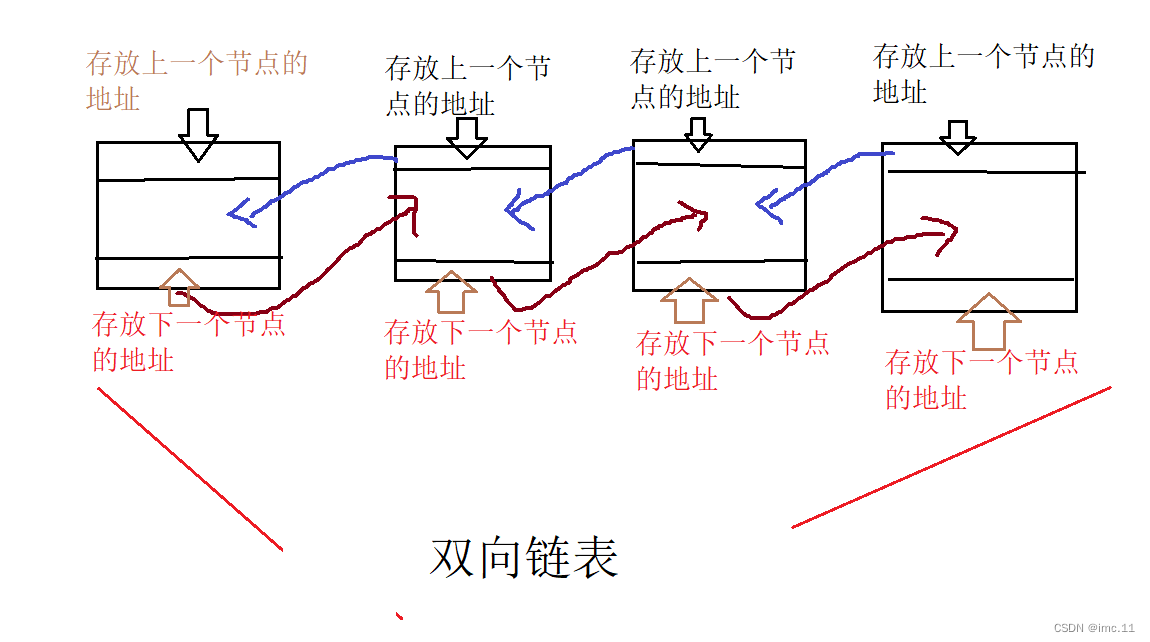
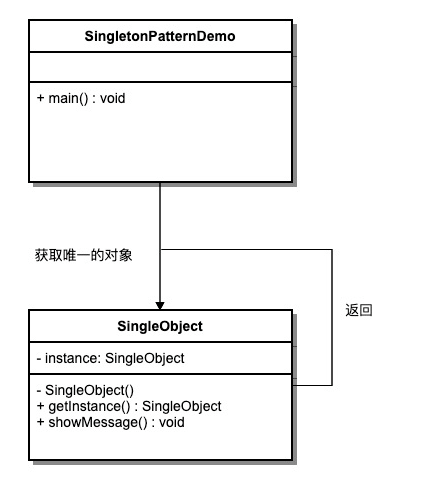
NLP预训练模型(Natural Language Processing pre-training model)是一种通过无监督学习方式在大规模文本数据上进行训练的模型。这些模型通常采用深度学习的方法,如自编码器、语言模型等,通过学习语言的统计规律和语义信息,提取文本的特征表示。预训练模型的目标是学习到一个通用的语言模型,能够理解和生成自然语言。
常见的NLP预训练模型有:
Word2Vec:将每个词映射为一个固定维度的向量表示,使得具有相似语义的词在向量空间中距离较近。
GloVe:类似于Word2Vec,通过统计词语共现信息,生成词向量表示。
FastText:在Word2Vec的基础上,进一步考虑了词语的子词信息,使得模型对于低频词和未登录词有更好的处理能力。
ELMo(Embeddings from Language Models):使用双向语言模型学习词语的上下文相关表示,通过将词向量与上下文表示进行拼接,获得更丰富的词语表示。
BERT(Bidirectional Encoder Representations from Transformers):基于Transformer模型,采用Masked Language Model(MLM)和Next Sentence Prediction(NSP)两个无监督的预训练任务,学习出双向上下文相关的词语表示。
GPT(Generative Pre-trained Transformer):基于Transformer模型,通过自回归语言模型任务,在大规模文本上进行训练,生成语义连贯、有逻辑的文本。
这些预训练模型通常在大规模语料上进行训练,并且通常可以进行微调,以适应特定的下游任务,如情感分析、文本分类等。预训练模型的使用可以大大提高NLP任务的性能,并减少训练数据的需求。