目录
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras机器学习实战
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
本文目标:利用混合技术对图像分类进行数据扩增。
简介
mixup 是由 Zhang 等人在 mixup.Beyond Empirical Risk Minimization 一书中提出的一种与领域无关的数据增强技术。
这项技术的名称相当系统。从字面上看,我们是在混合特征及其相应的标签。实施起来很简单。神经网络很容易记住错误的标签。mixup 通过将不同的特征相互组合(标签也是如此)来放松这一点,这样网络就不会对特征及其标签之间的关系过于自信。
当我们不确定是否要为给定数据集(例如医学影像数据集)选择一组增强变换时,mixup 特别有用。
设置
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import numpy as np
import keras
import matplotlib.pyplot as plt
from keras import layers
# TF imports related to tf.data preprocessing
from tensorflow import data as tf_data
from tensorflow import image as tf_image
from tensorflow.random import gamma as tf_random_gamma准备数据集
在本例中,我们将使用 FashionMNIST 数据集。但同样的方法也可用于其他分类数据集。
(x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
x_train = x_train.astype("float32") / 255.0
x_train = np.reshape(x_train, (-1, 28, 28, 1))
y_train = keras.ops.one_hot(y_train, 10)
x_test = x_test.astype("float32") / 255.0
x_test = np.reshape(x_test, (-1, 28, 28, 1))
y_test = keras.ops.one_hot(y_test, 10)定义超参数
AUTO = tf_data.AUTOTUNE
BATCH_SIZE = 64
EPOCHS = 10将数据转换为 TensorFlow 数据集对象
# Put aside a few samples to create our validation set
val_samples = 2000
x_val, y_val = x_train[:val_samples], y_train[:val_samples]
new_x_train, new_y_train = x_train[val_samples:], y_train[val_samples:]
train_ds_one = (
tf_data.Dataset.from_tensor_slices((new_x_train, new_y_train))
.shuffle(BATCH_SIZE * 100)
.batch(BATCH_SIZE)
)
train_ds_two = (
tf_data.Dataset.from_tensor_slices((new_x_train, new_y_train))
.shuffle(BATCH_SIZE * 100)
.batch(BATCH_SIZE)
)
# Because we will be mixing up the images and their corresponding labels, we will be
# combining two shuffled datasets from the same training data.
train_ds = tf_data.Dataset.zip((train_ds_one, train_ds_two))
val_ds = tf_data.Dataset.from_tensor_slices((x_val, y_val)).batch(BATCH_SIZE)
test_ds = tf_data.Dataset.from_tensor_slices((x_test, y_test)).batch(BATCH_SIZE)定义混合技术函数
为了执行混合例程,我们使用同一数据集的训练数据创建新的虚拟数据集,并应用从 Beta 分布采样的 [0, 1] 范围内的 lambda 值,例如,new_x = lambda * x1 + (1 - lambda) * x2(其中 x1 和 x2 为图像),同样的等式也应用于标签。
def sample_beta_distribution(size, concentration_0=0.2, concentration_1=0.2):
gamma_1_sample = tf_random_gamma(shape=[size], alpha=concentration_1)
gamma_2_sample = tf_random_gamma(shape=[size], alpha=concentration_0)
return gamma_1_sample / (gamma_1_sample + gamma_2_sample)
def mix_up(ds_one, ds_two, alpha=0.2):
# Unpack two datasets
images_one, labels_one = ds_one
images_two, labels_two = ds_two
batch_size = keras.ops.shape(images_one)[0]
# Sample lambda and reshape it to do the mixup
l = sample_beta_distribution(batch_size, alpha, alpha)
x_l = keras.ops.reshape(l, (batch_size, 1, 1, 1))
y_l = keras.ops.reshape(l, (batch_size, 1))
# Perform mixup on both images and labels by combining a pair of images/labels
# (one from each dataset) into one image/label
images = images_one * x_l + images_two * (1 - x_l)
labels = labels_one * y_l + labels_two * (1 - y_l)
return (images, labels)请注意,这里我们是将两幅图像合并为一幅。理论上,我们可以组合任意多的图像,但这样做会增加计算成本。在某些情况下,这可能也无助于提高性能。
可视化新的增强数据集
# First create the new dataset using our `mix_up` utility
train_ds_mu = train_ds.map(
lambda ds_one, ds_two: mix_up(ds_one, ds_two, alpha=0.2),
num_parallel_calls=AUTO,
)
# Let's preview 9 samples from the dataset
sample_images, sample_labels = next(iter(train_ds_mu))
plt.figure(figsize=(10, 10))
for i, (image, label) in enumerate(zip(sample_images[:9], sample_labels[:9])):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image.numpy().squeeze())
print(label.numpy().tolist())
plt.axis("off")演绎展示:
[0.0, 0.9964277148246765, 0.0, 0.0, 0.003572270041331649, 0.0, 0.0, 0.0, 0.0, 0.0]
[0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
[0.0, 0.0, 0.0, 0.0, 0.9794676899909973, 0.02053229510784149, 0.0, 0.0, 0.0, 0.0]
[0.0, 0.0, 0.0, 0.0, 0.9536369442939758, 0.0, 0.0, 0.0, 0.04636305570602417, 0.0]
[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.7631776928901672, 0.0, 0.0, 0.23682232201099396]
[0.0, 0.0, 0.045958757400512695, 0.0, 0.0, 0.0, 0.9540412425994873, 0.0, 0.0, 0.0]
[0.0, 0.0, 0.0, 0.0, 2.8015051611873787e-08, 0.0, 0.0, 1.0, 0.0, 0.0]
[0.0, 0.0, 0.0, 0.0003173351287841797, 0.0, 0.9996826648712158, 0.0, 0.0, 0.0, 0.0]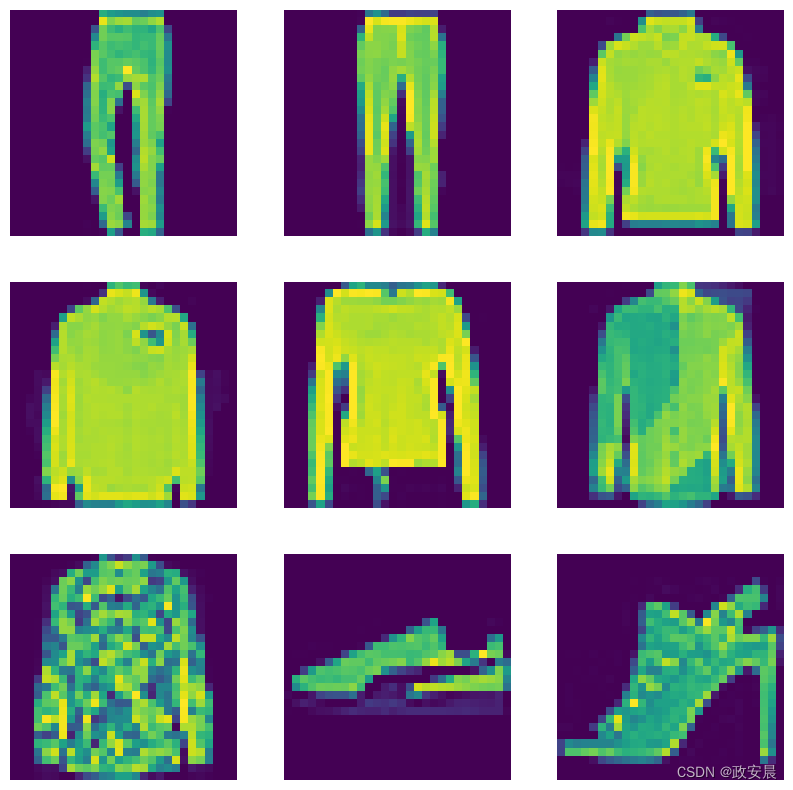
模型制作
def get_training_model():
model = keras.Sequential(
[
layers.Input(shape=(28, 28, 1)),
layers.Conv2D(16, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(32, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Dropout(0.2),
layers.GlobalAveragePooling2D(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax"),
]
)
return model为了提高可重复性,我们将浅层网络的初始随机权重序列化。
initial_model = get_training_model()
initial_model.save_weights("initial_weights.weights.h5")1.使用混合数据集训练模型
model = get_training_model()
model.load_weights("initial_weights.weights.h5")
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(train_ds_mu, validation_data=val_ds, epochs=EPOCHS)
_, test_acc = model.evaluate(test_ds)
print("Test accuracy: {:.2f}%".format(test_acc * 100))Epoch 1/10
62/907 ━[37m━━━━━━━━━━━━━━━━━━━ 2s 3ms/step - accuracy: 0.2518 - loss: 2.2072
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1699655923.381468 16749 device_compiler.h:187] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
907/907 ━━━━━━━━━━━━━━━━━━━━ 13s 9ms/step - accuracy: 0.5335 - loss: 1.4414 - val_accuracy: 0.7635 - val_loss: 0.6678
Epoch 2/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 12s 4ms/step - accuracy: 0.7168 - loss: 0.9688 - val_accuracy: 0.7925 - val_loss: 0.5849
Epoch 3/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 5s 4ms/step - accuracy: 0.7525 - loss: 0.8940 - val_accuracy: 0.8290 - val_loss: 0.5138
Epoch 4/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 4s 3ms/step - accuracy: 0.7742 - loss: 0.8431 - val_accuracy: 0.8360 - val_loss: 0.4726
Epoch 5/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 3s 3ms/step - accuracy: 0.7876 - loss: 0.8095 - val_accuracy: 0.8550 - val_loss: 0.4450
Epoch 6/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 3s 3ms/step - accuracy: 0.8029 - loss: 0.7794 - val_accuracy: 0.8560 - val_loss: 0.4178
Epoch 7/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 2s 3ms/step - accuracy: 0.8039 - loss: 0.7632 - val_accuracy: 0.8600 - val_loss: 0.4056
Epoch 8/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 3s 3ms/step - accuracy: 0.8115 - loss: 0.7465 - val_accuracy: 0.8510 - val_loss: 0.4114
Epoch 9/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 3s 3ms/step - accuracy: 0.8115 - loss: 0.7364 - val_accuracy: 0.8645 - val_loss: 0.3983
Epoch 10/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 3s 3ms/step - accuracy: 0.8182 - loss: 0.7237 - val_accuracy: 0.8630 - val_loss: 0.3735
157/157 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.8610 - loss: 0.4030
Test accuracy: 85.82%2.在没有混合数据集的情况下训练模型
model = get_training_model()
model.load_weights("initial_weights.weights.h5")
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
# Notice that we are NOT using the mixed up dataset here
model.fit(train_ds_one, validation_data=val_ds, epochs=EPOCHS)
_, test_acc = model.evaluate(test_ds)
print("Test accuracy: {:.2f}%".format(test_acc * 100))Epoch 1/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 8s 6ms/step - accuracy: 0.5690 - loss: 1.1928 - val_accuracy: 0.7585 - val_loss: 0.6519
Epoch 2/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 5s 2ms/step - accuracy: 0.7525 - loss: 0.6484 - val_accuracy: 0.7860 - val_loss: 0.5799
Epoch 3/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 2s 2ms/step - accuracy: 0.7895 - loss: 0.5661 - val_accuracy: 0.8205 - val_loss: 0.5122
Epoch 4/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8148 - loss: 0.5126 - val_accuracy: 0.8415 - val_loss: 0.4375
Epoch 5/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8306 - loss: 0.4636 - val_accuracy: 0.8610 - val_loss: 0.3913
Epoch 6/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 2s 2ms/step - accuracy: 0.8433 - loss: 0.4312 - val_accuracy: 0.8680 - val_loss: 0.3734
Epoch 7/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8544 - loss: 0.4072 - val_accuracy: 0.8750 - val_loss: 0.3606
Epoch 8/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8577 - loss: 0.3913 - val_accuracy: 0.8735 - val_loss: 0.3520
Epoch 9/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8645 - loss: 0.3803 - val_accuracy: 0.8725 - val_loss: 0.3536
Epoch 10/10
907/907 ━━━━━━━━━━━━━━━━━━━━ 3s 3ms/step - accuracy: 0.8686 - loss: 0.3597 - val_accuracy: 0.8745 - val_loss: 0.3395
157/157 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step - accuracy: 0.8705 - loss: 0.3672
Test accuracy: 86.92%我们鼓励读者在不同领域的不同数据集上试用 mixup,并尝试使用 lambda 参数。我们强烈建议您同时查看原始论文--作者介绍了几项关于 mixup 的消融研究,展示了 mixup 如何提高泛化效果,并展示了他们将两幅以上图像合并为一幅图像的结果。
说明
× 通过混合,您可以创建合成示例,尤其是在缺乏大型数据集的情况下,而不会产生高昂的计算成本。
× 标签平滑和 mixup 通常不能很好地结合使用,因为标签平滑已经对硬标签进行了一定程度的修改。
× 在使用有监督对比学习(SCL)时,mixup 不能很好地发挥作用,因为 SCL 在预训练阶段就需要真实标签。
× mixup 的其他一些优势还包括(如论文所述)对对抗性示例的鲁棒性和稳定的生成对抗网络(GAN)训练。
× 有许多数据增强技术可以扩展 mixup,如 CutMix 和 AugMix。