目录
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras机器学习实战
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
在 Kaggle Cats vs Dogs 数据集上从头开始训练图像分类器。
简介
本示例展示了如何从零开始进行图像分类,从磁盘上的 JPEG 图像文件开始,而无需利用预训练的权重或预制的 Keras 应用程序模型。
我们在 Kaggle Cats vs Dogs 二进制分类数据集上演示了该工作流程。
我们使用 image_dataset_from_directory 实用程序生成数据集,并使用 Keras 图像预处理层进行图像标准化和数据扩增。
设置
接下来的演绎咱们在Kaggle上进行。
import os
import numpy as np
import keras
from keras import layers
from tensorflow import data as tf_data
import matplotlib.pyplot as plt演绎:
加载数据:猫与狗数据集
原始数据下载
首先,让我们下载 786M 的原始数据 ZIP 压缩包:
!curl -O https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_5340.zip!unzip -q kagglecatsanddogs_5340.zip
!ls演绎如下:
现在,我们有一个 PetImages 文件夹,其中包含两个子文件夹:猫和狗。每个子文件夹都包含每个类别的图片文件。
!ls PetImages
滤除损坏的图像
在处理大量真实世界的图像数据时,损坏图像是常有的事。让我们来过滤掉标题中没有 "JFIF "字符串的编码不良图像。
num_skipped = 0
for folder_name in ("Cat", "Dog"):
folder_path = os.path.join("PetImages", folder_name)
for fname in os.listdir(folder_path):
fpath = os.path.join(folder_path, fname)
try:
fobj = open(fpath, "rb")
is_jfif = b"JFIF" in fobj.peek(10)
finally:
fobj.close()
if not is_jfif:
num_skipped += 1
# Delete corrupted image
os.remove(fpath)
print(f"Deleted {num_skipped} images.")演绎:

生成数据集
image_size = (180, 180)
batch_size = 128
train_ds, val_ds = keras.utils.image_dataset_from_directory(
"PetImages",
validation_split=0.2,
subset="both",
seed=1337,
image_size=image_size,
batch_size=batch_size,
)演绎如下:

将数据可视化
以下是训练数据集中的前 9 幅图像。
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(np.array(images[i]).astype("uint8"))
plt.title(int(labels[i]))
plt.axis("off")
使用图像数据增强
在没有大型图像数据集的情况下,通过对训练图像进行随机但真实的变换,例如随机水平翻转或小幅随机旋转,人为地引入样本多样性是一种很好的做法。这有助于让模型接触到训练数据的不同方面,同时减缓过度拟合。
data_augmentation_layers = [
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
]
def data_augmentation(images):
for layer in data_augmentation_layers:
images = layer(images)
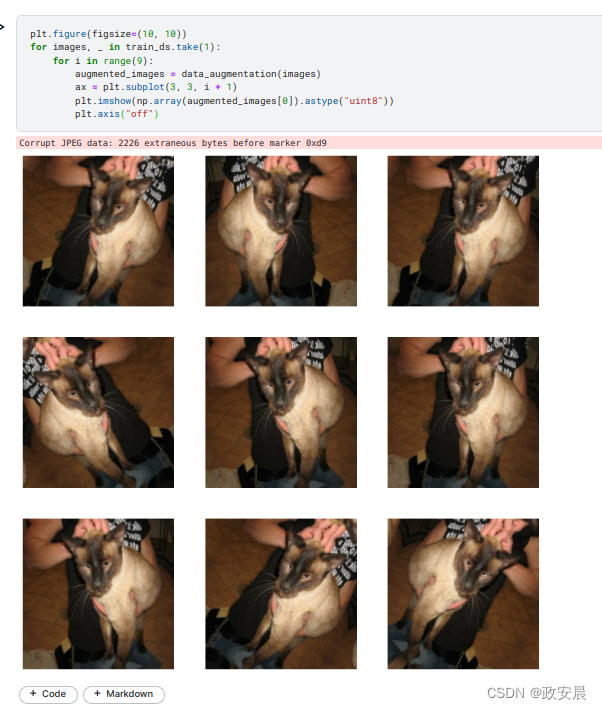
return images让我们对数据集中的前几张图片反复应用 data_augmentation,直观地看看增强后的样本是什么样的:
plt.figure(figsize=(10, 10))
for images, _ in train_ds.take(1):
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(np.array(augmented_images[0]).astype("uint8"))
plt.axis("off")演绎如下:
数据标准化
我们的图像已经是标准尺寸(180x180),因为它们是由我们的数据集生成的连续 float32 批次。不过,它们的 RGB 通道值在 [0, 255] 范围内。
这对于神经网络来说并不理想;
一般来说,你应该尽量使输入值小一些。
在此,我们将在模型开始时使用重缩放层(Rescaling layer),将值标准化为 [0, 1] 范围内的值。
预处理数据的两个选项
使用 data_augmentation 预处理器有两种方式:
方案 1: 让它成为模型的一部分,就像这样:
inputs = keras.Input(shape=input_shape)
x = data_augmentation(inputs)
x = layers.Rescaling(1./255)(x)
... # Rest of the model使用此选项,数据增强将在设备上进行,与模型执行的其他部分同步,这意味着它将受益于 GPU 加速。
请注意,数据增强在测试时处于非活动状态,因此输入样本只会在拟合(fit)时增强,而不会在调用评估(evaluate)或预测(predict)时增强。
如果使用 GPU 进行训练,这可能是一个不错的选择。
方案 2:将其应用于数据集,从而获得一个数据集,生成成批的增强图像,就像这样:
augmented_train_ds = train_ds.map(
lambda x, y: (data_augmentation(x, training=True), y))使用该选项,数据增强将在 CPU 上异步进行,并在进入模型前进行缓冲。
如果在 CPU 上进行训练,这是更好的选择,因为它能使数据增强异步且无阻塞。
在我们的例子中,我们会选择第二种方案。如果你不确定该选哪一个,那么第二个选项(异步预处理)始终是一个可靠的选择。
配置数据集以提高性能
让我们对训练数据集进行数据增强,并确保使用缓冲预取,这样我们就能从磁盘获取数据,而不会出现 I/O 阻塞:
# Apply `data_augmentation` to the training images.
train_ds = train_ds.map(
lambda img, label: (data_augmentation(img), label),
num_parallel_calls=tf_data.AUTOTUNE,
)
# Prefetching samples in GPU memory helps maximize GPU utilization.
train_ds = train_ds.prefetch(tf_data.AUTOTUNE)
val_ds = val_ds.prefetch(tf_data.AUTOTUNE)建立模型
我们将构建一个小版本的 Xception 网络。我们没有特别尝试优化架构;如果你想系统地搜索最佳模型配置,可以考虑使用 KerasTuner。
请注意
我们用 data_augmentation 预处理器启动模型,然后是 Rescaling 层。
我们在最终分类层之前加入了一个 Dropout 层。
def make_model(input_shape, num_classes):
inputs = keras.Input(shape=input_shape)
# Entry block
x = layers.Rescaling(1.0 / 255)(inputs)
x = layers.Conv2D(128, 3, strides=2, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
previous_block_activation = x # Set aside residual
for size in [256, 512, 728]:
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.MaxPooling2D(3, strides=2, padding="same")(x)
# Project residual
residual = layers.Conv2D(size, 1, strides=2, padding="same")(
previous_block_activation
)
x = layers.add([x, residual]) # Add back residual
previous_block_activation = x # Set aside next residual
x = layers.SeparableConv2D(1024, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.GlobalAveragePooling2D()(x)
if num_classes == 2:
units = 1
else:
units = num_classes
x = layers.Dropout(0.25)(x)
# We specify activation=None so as to return logits
outputs = layers.Dense(units, activation=None)(x)
return keras.Model(inputs, outputs)
model = make_model(input_shape=image_size + (3,), num_classes=2)
keras.utils.plot_model(model, show_shapes=True)演绎如下:

训练模型
epochs = 25
callbacks = [
keras.callbacks.ModelCheckpoint("save_at_{epoch}.keras"),
]
model.compile(
optimizer=keras.optimizers.Adam(3e-4),
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.BinaryAccuracy(name="acc")],
)
model.fit(
train_ds,
epochs=epochs,
callbacks=callbacks,
validation_data=val_ds,
)演绎如下:
epochs = 25
callbacks = [
keras.callbacks.ModelCheckpoint("save_at_{epoch}.keras"),
]
model.compile(
optimizer=keras.optimizers.Adam(3e-4),
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.BinaryAccuracy(name="acc")],
)
model.fit(
train_ds,
epochs=epochs,
callbacks=callbacks,
validation_data=val_ds,
)演绎如下:
Epoch 1/25
...
Epoch 25/25
147/147 ━━━━━━━━━━━━━━━━━━━━ 53s 354ms/step - acc: 0.9638 - loss: 0.0903 - val_acc: 0.9382 - val_loss: 0.1542
<keras.src.callbacks.history.History at 0x7f41003c24a0>过程:
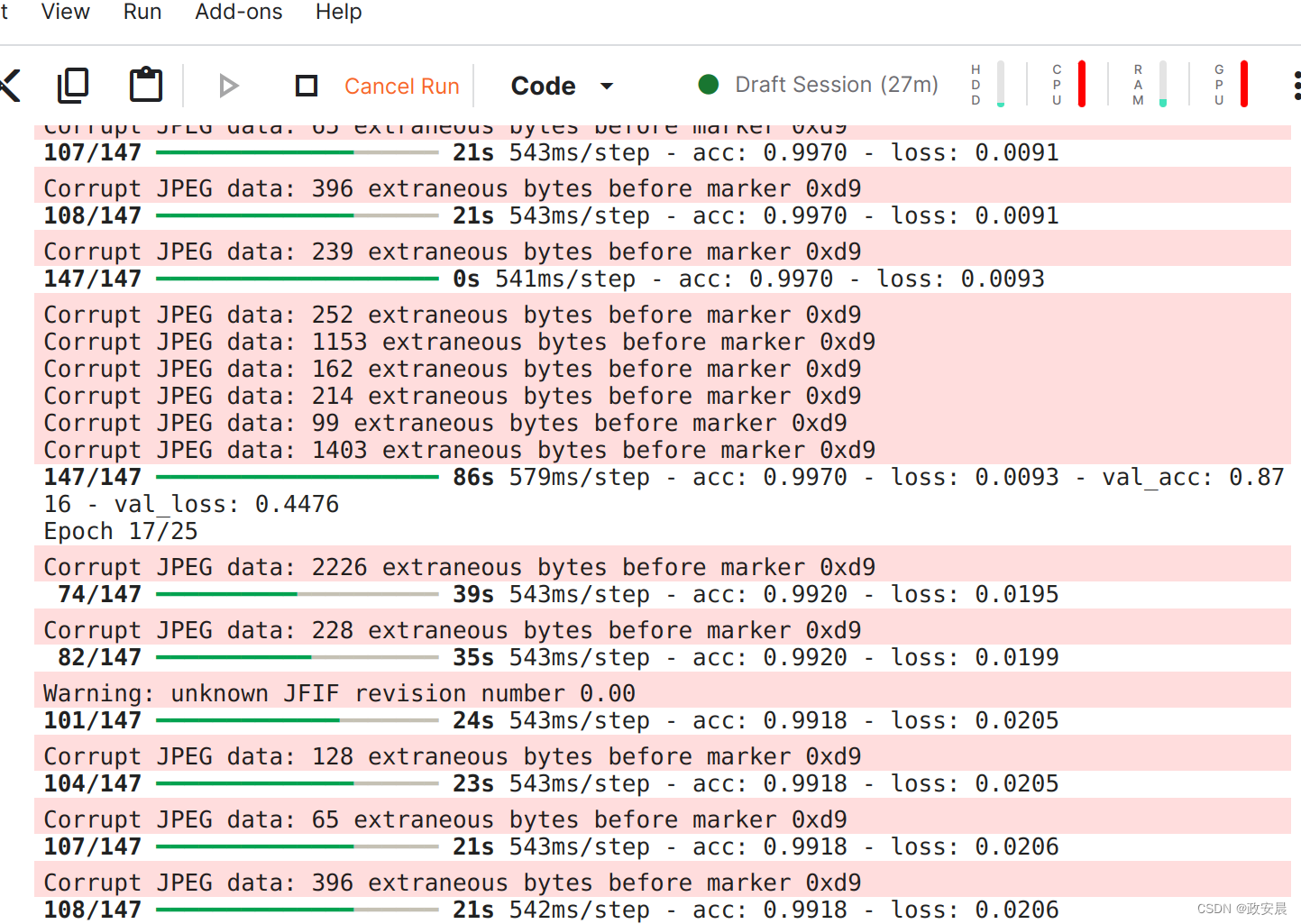
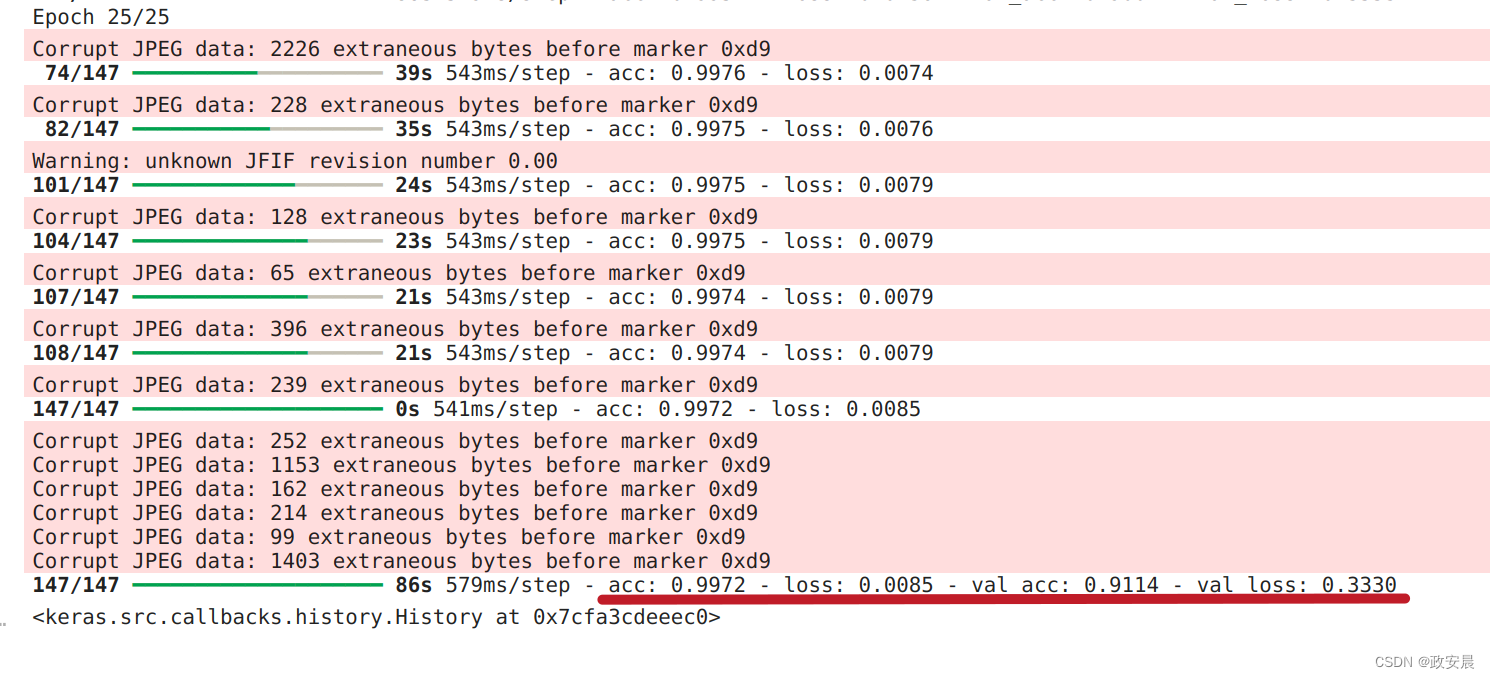
我们在完整数据集上训练了 25 个历元后,验证准确率达到了 90% 以上(实际上,在验证性能开始下降之前,可以训练 50 多个历元)。
对新数据进行推理
需要注意的是,在推理时,数据扩增和数据剔除都处于非活动状态。
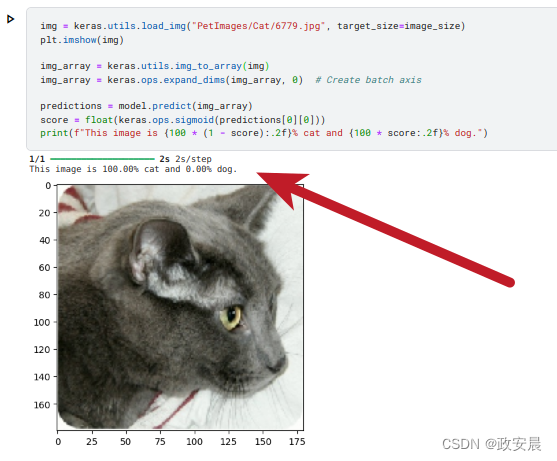
img = keras.utils.load_img("PetImages/Cat/6779.jpg", target_size=image_size)
plt.imshow(img)
img_array = keras.utils.img_to_array(img)
img_array = keras.ops.expand_dims(img_array, 0) # Create batch axis
predictions = model.predict(img_array)
score = float(keras.ops.sigmoid(predictions[0][0]))
print(f"This image is {100 * (1 - score):.2f}% cat and {100 * score:.2f}% dog.")实验如下: