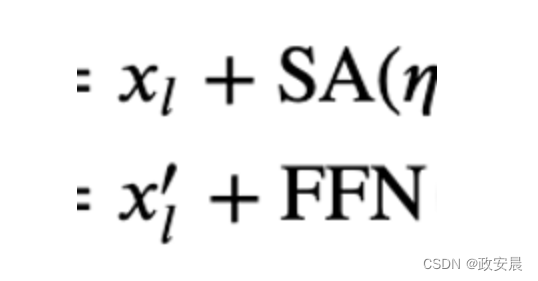目录
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras机器学习实战
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
本文目标:如何为深度神经网络的端到端学习训练可微分决策树。
导言
本示例提供了 P. Kontschieder 等人提出的用于结构化数据分类的深度神经决策林模型的实现。 它演示了如何建立一个随机可变的决策树模型,对其进行端到端训练,并将决策树与深度表示学习统一起来。
数据集
本示例使用加州大学欧文分校机器学习资料库提供的美国人口普查收入数据集。 该数据集包含 48,842 个实例,其中有 14 个输入特征(如年龄、工作级别、教育程度、职业等): 5 个数字特征和 9 个分类特征。
设置
import keras
from keras import layers
from keras.layers import StringLookup
from keras import ops
from tensorflow import data as tf_data
import numpy as np
import pandas as pd
import math准备数据
CSV_HEADER = [
"age",
"workclass",
"fnlwgt",
"education",
"education_num",
"marital_status",
"occupation",
"relationship",
"race",
"gender",
"capital_gain",
"capital_loss",
"hours_per_week",
"native_country",
"income_bracket",
]
train_data_url = (
"https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
)
train_data = pd.read_csv(train_data_url, header=None, names=CSV_HEADER)
test_data_url = (
"https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test"
)
test_data = pd.read_csv(test_data_url, header=None, names=CSV_HEADER)
print(f"Train dataset shape: {train_data.shape}")
print(f"Test dataset shape: {test_data.shape}")Train dataset shape: (32561, 15)
Test dataset shape: (16282, 15)删除第一条记录(因为它不是一个有效的数据示例)和类标签中的尾部 "点"。
test_data = test_data[1:]
test_data.income_bracket = test_data.income_bracket.apply(
lambda value: value.replace(".", "")
)我们将训练数据和测试数据分割成 CSV 文件存储在本地。
train_data_file = "train_data.csv"
test_data_file = "test_data.csv"
train_data.to_csv(train_data_file, index=False, header=False)
test_data.to_csv(test_data_file, index=False, header=False)定义数据集元数据
在此,我们定义了数据集的元数据,这些元数据将有助于读取、解析和编码输入特征。
# A list of the numerical feature names.
NUMERIC_FEATURE_NAMES = [
"age",
"education_num",
"capital_gain",
"capital_loss",
"hours_per_week",
]
# A dictionary of the categorical features and their vocabulary.
CATEGORICAL_FEATURES_WITH_VOCABULARY = {
"workclass": sorted(list(train_data["workclass"].unique())),
"education": sorted(list(train_data["education"].unique())),
"marital_status": sorted(list(train_data["marital_status"].unique())),
"occupation": sorted(list(train_data["occupation"].unique())),
"relationship": sorted(list(train_data["relationship"].unique())),
"race": sorted(list(train_data["race"].unique())),
"gender": sorted(list(train_data["gender"].unique())),
"native_country": sorted(list(train_data["native_country"].unique())),
}
# A list of the columns to ignore from the dataset.
IGNORE_COLUMN_NAMES = ["fnlwgt"]
# A list of the categorical feature names.
CATEGORICAL_FEATURE_NAMES = list(CATEGORICAL_FEATURES_WITH_VOCABULARY.keys())
# A list of all the input features.
FEATURE_NAMES = NUMERIC_FEATURE_NAMES + CATEGORICAL_FEATURE_NAMES
# A list of column default values for each feature.
COLUMN_DEFAULTS = [
[0.0] if feature_name in NUMERIC_FEATURE_NAMES + IGNORE_COLUMN_NAMES else ["NA"]
for feature_name in CSV_HEADER
]
# The name of the target feature.
TARGET_FEATURE_NAME = "income_bracket"
# A list of the labels of the target features.
TARGET_LABELS = [" <=50K", " >50K"]为训练和验证创建 tf_data.Dataset 对象
我们创建了一个输入函数来读取和解析文件,并将特征和标签转换为 tf_data.Dataset 用于训练和验证。 我们还通过将目标标签映射到索引对输入进行预处理。
target_label_lookup = StringLookup(
vocabulary=TARGET_LABELS, mask_token=None, num_oov_indices=0
)
lookup_dict = {}
for feature_name in CATEGORICAL_FEATURE_NAMES:
vocabulary = CATEGORICAL_FEATURES_WITH_VOCABULARY[feature_name]
# Create a lookup to convert a string values to an integer indices.
# Since we are not using a mask token, nor expecting any out of vocabulary
# (oov) token, we set mask_token to None and num_oov_indices to 0.
lookup = StringLookup(vocabulary=vocabulary, mask_token=None, num_oov_indices=0)
lookup_dict[feature_name] = lookup
def encode_categorical(batch_x, batch_y):
for feature_name in CATEGORICAL_FEATURE_NAMES:
batch_x[feature_name] = lookup_dict[feature_name](batch_x[feature_name])
return batch_x, batch_y
def get_dataset_from_csv(csv_file_path, shuffle=False, batch_size=128):
dataset = (
tf_data.experimental.make_csv_dataset(
csv_file_path,
batch_size=batch_size,
column_names=CSV_HEADER,
column_defaults=COLUMN_DEFAULTS,
label_name=TARGET_FEATURE_NAME,
num_epochs=1,
header=False,
na_value="?",
shuffle=shuffle,
)
.map(lambda features, target: (features, target_label_lookup(target)))
.map(encode_categorical)
)
return dataset.cache()
创建模型输入
def create_model_inputs():
inputs = {}
for feature_name in FEATURE_NAMES:
if feature_name in NUMERIC_FEATURE_NAMES:
inputs[feature_name] = layers.Input(
name=feature_name, shape=(), dtype="float32"
)
else:
inputs[feature_name] = layers.Input(
name=feature_name, shape=(), dtype="int32"
)
return inputs输入特征编码
def encode_inputs(inputs):
encoded_features = []
for feature_name in inputs:
if feature_name in CATEGORICAL_FEATURE_NAMES:
vocabulary = CATEGORICAL_FEATURES_WITH_VOCABULARY[feature_name]
# Create a lookup to convert a string values to an integer indices.
# Since we are not using a mask token, nor expecting any out of vocabulary
# (oov) token, we set mask_token to None and num_oov_indices to 0.
value_index = inputs[feature_name]
embedding_dims = int(math.sqrt(lookup.vocabulary_size()))
# Create an embedding layer with the specified dimensions.
embedding = layers.Embedding(
input_dim=lookup.vocabulary_size(), output_dim=embedding_dims
)
# Convert the index values to embedding representations.
encoded_feature = embedding(value_index)
else:
# Use the numerical features as-is.
encoded_feature = inputs[feature_name]
if inputs[feature_name].shape[-1] is None:
encoded_feature = keras.ops.expand_dims(encoded_feature, -1)
encoded_features.append(encoded_feature)
encoded_features = layers.concatenate(encoded_features)
return encoded_features深度神经决策树
神经决策树模型有两组权重需要学习。 第一组是 pi,代表树叶中类别的概率分布。 第二组是路由层 decision_fn 的权重,代表前往每个树叶的概率。 该模型的前向传递工作原理如下:
该模型希望将输入特征作为一个单一的向量,对批次中某个实例的所有特征进行编码。 该向量可以由应用于图像的卷积神经网络(CNN)生成,也可以由应用于结构化数据特征的密集变换生成。
模型首先应用已用特征掩码随机选择要使用的输入特征子集。
然后,模型通过在树的各个层级迭代执行随机路由,计算输入实例到达树叶的概率(mu)。
最后,将到达树叶的概率与树叶上的类概率相结合,生成最终输出。
class NeuralDecisionTree(keras.Model):
def __init__(self, depth, num_features, used_features_rate, num_classes):
super().__init__()
self.depth = depth
self.num_leaves = 2**depth
self.num_classes = num_classes
# Create a mask for the randomly selected features.
num_used_features = int(num_features * used_features_rate)
one_hot = np.eye(num_features)
sampled_feature_indices = np.random.choice(
np.arange(num_features), num_used_features, replace=False
)
self.used_features_mask = ops.convert_to_tensor(
one_hot[sampled_feature_indices], dtype="float32"
)
# Initialize the weights of the classes in leaves.
self.pi = self.add_weight(
initializer="random_normal",
shape=[self.num_leaves, self.num_classes],
dtype="float32",
trainable=True,
)
# Initialize the stochastic routing layer.
self.decision_fn = layers.Dense(
units=self.num_leaves, activation="sigmoid", name="decision"
)
def call(self, features):
batch_size = ops.shape(features)[0]
# Apply the feature mask to the input features.
features = ops.matmul(
features, ops.transpose(self.used_features_mask)
) # [batch_size, num_used_features]
# Compute the routing probabilities.
decisions = ops.expand_dims(
self.decision_fn(features), axis=2
) # [batch_size, num_leaves, 1]
# Concatenate the routing probabilities with their complements.
decisions = layers.concatenate(
[decisions, 1 - decisions], axis=2
) # [batch_size, num_leaves, 2]
mu = ops.ones([batch_size, 1, 1])
begin_idx = 1
end_idx = 2
# Traverse the tree in breadth-first order.
for level in range(self.depth):
mu = ops.reshape(mu, [batch_size, -1, 1]) # [batch_size, 2 ** level, 1]
mu = ops.tile(mu, (1, 1, 2)) # [batch_size, 2 ** level, 2]
level_decisions = decisions[
:, begin_idx:end_idx, :
] # [batch_size, 2 ** level, 2]
mu = mu * level_decisions # [batch_size, 2**level, 2]
begin_idx = end_idx
end_idx = begin_idx + 2 ** (level + 1)
mu = ops.reshape(mu, [batch_size, self.num_leaves]) # [batch_size, num_leaves]
probabilities = keras.activations.softmax(self.pi) # [num_leaves, num_classes]
outputs = ops.matmul(mu, probabilities) # [batch_size, num_classes]
return outputs深度神经决策森林
神经决策森林模型由一组同时训练的神经决策树组成。 森林模型的输出是各树的平均输出。
class NeuralDecisionForest(keras.Model):
def __init__(self, num_trees, depth, num_features, used_features_rate, num_classes):
super().__init__()
self.ensemble = []
# Initialize the ensemble by adding NeuralDecisionTree instances.
# Each tree will have its own randomly selected input features to use.
for _ in range(num_trees):
self.ensemble.append(
NeuralDecisionTree(depth, num_features, used_features_rate, num_classes)
)
def call(self, inputs):
# Initialize the outputs: a [batch_size, num_classes] matrix of zeros.
batch_size = ops.shape(inputs)[0]
outputs = ops.zeros([batch_size, num_classes])
# Aggregate the outputs of trees in the ensemble.
for tree in self.ensemble:
outputs += tree(inputs)
# Divide the outputs by the ensemble size to get the average.
outputs /= len(self.ensemble)
return outputs最后,让我们来设置训练和评估模型的代码。
learning_rate = 0.01
batch_size = 265
num_epochs = 10
def run_experiment(model):
model.compile(
optimizer=keras.optimizers.Adam(learning_rate=learning_rate),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
print("Start training the model...")
train_dataset = get_dataset_from_csv(
train_data_file, shuffle=True, batch_size=batch_size
)
model.fit(train_dataset, epochs=num_epochs)
print("Model training finished")
print("Evaluating the model on the test data...")
test_dataset = get_dataset_from_csv(test_data_file, batch_size=batch_size)
_, accuracy = model.evaluate(test_dataset)
print(f"Test accuracy: {round(accuracy * 100, 2)}%")实验 1:训练决策树模型
在本实验中,我们使用所有输入特征训练一个神经决策树模型。
num_trees = 10
depth = 10
used_features_rate = 1.0
num_classes = len(TARGET_LABELS)
def create_tree_model():
inputs = create_model_inputs()
features = encode_inputs(inputs)
features = layers.BatchNormalization()(features)
num_features = features.shape[1]
tree = NeuralDecisionTree(depth, num_features, used_features_rate, num_classes)
outputs = tree(features)
model = keras.Model(inputs=inputs, outputs=outputs)
return model
tree_model = create_tree_model()
run_experiment(tree_model)Start training the model...
Epoch 1/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 5s 26ms/step - loss: 0.5308 - sparse_categorical_accuracy: 0.8150
Epoch 2/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - loss: 0.3476 - sparse_categorical_accuracy: 0.8429
Epoch 3/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - loss: 0.3312 - sparse_categorical_accuracy: 0.8478
Epoch 4/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - loss: 0.3247 - sparse_categorical_accuracy: 0.8495
Epoch 5/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.3202 - sparse_categorical_accuracy: 0.8512
Epoch 6/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - loss: 0.3158 - sparse_categorical_accuracy: 0.8536
Epoch 7/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - loss: 0.3116 - sparse_categorical_accuracy: 0.8572
Epoch 8/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - loss: 0.3071 - sparse_categorical_accuracy: 0.8608
Epoch 9/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - loss: 0.3026 - sparse_categorical_accuracy: 0.8630
Epoch 10/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.2975 - sparse_categorical_accuracy: 0.8653
Model training finished
Evaluating the model on the test data...
62/62 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - loss: 0.3279 - sparse_categorical_accuracy: 0.8463
Test accuracy: 85.08%实验 2:训练森林模型
在本实验中,我们使用 num_trees 树训练神经决策森林,每棵树随机使用 50%的输入特征。 通过设置 used_features_rate 变量,可以控制每棵树使用的特征数量。 此外,与之前的实验相比,我们将深度设置为 5,而不是 10。
num_trees = 25
depth = 5
used_features_rate = 0.5
def create_forest_model():
inputs = create_model_inputs()
features = encode_inputs(inputs)
features = layers.BatchNormalization()(features)
num_features = features.shape[1]
forest_model = NeuralDecisionForest(
num_trees, depth, num_features, used_features_rate, num_classes
)
outputs = forest_model(features)
model = keras.Model(inputs=inputs, outputs=outputs)
return model
forest_model = create_forest_model()
run_experiment(forest_model)Start training the model...
Epoch 1/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 47s 202ms/step - loss: 0.5469 - sparse_categorical_accuracy: 0.7915
Epoch 2/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.3459 - sparse_categorical_accuracy: 0.8494
Epoch 3/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.3268 - sparse_categorical_accuracy: 0.8523
Epoch 4/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.3195 - sparse_categorical_accuracy: 0.8524
Epoch 5/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.3149 - sparse_categorical_accuracy: 0.8539
Epoch 6/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.3112 - sparse_categorical_accuracy: 0.8556
Epoch 7/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.3079 - sparse_categorical_accuracy: 0.8566
Epoch 8/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - loss: 0.3050 - sparse_categorical_accuracy: 0.8582
Epoch 9/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - loss: 0.3021 - sparse_categorical_accuracy: 0.8595
Epoch 10/10
123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - loss: 0.2992 - sparse_categorical_accuracy: 0.8617
Model training finished
Evaluating the model on the test data...
62/62 ━━━━━━━━━━━━━━━━━━━━ 5s 39ms/step - loss: 0.3145 - sparse_categorical_accuracy: 0.8503
Test accuracy: 85.55%