一、urllib库
1、概述
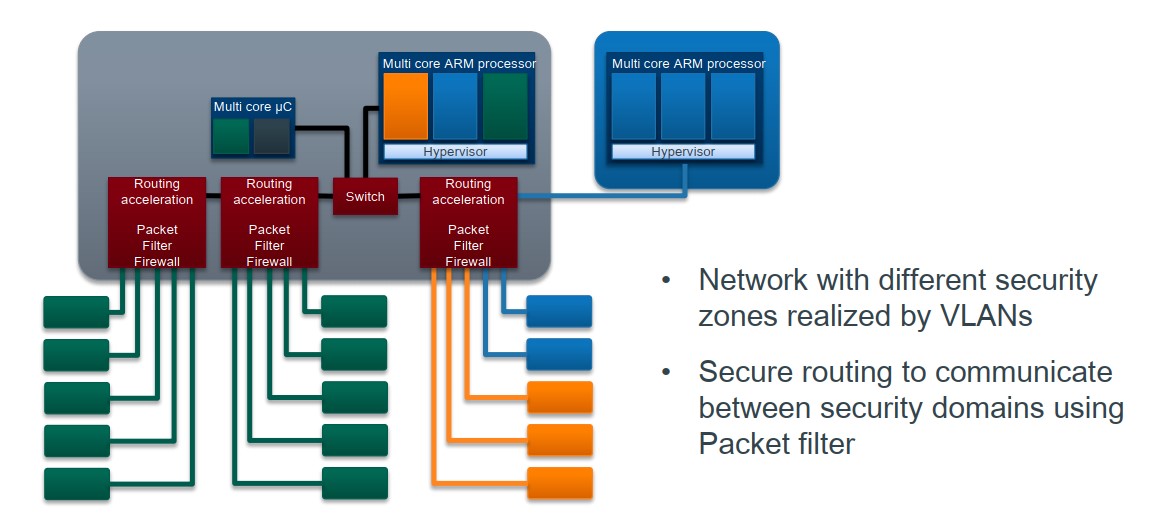
urllib库的核心功能是:向服务器发送请求,得到服务器响应,获取网页的内容。urllib库是Python3.X内置的HTTP请求库。urllib库提供了四大模块,如图1-1所示。
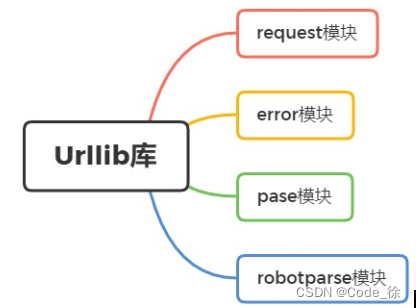
图1-1 urllib库结构
Ø requset:HTTP请求模块,可以用来模拟发送请求,只需要传入URL及额外参数,就可以模拟浏览器访问网页的过程。
Ø error:异常处理模块,检测请求是否报错,捕捉异常错误,进行重试或其他操作,保证程序不会终止。
Ø parse:工具模块,提供许多URL处理方法,如拆分、解析、合并等。
Ø robotparser:识别网站的robots.txt文件,判断哪些网站可以爬,哪些网站不可以爬,使用频率较少。
2、常用方法介绍
(1)urllib.request.urlopen()函数
创建一个标识远程url的文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据。语法如下:
urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT, *,
cafile=None, capath=None, cadefault=False, context=None)
Ø 参数描述
名称 |
描述 |
url |
URL地址,即为要抓取网页的地址,如:http://www.baidu.com/; |
data |
data用来指明发往服务器请求中的额外信息。data默认是None,表示此时以GET方式发送请求;当用户给出data参数的时候,表示为POST方式发送请求; |
timeout |
在某些网络情况不好或者服务器端异常的情况会出现请求慢的情况,或者请求异常,这时给timeout参数设置一个请求超时时间,而不是让程序一直在等待结果; |
cafile、capath、cadefault |
用于实现可信任的CA证书的HTTP请求; |
context |
实现SSL加密传输。 |
返回值:http.client.HTTPResponse对象 |
|
http.client.HTTPResponse对象提供的常用方法如下: v read()、readline()、readlines()、fileno()、close():对HTTP Response类型数据进行操作; v info():返回HTTPMessage对象,表示远程服务器返回的头信息; v getcode():返回HTTP状态码 v geturl():返回请求的url; v getheaders():响应的头部信息; v getheader('Server'):返回响应头指定参数Server的值; v status:返回状态码; v reason:返回状态的详细信息。 |
(2)urllib.request.urlretrieve()函数
函数urlretrieve()将远程数据下载到本地。语法如下:
urllib.request. urlretrieve(url, filename=None, reporthook=None, data=None)
Ø 参数描述
名称 |
描述 |
url |
远程数据的地址。 |
filename |
保存文件的路径,如果为空,则下载为临时文件。 |
reporthook |
钩子函数连接服务器成功以及每个数据块下载完成时各调用一次,包含3个参数,依次为已经下载的数据块,数据块的大小,总文件的大小,可用于显示下载进度。 |
data |
post到服务器的数据。 |
使用示例: def Schedule(a, b, c): """a:已经下载的数据块 b:数据块的大小 c:远程文件的大小 """ per = 100.0*float(a*b)/float(c) if per > 100: per = 100 print("a", a) print("b", b) print("c", c) print('{:.2f}%'.format(per)) url = 'https://xxx.cmg.cn/' local ='mylogo.png' filename, _= urllib.request.urlretrieve(url,local,Schedule) # ('mylogo.png', <http.client.HTTPMessage object at 0x000001FD6491D6D8>) print(filename) # mylogo.png |
|
(3)decode()函数
decode()方法以指定的编码格式解码bytes对象,并返回解码后的字符串。语法格式为:
bytes.decode(encoding=“utf-8”,errors=“strict”)
Ø 参数描述
名称 |
描述 |
encoding |
要使用的编码,如“UTF-8”,“gbk”,默认编码为“UTF-8” |
errors |
设置不同错误的处理方案。默认为“strict”,意为编码错误引起一个UnicodeError,其它可能的值有“ignore”,“replace”,“xmlcharrefreplace”,“backslashreplace” |
(4)urllib.parse.urlencode()函数
把字典或序列数据转换为URL字符串。语法如下:
urllib.parse.urlencode(query, doseq=False, safe='', encoding=None,
errors=None, quote_via=quote_plus)
Ø 参数描述
名称 |
描述 |
query |
待转换的参数对象 |
doseq |
序列元素是否单独转换 |
safe |
安全默认值 |
encoding |
编码 |
errors |
错误默认值 |
(5)urllib.parse模块的常用函数表
【urlparse, urlunparse, urljoin, urldefrag, urlsplit, urlunsplit, urlencode, parse_qs,
parse_qsl, quote, quote_plus, quote_from_bytes, unquote, unquote_plus, unquote_to_bytes】
(6)常见的各种状态码含义
200:请求正常,服务器正常的返回数据;
301:永久重定向。比如在访问www.jingdong.com的时候会重定向到www.jd.com;
302:临时重定向。比如在访问一个需要登录的页面的时候,而此时没有登录,那么就会重定向到登录页面;
400:请求的url在服务器上找不到。换句话说就是请求url错误;
403:服务器拒绝访问,权限不够;
500:服务器内部错误。可能是服务器出现bug了。
3、使用基础
(1)发送请求
import urllib.request
r = urllib.request.urlopen("http://www.python.org/")
(2)读取响应内容
import urllib.request
url = “http://www.python.org/"
with urllib.request.urlopen(url) as r:
r.read()
(3)传递URL参数
import urllib.request
import urllib.parse
params = urllib.parse.urlencode({'q': 'urllib', 'check_keywords': 'yes', 'area': 'default'})
url = "HTTPS://docs.python.org/3/search.html?{}".format(params)
r = urllib.request.urlopen(url)
(4)传递中文参数
import urllib.request
searchword = urllib.parse.quote(input("请输入要查询的关键字:"))
url ="https://cn.bing.com/images/async?q={}&first=0&mmasync=1".format(searchword)
r = urllib.request.urlopen(url)
(5)传递POST请求
import urllib.request
import urllib.parse
base_url="你的请求网址"
# 你请求网址的参数
data={
"name":"www.lidihuo.com",
"pass":"xxxx"
}
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE"}
postdata=urllib.parse.urlencode(data).encode('utf-8')
req=urllib.request.Request(url=base_url,headers=headers,data=postdata,method='POST')
response=urllib.request.urlopen(req)
html=response.read()
# html=response.read().decode('utf-8') # decode()是把bytes转化解码为str
print(html)
(6)传递GET请求
from urllib import parse, request
import random
url = 'https://www.lidihuo.com/python/spider-test.html'
keyvalue = 'url参数'
encoded_wd = parse.urlencode(wd)
new_url = url + '?' + encoded_wd
req = request.Request(url)
# 为了防止被网站封ip,模仿浏览器访问网站
ua_list = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"
]
# 在User-Agent列表里随机选择一个User-Agent ;从序列中随机选取一个元素
user_agent = random.choice(ua_list)
req.add_header('User-Agent', user_agent)
response = request.urlopen(req)
print(response.read().decode('utf-8'))
(7)下载远程数据到本地
import urllib.request
url = “https://www.python.org/static/img/python-logo.png"
urllib.request.urlretrieve(url, "python-logo.png")
(8)Cookie的使用
import urllib.request
import HTTP.cookiejar
url = “http://www.w3school.com.cn/"
cjar = HTTP.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cjar))
urllib.request.install_opener(opener)
r = urllib.request.urlopen(url)
(9)设置Headers
浏览器header部分的信息:
Ø User-Agent:有些服务器或Proxy会通过该值来判断是否是浏览器发出的请求。
Ø Content-Type:在使用REST接口时,服务器会检查该值,用来确定HTTP Body中的内容该怎样解析。
Ø application/xml:在XML RPC,如RESTful/SOAP调用时使用。
Ø application/json:在JSON RPC调用时使用。
Ø application/x-www-form-urlencoded:浏览器提交Web表单时使用。
其中,agent就是请求的身份,user-agent能够使服务器识别出用户的操作系统及版本、cpu类型、浏览器类型和版本。很多网站会设置user-agent白名单,只有在白名单范围内的请求才能正常访问。所以在我们的爬虫代码中需要设置user-agent伪装成一个浏览器请求。有时候服务器还可能会校验Referer,所以还可能需要设置Referer(用来表示此时的请求是从哪个页面链接过来的)。示例代码如下:
# 伪装浏览器的爬虫
from urllib import request
import re
import ssl
url="https://www.lidihuo.com/python/spider-test.html"
# 导入ssl时关闭证书验证
ssl._create_default_https_context = ssl._create_unverified_context
# 构造请求头信息
header={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
req=request.Request(url,headers=header)
# 发送请求.获取响应信息
reponse=request.urlopen(req).read().decode() #解码---(编码encode())
pat=r""
data=re.findall(pat,reponse)
#由于data返回的是列表形式的数据用data[0]直接取值
print(data[0])
(10)Proxy(代理)的设置
动态设置代理,就是事先准备一堆User-Agent.每次发送请求时就从中间随机选取一个,采用random随机模块的choice方法随机选择User-Agent,这样每次请求都会从中选择,请求很频繁的话就多找几个user-agent,具体如下:
def load_page(url, form_data):
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
user_agent = random.choice(USER_AGENTS)
headers = {
'User-Agent':user_agent
}
二、Request库
1、概述
Requests库号称是最好用的,同时也是使用最多的Python HTTP库。Requests库由Python的urllib3封装而成,但比urllib3提供了更友好的接口调用体验。Requests库可发送原生的HTTP/1.1请求,无须手动为URL添加查询字符串,也不需要对POST数据进行表单编码。相对于urllib3,Requests库拥有完全自动化的Keep-Alive和HTTP连接池的功能。主要特性如下:
v Keep-Alive & 连接池
v 国际化域名和URL
v 带持久Cookie的会话
v 浏览器方式的SSL认证
v 自动内容解码
v 基本/摘要式的身份认证
v 优雅的Key/Value Cookie
v 自动解压
v Unicode响应体
v HTTP(S) 代理支持
v 文件分块上传
v 流下载
v 连接超时
v 分块请求
v 支持.netrc
2、安装
pip install requests
3、基本使用
(1)Make a Request
v importing the Requests module:
import requests
v try to get a webpage
r = requests.get(‘https://api.github.com/’)
§——使用get方法,获取网络资源时,有一个基本流程:
第一步 发送get请求,获取HTTP返回的Response对象r
第二步 使用r.status_code,检测返回的状态,如果r.status_code=200,则可以获取HTTP响应的数据;否则,则检测请求出错原因。
§——爬取网页的通用代码框架:
import requests
url = ‘https://api.github.com/’
try:
r = requests.get(url,timeout=30)
r.raise_for_status() # 状态码不是200,则引发HTTPError异常
r.encoding = r.apparent_encoding
print(r.text)
except:
print(‘产生异常’)
v try to make an HTTP POST request
r = request.post(‘https://httpbin.org/post’,data={‘key’:’value’})
(2)Passing Parameters In URLs
You often want to send some sort of data in the URL’s query string. for example:
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get('https://httpbin.org/get', params=payload)
print(r.url) #https://httpbin.org/get?key2=value2&key1=value1
(3)Response Content
We can read the content of the server’s response. for example:
r = requests.get('https://api.github.com/events')
print(r.text) # '[{"repository":{"open_issues":0,"url":"https://github.com/...
Hints: If you change the encoding, Requests will use the new value of r.encoding whenever you call r.text.
(4)Binary Response Content
You can also access the response body as bytes, for non-text requests:
print(r.content) # b'[{"repository":{"open_issues":0,"url":"https://github.com/...
Hints : The gzip and deflate transfer-encodings are automatically decoded for you.
(5)JSON Response Content
There’s also a builtin JSON decoder, in case you’re dealing with JSON data:
r = requests.get('https://api.github.com/events')
print(r.json()) # [{'repository': {'open_issues': 0, 'url': 'https://github.com/...
(6)Raw Response Content
In the rare case that you’d like to get the raw socket response from the server, you can access r.raw. If you want to do this, make sure you set stream=True in your initial request.
(7)Custom Headers
If you’d like to add HTTP headers to a request, simply pass in a dict to the headers parameter. for example:
url = 'https://api.github.com/some/endpoint'
headers = {'user-agent': 'my-app/0.0.1'}
r = requests.get(url, headers=headers)
Note: Custom headers are given less precedence than specific sources of information. Furthermore, Requests does not change its behavior at all based on which custom headers are specified. The headers are simply passed on into the final request.
(8)More complicated POST requests
Typically, you want to send some form-encoded data, much like an HTML form. To do this,simply pass a dictionary to the data argument. Your dictionary of data will automatically be form-encoded when the request is made:
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.post("https://httpbin.org/post", data=payload)
print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
Note: 参数还可以是列表,JSON格式数据等。
(9)POST a Multipart-Encoded File
Requests makes it simple to upload Multipart-encoded files. for example:
url = 'https://httpbin.org/post'
files = {'file': open('report.xls', 'rb')}
r = requests.post(url, files=files)
r.text
{
...
"files": {
"file": "<censored...binary...data>"
},
...
}
You can set the filename, content_type and headers explicity,for example:
url = 'https://httpbin.org/post'
files = {'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})}
r = requests.post(url, files=files)
r.text
(10)Response Status Codes
You can check the response status code, for example:
r = requests.get('https://httpbin.org/get')
print(r.status_code) # 200
(11)Response Headers
print(r.headers)
(12)Cookies
If a response contains some Cookies, you can quickly access them:
url = 'http://example.com/some/cookie/setting/url'
r = requests.get(url)
r.cookies['example_cookie_name'] # 'example_cookie_value'
4、高级使用
(1)Session Objects
The Session object allows you to persist certain parameters across requests. It also persists cookies across all requests made from the Session instance, and will use urllib3’s connection polling.
A Session object has all the methods of the main Requests API.
Let’s persist some cookies across requests, for example:
s = requests.Session()
s.get('https://httpbin.org/cookies/set/sessioncookie/123456789')
r = s.get('https://httpbin.org/cookies')
print(r.text)
Sessions can also be used to provide default data to the request methods. This is done by providing data to the properties on a Session object,for example:
s = requests.Session()
s.auth = ('user', 'pass')
s.headers.update({'x-test': 'true'})
# both 'x-test' and 'x-test2' are sent
s.get('https://httpbin.org/headers', headers={'x-test2': 'true'})
(2)Request and Response Objects
Whenever a call is made to requests.get() and friends, you are doing two major things. First,you are constructing a Request object which will be sent off to a seerver to request or query some resource. Second, a Response object is generated once Requests gets a response back from the server. The Response object contains all of the information returned by the server and also contains the Requests object you created originally.
r = requests.get('https://en.wikipedia.org/wiki/Monty_Python')
If we want to access the headers the server sent back to us, we do this:
print(r.headers)
(3)Prepared Requests
Whenever you receive a Response object from an API call or a Session call, the request attribute is actually the PreparedRequest that was used. In some cases you may wish to do some extra work to the body or headers before sending a request. for example:
from requests import Request, Session
s = Session()
req = Request('POST', url, data=data, headers=headers)
prepped = req.prepare()
# do something with prepped.body
prepped.body = 'No, I want exactly this as the body.'
# do something with prepped.headers
del prepped.headers['Content-Type']
resp = s.send(prepped,
stream=stream,
verify=verify,
proxies=proxies,
cert=cert,
timeout=timeout
)
print(resp.status_code)
5、API参考
【https://docs.python-requests.org/en/latest/api/】
(1)主接口
所有请求功能都可以通过7个函数实现,这7个函数都返回Response对象实例,如表5-1所示。
表5-1 七个请求函数
名称 |
描述 |
requests.request(method,url,**kwargs) |
构造并发送一个请求。总共15个参数: Ø method:请求方式,GET,OPTIONS,HEAD, POST,PUT,PATCH,和DELETE七种。 Ø url:一个请求的url Ø params:[字典,元组型列表,字节]在url上传递的参数 Ø data:[字典,元组型列表,字节] 在请求体中传递的参数 Øjson:[序列化的python对象]json格式数据,在请求体传递 Ø headers:[字典] 定制http请求头 Ø cookies:[字典或CookJar对象]请求中的cookies信息 Ø files:[字典]上传的文件列表 Ø auth:[元组]支持HTTP认证功能 Ø timeout:[float/元组]超时时间,单位:秒 Ø allow_redirects:[True(默认)/False]允许/禁止重定向 Ø proxies:[字典]设置访问的代理服务器 Ø verify :[True(默认)/False],认证SSL证书开关 Ø stream:[True(默认)/False], 获取内容立即下载开关 Ø cert:本地SSL证书路径 |
requests.get(url,params=None,**kwargs) |
构造一个向服务器请求资源的Request对象,请求方式:GET,并返回一个包含服务器资源的Response对象。 参数:url:拟获取页面的url的链接; params:url中的额外参数,字典或字节流格式[可选] **kwargs:12个控制访问的参数,与request方法一致。 |
requests.head(url,**kwargs) |
Sends a HEAD request |
request.post(url,data=None,json=None,**kwargs) |
Sends a POST request |
request.put(url,data=None,**kwargs) |
Sends a PUT request |
request.patch(url,data=None,**kwargs) |
Sends a PATCH request |
request.delete(url,**kwargs) |
Sends a DELETE request |
(2)Request Sessions
一个请求会话对象,提供了持久化cookie、连接查询和配置等功能。常用功能列表如5-2所示。
表5-2 Request Sessions属性和函数
名称 |
描述 |
auth=None |
[元组或对象] 请求授权信息 |
cert=None |
SSL客户验证,“字符串”则是客户的.pem文件,若为元组,则(cert,key)对 |
close() |
关闭所有适配器与会话 |
cookies=None |
|
delete(url,**kwargs) |
发送DELETE请求,返回Response对象 |
get(url,**kwargs) |
发送GET请求,返回Response对象 |
get_adapter(url) |
[BaseApapter]返回指定连接(url)的适配器对象 |
get_redirect_target(resp) |
接收响应,返回一个重定位的URI或None |
head(url,**kwargs) |
发送HEAD请求 |
headers=None |
A case-insensitive dictionary of headers to be sent on each Request sent from the session |
hooks=None |
Event-handling hooks |
max_redirests=None |
允许重定向的最大数量 |
merge_environment_settings() |
检测环境并用给定的参数设置环境对象 |
mount(prefix,adapter) |
registers a connection a adapter to a prefix |
options(url,**kwargs) |
Sends a OPTIONS request. Returns Response object |
params = None |
[dict]请求的参数 |
patch(url,data=None,**kwargs) |
发送PATCH请求,返回Response对象 |
post(url,data=None,...) |
发送POST请求,返回Response对象 |
prepare_request(request) |
实例化一个PrepareRequest对象 |
request(method,url,...) |
实例化一个Request对象,并发送请求,返回Response对象 |
send(request,**kwargs) |
Send a given PreparedRequest,返回Response对象 |
stream=None |
【Stream response content】 |
(3)Lower-Level Classes
class requests.Request(method=None, url=None, headers=None, files=None,
data=None, params=None, auth=None, cookies=None, hooks=None, json=None)
该类标识一个用户自定义的Request对象。
- class requests.Response(object)
一个Response对象,该对象包含了HTTP请求的服务器响应信息,如表5-3所示。
表5-3 Response对象属性和函数
名称 |
描述 |
apparent_encoding |
The apparent encoding, provided by the chardet library(从内容中分析出来的响应内容编码方式【备选编码方式,编码方式更准确】)。 |
close() |
关闭连接,并将连接释放到连接池 |
content |
HTTP响应内容的二进制形式。 |
cookies=None |
A CookieJar of Cookies the server sent back |
elapsed = None |
从发送请求到收到响应已经消耗的时间 |
encoding=None |
Encoding to decode with when accessing r.text(即:从HTTP header中猜测的响应内容的编码形式,即:从header的charset字段获取。若header中不存在charset,则认为编码为ISO-8859-1) |
headers = None |
[dict]响应头部信息 |
history = None |
[list]A list of Response objects from the history of the Request |
is_redirect |
|
iter_content(..) |
Iterates over the response data |
iter_lines |
Iterates over the response data, one line at a time. |
json(**kwargs) |
Returns the json-encoded content of a response. |
links |
Returns the parsed header links of the response |
next |
Returns a PrepareRequest for the next request in a redirect chain |
ok |
Returns True if status_code less than 400, False if not |
raise_for status() |
Raises HTTPError, if one occurred(即:若不是200,产生HTTPError异常) |
raw = None |
File-like object representation of reaponse |
reason = None |
Textual reason of responded HTTP status |
request = None |
The PreparedRequest object to which this a response |
status_code=None |
HTTP请求的返回状态码,200——成功 |
text |
HTTP响应内容的字符串形式,即:url对应的页面内容 |
url = None |
Final URL location of Response. |
class requests.PreparedRequest
The fully mutable PreparedRequest object, containing the exact bytes that will be sent to the server.
Instances are generated from a Request object, and should not be instantiated manually; doing so may produce undesirable effects.
表5-4 PreparedRequest对象属性和函数
名称 |
描述 |
body = None |
request body to send to the server |
deregister_hook(event,hook) |
[bool] Deregister a previously registered hook. =True: the hook existed |
headers = None |
dictionary of HTTP headers |
hooks = None |
dictionary of callback hooks, for internal usage. |
method = None |
HTTP verb to send to the server |
path_url |
Build the path URL to use |
prepare(method=None,url=None,...) |
Prepares the entire request with the given parameters |
prepare_auth(auth,url=’’) |
Prepares the given HTTP auth data |
prepare_body(data,files,json=None) |
Prepares the given HTTP body data |
prepare_content_length(body) |
Prepare Content-Length header based on request method and body |
prepare_cookies(cookies) |
Prepares the given HTTP cookie data |
prepare_headers(headers) |
Prepares the given HTTP headers |
prepare_hooks(hooks) |
Prepares the given hooks |
prepare_method(method) |
Prepares the HTTP method |
prepare_url(url,params) |
Prepares the given HTTP URL |
register_hook(event,hook) |
Properly register a hook |
url = None |
HTTP URL to send the request to |
Ø class requests.adapters.BaseAdapter
The Base Transport Adapter (基本传输适配器)
表5-5 BaseAdapter对象属性和函数
名称 |
描述 |
close() |
Cleans up adapter specific items. |
send(request,stream=False,...) |
Sends PreparedRequest object. Return Response object |
send(request,stream=False,timeout=None,verify=True,cert=None,proxies=None) v request : The PreparedRequest being sent v stream : whether to stream the request content. v timeout : (float/tuple) how long to wait the server to send data before giving up, as a float, or a tuple(连接,读取) v verify : (1)boolean--TLS certificate,(2)string -- it must be a path to a CA bundle to use v cert : Any user-provided SSL certificate to be trusted v proxies -- The proxies dictionary to apply to the request |
|
class requests.adapters.HTTPAdapter(pool_connections=10, pool_maxsize=10,
max_retries=0, pool_block=False)
The built-in HTTP Adapter for urllib3.
Provides a general-case interface for Requests sessions to contact HTTP and HTTPS urls by implementing the Transport Adapter interface. This class will usually be created by the Session class under the covers.
表5-6 HTTPAdapter参数描述、属性与方法
名称 |
描述 |
参数列表 |
|
pool_connections |
The number of urllibs connection pools to cache |
pool_maxsize |
The maximum number of connections to save in the pool |
max_retries |
The maximum number of retries each connection should attempt |
pool_block |
Whether the connection pool should block for connections |
属性和方法 |
|
add_headers(request,**kwargs) |
Add any headers needed by the connection |
build_response(req,resp) |
Builds a Response object from a urllib3 response.This should not be called from user code |
cert_verify(conn,url,verify,cert) |
Verify a SSL certificate. |
close() |
Disposes of any internal state. |
get_connection(url,proxies=None) |
Returns a urllibs connection for the given URL. |
init_poolmanager(connections,...) |
Initializes a urllibs PoolManager |
proxy_headers(proxy) |
Returns a dictionary of the headers to add to any request sent through a proxy |
proxy_manager_for(proxy,...) |
Return urllibs ProxyManager for the given proxy. |
request_url(request,proxies) |
Obtain the url to use when making the final request |
send(request,stream=False,...) |
Sends PreparedRequest object. Returns Response object. |
(4)Encodings
表5-7 Encoding方法
名称 |
描述 |
request.utils.get_encodings_from_content(content) |
Returns encodings from given content string |
request.utils.get_encoding_from_headers(headers) |
Returns encodings from given HTTP Header Dict |
requests.utils.get_unicode_from_response(r) |
Returns the requested content back in unicode |





























![[羊城杯 2020]EasySer ---不会编程的崽](https://img-blog.csdnimg.cn/direct/cf137ad8f2c1469cba18f3d2a52f4bca.png)