通过5个条件判定一件事情是否会发生,5个条件对这件事情是否发生的影响力不同,计算每个条件对这件事情发生的影响力多大,写一个循环神经网络模型pytorch程序,最后打印5个条件分别的影响力。
示例
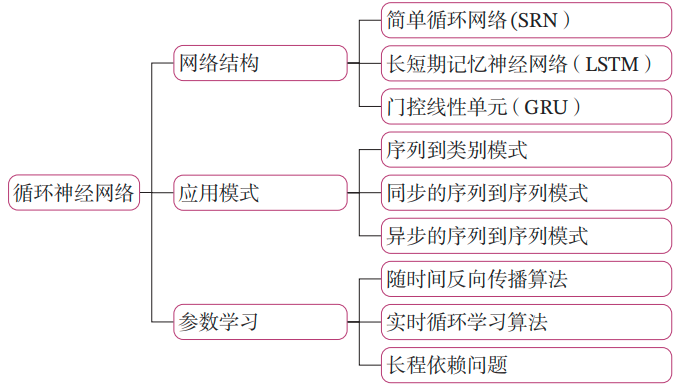
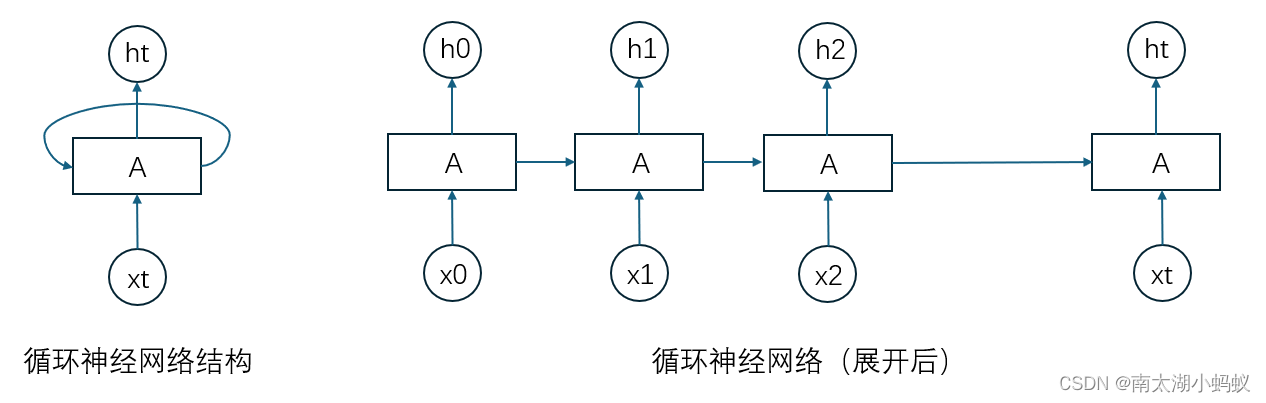
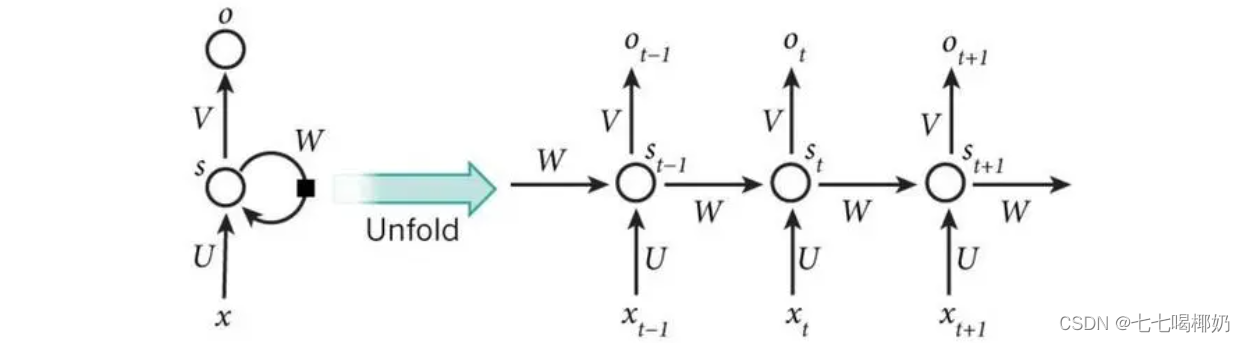
在这个场景中,我们想要使用循环神经网络(RNN)来评估五个条件对某一事件发生的影响力。RNN 适用于处理序列数据, 并且可以通过其隐藏状态来捕获序列中的信息。然而,标准的 RNN 可能不是直接解释每个输入条件影响力的最佳模型,因为 RNN 的隐藏状态是累积的,并且通常难以直接映射回特定的输入。
并且可以通过其隐藏状态来捕获序列中的信息。然而,标准的 RNN 可能不是直接解释每个输入条件影响力的最佳模型,因为 RNN 的隐藏状态是累积的,并且通常难以直接映射回特定的输入。
尽管如此,我们可以尝试使用一种简单的 RNN 结构,并通过观察隐藏状态的变化来近似地推断每个条件的影响力。更好的选择可能是使用长短期记忆(LSTM)或门控循环单元(GRU),因为它们具有更复杂的门控机制,可以更好地保留和传递信息。
以下是一个使用 PyTorch 实现的简单 RNN 模型的示例代码,该代码试图展示如何构建模型并输出隐藏状态,这些隐藏状态可以粗略地解释为条件的影响力。但是请注意,这种解释在严格的意义上可能是不准确的,因为 RNN 的内部状态并不直接对应于单个输入的影响力。
import torch
import torch.nn as nn
# 假设每个条件是一个特征向量
input_size = 10 # 每个条件的特征维度
hidden_size = 20 # 隐藏层大小
num_layers = 1 # RNN层数
num_conditions = 5 # 条件数量
# 构建RNN模型
class ConditionInfluenceRNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers):
super(ConditionInfluenceRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, 1) # 输出层
def forward(self, conditions):
# 初始化隐藏状态
h0 = torch.zeros(num_layers, conditions.size(0), hidden_size).to(conditions.device)
# 通过RNN
out, hidden = self.rnn(conditions, h0)
# 取最后一个隐藏状态,或者你可以平均所有隐藏状态
# 这里我们假设最后一个隐藏状态包含了所有条件的信息
influence = hidden.squeeze(0)
# 预测(这里只是为了完整性,实际上我们更关心隐藏状态)
prediction = self.fc(influence)
return prediction, influence
# 实例化模型
model = ConditionInfluenceRNN(input_size, hidden_size, num_layers)
# 假设我们有5个条件,每个条件是一个10维的特征向量
conditions = torch.randn((1, num_conditions, input_size)) # (batch_size, seq_len, input_size)
# 前向传播
prediction, influence = model(conditions)
# 打印影响力(这里的影响力实际上是RNN的最后一个隐藏状态)
for i, infl in enumerate(influence.squeeze(0)):
print(f"Condition {i + 1} influence (approx.): {infl.item()}")
# 注意:这里的“影响力”只是一个示例,并不代表真实的条件影响力。
# 在实际应用中,你可能需要设计更复杂的模型或方法来准确地量化每个条件的影响力。
在这个例子中,我们构建了一个简单的 RNN,并且试图通过输出隐藏状态来近似每个条件的影响 力。然而,这种方法的问题在于 RNN 的隐藏状态是序列中所有先前条件的累积结果,因此它并不能直接反映单个条件的影响力。
力。然而,这种方法的问题在于 RNN 的隐藏状态是序列中所有先前条件的累积结果,因此它并不能直接反映单个条件的影响力。
如果你真的想要衡量每个条件对输出的独立影响力,你可能需要考虑使用其他类型的模型,比如基于注意力的模型,或者直接将每个条件单独输入到模型中,并观察输出的变化。然而,这取决于你的具体任务和数据的性质。
对于序列模型来说,更常见的是使用时间步长的输出来解释每个时间步长输入的影响力,而不是使用隐藏状态。但请注意,即使这样做,输出也是所有先前时间步长的函数,因此解释起来可能仍然很复杂。
通义灵码

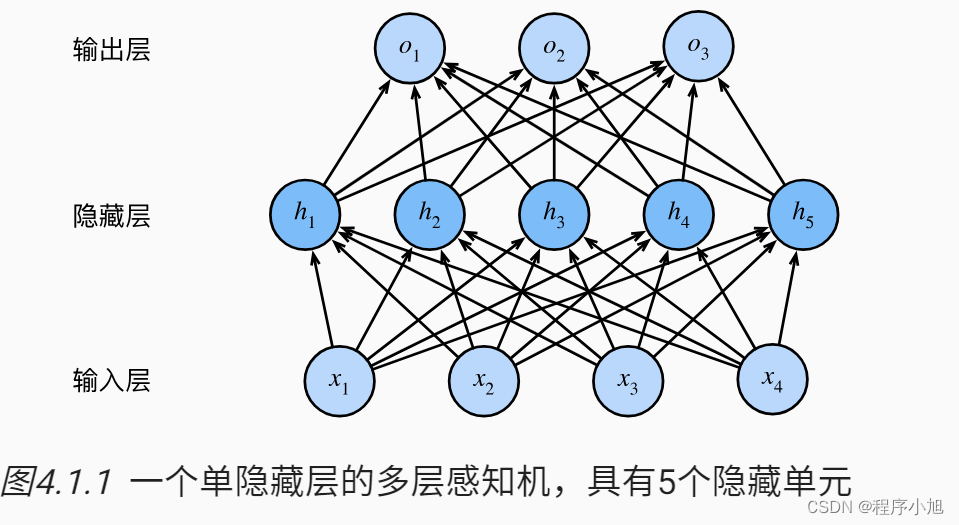
要构建一个循环神经网络(RNN)模型来评估五个条件对某件事情发生影响力的大小,首先需要明确以下几点:
数据准备:每个样本应包含五个条件特征(即输入特征)和一个标签(即事情是否发生,通常为二分类问题)。同时,需要确保数据集已适当划分成训练集、验证集和测试集。
模型架构:使用一个具有多个隐藏层的RNN(如LSTM或GRU)模型,每个条件作为时间步的输入,输出层为一个单一的sigmoid单元,预测事情发生的概率。
损失函数:采用二元交叉熵损失函数,因为它适用于二分类问题。
评估指标:可以使用AUC-ROC曲线、准确率、召回率等评估模型性能。
影响力计算:通过反向传播计算每个条件特征对于最终预测结果的梯度,梯度绝对值的大小可以作为衡量影响力的一种方式。这里我们仅展示模型构建和训练部分,影响力计算部分可参考相关梯度解释方法(如Integrated Gradients)进行扩展。
以下是一个使用PyTorch构建的简单RNN模型示例:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
# 假设数据集已准备好,形状为 (num_samples, sequence_length=5, input_dim)
# labels 形状为 (num_samples,)
input_data = torch.tensor(...)
labels = torch.tensor(...)
# 划分数据集
train_data, train_labels, val_data, val_labels, test_data, test_labels = ...
# 定义RNN模型
class RNNModel(nn.Module):
def __init__(self, input_dim, hidden_dim, num_layers, output_dim=1):
super(RNNModel, self).__init__()
self.rnn = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
_, (hidden, _) = self.rnn(x)
out = self.fc(hidden[-1])
return self.sigmoid(out)
model = RNNModel(input_dim=5, hidden_dim=64, num_layers=2)
# 定义损失函数和优化器
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 10
batch_size = 32
train_loader = DataLoader(TensorDataset(train_data, train_labels), batch_size=batch_size, shuffle=True)
val_loader = DataLoader(TensorDataset(val_data, val_labels), batch_size=batch_size, shuffle=False)
for epoch in range(num_epochs):
model.train()
for inputs, targets in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs.squeeze(-1), targets.float())
loss.backward()
optimizer.step()
# 在验证集上评估模型
model.eval()
with torch.no_grad():
val_losses = []
for inputs, targets in val_loader:
outputs = model(inputs)
loss = criterion(outputs.squeeze(-1), targets.float())
val_losses.append(loss.item())
print(f"Epoch {epoch+1}: Validation Loss = {sum(val_losses)/len(val_losses)}")
# 测试模型并打印预测结果
test_loader = DataLoader(TensorDataset(test_data, test_labels), batch_size=batch_size, shuffle=False)
model.eval()
with torch.no_grad():
predictions = []
for inputs in test_loader:
outputs = model(inputs).squeeze(-1)
predictions.extend(outputs.tolist())
# 对于影响力计算,此处仅展示模型训练过程,实际计算需参考相关梯度解释方法(如Integrated Gradients)请注意,上述代码并未实现条件影响力的具体计算。在实际应用中,您可能需要借助专门的梯度解释工具(如Captum库)或根据具体需求自定义计算方法来评估每个条件对预测结果的影响力。由于计算条件影响力的复杂性,这通常涉及到更高级的可解释性技术,超出了上述简单模型训练的范畴。
Kimi
在PyTorch中创建一个循环神经网络(RNN)来评估不同条件对某个事件发生的影响力是一个相对 复杂的过程,因为RNN主要用于处理序列数据。然而,如果我们将这个问题简化为一个分类任务,其中每个条件是输入特征,我们可以使用RNN来学习这些特征如何影响结果。
复杂的过程,因为RNN主要用于处理序列数据。然而,如果我们将这个问题简化为一个分类任务,其中每个条件是输入特征,我们可以使用RNN来学习这些特征如何影响结果。
以下是一个简单的PyTorch程序,演示了如何创建一个RNN模型,并使用它来评估每个条件的影响力。这个例子中,我们使用了一个合成数据集,其中每个条件的影响力是随机生成的。
首先,确保你已经安装了PyTorch。如果没有安装,可以从PyTorch的官方网站获取安装指南:Start Locally | PyTorch
然后,你可以使用以下Python代码:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的RNN模型
class RNNModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNNModel, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
x, hidden = self.rnn(x)
x = self.fc(x[:, -1, :]) # 使用序列的最后一个时间步的输出
return x
# 超参数
input_size = 5 # 5个条件
hidden_size = 10 # 隐藏层的大小
output_size = 1 # 输出层的大小(二分类问题)
# 实例化模型
model = RNNModel(input_size, hidden_size, output_size)
# 损失函数和优化器
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters())
# 合成数据
def generate_data(batch_size):
X = torch.rand(batch_size, 1, input_size)
y = torch.bernoulli(torch.rand(batch_size, 1)).float()
return X, y
# 训练模型
def train_model(model, criterion, optimizer, n_epochs=10):
for epoch in range(n_epochs):
X, y = generate_data(100) # 假设每批100个样本
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}/{n_epochs}, Loss: {loss.item()}')
train_model(model, criterion, optimizer)
# 为了计算特征影响力,我们可以使用模型的权重
# 请注意,这只是一个简化的示例,实际应用中可能需要更复杂的方法
influence = model.fc.weight.view(-1) # 将权重展开为1D向量
print("Influence of each condition:", influence)这段代码首先定义了一个简单的RNN模型,然后生成了合成数据来训练这个模型。在训练过程中,我们使用了二元交叉熵损失函数(BCEWithLogitsLoss)和Adam优化器。
请注意,这个示例中我们使用了模型的最后一层权重来表示每个条件的影响力,这只是一个简化的 方法。在实际应用中,评估特征影响力可能需要更复杂的技术,如SHAP(SHapley Additive exPlanations)或LIME(Local Interpretable Model-agnostic Explanations)。
方法。在实际应用中,评估特征影响力可能需要更复杂的技术,如SHAP(SHapley Additive exPlanations)或LIME(Local Interpretable Model-agnostic Explanations)。
此外,由于RNN通常用于处理序列数据,如果你的问题涉及到时间序列或序列预测,你可能需要调整模型结构以适应数据的序列特性。