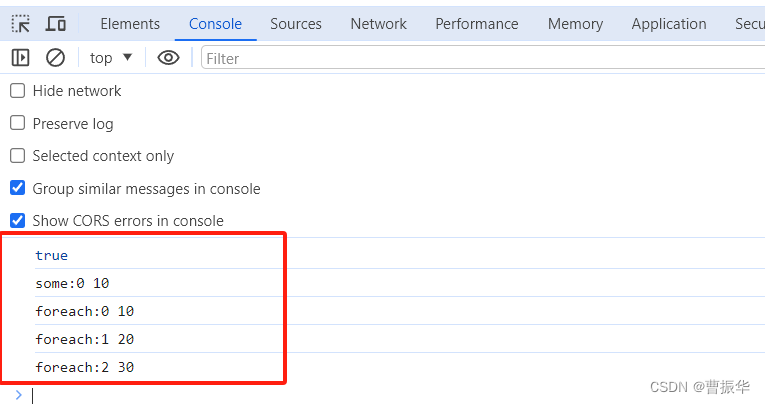
1、类可以定义构造函数,用来控制在创建此类型对象时做什么
类如何控制该类型对象拷贝、赋值、移动或销毁时做什么
类通过一些 特殊的成员函数 控制这些操作,包括:拷贝构造函数、移动构造函数、拷贝赋值运算符、移动赋值运算符 以及 析构函数
2、当定义一个类时,我们 显式地或隐式地指定 在此类型的对象拷贝、移动、赋值和销毁时做什么
一个类通过 定义五种特殊的成员函数 来控制这些操作,包括:拷贝构造函数、拷贝赋值运算符、移动构造函数、移动赋值运算符 和 析构函数
拷贝 和 移动构造函数 定义了 当用同类型的另一个对象 初始化 本对象时做什么
拷贝 和 移动赋值运算符 定义了 将一个对象 赋予同类型的另一个对象时做什么
析构函数 定义了 当此类型对象销毁时 做什么
我们称这些操作为拷贝控制操作
在定义任何C++类时,拷贝控制操作 都是必要部分
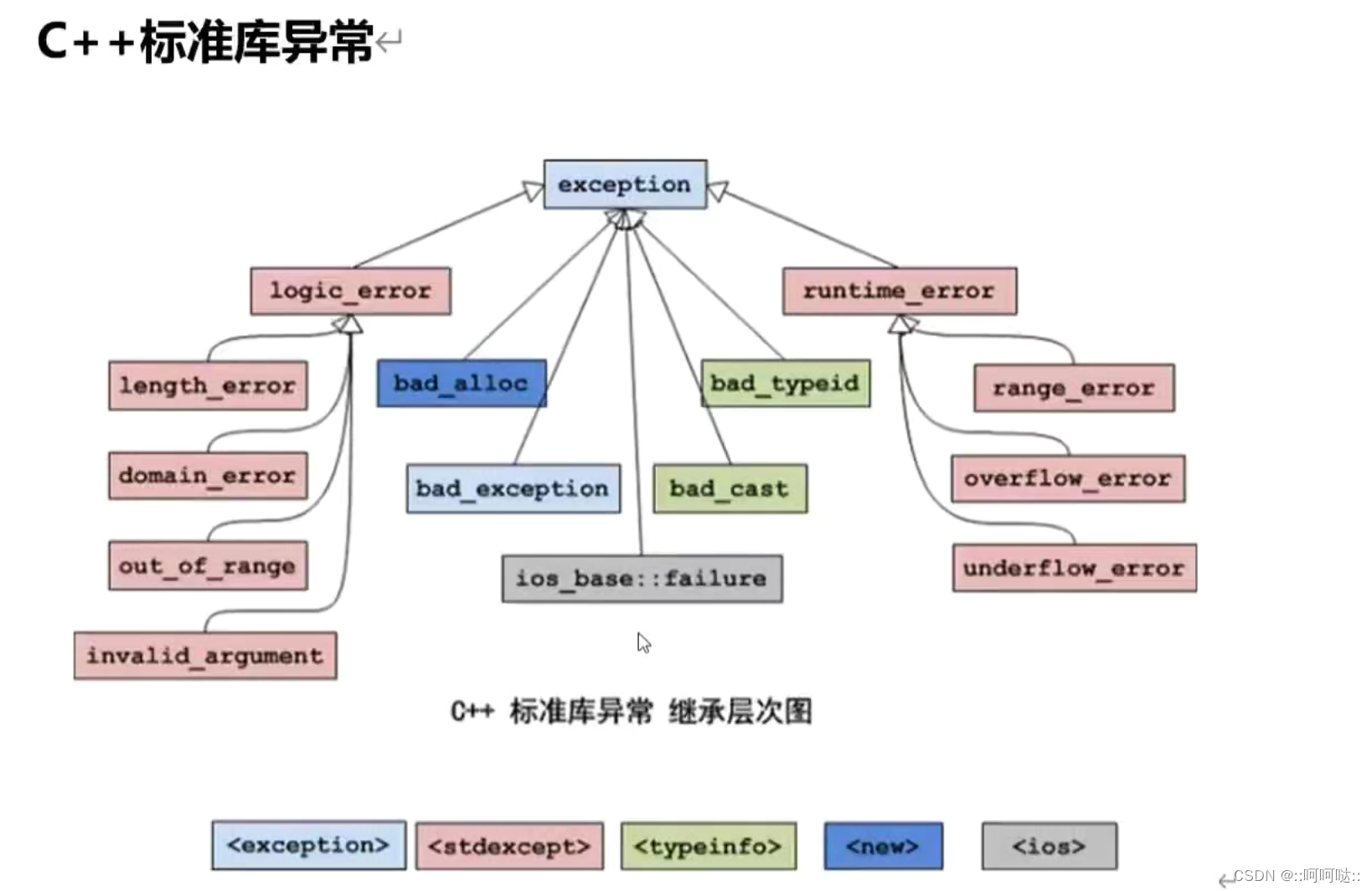
1、拷贝、赋值与销毁
拷贝构造函数、拷贝赋值运算符 和 析构函数
1.1 拷贝构造函数
1、如果一个构造函数的第一个参数 是自身类类型的引用,且任何额外参数 都有默认值,则此构造函数是 拷贝构造函数
class Foo {
public:
Foo(); // 默认构造函数
Foo(const Foo&); // 拷贝构造函数
// ...
};
拷贝构造函数的第一个参数 必须是一个引用类型,可以定义一个接受 非const引用的拷贝构造函数,但此参数 几乎总是一个const的引用。拷贝构造函数 在几种情况下 都会被隐式地使用。因此,拷贝构造函数 通常不应该是 explicit的
2、合成拷贝构造函数:没有为一个类 定义拷贝构造函数,编译器会为我们定义一个。与合成默认构造函数不同,即使我们定义了其他构造函数,编译器也会为我们 合成一个拷贝构造函数
合成拷贝构造函数 用来阻止我们 拷贝该类类型的对象。而一般情况,合成的拷贝构造函数会将 其参数的成员 逐个拷贝到正在创建的对象中。编译器从给定对象中 依次将 每个非static成员 拷贝到正在创建的对象中
每个成员的类型 决定了 它如何拷贝:对类类型的成员,会使用其拷贝构造函数来拷贝
内置类型的成员则直接拷贝。虽然我们不能 直接拷贝一个数组,但合成拷贝构造函数会逐元素地拷贝一个数组类型的成员。如果数组元素是类类型,则使用元素的拷贝构造函数 来进行拷贝
作为一个例子,我们的Sales data类的合成拷贝构造函数等价于:
class Sales data {
public:
//其他成员和构造函数的定义,如前
//与合成的拷贝构造函数等价的拷贝构造函数的声明
Sales data(const Sales data&);
private:
std::string bookNo;
int units_sold = 0;
double revenue = 0.0;
}
//与Sales_data的合成的拷贝构造函数等价
Sales_data::Sales_data(const Sales_data &orig):
bookNo(orig.bookNo), //使用string的拷贝构造函数
units_sold(orig.units_sold), //拷贝orig.units_sold
revenue(orig.revenue) //拷贝orig.revenue
{ } //空函数体
3、拷贝初始化(有等号) 直接初始化(括号)
string dots(10, '.'); //直接初始化
string s(dots); //直接初始化
string s2 = dots; //拷贝初始化
string null_book = "9-999-99999-9"; //拷贝初始化
string nines = string(100, '9'); //拷贝初始化
当使用 直接初始化时,我们实际上是 要求编译器使用普通的函数匹配 来选择与我们提供的参数最匹配的构造函数。当我们使用拷贝初始化时,我们要求编译器 将右侧运算对象拷贝到正在创建的对象中,如果需要的话 还要进行类型转换
拷贝初始化通常使用 拷贝构造函数来完成。如果一个类有一个移动构造函数,则拷贝初始化 有时会 使用移动构造函数 而非拷贝
构造函数来完成
拷贝初始化 不仅在 我们用=定义变量时会发生,在下列情况下也会发生
1)将一个对象作为实参传递给一个非引用类型的形参
2)从一个返回类型为非引用类型的函数返回一个对象
3)用花括号列表初始化一个数组中的元素或一个聚合类中的成员
某些类类型 还会对它们所分配的对象 使用拷贝初始化。例如,当我们初始化标准库容器或是调用 其insert或push成员时,容器会对其元素进行 拷贝初始化。与之相对,用 emplace成员 创建的元素 都进行直接初始化
4、参数和返回值:在函数调用过程中,具有非引用类型的参数 要进行 拷贝初始化。当一个函数 具有非引用的返回类型时,返回值 会被用来 初始化调用方的结果
拷贝构造函数 被用来 初始化非引用类类型参数,这一特性 解释了 为什么拷贝构造函数 自己的参数必须是引用类型。如果其参数不是引用类型,则调用 永远也不会成功 —— 为了调用 拷贝构造函数,我们必须 拷贝它的实参,但为了 拷贝实参,我们又需要 调用拷贝构造函数,如此无限循环
5、拷贝初始化的限制:如果 我们使用的初始化值 要求通过一个explicit的构造函数 来进行类型转换,那么使用 拷贝初始化还是直接初始化 就不是无关紧要的了:
vector<int> v1(10); //正确:直接初始化
vector<int> v2 = 10; //错误:接受大小参数的构造函数是explicit的
void f(vector<int>); //f的参数进行拷贝初始化
f(10); //错误:不能用一个explicit的构造函数拷贝一个实参
f(vector<int>(10)); //正确:从一个int直接构造一个临时vector
直接初始化v1是合法的,但看起来 与之等价的 拷贝初始化v2则是错误的,因为vector的 接受单一大小参数的 构造函数 是explicit的。如果我们希望使用 一个explicit构造函数,就必须 显式地使用,像此代码中最后一行那样
6、编译器可以绕过拷贝构造函数:在拷贝初始化过程中,编译器可以(但不是必须)跳过拷贝/移动构造函数,直接创建
对象
即,编译器被允许将下面的代码
string null_book = "9-999-99999-9"; //拷贝初始化
改写为
string null_book("9-999-99999-9"); //编译器略过了拷贝构造函数
即使 编译器略过了拷贝 / 移动构造函数,但在这个程序点上,拷贝 / 移动构造函数 必须是存在且可访问的(例如,不能是private的)
7、当我们拷贝一个StrBlob时,会发生什么?拷贝一个StrBlobPtr呢?
这两个类都未定义拷贝构造函数,因此编译器为它们定义了 合成的拷贝构造函数。合成的拷贝构造函数 逐个拷贝非 static 成员,对内置类型的成员,直接进行内存拷贝,对类类型的成员,调用 其拷贝构造函数进行拷贝
因此,拷贝一个 StrBlob 时,拷贝其唯一的成员 data,使用 shared_ptr 的拷贝构造函数 来进行拷贝,因此其引用计数增加1
拷贝一个 StrBlobPtr 时,拷贝成员 wptr,用 weak_ptr 的拷贝构造函数进行拷贝,引用计数不变,然后拷贝 curr,直接进行内存复制
当我们将一个 StrBlob 赋值给另一个 StrBlob 时,会发生什么?赋值 StrBlobPtr 呢?
一样,赋值StrBlob时shared_ptr+1,赋值StrBlobPtr不会
8、假定 Point 是一个类类型,它有一个public的拷贝构造函数,指出下面程序片段中哪些地方使用了拷贝构造函数:
Point global;
Point foo_bar(Point arg) //1 函数参数
{
Point local = arg, *heap = new Point(global); //2 赋值初始化
// *heap = new Point(global)不使用拷贝构造函数
*heap = local; // 3 赋值初始化
Point pa[ 4 ] = { local, *heap }; //4,5 列表初始化
return *heap; //6 返回值
}
给定下面的类框架
编写一个 拷贝构造函数,拷贝所有成员。你的构造函数 应该动态分配一个新的string,并将对象拷贝到ps所指向的位置,而不是拷贝ps本身
为HasPtr 类编写赋值运算符。类似拷贝构造函数,你的赋值运算符应该将对象拷贝到ps指向的位置
class HasPtr {
public:
HasPtr(const std::string& s = std::string()):
ps(new std::string(s)), i(0) { }
// 拷贝构造函数
HasPtr(const HasPtr& hp) : ps(new std::string(*hp.ps)), i(hp.i) { }
// 拷贝赋值运算符
HasPtr &operator=(const HasPtr &);
private:
std::string *ps;
int i;
}
HasPtr& HasPtr::operator=(const HasPtr &rhs) {
std::string *newps = new std::string(*rhs.ps); // 拷贝指针指向的对象
delete ps; // 销毁原 string
ps = newps; // 指向新 string
i = rhs.i; // 使用内置的 int 赋值
return *this; // 返回一个此对象的引用
}
在拷贝赋值运算符中,我们首先需要为新的对象分配内存来存储新的字符串。在这之前,我们需要确保原来 ps 指向的内存空间被释放,否则会导致内存泄漏。因此,我们先使用 delete ps; 来释放原来 ps 指向的内存
1.2 拷贝赋值运算符
1、与类控制其对象如何初始化一样,类也可以 控制其对象如何赋值
Sales_data trans, accum;
trans = accum; //使用Sales_data的拷贝赋值运算符
与拷贝构造函数一样,如果 类未定义 自己的拷贝赋值运算符,编译器会为它合成一个
2、重载赋值运算符:
重载运算符:重载运算符 本质上是函数,其名字 由operator关键字后接 表示要定义的运算符的符号 组成。因此,赋值运算符 就是 一个名为operator=的函数。类似于 任何其他函数,运算符函数 也有一个返回类型和一个参数列表
重载运算符的参数 表示 运算符的运算对象。某些运算符,包括赋值运算符,必须定义为 成员函数。如果一个运算符是一个成员函数,其左侧运算对象 就绑定到隐式的this参数。对于 一个二元运算符,例如赋值运算符,其右侧运算对象 作为显式参数传递
隐式的this参数:
如果一个运算符被定义为一个成员函数,那么它的左侧运算对象将会被绑定到隐式的 this 参数上。这意味着该成员函数将作为对象的成员函数被调用,并且该对象将会成为该成员函数的隐式参数,通常表示为 this
“左侧运算对象将会被绑定到隐式的 this 参数上” 意味着:
运算符被定义为成员函数:重载运算符函数是类的成员函数,它在类的内部声明和定义
隐式的 this 参数:编译器会在调用成员函数时自动传递一个指向调用对象的指针,即 this 指针,作为函数的一个参数
左侧运算对象绑定到 this 参数:当你调用运算符时,编译器会将左侧的对象绑定到隐式的 this 参数上,这样在运算符函数内部可以通过 this 指针来访问该对象的成员变量和其他成员函数
#include <iostream>
class Vector2D {
private:
double x;
double y;
public:
Vector2D(double x, double y) : x(x), y(y) {}
// 重载加法运算符+
Vector2D operator+(const Vector2D& other) const {
// 在这里,左侧运算对象(即调用该函数的对象)会被绑定到隐式的this参数上
// 即,this指针指向调用这个运算符的对象(v1)
double newX = this->x + other.x;
double newY = this->y + other.y;
return Vector2D(newX, newY);
}
// 输出向量的坐标
void print() const {
std::cout << "(" << x << ", " << y << ")" << std::endl;
}
};
int main() {
Vector2D v1(1.0, 2.0);
Vector2D v2(3.0, 4.0);
// 调用重载的加法运算符+
Vector2D result = v1 + v2;
// 输出结果
result.print(); // 输出 (4, 6)
return 0;
}
在这个例子中,我们定义了一个 Vector2D 类,并且重载了加法运算符 + 作为该类的成员函数。在 operator+ 函数内部,我们可以通过 this 指针访问调用该函数的对象(即左侧的运算对象)的成员变量 x 和 y,然后将其与传入的参数 other 对象的对应成员变量相加,从而实现了向量的加法操作
拷贝赋值运算符 接受一个 与其所在类相同类型的参数:
class Foo {
public:
Foo& operator=(const Foo&); // 赋值运算符
// ...
};
为了 与内置类型的赋值 保持一致,赋值运算符 通常返回一个指向 其左侧运算对象的引用
标准库 通常要求 保存在容器中的类型 要具有赋值运算符,且其返回值 是左侧运算对象的引用(其他运算符不一定)
赋值运算符 通常 应该返回一个指向其左侧运算对象的引用
3、合成拷贝赋值运算符:如果一个类 未定义自己的拷贝赋值运算符,编译器会为它 生成一个合成拷贝赋值运算符
对于某些类,合成拷贝赋值运算符 用来禁止 该类型对象的赋值
如果 拷贝赋值运算符并非出于此目的,它会将右侧运算对象的每个非static成员 赋予左侧运算对象的对应成员,这一工作 是通过成员类型的拷贝赋值运算符 来完成的
// 等价于合成拷贝赋值运算符
Sales_data&
Sales_data::operator=(const Sales_data &rhs)
{
bookNo = rhs.bookNo; //调用string::operator=
units_sold = rhs.units_sold; //使用内置的int赋值
revenue = rhs.revenue; //使用内置的double赋值
return *this; //返回一个此对象的引用
}
4、拷贝赋值运算符和拷贝构造函数 在使用上的区别:
拷贝构造函数:
它通常用于传递对象给函数参数、以值的形式返回对象、或者在程序中显式创建一个新的对象,其中新对象的内容与现有对象相同
拷贝构造函数的声明通常如下所示:
ClassName(const ClassName& other);
拷贝赋值运算符:
当已经存在的对象被另一个同类对象的值替换时,拷贝赋值运算符被调用
它通常用于已经存在的对象重新赋值为另一个对象的值
拷贝赋值运算符的声明通常如下所示:
ClassName& operator=(const ClassName& other);
它通常返回一个对当前对象的引用,以支持连续赋值操作
拷贝赋值运算符通常被实现为成员函数
1.3 析构函数
1、析构函数执行 与 构造函数相反的操作:构造函数 初始化对象的非static数据成员,还可能做一些其他工作:析构函数释放对象使用的资源,并销毁对象的非static数据成员
析构函数是类的一个成员函数,名字由波浪号接类名构成。它没有返回值,也不接受参数
class Foo {
public:
~Foo(); // 析构函数
// ...
};
由于析构函数 不接受参数,因此它不能被重载。对一个给定类,只会有唯一一个析构函数
2、析构函数完成什么工作:在一个构造函数中,成员的初始化 是在函数体执行之前完成的,且按照 它们在类中出现的顺序进行初始化。在一个析构函数中,首先执行函数体,然后销毁成员。成员 按初始化顺序的逆序销毁
在对象 最后一次使用之后,析构函数的函数体 可执行 类设计者希望执行的任何收尾工作。通常,析构函数释放对象在生存期分配的所有资源
在一个析构函数中,不存在类似构造函数中 初始化列表的东西来控制成员如何销毁,析构部分是隐式的。成员销毁时 发生什么完全依赖于 成员的类型。销毁类类型的成员 需要执行 成员自己的析构函数。内置类型没有析构函数,因此销毁内置类型成员什么也不需要做
3、隐式销毁一个内置指针类型的成员不会delete它所指向的对象
隐式销毁指的是当对象超出其作用域时,编译器会自动调用对象的析构函数来销毁该对象。这种销毁过程是隐式的,因为它是由编译器在程序执行时自动处理的,而不需要程序员显式地调用
隐式销毁通常发生在以下情况下:
1)局部对象超出作用域:当一个局部对象在其定义的代码块 结束 超出作用域时,它会被销毁
void someFunction() {
MyClass obj; // 定义局部对象
// 在这里执行一些代码
} // obj超出作用域,在此时被隐式销毁
2)动态分配的对象被 delete 释放:当使用 new 关键字动态分配内存来创建对象,然后在适当的时候使用 delete 释放内存时,对象会被销毁
MyClass* ptr = new MyClass(); // 动态分配对象
delete ptr; // 释放对象的内存,对象被销毁
3)成员对象随着其所属对象的销毁而销毁:当一个对象被销毁时,它的成员对象也会被销毁,这一过程也是隐式的
class MyClass {
private:
OtherClass member; // MyClass的成员对象
};
void someFunction() {
MyClass obj; // 定义对象
// 在这里执行一些代码
} // obj及其成员对象 member 在此时被隐式销毁
4、与普通指针不同,智能指针是 类类型,所以具有析构函数
因此,与普通指针不同,智能指针成员 在析构阶段 会被自动销毁
智能指针是C++中用于管理动态分配内存的类模板,它们的主要目的是在对象超出其作用域时自动释放所管理的内存,从而避免内存泄漏
智能指针的析构函数负责释放其所管理的动态分配内存。当智能指针对象超出其作用域时,或者不再需要时,它的析构函数会自动调用,从而释放其所持有的资源
在C++标准库中,有两种主要的智能指针类型:std::unique_ptr 和 std::shared_ptr。它们都有析构函数来确保资源的释放
对于 std::unique_ptr,析构函数会删除其所管理的对象
对于 std::shared_ptr,析构函数会递减引用计数,并在引用计数减为零时删除其所管理的对象
#include <iostream>
#include <memory>
class MyClass {
public:
MyClass() {
std::cout << "Constructor called." << std::endl;
}
~MyClass() {
std::cout << "Destructor called." << std::endl;
}
};
int main() {
std::cout << "Creating smart pointer." << std::endl;
std::unique_ptr<MyClass> ptr(new MyClass()); // 创建 unique_ptr
std::cout << "Exiting main function." << std::endl;
return 0;
} // 在 main 函数结束时,unique_ptr 的析构函数被调用,释放其管理的资源
在上面的示例中,当 ptr 超出其作用域时,std::unique_ptr 的析构函数会被调用,自动删除其所管理的对象 MyClass 的实例
5、什么时候会调用析构函数:无论何时一个对象被销毁,就会自动调用 其析构函数
- 变量在离开其作用域时被销毁
- 当一个对象被销毁时,其成员被销毁
- 容器(无论是标准库容器 还是数组)被销毁时,其元素被销毁
- 对于动态分配的对象,当对指向它的指针应用delete运算符时被销毁
- 对于临时对象,当创建它的完整表达式结束时被销毁
由于析构函数 自动运行,我们的程序 可以按需要分配资源,而(通常)无须担心 何时释放这些资源
{//新作用城
//p和p2指向动态分配的对象
Sales_data *p = new Sales_data; //p是一个内置指针
auto p2 = make_shared<Sales_data>(); //p2是一个shared_ptr
Sales_data item(*p); //拷贝构造函数将*p拷贝到item中
vector<Sales_data> vec; //局部对象
vec.push_back(*p2); //拷贝p2指向的对象
delete p; //对p指向的对象执行析构函数
} //退出局部作用域;对item(Sales_data)、p2(shared_ptr)和vec(vector)调用析构函数
//销毁p2 会递减其引用计数;如果 引用计数变为0,对象被释放(本例中计数为0)
//销毁vec会销毁它的元素
在vec.push_back(*p2)这行代码中,确实发生了一次拷贝,但是这个拷贝的对象是指针所指向的对象,而不是指针本身。因为引用计数是跟着shared_ptr对象本身的,而不是指向的对象
每个Sales_data对象 都包含一个string成员,它分配动态内存 来保存bookNo成员中 的字符。但是,我们的代码唯一需要直接管理的内存 就是我们直接分配的Sales_data对象。我们的代码 只需直接释放 绑定到p的动态分配对象
其他Sales_data对象会在离开作用域时被自动销毁
在所有情况下,Sales_data的析构函数 都会 隐式地销毁bookNo成员。销毁bookNo 会调用string的析构函数,它会释放 用来保存ISBN的内存
当指向一个对象的引用 或指针离开作用城时,折构函数不会执行(所以 手动管理)
6、合成析构函数:当一个类未定义自己的析构函数时,编译器 会为它定义一个合成析构函数。类似拷贝构造函数 和 拷贝赋值运算符,对于某些类,合成析构函数 被用来阻止该类型的对象被销毁
如果不是这种情况,合成析构函数的函数体 就为空
class Sales_data {
public:
//成员会被自动销毁,除此之外不需要做其他事情
~Sales_data() {}
//其他成员的定义,如前
};
在(空)析构函数体执行完毕后,成员会被自动销毁。特别的,string的析构函数会被调用,它将释放bookNo成员所用的内存
认识到析构函数体自身 并不直接销毁成员 是非常重要的。成员是在析构函数体之后 隐含的析构阶段中 被销毁的。在整个对象销毁过程中,析构函数体 是作为成员销毁步骤之外 的另一部分而进行的
7、当一个 StrBlob 对象销毁时会发生什么?一个 StrBlobPtr 对象销毁时呢?
这两个类都没有定义析构函数,因此编译器会为它们合成析构函数
对 StrBlob,合成析构函数的空函数体执行完毕后,会进行隐含的析构阶段,销毁非静态数据成员 data。这会调用 shared_ptr 的析构函数,将引用计数减 1,引用计数变为 0,会销毁共享的 vector 对象
对 StrBlobPtr,合成析构函数在隐含的析构阶段会销毁数据成员 wptr 和 curr,销毁 wptr 会调用 weak_ptr 的析构函数,引用计数不变,而 curr 是内置类型,销毁它不会有特殊动作
在下面的代码片段中会发生几次析构函数调用
bool fcn(const Sales_data *trans, Sales_data accum)
{
Sales_data item1(*trans), item2(accum);
return item1.isbn() != item2.isbn();
}
这段代码中会发生三次析构函数调用:
1)函数结束时,局部变量 item1 的生命期结束,被销毁,Sale_data 的析构函数被调用
2)类似的,item2 在函数结束时被销毁,Sale_data 的析构函数被调用
3)函数结束时,参数 accum 的生命期结束,被销毁,Sale_data 的析构函数被调用
在函数结束时,trans 的生命期也结束了,但它是 Sale_data 的指针,并不是它指向的 Sale_data 对象的生命期结束(只有 delete 指针时,指向的动态对象的生命期才结束),所以不会引起析构函数的调用
8、为前面的 HasPtr 类添加一个析构函数
private:
std::string *ps; // 只要手动释放这个指针就行
int i;
HasPtr::~HasPtr() {
delete ps;
}
编写一个程序以不同的方式使用 X 的对象:将它们作为非引用参数传递;动态分配 / 释放它们;将它们存放于容器中;拷贝初始化和赋值
#include <iostream>
#include <vector>
using namespace std;
struct X {
X() { cout << "构造函数 X()" << endl; }
X(const X&) { cout << "拷贝构造函数 X(const X&)" << endl; }
~X() { cout << "析构函数 ~X()" << endl; }
X& operator=(const X& tmp) {
cout << "拷贝赋值运算符 operator=(const X &)" << endl;
return *this;
}
};
void f1(X x) {
}
void f2(X& x) {
}
int main()
{
cout << "局部变量:" << endl;
X x;
cout << endl;
// 通过非引用参数传递方式调用 f1(x),这将创建 X 类型的对象作为参数传递给函数
// 在函数内部,这个参数对象会在函数执行结束时销毁,因此会调用一次析构函数
cout << "非引用参数传递:" << endl;
f1(x);
cout << endl;
// 通过引用参数传递方式调用 f2(x),这并不会创建新的对象,因为传递的是引用
// 所以在 f2() 函数执行结束时并不会调用析构函数
cout << "引用参数传递:" << endl;
f2(x);
cout << endl;
cout << "动态分配:" << endl;
X* px = new X;
cout << endl;
cout << "添加到容器中:" << endl;
vector<X> vx;
vx.push_back(x);
cout << endl;
// 这里最后出块会有一个析构函数 析构vx中的x
cout << "释放动态分配对象:" << endl;
delete px;
cout << endl;
cout << "拷贝初始化和赋值:" << endl;
X y = x;
y = x;
cout << endl;
cout << "程序结束!" << endl;
return 0;
}
运行结果
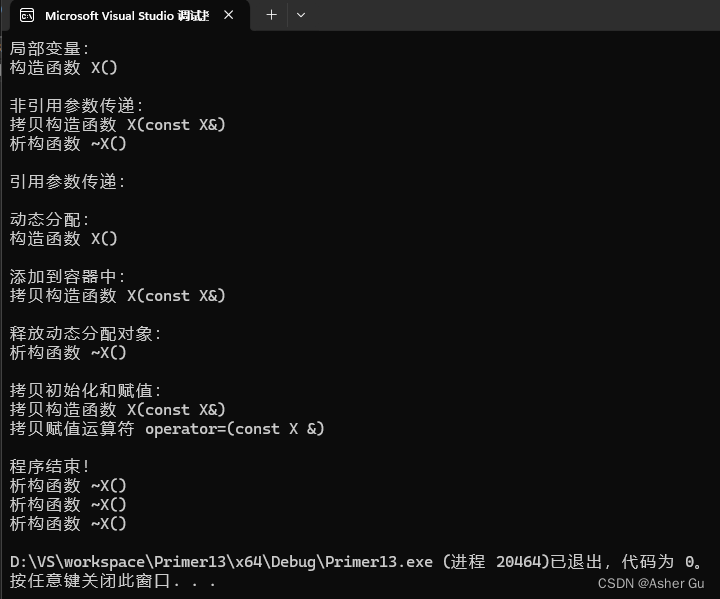
逐个地看一下在哪些地方创建了 X 类型的对象:
1)在 main() 函数中:
创建了局部变量 x,它的生命周期在 main() 函数结束时结束,因此会调用一次析构函数
2)在 f1() 函数中:
通过非引用参数传递方式调用 f1(x),这将创建 X 类型的对象作为参数传递给函数。在函数内部,这个参数对象会在函数执行结束时销毁,因此会调用一次析构函数
3)在 f2() 函数中:
通过引用参数传递方式调用 f2(x),这并不会创建新的对象,因为传递的是引用。所以在 f2() 函数执行结束时并不会调用析构函数
4)在动态分配中:
在 main() 函数中通过 new 关键字创建了一个动态分配的对象 px,在程序结束时通过 delete 释放了这个对象。因此,会调用一次析构函数
5)在容器中:
创建了一个 vector<X> 类型的容器 vx,并将 x 添加到容器中。当容器 vx 被销毁时,其中的所有元素也会被销毁,因此会调用一次析构函数
1.4 三 / 五法则
1、有三个基本操作可以控制类的拷贝操作:拷贝构造函数、拷贝赋值运算符 和 析构函数。而且,在新标准下,一个类还可以定义 一个移动构造函数 和 一个移动赋值运算符
通常,只需要其中一个操作,而不需要定义所有操作的情况 是很少见的
2、需要析构函数的类 也需要拷贝和赋值操作:决定一个类 是否要定义 它自己版本的拷贝控制成员时,一个基本原则是首先确
定这个类 是否需要一个析构函数。通常,对析构函数的需求 要比 对拷贝构造函数或赋值运算符的需求更为明显。如果这个类需要一个析构函数,我们几乎可以肯定 它也需要一个拷贝构造函数和一个拷贝赋值运算符
之前用过的 HasPtr类是一个好例子。这个类 在构造函数中 分配动态内存。合成析构函数 不会delete一个指针数据成员。因此,此类需要 定义一个析构函数 来释放构造函数分配的内存
应该怎么做可能还有点儿不清晰,但基本原则告诉我们,HasPtr也需要一个拷贝构造函数 和 一个拷贝赋值运算符
如果我们为HasPtr定义一个析构函数,但使用 合成版本的拷贝构造函数 和 拷贝赋值运算符,考虑会发生什么
class HasPtr {
public:
HasPtr(const std::string &s = std::string()):
ps(new std::string(s)), i(0) {}
~HasPtr() { delete ps; }
// 错误:HasPtr需要一个拷贝构造函数 和 一个拷贝赋值运算符
// 其他成员的定义,如前
};
构造函数中分配的内存 将在HasPtr对象销毁时被释放。这个版本的类 使用了合成的拷贝构造函数 和 拷贝赋值运算符。这些函数简单拷贝 指针成员,这意味着 多个HasPtr对象 可能指向相同的内存:
HasPtr f(HasPtr hp) //Has Ptr是传值参数,所以将被拷贝(因为使用了指针值传递所以出问题了,如果用智能指针就没事)
{
HasPtr ret = hp; //拷贝给定的HasPtr
//处理ret
return ret; //ret和hp被销毁
}
当f返回时,hp和ret都被销毁,在两个对象上 都会调用HasPtr 的析构函数。此析构函数会 delete ret 和 hp中 的指针成员。但这两个对象包含相同的指针值。此代码会导致 此指针被delete两次,这显然是一个错误。将要发生什么 是未定义的
f的调用者 还会使用传递给f的对象
HasPtr p("some values");
f(p); //当f结束时,p.ps指向的内存被释放
HasPtr q(p); //现在p和q都指向无效内存!
p(以及q)指向的内存 不再有效,在hp(或ret!)销毁时它就被归还给系统了
如果一个类需要自定义析构函数,几乎可以肯定它也需要自定义拷贝赋值运算符 和 拷贝构造函数
3、需要拷贝操作的类 也需要赋值操作,反之亦然
然而,无论是需要拷贝构造函数 还是需要拷贝赋值运算符 都不必然意味着也需要析构函数
虽然很多类 需要定义所有(或是不需要定义任何)拷贝控制成员,但某些类 所要完成的工作,只需要拷贝 或 赋值操作,不需要析构函数
考虑一个类 为每个对象分配一个独有的、唯一的序号。这个类需要一个拷贝构造函数 为每个新创建的对象 生成一个新的、独一无二的序号。除此之外,这个拷贝构造函数 从给定对象拷贝所有其他数据成员。这个类还需要 自定义拷贝赋值运算符 来避免将序号赋予目的对象。但是,这个类不需要自定义析构函数
4、假定 numbered 是一个类,它有一个默认构造函数,能为每个对象生成一个唯一的序号,保存在名为 mysn 的数据成员中。假定 numbered 使用合成的拷贝控制成员,并给定如下函数:
void f(numbered s) { cout << s.mysn < endl; }
#include <iostream>
using namespace std;
class numberd {
public:
int mysn;
numberd() { mysn = ++count; }
private:
int static count;
};
void f(numberd s) { cout << s.mysn << endl; }
int numberd::count = 0;
int main()
{
numberd a, b = a, c = b;
f(a); f(b); f(c);
return 0;
}
运行结果
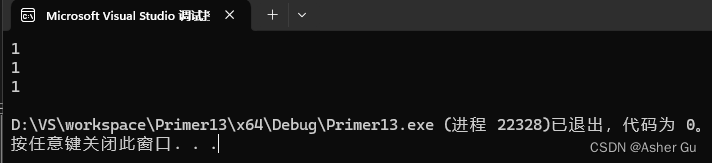
如果不定义拷贝构造函数和拷贝赋值运算符,依赖合成的版本,则在拷贝构造和赋值时,会简单复制数据成员。对本问题来说,就是将序号简单复制给新对象
合成拷贝构造函数被调用时简单复制序号,使得三个对象具有相同的序号
假定numbered 定义了一个拷贝构造函数,能生成一个新的序列号
#include <iostream>
using namespace std;
class numberd {
public:
int mysn;
numberd() { mysn = ++count; }
numberd(numberd& n) { mysn = ++count; }
private:
int static count;
};
void f(numberd s) { cout << s.mysn << endl; }
int numberd::count = 0;
int main()
{
numberd a, b = a, c = b;
f(a); f(b); f(c);
return 0;
}
运行结果
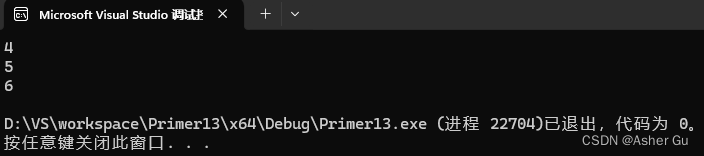
在定义变量 a 时,默认构造函数起作用,将其序号设定为 1。当定义 b、c 时,拷贝构造函数起作用,将它们的序号分别设定为 2、3
但是,在每次调用函数 f 时,由于参数是 numbered 类型,又会触发拷贝构造函数,使得每一次都将形参 s 的序号设定为新值,从而导致三次的输出结果是 4、5、6
将 类成员变量设置为static 有着特定的含义和用途。static类成员变量有以下特点和用途:
- 类级别的共享
static成员变量属于类本身,而不是属于类的任何特定实例。这意味着类的所有实例共享同一个static变量。如果任何实例修改了static变量的值,这个变化对所有其他实例都是可见的 - 独立于对象的存在
static成员变量即使在没有创建类的任何实例时也存在。它们在程序开始执行时就被初始化(在其定义的翻译单元中),并在程序结束时被销毁。这使得static变量可以在不创建类实例的情况下使用 - 内存效率
由于static成员变量不依赖于类的实例,不管创建了多少对象,都只有一个该变量的副本。这有助于节省内存,特别是当static变量被大量实例共享时 - 实现类级别的状态或服务
static变量可以用来跟踪类级别的状态信息,比如已创建的实例数量,或者用作某种全局服务的配置设置(尽管在现代C++设计中,更倾向于使用单例模式或者命名空间级别的变量来实现这一点) - 默认初始化
static成员变量会被自动初始化为零(对于基本数据类型),而非static成员变量的初始化则依赖于构造函数中的初始化列表
#include <iostream>
using namespace std;
class Account {
public:
Account() { ++numAccounts; }
~Account() { --numAccounts; cout << numAccounts << endl; }
static int getNumAccounts() { return numAccounts; }
private:
static int numAccounts;
};
int Account::numAccounts = 0; // 在类外初始化
int main() {
Account a1, a2;
std::cout << "Number of accounts: " << Account::getNumAccounts() << std::endl;
return 0;
}
运行结果
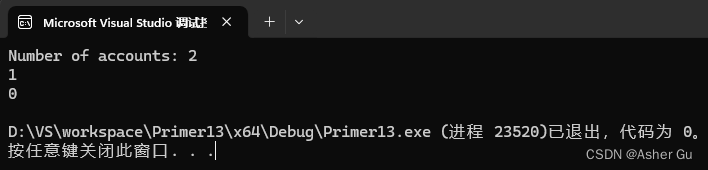
不论创建了多少个Account对象,numAccounts变量 都只有一个副本,并且所有的Account对象 都可以 访问和修改这个变量
如果 f 中的参数是 const numbered&,将会怎样
#include <iostream>
using namespace std;
class numberd {
public:
int mysn;
numberd() { mysn = ++count; }
numberd(numberd& n) { mysn = ++count; }
private:
int static count;
};
void f(const numberd& s) { cout << s.mysn << endl; }
int numberd::count = 0;
int main()
{
numberd a, b = a, c = b;
f(a); f(b); f(c);
return 0;
}
运行结果

由于形参类型由类类型 变为引用类型,传递的不是类对象而是类对象的引用。因此,对每次调用 f,序号自然就是实参的序号(不会递增了)
1.5 使用=default
1、可以通过将拷贝控制成员 定义为=default来 显式地要求编译器生成合成的版本
class Sales_data {
public:
//拷贝控制成员;使用default
Sales_data() = default;
Sales_data(const Sales_data&) = default;
Sales_data& operator=(const Sales_data &);
//其他成员的定义,如前
};
Sales_data& Sales_data::operator=(const Sales_data&) = default;
在类内用=default 修饰成员的声明时,合成的函数 将隐式地声明为内联的(就像任何其他 类内声明的成员函数一样)。如果我们不希望 合成的成员是内联函数,应该 只对成员的类外定义使用=default
只能对 具有合成版本的成员函数使用=default(即,默认构造函数 或 拷贝控制成员)
1.6 阻止拷贝
1、虽然大多数类应该 定义拷贝构造函数和拷贝赋值运算符。但对某些类来说,这些操作没有合理的意义。定义类时必须采用某种机制阻止拷贝或赋值
例如,iostream类阻止了拷贝,以避免 多个对象写入或读取相同的IO缓冲
为了阻止拷贝,看起来 可能应该不定义拷贝控制成员。但是,这种策略是无效的。如果我们的类未定义这些操作,编译器为它生成合成的版本
2、定义删除的函数:在新标准下,我们可以通过 将拷贝构造函数和拷贝赋值运算符 定义为删除的函数 来阻止拷贝。删除的函数是这样一种函数:我们虽然声明了它们,但不能以任何方式使用它们。在函数的参数列表后面加上=delete 来指出我们希望将它定义为删除的:
struct NoCopy {
NoCopy() = default; //使用合成的默认构造函数
NoCopy(const NoCopy&) = delete; //阻止拷贝
NoCopy &operator=(const NoCopy&) = delete; //阻止赋值
~NoCopy() = default; //使用合成的析构函数
//其他成员
}
1)与=default不同,=delete必须 出现在函数第一次声明的时候,与=delete不同,=default既可以在类的内部声明时使用,也可以在类的定义外使用
当在类定义外使用=default时,它不出现在函数的第一次声明处。这主要用于当你需要类的某个函数是默认行为,但你又希望它的声明与实现分离,或者需要某种形式的前置声明时
下面是一个示例:
假设你有一个类Example,并希望它的默认构造函数遵循默认行为,但又想在类的实现文件中明确这一点,以保持头文件的简洁:
// Example.h - 头文件
class Example {
public:
Example(); // 第一次声明,没有使用=default
// ... 其他成员函数 ...
};
// Example.cpp - 实现文件
#include "Example.h"
Example::Example() = default; // 在类定义外使用=default
=default是在类定义外部,即在实现文件(Example.cpp)中使用的。这样做的好处包括:
分离接口和实现:保持头文件(.h)的简洁和清晰,只展示接口而将实现细节隐藏在实现文件(.cpp)中
编译依赖性减少:改变类的实现时,不需要重新编译那些仅仅依赖于类接口的代码文件
2)与=default的 另一个不同之处是,我们可以 对任何函数指定=delete(我们只能对编译器可以合成的默认构造函数 或 拷贝控制成员使用=default)。虽然删除函数的主要用途是 禁止拷贝控制成员,但当我们希望 引导函数匹配过程时,删除函数有时也是有用的
3、析构函数不能是删除的成员:不能删除析构函数。如果 析构函数被删除,就无法销毁此类型的对象了。对于一个 删除了析构函数的类型,编译器将 不允许定义该类型的变量 或 创建该类的临时对象
如果一个类 有某个成员的类型 删除了析构函数,我们也不能 定义该类的变量 或 临时对象。因为如果一个成员的析构函数是删除的,则该成员无法被销毁。而如果一个成员无法被销毁,则对象整体也就无法被销毁了
对于删除了 析构函数的类型,虽然我们不能定义 这种类型的变量或成员,但可以动态分配 这种类型的对象。但是,不能释放这些对象
struct NoDtor {
NoDtor() = default; //使用合成默认构造函数
~NoDtor() = delete; //我们不能销毁NoDtor类型的对象
};
NoDtor nd; //错误:NoDtor的析构函数是删除的
NoDtor *p = new NoDtor(); //正确:但我们不能delete p
delete p; //错误:NoDtor的析构函数是删除的
对于析构函数 已删除的类型,不能定义 该类型的变量 或 释放指向该类型动态分配对象的指针
4、合成的拷贝控制成员 可能是删除的:
对某些类来说,编译器 将这些合成的成员 定义为删除的函数:
- 如果类的某个成员的析构函数 是删除的 或 不可访问的(例如,是private的),则类的合成析构函数 被定义为删除的
- 如果类的某个成员的拷贝构造函数 是删除的 或 不可访问的,则类的合成拷贝构造函数 被定义为删除的。如果类的某个成员的析构函数 是删除的 或 不可访问的,则类合成的拷贝构造函数 也被定义为删除的
- 如果类的某个成员的拷贝赋值运算符 是删除的 或 不可访问的,或是 类有一个const的或引用成员,则类的合成拷贝赋值运算符被定义为删除的
- 如果类的某个成员的析构函数 是删除的 或 不可访问的,或是 类有一个引用成员,它没有类内初始化器,或是类有一个const成员,它没有类内初始化器 且 其类型未显式定义默认构造函数,则该类的默认构造函数被定义为删除的
本质上,这些规则的含义是:如果一个类有数据成员 不能默认构造、拷贝、复制或销毁,则对应的成员函数 将被定义为删除的
类内初始化器:
class MyClass {
public:
type member_name = value; // 类内初始化器
};
当一个类包含常量(const)或引用成员时,这对该类的构造函数和赋值操作有特别的影响。这是因为常量成员一旦被初始化后就不能被修改,引用成员必须在初始化时被绑定到一个对象上,之后也不能再绑定到另一个对象
1)常量成员
对于常量成员,由于它们的值在初始化之后不能更改,因此它们必须在类的构造函数初始化列表中初始化。这意味着,即使是默认构造函数,也需要明确指定常量成员的初始值
class WithConstMember {
public:
const int constMember;
WithConstMember(int value) : constMember(value) {} // 必须在初始化列表中初始化const成员
};
2)引用成员
引用成员也必须在构造函数的初始化列表中进行初始化,因为引用一旦被初始化以指向一个对象,就不能被改变指向另一个对象
class WithReferenceMember {
public:
int& referenceMember;
WithReferenceMember(int& value) : referenceMember(value) {} // 必须在初始化列表中初始化引用成员
};
2)构造函数 和 赋值操作
构造函数:对于含有常量 或 引用成员的类,它们的构造函数 必须通过初始化列表来初始化这些成员。默认构造函数(如果需要的话)也必须 提供这样的初始化列表
拷贝构造函数 和 移动构造函数:通常可以自动生成,但它们 也会通过成员初始化列表 来初始化常量和引用成员
拷贝赋值运算符 和 移动赋值运算符:由于常量和引用成员 一旦被初始化后就不能更改,这意味着 如果类中包含常量 或 引用成员,那么这个类 就不能有默认的拷贝赋值运算符 或 移动赋值运算符。你需要 自己定义赋值运算符的行为,确保符合类设计的意图,或者 选择删除这些赋值运算符
3)实践建议
当类包含常量或引用成员时,仔细考虑类的拷贝和移动语义。有时,明确删除拷贝赋值运算符和移动赋值运算符(使用=delete)是一个明智的选择,特别是当拷贝或移动操作在逻辑上不适合你的类时
确保在类的构造函数中通过初始化列表正确地初始化所有常量和引用成员
如果类的设计不需要对象之间的拷贝或赋值,考虑将拷贝构造函数和拷贝赋值运算符标记为=delete,以防止编译器自动生成它们
一个成员 有删除的或不可访问的析构函数 会导致合成的默认和拷贝构造函数被定义为删除的,避免创建出无法销毁的对象
对于具有引用成员 或 无法默认构造的const成员的类,编译器 不会为其合成默认构造函数;如果一个类有const成员,则它不
能使用 合成的拷贝赋值运算符。毕竟,此运算符 试图赋值所有成员,而 将一个新值赋予一个const对象 是不可能的
虽然 我们可以 将一个新值 赋予一个引用成员,但这样做 改变的是 引用指向的对象的值,而不是引用本身。如果为这样的类 合成拷贝赋值运算符,则赋值后,左侧运算对象仍然指向 与赋值前一样的对象,而不会与右侧运算对象指向相同的对象。由于这种行为看起来并不是我们所期望的,因此对于 有引用成员的类,合成拷贝赋值运算符被定义为删除的
5、private拷贝控制:类是 通过将其拷贝构造函数 和 拷贝赋值运算符声明为private的来阻止拷贝
class PrivateCopy {
//无访问说明符;接下来的成员默认为private的
//拷贝控制成员是private的,因此普通用户代码无法访问
PrivateCopy(const PrivateCopy&);
PrivateCopy &operator=(const PrivateCopy&);
//其他成员
public:
PrivateCopy() = default; //使用合成的默认构造函数
~PrivateCopy(); //用户可以定义此类型的对象,但无法拷贝它们
};
由于析构函数是public的,用户 可以定义PrivateCopy类型的对象。但是,由于拷贝构造函数 和 拷贝赋值运算符 是private的,用户代码 将不能拷贝这个类型的对象。但是友元 和 成员函数 仍旧可以拷贝对象。为了阻止友元和成员函数进行拷贝,我们将 这些拷贝控制成员 声明为private的,但并不定义它们
试图访问 一个未定义的成员 将导致一个链接时错误。通过声明(但不定义)private的拷贝构造函数,我们可以 预先阻止任何拷贝该类型对象的企图:试图拷贝对象的用户代码 将在编译阶段被标记为错误:成员函数 或 友元函数中的拷贝操作 将会导致链接时错误
希望阻止拷贝的类 应该使用=delete 来定义它们自己的拷贝构造函数 和 拷贝赋值运算符,而不应该 将它们声明为private的
6、定义一个 Employee 类,它包含雇员的姓名和唯一的雇员证号。为这个类定义默认构造函数,以及接受一个表示雇员姓名的 string 的构造函数。每个构造函数应该通过递增一个 static 数据成员来生成一个唯一的证号
同时定义它自己的拷贝控制成员
(当用 a 初始化 b 时,会调用拷贝构造函数。如果不定义拷贝构造函数,则合成的拷贝构造函数简单复制 mysn,会使两者的序号相同
当用 b 为 c 赋值时,会调用拷贝赋值运算符。如果不定义自己的版本,则编译器定义的合成版本会简单复制 mysn,会使两者的序号相同)
#include <iostream>
#include <string>
using namespace std;
class Employee {
private:
int static count;
public:
Employee() { num = count++; }
Employee(const string& s) :name(s) { num = count++; }
Employee(const Employee& e) { name = e.name; num = count++; }
// 没有重载赋值运算符= 下面使用c=b时 就直接用生成的,b和c的num会一致
// 赋值运算符被定义为只复制name,并不改变mysn的值。如果移除了这个自定义的赋值运算符定义,编译器生成的默认赋值运算符将会复制所有成员,包括mysn
// 这就导致了,使用默认的赋值运算符之后,b和c对象将有相同的name和mysn值,因为c完全复制了b的状态
Employee& operator=(Employee &e) {
name = e.name;
// num = count++; 加上这句就0,1,3了
return *this;
}
string& get_name() { return name; }
int get_num() { return num; }
private:
int num;
string name;
};
int Employee::count = 0;
void f(Employee& e) {
cout << e.get_name() << " " << e.get_num() << endl;
}
int main()
{
Employee a("ashergu"), b = a, c;
c = b;
f(a); f(b); f(c);
return 0;
}
运行结果:

在这个程序中,sn是Employee类的一个静态成员变量,用于给每个Employee对象一个唯一的序列号。根据给出的程序,sn在以下情况下递增:
a的默认构造函数:mysn = sn++;
b的拷贝构造函数:mysn(sn++)
c的默认构造函数:mysn = sn++;
这里总共有3次构造函数的调用(一次默认构造,一次拷贝构造,再一次默认构造),每次构造函数被调用时,sn都会递增1次。因此,sn总共递增了3次
关于赋值操作(c = b; ):
Employee& operator=(Employee& rhs):这个赋值操作并不会导致sn的递增,因为它只是将一个对象的name复制到另一个对象,而序列号mysn是在构造时已经固定下来的,并不会因为赋值操作而改变
7、当我们拷贝、赋值或销毁 TextQuery 和 QueryResult 类对象时会发生什么
两个类都未定义拷贝控制成员,因此都是编译器为它们定义合成版本
当 TextQuery 销毁时,合成版本会销毁其 vec 和 m 成员。对 vec 成员,会将 shared_ptr 的引用计数减 1,若变为 0,则销毁所管理的动态 vector 对象(会调用 vector 和 string 的析构函数)。对 m,调用 map 的析构函数(从而调用 string、shared_ptr 和 set 的析构函数),会正确释放资源。
当 QueryResult 销毁时,合成版本会销毁其 word、lines 和 vec 成员。类似 TextQery,string、shared_ptr、set、vector 的析构函数可能被调用,因为这些类都有良好的拷贝控制成员,会正确释放资源。
当拷贝一个 TextQery 时,合成版本会拷贝vec 和 m 成员。对 file,shared_ptr 的引用计数会加 1。对 m,会调用 map 的拷贝构造函数(继而调用 string、shared_ptr 和 set 的拷贝构造函数),因此会正确进行拷贝操作。赋值操作类似,只不过会将原来的资源释放掉,例如,原有的 vec 的引用计数会减 1
这两个类的类对象之间使用智能指针 就实现了资源共享,不需要定义它们自己版本的拷贝控制成员
2、拷贝控制和资源管理
1、通常,管理类外资源的类 必须定义拷贝控制成员。这种类 需要通过析构函数 来释放对象所分配的资源。一旦一个类 需要析构函数,那么它几乎肯定 也需要一个拷贝构造函数和一个拷贝赋值运算符
为了定义这些成员,我们首先必须确定此类型对象的拷贝语义。一般来说,有两种选择:
可以定义拷贝操作,1)使类的行为看起来像一个值或者 2)像一个指针
类的行为 像一个值,意味着 它应该也有自己的状态。当我们拷贝一个 像值的对象时 副本和原对象是完全独立的。改变副本 不会对原对象有任何影响,反之亦然
行为像指针的类 则共享状态。当我们 拷贝一个这种类的对象时,副本和原对象 使用相同的底层数据。改变副本也会改变原对象,反之亦然
标准库类中,标准库容器和string类的行为像一个值;shared ptr类提供类似指针的行为;IO类型和unique ptr不允许拷贝或赋值,因此它们的行为既不像值也不像指针
2、HasPtr的行为像一个值。即,对于对象所指向的string成员,每个对象 都有一份自己的拷贝
#include <iostream>
#include <string>
using namespace std;
class HasPtr {
public:
//对ps指向的string,每个HasPtr对象都有自己的拷贝
HasPtr(const string& s = string()) : num(0), sp(new string(s)) {}
HasPtr(const HasPtr& h) : num(h.num), sp(new string(*(h.sp))) {} // 拷贝构造函数
HasPtr& operator=(const HasPtr& h); // 拷贝赋值运算符
HasPtr& operator=(const string& s) { *sp = s; return *this; } // 拷贝赋值运算符
string& operator*() { return *sp; } // 重载运算符:解引用
~HasPtr() { delete sp; } // 释放new的内存
private:
int num;
string* sp;
};
HasPtr& HasPtr::operator=(const HasPtr& h) {
string* ns = new string(*h.sp); // 拷贝底层string
delete sp; // 先释放空间再指向新的
sp = ns;
num = h.num;
return *this;
}
int main()
{
HasPtr h("hi mom!");// 行为类值,h2、h3 和 h 指向不同 string
HasPtr h2(h);
// 使用拷贝构造函数进行初始化。这意味着h2将会拥有一个与h相同内容的std::string对象,但它们是独立的对象,修改其中一个不会影响另一个
HasPtr h3 = h;
// 也是使用拷贝构造函数进行初始化的,语法上看起来像拷贝构造函数,但实际上也可以被认为是拷贝初始化的一种形式
// h3将会拥有一个与h相同内容的std::string对象,但它们是独立的对象,修改其中一个不会影响另一个
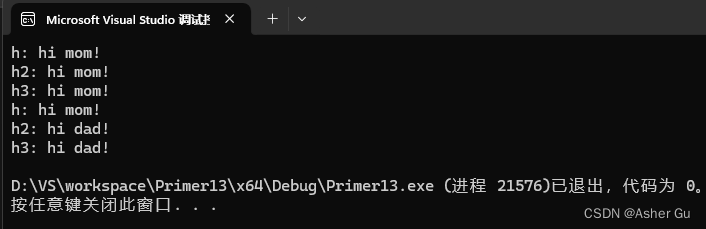
cout << "h: " << *h << endl;
cout << "h2: " << *h2 << endl;
cout << "h3: " << *h3 << endl;
h2 = "hi dad!"; // 拷贝赋值运算符
h3 = h2; // 拷贝赋值运算符
cout << "h: " << *h << endl;
cout << "h2: " << *h2 << endl;
cout << "h3: " << *h3 << endl;
return 0;
}
运行结果
HasPtr(const std::string &s = std::string()):
ps(new std::string(s)), i(0) { }
HasPtr(const std::string &s = std::string()):这是HasPtr类的一个构造函数,它接受一个对std::string的常量引用作为参数。这个参数有一个默认值,即一个默认构造的std::string对象。这意味着你可以不传递任何参数 来构造HasPtr对象,此时s将会是一个空的std::string对象
ps(new std::string(s)):这部分使用new操作符动态分配了一个std::string对象,这个对象是用传入的std::string对象s来初始化的。然后,这个新分配的std::string对象的地址被赋给成员变量ps。简而言之,ps是一个指向动态分配的std::string对象的指针,这个std::string对象的内容与传入的参数s相同
为什么在这个场景中需要使用const:
- 避免意外修改
当一个函数的参数是引用类型时,如果不使用const修饰,那么在函数内部有可能修改传递进来的参数值,这可能导致意外的行为,尤其是在涉及到临时对象的时候。使用const修饰可以确保函数不会修改传递进来的参数。 - 允许传递临时对象
在这种情况下,右值std::string()是一个临时对象(也称为右值),它是一个匿名对象,只能绑定到const引用上。因此,如果不将s声明为const,则无法将临时对象绑定到非const引用上,这将导致编译错误 - 符合类型推导的要求
const引用能够接受常量和非常量对象,这样就符合了类型推导的要求。如果不加const,则右值std::string()将无法与非const引用匹配,导致类型推导失败
const std::string &s = std::string(); // 正确,允许绑定到临时对象
std::string &s = std::string(); // 错误,无法将临时对象绑定到非const引用
2.1 行为像值的类
1、为了提供 类值的行为,对于类管理的资源,每个对象 都应该 拥有一份自己的拷贝。这意味着 对于ps指向的string,每个HasPtr对象都必须有自己的拷贝。为了实现类值行为,HasPtr需要
- 定义一个拷贝构造函数,完成string的拷贝,而不是拷贝指针
- 定义一个析构函数来释放string
- 定义一个拷贝赋值运算符来释放对象当前的string,并从右侧运算对象拷贝
class HasPtr {
public:
//对ps指向的string,每个HasPtr对象都有自己的拷贝
HasPtr(const string& s = string()) : num(0), sp(new string(s)) {}
HasPtr(const HasPtr& h) : num(h.num), sp(new string(*(h.sp))) {} // 拷贝构造函数
HasPtr& operator=(const HasPtr& h); // 拷贝赋值运算符
HasPtr& operator=(const string& s) { *sp = s; return *this; } // 拷贝赋值运算符
string& operator*() { return *sp; } // 重载运算符:解引用
~HasPtr() { delete sp; } // 释放new的内存
private:
int num;
string* sp;
};
第一个构造函数 接受一个(可选的)string参数。这个构造函数 动态分配它自己的string副本,并 将指向string的指针 保存在ps中。拷贝构造函数 也分配 它自己的string副本。析构函数 对指针成员sp执行delete,释放构造函数中分配的内存
2、类值拷贝赋值运算符:赋值运算符 通常组合了 析构函数和构造函数的操作。类似析构函数,赋值操作 会销毁 左侧运算对象的资源。类似 拷贝构造函数,赋值操作 会从右侧运算对象拷贝数据
但是,这些操作是以正确的顺序执行的,即使将一个对象赋予它自身,也保证正确。而且,如果可能,我们编写的赋值运算符还应该是异常安全的一一当异常发生时(new的时候) 能将左侧运算对象置于一个有意义的状态
通过 先拷贝右侧运算对象,我们可以处理 自赋值情况,并能保证 在异常发生时 代码也是安全的。在完成拷贝后,我们释放左侧运算对象的资源,并更新指针 指向新分配的string:
HasPtr& HasPtr::operator=(const HasPtr& h) {
string* ns = new string(*h.sp); // 拷贝底层string
delete sp; // 先释放空间再指向新的
sp = ns;
num = h.num;
return *this;
}
首先 进行了构造函数的工作:ns的初始化器等价于HasPtr的拷贝构造函数中sp的初始化器。接下来与析构函数一样,我们delete
当前sp指向的string
3、当你编写赋值运算符时:
- 如果将一个对象赋予它自身,赋值运算符必须能正确工作
- 大多数赋值运算符 组合了 析构函数和拷贝构造函数的工作
一个好的模式 是 先将右侧运算对象拷贝到一个局部临时对象中。当拷贝完成后,销毁左侧运算对象的现有成员 就是安全的了。一旦左侧运算对象的资源被销毁,就只剩下将数据从临时对象拷贝到左侧运算对象的成员中了
HasPtr&
HasPtr::operator=(const HasPtr &rhs)
{
delete sp; //释放对象指向的string
//如果rhs和*this是同一个对象,我们就将从已释放的内存中拷贝数据
sp = new string(*(rhs.sp));
num = rhs.num;
return *this;
}
4、如果 HasPtr 版本未定义析构函数,将会发生什么?如果未定义拷贝构造函数,将会发生什么
如果未定义析构函数,在销毁 HasPtr 对象时,合成的析构函数不会释放指针 sp 指向的内存,造成内存泄漏
如果未定义拷贝构造函数,在拷贝 HasPtr 对象时,合成的拷贝构造函数会简单复制 sp 成员,使得两个 HasPtr 指向相同的 string。当其中一个 HasPtr 修改 string 内容时,另一个 HasPtr 也被改变,这并不符合我们的设想。如果同时定义了析构函数,情况会更为糟糕,当销毁其中一个 HasPtr 时,sp 指向的 string 被销毁,另一个 HasPtr 的 sp 成为空悬指针
5、假定希望定义 StrBlob 的类值版本,而且希望继续使用 shared_ptr,这样我们的 StrBlobPtr 类就仍能使用指向vector的 weak_ptr 了。你修改后的类 将需要一个拷贝的构造函数和一个拷贝赋值运算符,但不需要析构函数
解释拷贝构造函数和拷贝赋值运算符必须要做什么。解释为什么不需要析构函数
由于希望 StrBlob 的行为像值一样,因此在拷贝构造函数和拷贝赋值运算符中,我们应该将其数据 —— string 的 vector 拷贝一份,使得两个 StrBlob 对象指向各自的数据,而不是简单拷贝 shared_ptr 使得两个 StrBlob 指向同一个 vector
StrBlob 不需要析构函数的原因是,它管理的全部资源就是 string 的 vector,而这是由 shared_ptr 负责管理的。当一个 StrBlob 对象销毁时,会调用 shared_ptr 的析构函数,它会正确调整引用计数,当需要时(引用计数变为 0)释放 vector。即,shared_ptr 保证了资源分配、释放的正确性,StrBlob 就不必进行相应的处理了
StrBlob.h
#pragma once
#ifndef STRBLOB_H
#define STRBLOB_H
#include <string>
#include <vector>
#include <iostream>
#include <memory>
#include <initializer_list>
#include <stdexcept>
class StrBlobPtr;
class StrBlob {
public:
friend class StrBlobPtr;
typedef std::vector<std::string>::size_type size_type;
StrBlob() :data(std::make_shared<std::vector<std::string>>()) {};
StrBlob(const std::initializer_list<std::string>& il);
StrBlob(StrBlob &sb):data(std::make_shared<std::vector<std::string>>(*sb.data)) {} // shared_ptr操作和指针一致,拷贝构造函数
StrBlob& operator=(StrBlob& sb); // 拷贝赋值运算符,不需要析构函数
size_type size() const { return data->size(); }
bool empty() const { return data->empty(); }
void push_back(const std::string& t) { data->push_back(t); }
void pop_back();
std::string& front();
std::string& front() const;
std::string& back();
std::string& back() const;
StrBlobPtr begin();
StrBlobPtr end();
private:
std::shared_ptr<std::vector<std::string>> data;
void check(size_type i, const std::string& msg) const;
};
StrBlob& StrBlob::operator=(StrBlob& sb) {// 拷贝赋值运算符
data = std::make_shared<std::vector<std::string>>(*sb.data);
return *this;
}
class StrBlobPtr {
public:
StrBlobPtr() :curr(0) {}
StrBlobPtr(StrBlob& a, size_t sz = 0) :wptr(a.data), curr(sz) {}
std::string& deref() const;
StrBlobPtr& incr();
bool operator!=(const StrBlobPtr& p) { return p.curr != curr; }
private:
// 若检查确实存在,check返回一个 指向vector的shared_ptr
std::shared_ptr<std::vector<std::string>> check(std::size_t, const std::string&) const;
// 保存一个weak_ptr,意味着 底层vector可能被销毁,直接用vector初始化即可
std::weak_ptr<std::vector<std::string>> wptr;
std::size_t curr; // 在数组中的当前位置
};
StrBlob::StrBlob(const std::initializer_list<std::string>& il) :data(std::make_shared<std::vector<std::string>>(il)) {}
void StrBlob::check(size_type i, const std::string& msg) const {
if (i >= data->size())
throw std::out_of_range(msg);
}
void StrBlob::pop_back() {
check(0, "pop_back on empty StrBlob");
data->pop_back();
}
std::string& StrBlob::front() {
check(0, "front on empty StrBlob");
return data->front();
}
std::string& StrBlob::front() const {
check(0, "front on empty StrBlob");
return data->front();
}
std::string& StrBlob::back() {
check(0, "back on empty StrBlob");
return data->back();
}
std::string& StrBlob::back() const {
check(0, "back on empty StrBlob");
return data->back();
}
std::shared_ptr<std::vector<std::string>> StrBlobPtr::check(std::size_t i, const std::string& msg) const // msg不同错误不同信息
{
auto ret = wptr.lock(); // vector存在与否
if (!ret)
throw std::runtime_error("unbound StrBlobPtr");
if (i >= ret->size())
throw std::out_of_range(msg);
return ret; // 返回指向vector的shared_ptr
}
std::string& StrBlobPtr::deref() const
{
auto p = check(curr, "dereference past end");
return (*p)[curr]; // *p是对象所指向的vector
}
StrBlobPtr& StrBlobPtr::incr()
{
// 如果curr已经指向容器的尾后位置,就不能递增它
check(curr, "increment past end of StrBlobPtr");
++curr; // 推进当前位置
return *this;
}
StrBlobPtr StrBlob::begin() {
return StrBlobPtr(*this);
}
StrBlobPtr StrBlob::end()
{
auto ret = StrBlobPtr(*this, data->size());
return ret;
}
#endif
3.26.cpp
#include <iostream>
#include "StrBlob.h"
using namespace std;
int main() {
// 展现独立性
StrBlob b1;
{
StrBlob b2 = { "ashergu", "is", "an", "embedded_ai" };
b1 = b2;
b2.push_back("engineer");
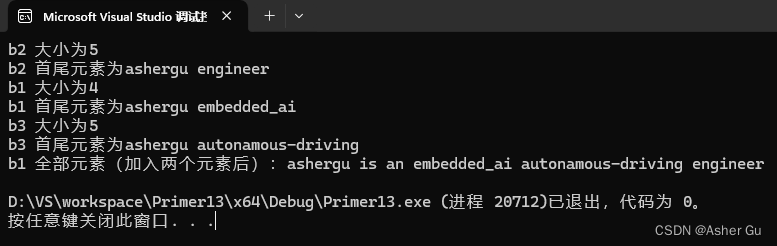
cout << "b2 大小为" << b2.size() << endl;
cout << "b2 首尾元素为" << b2.front() << " " << b2.back() << endl;
}
// b2 在花括号外失效,作用域仅限于花括号内
cout << "b1 大小为" << b1.size() << endl;
cout << "b1 首尾元素为" << b1.front() << " " << b1.back() << endl;
StrBlob b3 = b1;
b3.push_back("autonamous-driving");
cout << "b3 大小为" << b3.size() << endl;
cout << "b3 首尾元素为" << b3.front() << " " << b3.back() << endl;
b1.push_back("autonamous-driving");
b1.push_back("engineer");
cout << "b1 全部元素(加入两个元素后):";
for (StrBlobPtr sbp = b1.begin(); sbp != b1.end(); sbp.incr())
cout << sbp.deref() << " ";
cout << endl;
return 0;
}
运行结果
2.2 定义行为像指针的类
1、对于 行为类似指针的类,我们需要 为其定义 拷贝构造函数和拷贝赋值运算符,来拷贝 指针成员本身而不是它指向的string。我们的类 仍然需要自己的析构函数来释放接受 string参数的构造函数分配的内存。析构函数 不能单方面地释放关联的string。只有 当最后一个指向string的HasPtr销毁时,它才可以释放string
2、令一个类展现类似指针的行为的最好方法是使用shared_ptr 来管理类中的资源。拷贝(或赋值)一个shared_ptr会拷贝(赋值)shared_ptr所指向的指针。shared_ptr类 自己记录有多少用户共享它所指向的对象。当没有用户使用对象时,shared_ptr类负责释放资源
有时我们希望直接管理资源。使用引用计数就很有用了。将重新定义 HasPtr,令其行为像指针一样,但我们不使用 shared_ptr,而是 设计自己的引用计数
3、引用计数:
- 除了初始化对象外,每个构造函数(拷贝构造函数除外)还要创建一个引用计数,用来记录有多少对象 与正在创建的对象共享状态。当我们创建一个对象时,只有 一个对象共享状态,因此 将计数器初始化为1
- 拷贝构造函数 不分配新的计数器,而是拷贝 给定对象的数据成员,包括 计数器。拷贝构造函数 递增共享的计数器,指出给定对象的状态 又被一个新用户所共享
- 析构函数递减计数器,指出共享状态的用户少了一个。如果计数器变为0,则析构函数释放状态。
- 拷贝赋值运算符 递增右侧运算对象的计数器,递减左侧运算对象的计数器。如果左侧运算对象的计数器变为0,意味着它的共享状态没有用户了,拷贝赋值运算符就必须 销毁状态
计数器 不能直接作为 HasPtr对象的成员
HasPtr p1("Hiya!");
HasPtr p2(p1); //p1和p2指向相同的string
HasPtr p3(p1); //p1、p2和p3都指向相同的string
引用计数 保存在每个对象中,当创建p3时 我们应该如何正确更新它呢?可以递增p1中的计数器 并将其拷贝到p3中,但如何更新p2中的计数器呢
解决此问题的一种方法是 将计数器保存在动态内存中。当创建一个对象时,我们也分配 一个新的计数器。当拷贝或赋值对象时,我们拷贝 指向计数器的指针。使用这种方法 副本和原对象 都会指向相同的计数器
4、定义一个使用引用计数的类:
class HasPtr {
public:
//构造函数分配新的string和新的计数器,将计数器置为1
HasPtr(const string& s = string()):
sp(new string(s)), i(0), use(new size_t(1)) {}
//拷贝构造函数
HasPtr(const HasPtr& hp);
HasPtr& operator=(const HasPtr& hp);
HasPtr& operator=(const string& s);
string& operator*();
~HasPtr(); //用来记录有多少个对象共享*sp的成员
private:
string* sp;
int i;
size_t* use;
};
接受string参数的构造函数 分配新的计数器
5、类指针的拷贝成员“篡改”引用计数:当拷贝 或 赋值一个HasPtr对象时,我们希望副本和原对象都指向相同的string。即,当拷贝一个HasPtr时,我们将拷贝sp本身,而不是sp指向的string。当我们进行拷贝时,还会递增 该string关联的计数器
//拷贝构造函数拷贝所有三个数据成员,并递增计数器
HasPtr::HasPtr(const HasPtr& hp) {
sp = hp.sp;
i = hp.i;
use = hp.use;
++*use; // 不能写成*use++,后加加 优先级低
}
析构函数 不能无条件地delete sp —— 可能还有其他对象 指向这块内存。析构函数应该 递减引用计数,指出共享string的对象少了一个。如果 计数器变为0,则析构函数 释放sp和use指向的内存:
HasPtr::~HasPtr() {
if (--*use == 0) { // 如果引用计数变为 0再释放
delete use;
delete sp;
}
}
拷贝赋值运算符 与往常一样 执行类似 拷贝构造函数和析构函数的工作。即,它必须 递增右侧运算对象的引用计数(即,拷贝构造函数的工作),并 递减左侧运算对象的引用计数,在必要时 释放使用的内存(即,析构函数的工作)
赋值运算符 必须处理自赋值。我们通过 先递增rhs中的计数然后 再递减左侧运算对象中的计数 来实现这一点。通过这种方法(先增后减),当两个对象相同时,在我们检查sp(及use)是否应该释放之前,计数器就已经被递增过了
HasPtr& HasPtr::operator=(const HasPtr& hp) {
// 右侧增左侧减,先增后减
++*hp.use;
if (--*use == 0) {
delete use;
delete sp;
}
sp = hp.sp;
i = hp.i;
use = hp.use;
return *this;
}
引用计数版本的 HasPtr 完整定义
#include <iostream>
#include <string>
using namespace std;
class HasPtr {
public:
HasPtr(const string& s = string()):
sp(new string(s)), i(0), use(new size_t(1)) {}
HasPtr(const HasPtr& hp);
HasPtr& operator=(const HasPtr& hp);
HasPtr& operator=(const string& s);
string& operator*();
~HasPtr();
private:
string* sp;
int i;
size_t* use;
};
HasPtr::HasPtr(const HasPtr& hp) {
sp = hp.sp;
i = hp.i;
use = hp.use;
++*use; // 不能写成*use++,后加加 优先级低
}
HasPtr::~HasPtr() {
if (--*use == 0) { // 如果引用计数变为 0再释放
delete use;
delete sp;
}
}
HasPtr& HasPtr::operator=(const HasPtr& hp) {
// 右侧增左侧减,先增后减
++*hp.use;
if (--*use == 0) {
delete use;
delete sp;
}
sp = hp.sp;
i = hp.i;
use = hp.use;
return *this;
}
HasPtr& HasPtr::operator=(const string& s) {
*sp = s;
return *this;
}
string& HasPtr::operator*() {
return *sp;
}
int main()
{
HasPtr h1("hi mom");
HasPtr h2 = h1;
HasPtr h3(h1);
cout << *h1 << endl;
cout << *h2 << endl;
cout << *h3 << endl;
h2 = "hi dad";
// 展现共享
cout << *h1 << endl;
cout << *h2 << endl;
cout << *h3 << endl;
return 0;
}
运行结果
6、给定下面的类,为其实现一个默认构造函数和必要的拷贝控制成员
(a)
class TreeNode {
pravite:
std::string value;
int count;
TreeNode *left;
TreeNode *right;
};
(b)
class BinStrTree{
pravite:
TreeNode *root;
};
class TreeNode {
public:
TreeNode() : value(string()), count(new int(1)), left(nullptr), right(nullptr) { }
TreeNode(const TreeNode &rhs) : value(rhs.value), count(rhs.count), left(rhs.left), right(rhs.right) { ++*count; }
TreeNode& operator=(const TreeNode &rhs);
~TreeNode() {
if (--*count == 0) {
delete left;
delete right;
delete count;
}
}
private:
std::string value;
int *count;
TreeNode *left;
TreeNode *right;
};
TreeNode& TreeNode::operator=(const TreeNode &rhs)
{
++*rhs.count;
if (--*count == 0) {
delete left;
delete right;
delete count;
}
value = rhs.value;
left = rhs.left;
right = rhs.right;
count = rhs.count;
return *this;
}
class BinStrTree {
public:
BinStrTree() : root(new TreeNode()) { }
BinStrTree(const BinStrTree &bst) : root(new TreeNode(*bst.root)) { }
BinStrTree& operator=(const BinStrTree &bst);
~BinStrTree() { delete root; }
private:
TreeNode *root;
};
BinStrTree& BinStrTree::operator=(const BinStrTree &bst)
{
TreeNode *new_root = new TreeNode(*bst.root);
delete root;
root = new_root;
return *this;
}
3、交换操作
1、除了定义 拷贝控制成员,管理资源的类 通常还定义一个名为swap的函数。对于那些与 重排元素顺序的算法 一起使用
的类,定义swap是非常重要的。这类算法在需要 交换两个元素时会调用swap
交换两个类值HasPtr对象
HasPtr temp = v1; //创建v1的值的一个临时副本
v1 = v2; //将v2的值赋予vl
v2 = temp; //将保存的v1的值赋予v2
更希望swap交换指针,而不是分配string的新副本
string *temp = v1.sp; //为v1.sp中的指针创建一个副本
v1.sp = v2.sp; //将v2.sp中的指针赋予v1.sp
v2.sp = temp; //将保存的v1.sp中原来的指针赋子v2.sp
2、可以在 我们的类上 定义一个自己版本的swap 来重载swap的默认行为
class HasPtr {
friend void swap(HasPtr&, HasPtr&);
//其他成员定义,与之前一样
};
inline
void swap(HasPtr &lhs, HasPtr &rhs)
{
using std::swap;
swap(ihs.sp, rhs.sp); //交换指针,而不是string数据
swap(ihs.i, rhs.i); //交换int成员
}
由于swap的存在就是为了优化代码,我们将其声明为inline函数
与拷贝控制成员 不同,swap并不是必要的。但是,对于 分配了资源的类,定义swap 可能是一种很重要的优化手段
3、swap函数中 调用的swap不是std::swap。在本例中,数据成员 是内置类型的,而内置类型 是没有特定版本的swap的,所以在本例中,对swap的调用 会调用标准库std::swap
如果一个类的成员 有自己类型特定的swap函数,调用std::swap就是错误的了
void swap(Foo &lhs, Foo &rhs)
{
//错误:这个函数使用了标准库版本的swap,而不是HasPtr版本
std::swap(lhs.h, rhs.h);
//交换类型Foo的其他成员
}
问题在于 显式地调用了标准库版本的swap,正确的swap函数如下
void swap(Foo &lhs, Foo &rhs)
{
using std::swap;
swap(lhs.h, rhs.h); //使用HasPtr版本的swap
//交换类型Foo的其他成员
}
每个调用都应该是swap,而不是std::swap
如果存在 类型特定的swap版本,swap调用 会与之匹配。如果 不存在类型特定的版本,则会使用std中的版本(假定作用域中有using声明)
4、定义swap的类 通常用swap来定义它们的赋值运算符。这些运算符 使用了一种名为 拷贝并交换的技术。这种技术 将左侧运算对象 与 右侧运算对象的一个副本进行交换:
//注意rhs是 按值传递的,意味着HasPtr的拷贝构造函数
//将右侧运算对象中的string拷贝到rhs
HasPtr& Hasptr::operator=(HasPtr rhs)
{
//交换左侧运算对象和局部变量rhs的内容
swap(*this, rhs); //rhs现在指向本对象曾经使用的内存
return *this; //rhs被销毁,从而delete了rhs中的指针
}
rhs 是右侧运算对象的一个副本。参数传递时 拷贝HasPtr的操作 会分配该对象的string的一个新副本
*this中的指针成员 将指向新分配的string——右侧运算对象中 string的一个副本
当赋值运算符结束时,rhs被销毁,HasPtr的析构函数 将执行。此析构函数 delete rhs现在指向的内存,即,释放掉左侧运算对象中原来的内存
它自动处理了自赋值情况 且 天然就是异常安全的。它通过在改变左侧运算对象之前 拷贝右侧运算对象 保证了自赋值的正确,这与我们在原来的赋值运算符中 使用的方法是一致的(先增后减,先存入随机变量,再赋值)。它保证异常安全的方法也与原来
的赋值运算符实现一样
代码中唯一可能抛出异常的是 拷贝构造函数中的new表达式。如果真发生了异常,它也会在 我们改变左侧运算对象之前发生
使用拷贝和交换的赋值运算符 自动就是异常安全的,且 能正确处理自赋值
5、swap(HasPtr&, HasPtr&)中对 swap的调用不会导致递归循环:在此 swap 函数中 又调用了 swap 来交换 HasPtr 成员 ps 和 i。但这两个成员的类型 分别是指针和整型,都是内置类型,因此函数中的 swap 调用被解析为 std::swap,而不是 HasPtr 的特定版本 swap(也就是自身),所以不会导致递归循环
6、为你的 HasPtr 类定义一个 < 运算符,并定义一个 HasPtr 的 vector。为这个 vector 添加一些元素,并对它执行 sort。注意何时会调用 swap
#include <iostream>
using std::cout; using std::endl; using std::cin;
#include <fstream>
using std::ifstream;
#include <sstream>
using std::istringstream;
#include <string>
using std::string;
#include <vector>
using std::vector;
#include <algorithm>
class HasPtr {
public:
friend void swap(HasPtr&, HasPtr&);
HasPtr(const string& s = string()) : num(0), sp(new string(s)) {}
HasPtr(const HasPtr& h) : num(h.num), sp(new string(*(h.sp))) {}
HasPtr& operator=(const HasPtr& h);
HasPtr& operator=(const string& s) { *sp = s; return *this; }
string& operator*() { return *sp; }
bool operator<(HasPtr&); // 新定义
~HasPtr() { delete sp; }
private:
int num;
string* sp;
};
inline
void swap(HasPtr& h1, HasPtr& h2) { // 新定义
cout << "交换" << *h1.sp << "和" << *h2.sp << endl;
using std::swap;
swap(h1.sp, h2.sp);
swap(h1.num, h2.num);
}
bool HasPtr::operator<(HasPtr& hp) {
return *this->sp < *hp.sp; // this是指针
}
HasPtr& HasPtr::operator=(const HasPtr& h) {
string* ns = new string(*h.sp);
delete sp;
sp = ns;
num = h.num;
return *this;
}
int main()
{
vector<HasPtr> vec;
string line;
string word;
while (getline(cin, line)) {
istringstream iss(line); // 别忘了参数line
while (iss >> word) {
vec.push_back(word);
}
}
for (auto e : vec) {
cout << *e << " ";
}
cout << endl;
std::sort(vec.begin(), vec.end());
for (auto e : vec) {
cout << *e << " ";
}
return 0;
}
输入:
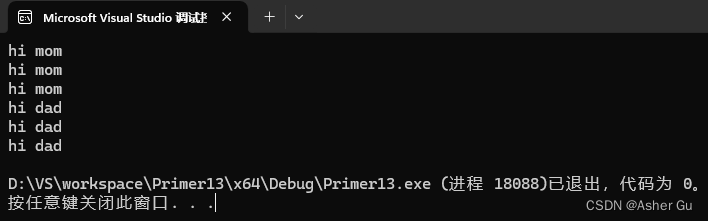
hello world c++ primer fifth
clion jetbrain apple
iphone
输出:
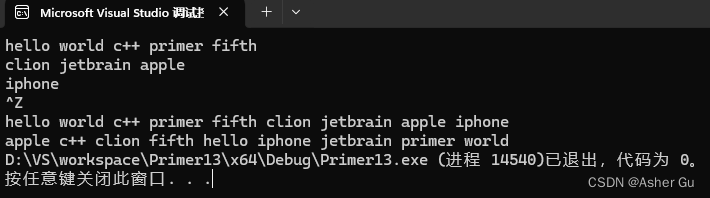
没有调用swap,网上调用 swap 的结果:
hello world c++ primer fifth clion jetbrain apple iphone
交换 hello 和 fifth
交换 world 和 apple
交换 primer 和 clion
交换 fifth 和 apple
交换 fifth 和 c++
交换 fifth 和 clion
交换 primer 和 jetbrain
交换 world 和 iphone
交换 primer 和 iphone
交换 jetbrain 和 iphone
apple c++ clion fifth hello iphone jetbrain primer world
Process finished with exit code 0
在 C++11 中引入了移动语义,即将资源(如动态分配的内存)的所有权从一个对象转移至另一个对象,而不是简单地进行拷贝。std::sort 在排序过程中会使用移动语义来优化元素的交换操作,因此不会直接调用自定义的 swap 函数
在你的 HasPtr 类中,你定义了拷贝构造函数和拷贝赋值运算符,但没有定义移动构造函数和移动赋值运算符。因此,std::sort 将使用默认的移动构造函数和移动赋值运算符来执行元素的移动操作,而不会直接调用你自定义的 swap 函数
7、类指针的 HasPtr 版本会从 swap 函数收益吗
默认 swap 版本(std::swap)简单交换两个对象(内置类型的对象)的非静态成员,对 HasPtr 而言,就是交换 string 指针 ps、引用计数指针 use 和整型值 i。可以看出,这种语义是符合期望的 —— 两个 HasPtr 指向了原来对方的 string,而两者互换 string 后,各自的引用计数本应该是不变的(都是减 1 再加 1)
因此,默认 swap 版本已经能正确处理类指针 HasPtr 的交换,专用 swap 版本(用户自定义的 swap)不会带来更多收益
4、拷贝控制示例
1、分配资源的类 更需要 拷贝控制,但资源管理 并不是一个类需要定义自己的拷贝控制成员的 唯一原因。一些类也需要拷贝控制成员的帮助来进行 簿记工作或其他操作
2、两个类命名为Message和Folder,分别表示电子邮件(或者其他类型的)消息和消息目录。每个Message对象可以出现在多个Folder中
任意给定的Message的内容只有一个副本。这样,如果一条Message的内容被改变,则我们从它所在的任何Folder来浏览此Message时,都会看到改变后的内容
为了记录Message位于哪些Folder中,每个Message都会保存一个它所在Folder的指针的set,同样的,每个Folder都保存一个它包含的Message的指针的set
Message类会提供 save和remove操作,来向一个给定Folder添加一条Message 或是 从中删除一条Message
拷贝一个 Message时,副本和原对象 将是不同的Message对象,但两个Message都出现在相同的Folder中。因此,拷贝Message的操作包括 消息内容 和 Folder指针set的拷贝。而且,我们必须在 每个包含此消息的Folder中 都添加一个指向新创建的Message的指针
销毁一个Message时,它将不复存在。因此,必须 从包含此消息的所有Folder中删除 指向此Message的指针
将一个Message对象 赋予 另一个Message对象时,左侧Message的内容会 被右侧Message的内容所替代。我们还必须更新Folder集合,从原来包含左侧Message的Folder中将它删除,并将它添加到 包含右侧Message的Folder中
3、拷贝赋值运算符通常执行考贝构造函数和析构函数中也要做的工作。这种情况下,公共的工作应该放在private的工具函数中完成
4、Folder类也需要类似的拷贝控制成员,来添加或删除它保存的Message
5、Message类:
class Folder;
class Message {
friend class Folder;
friend void swap(Message& lhs, Message& rhs);
public:
// folders被隐式初始化为空集合
explicit Message(const std::string& str = "") :
contents(str) {}
// 拷贝控制成员,用来管理指向本Message的指针
Message(const Message&); // 拷贝构造函数
Message& operator=(const Message&);// 拷贝赋值运算符
~Message(); // 析构函数
// 从给定的Folder集合中 添加/删除 本Message
void save(Folder&);
void remove(Folder&);
private:
std::string contents; // 实际消息文本
std::set<Folder*> folders; // 包含本Message的Folder
// 拷贝构造函数、拷贝赋值运算符 和 析构函数所使用的工具函数
// 将本Message添加到指向参数的Folder中
void add_to_Folders(const Message&);
// 从folders中的每个Folders中删除本Message
void remove_from_Folders();
};
这个类定义了 两个数据成员:contents,保存消息文本;folders,保存指向本Message所在Folder的指针
接受一个string参数的构造函数 将给定string拷贝给contents,并将folders(隐式)初始化为空集。由于此构造函数有一个默认参数,因此它也被当作 Message的默认构造函数
6、save和remove成员
Message类 只有两个公共成员:save,将本Message存放在 给定Folder中;remove,删除本Message
void Message::save(Folder &f)
{
folders.insert(&f); //将给定Folder添加到我们的Folder列表中
f.addMsg(this); //将本Message添加到f的Message集合中
}
void Message::remove(Folder &f)
{
folders.erase(&f); //将给定Folder从我们的Folder列表中删除
f.remMsg(this); //将本Message从f的Message集合中删除
}
当save一个Message时,我们应保存 一个指向给定Folder的指针;当remove 一个Message时,我们要删除此指针
还必须 更新给定的Folder。更新一个Folder的任务是 由Folder类的 addMsg 和 remMsg成员 来完成的,分别添加和删除给定Message的指针
为什么Message的成员save和remove的参数是一个 Folder&?为什么我们不能将参数定义为 Folder 或是 const Folder
首先,需要将给定 Folder 的指针 添加到当前 Message 的 folders 集合中。这样,参数类型就不能是 Folder,必须是引用类型。否则,调用 save 时会将实参拷贝给形参,folders.insert(&f); 添加的就是形参(与局部变量一样在栈中,save 执行完毕就被销毁)的指针,而非原始 Folder 的指针。而参数为引用类型,就可以令形参与实参指向相同的对象,对形参 f 取地址,得到的就是原始 Folder(实参)的指针
其次,我们需要调用 addMsg 将当前 Message 的指针添加到 Folder 的 message 集合中,这意味着我们修改了 Folder 的内容,因此参数不能是 const 的
7、Message类的拷贝控制成员:拷贝一个Message时,得到的副本 应该 与原Message出现在相同的Folder中。因此,我们必须 遍历Folder指针的set,对每个指向原Message的Folder添加 一个指向新Message的指针。拷贝构造函数 和 拷贝赋值运算符 都需要做这个工作,因此 我们定义一个函数来完成这个公共操作
// 将本Message添加到指向m的Folder中
void Message::add_to_Folders(const Message &m)
{
for(auto f : m.folders) //对每个包含m的Folder
f->addMsg(this); //向该Folder添加一个指向本Message的指针
}
函数addMsg 会将本Message的指针 添加到每个Folder中
Message的拷贝构造函数 拷贝给定对象的数据成员
Message::Message(const Message &m):
contents(m.contents), folders(m.folders)
{
add_to_Folders(m); //将本消息添加到指向m的Folder中
}
8、Message的析构函数:
当一个Message被销毁时,我们必须 从指向此Message的Folder中删除它。拷贝赋值运算符 也要执行此操作,因此我们会定义一个公共函数来完成此工作
// 从对应的Folder中删除Message
void Message::remove_from_Folders()
{
for (auto f : folders)
f->remMsg(this);
}
有了remove_from_Folders函数,编写析构函数就很简单了
// 通过remove_from_Folders函数构造析构函数
Message::~Message()
{
remove_from_Folders();
}
调用 remove_from_Folders 确保没有任何Folder保存 正在销毁的Message的指针。编译器自动调用 string的析构函数来释放contents,并自动调用set的析构函数来 清理集合成员使用的内存
9、Message的拷贝赋值运算符:最重要的是 要组织好代码结构,使得即使左侧和右侧运算对象 是同一个Message,拷贝赋值运算符 也能正确执行(先删再加,不然 自赋值后删的话 把加进去的也删了)
// Message的拷贝赋值运算符
Message& Message::operator=(const Message& rhs) {
// 通过先删除指针再插入它们来处理自赋值情况
remove_from_Folders();
contents = rhs.contents;
folders = rhs.folders;
add_to_Folders(rhs);
return *this;
}
如果左侧和右侧运算对象 是相同的Message,则它们具有相同的地址。如果我们在 add_to_Folders 之后调用 remove_from _Folders,就会将此Message 从它所在的所有Folder中删除
10、Message的swap函数:标准库中定义了 string和set的swap版本。通过定义一个 Message特定版本的swap(引用的版本,而不是值传递),我们可以避免 对contents和folders成员进行不必要的拷贝
swap函数必须管理指向被交换Message的Folder指针
通过两遍扫描folders中每个成员 来正确处理Folder指针。第一遍扫描 将Message从它们所在的Folder中删除。接下来我们调用swap来交换数据成员。最后 对folders进行第二遍扫描 来添加交换过的Message:
void swap(Message& lhs, Message& rhs) {
using std::swap; // 严格来说不需要,但是是一个好习惯,没用标准库的swap
// 将每个消息的指针从它(原来)所在的Folder中删除
for (auto f : lhs.folders)
f->remMsg(&lhs);
for (auto f : rhs.folders)
f->remMsg(&rhs);
// 交换contents和Folder指针set
swap(lhs.folders, rhs.folders); // swap(set&, set&)
swap(lhs.contents, rhs.contents); // swap(string&, string&)
// 将每个Message的指针添加到它的新Folder中
for (auto f : lhs.folders)
f->addMsg(&lhs);
for (auto f : rhs.folders)
f->addMsg(&rhs);
}
11、完整的Message定义和使用
Folder.h
#ifndef FOLDER_H
#define FOLDER_H
#include <iostream>
#include <string>
#include <set>
class Folder;
class Message {
friend class Folder;
friend void swap(Message& lhs, Message& rhs);
public:
// folders被隐式初始化为空集合
explicit Message(const std::string& str = "") :
contents(str) {}
// 拷贝控制成员,用来管理指向本Message的指针
Message(const Message&); // 拷贝构造函数
Message& operator=(const Message&);// 拷贝赋值运算符
~Message(); // 析构函数
// 从给定的Folder集合中 添加/删除 本Message
void save(Folder&);
void remove(Folder&);
private:
std::string contents; // 实际消息文本
std::set<Folder*> folders; // 包含本Message的Folder
// 拷贝构造函数、拷贝赋值运算符 和 析构函数所使用的工具函数
// 将本Message添加到指向参数的Folder中
void add_to_Folders(const Message&);
// 从folders中的每个Folders中删除本Message
void remove_from_Folders();
};
void swap(Message& lhs, Message& rhs);
class Folder {
friend class Message;
friend void swap(Message& lhs, Message& rhs);
public:
void debug_print();
private:
std::set<Message*> msgs;
void addMsg(Message* m);
void remMsg(Message* m);
};
#endif
Folder.cpp
#include "Folder.h"
using namespace std;
void Message::save(Folder& f) {
folders.insert(&f); // 将给定的Folder添加到Folder列表中,必须加&
f.addMsg(this); // 将本Message添加到f的Message集合中
}
void Message::remove(Folder& f) {
folders.erase(&f); // 将给定Folder从Message的Folders列表中删除
f.remMsg(this); // 将本Message从f的Message集合中删除
}
// 将本Message添加到指向m的Folder中
void Message::add_to_Folders(const Message& m)
{
for (auto f : m.folders) // 对每个包含m的Folder
f->addMsg(this); // 向该Folder中添加一个指向本Message的指针
}
// 从对应的Folder中删除Message
void Message::remove_from_Folders()
{
for (auto f : folders)
f->remMsg(this);
}
// 通过remove_from_Folders函数构造析构函数
Message::~Message()
{
remove_from_Folders();
}
// Message的构造拷贝函数拷贝给定对象的数据成员
Message::Message(const Message& m) :
contents(m.contents), folders(m.folders)
{
add_to_Folders(m);
}
// Message的拷贝赋值运算符
Message& Message::operator=(const Message& rhs) {
// 通过先删除指针再插入它们来处理自赋值情况
remove_from_Folders();
contents = rhs.contents;
folders = rhs.folders;
add_to_Folders(rhs);
return *this;
}
void swap(Message& lhs, Message& rhs) {
using std::swap; // 严格来说不需要,但是是一个好习惯,没用标准库的swap
// 将每个消息的指针从它(原来)所在的Folder中删除
for (auto f : lhs.folders)
f->remMsg(&lhs);
for (auto f : rhs.folders)
f->remMsg(&rhs);
// 交换contents和Folder指针set
swap(lhs.folders, rhs.folders); // swap(set&, set&)
swap(lhs.contents, rhs.contents); // swap(string&, string&)
// 将每个Message的指针添加到它的新Folder中
for (auto f : lhs.folders)
f->addMsg(&lhs);
for (auto f : rhs.folders)
f->addMsg(&rhs);
}
void Folder::debug_print() {
cout << "Folder: ";
for (auto a : this->msgs) {
cout << a->contents << " ";
}
cout << endl;
}
void Folder::addMsg(Message* m) {
msgs.insert(m);
}
void Folder::remMsg(Message* m) {
msgs.erase(m);
}
13.34.cpp
#include "Folder.h"
int main()
{
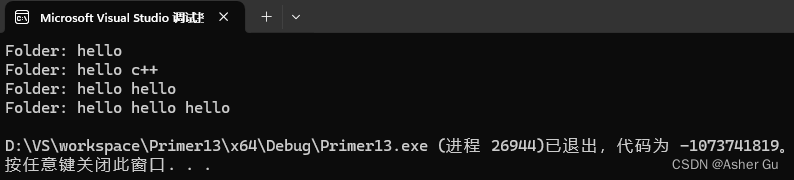
Message oneMail("hello");
Message twoMail("c++");
Folder mail;
oneMail.save(mail);
mail.debug_print();
twoMail.save(mail);
mail.debug_print();
twoMail = oneMail;
mail.debug_print();
Message threeMail = twoMail;
mail.debug_print();
return 0;
}
运行结果
如果Message 使用合成的拷贝控制成员,将会发生什么
Message 类包含两个数据成员:content 为 string 类型,folders 为 set。这两个标准库类都有完备的拷贝控制成员,因此 Message 使用合成的拷贝控制成员的话,简单拷贝这两个成员也能实现正确拷贝
当拷贝 Message 时,不仅要拷贝这个 Message 在哪些 Folder 中,还要将 Message 加到每个 Folder 中 —— 调用 addMsg
类似的,当销毁 Message 时,需要将它从所有 Folder 中删除 —— 调用 remMsg
因此,不能依赖合成的拷贝控制成员,必须设计自己的版本来完成这些薄记工作
12、未使用拷贝交换方式来设计 Message 的赋值运算符。你认为其原因是什么
如果采用拷贝并交换方式,执行过程是这样:
1)由于赋值运算符的参数是 Message 类型,因此会将实参拷贝给形参 rhs,这会触发拷贝构造函数,将实参的 contents 和 folders 拷贝给 rhs,并调用 add_to_Folders 将 rhs 添加到 folders 的所有文件夹中
2)随后赋值运算符调用 swap 交换 *this 和 rhs,首先遍历两者的 folders,将它们从自己的文件夹中删除;然后调用 string 和 set 的 swap 交换它们的 contents 和 folders;最后,再遍历两者新的 folders,将它们分别添加到自己的新文件夹中
3)最后,赋值运算符结束,rhs 被销毁,析构函数调用 remove_from_Folders 将 rhs 从自己的所有文件夹中删除
显然,语义是正确的,达到了预期目的。但效率低下,rhs 创建、销毁并两次添加、删除是无意义的。而采用拷贝赋值运算符的标准编写方式,形参 rhs 为引用类型,就能避免这些冗余操作
5、动态内存管理类
1、某些类 需要在运行时 分配可变大小的内存空间。这种类通常可以 使用标准库容器来保存它们的数据
例如,我们的StrBlob类使用一个vector 来管理其元素的底层内存
2、某些类 需要自己进行内存分配。这些类一般来说 必须定义自己的拷贝控制成员 来管理所分配的内存
将实现标准库vector类的一个简化版本。我们所做的一个简化是不使用模板,我们的类 只用于string。因此,它被命名为StrVec
3、StrVec类的设计:
为了获得可接受的性能,vector 预先分配足够的内存 来保存可能需要的更多元素。vector的每个添加元素的成员函数 会检查 是否有空间容纳更多的元素。如果有,成员函数会在下一个可用位置 构造一个对象。如果没有可用空间,vector 就会重新分配空间:它获得新的空间,将已有元素 移动到新空间中,释放旧空间,并添加新元素
将使用一个allocator 来获得原始内存。由于allocator分配的内存 是未构造的,我们将在 需要添加新元素时 用allocator的construct成员 在原始内存中创建对象。类似的,当我们 需要删除一个元素时,我们将 使用destroy成员来销毁元素
每个StrVec有三个指针成员指向其元素所使用的内存:
- elements,指向分配的内存中的首元素
- first_free,指向最后一个实际元素之后的位置
- cap,指向分配的内存末尾之后的位置

除了这些指针之外,StrVec 还有一个名为 alloc 的静态成员,其类型为 allocator<string>。alloc成员 会分配StrVec使用的内存
类还有4个工具函数:
- alloc_n_copy 会分配内存,并拷贝 一个给定范围中的元素
- free 会销毁构造的元素 并释放内存
- chk_n_alloc 保证 StrVec 至少有容纳一个新元素的空间。如果没有空间添加新元素,chk_n_alloc 会调用 reallocate 来分配更多内存
- reallocate 在内存用完时 为 StrVec 分配新内存
4、StrVec类定义:
#include <string>
#include <memory>
class StrVec {
public:
StrVec() : // allocator成员进行默认初始化
elements(nullptr), first_free(nullptr), cap(nullptr) {}
StrVec(const StrVec&); // 拷贝构造函数
StrVec& operator=(const StrVec&); // 拷贝赋值运算符
~StrVec();// 析构函数
void push_back(const std::string&); // 拷贝元素
size_t size() const { return first_free - elements; }
size_t capacity() const { return cap - elements; }
std::string* begin() const { return elements; }
std::string* end() const { return first_free; }
void reserve(size_t n); // 预留一部分空间
void resize(size_t n); // 改变大小
void resize(size_t n, const std::string& s);
StrVec(std::initializer_list<std::string>);
private:
static std::allocator<std::string> alloc; // 分配元素
void chk_n_alloc(); // 确保有空间容纳新元素
std::pair<std::string*, std::string*> alloc_n_copy(const std::string*, const std::string*); // 将指定值复制
void free(); // 销毁元素并释放内存
void reallocate(); // 获取更多内存并拷贝已有元素
std::string* elements; // 指向数组首元素的指针
std::string* first_free; // 指向数组第一个空闲元素的指针
std::string* cap; // 指向数组尾后位置的指针
};
5、使用 construct
函数 push_back 调用 chk_n_alloc 确保有空间容纳新元素。如果需要,chk_n_alloc 会调用 reallocate。当 chk_n_alloc 返回时,push_back 知道 必有空间容纳新元素。它要求 其 allocator成员 来construct新的尾元素
void StrVec::push_back(const string& s) {
chk_n_alloc(); // 确保有空间容纳新元素
// 在first_free指向的元素中构造s的副本
alloc.construct(first_free++, s);
}
用 allocator分配内存时,必须记住 内存是未构造的。为了使用此原始内存,我们必须调用 construct,在此内存中 构造一个对象。传递给 construct的第一个参数 必须是一个指针,指向调用allocate所分配的 未构造的内存空间。剩余参数确定用哪个构造函数来构造对象。只有一个额外参数,类型为string,因此会使用string的拷贝构造函数
6、alloc_n_copy成员:StrVec类 有类值的行为。当我们拷贝或赋值 StrVec 时,必须分配 独立的内存,并从原 StrVec对象 拷贝元素至新对象
alloc_n copy成员 会分配足够的内存 来保存给定范围的元素,并将这些元素拷贝 到新分配的内存中。此函数返回一个指针的pair,两个指针 分别指向新空间的开始位置 和 拷贝的尾后的位置
pair<string*, string*> StrVec::alloc_n_copy(const string* b, const string* e)
{
// 分配空间保存给定范围中的元素
auto data = alloc.allocate(e - b);
// 初始化并返回一个pair,该pair由data和uninitialized_copy的返回值构成
return { data, uninitialized_copy(b, e, data) };
}
7、free成员:free成员 有两个责任:首先 destroy元素,然后释放 StrVec自己分配的内存空间
void StrVec::free()
{
// 不能传递给deallocate一个空指针,如果element为空指针,函数什么也不做
if (elements) {
// 逆序销毁旧元素
for (auto p = first_free; p != elements;)
alloc.destroy(--p); // destroy与construct对应
alloc.deallocate(elements, cap - elements); // deallocate和allocate对应
}
}
destroy和deallocate通常与动态分配的内存相关
destroy通常用于对象的析构过程。当您使用动态内存分配(例如new)创建对象时,您需要在对象不再需要时调用delete来手动释放内存,并调用对象的析构函数来执行清理工作。这个清理工作包括释放对象持有的资源、关闭文件、解除关联的内存等。在C++标准库中,有一个名为std::destroy的算法,用于调用对象的析构函数,但通常在使用智能指针时,您不需要手动调用它,因为它们会自动处理对象的析构
deallocate通常与内存分配器相关,用于释放先前通过内存分配器分配的内存块。在C++中,使用new和delete进行动态内存分配和释放。但在高级用法中,您可能会使用自定义的内存分配器,这时您可能会使用deallocate来手动释放先前分配的内存块。在STL中,std::allocator类是用于分配和释放内存块的默认分配器,它有一个名为deallocate的成员函数,用于释放先前分配的内存块
总之,destroy和deallocate都是与内存管理相关的操作,分别用于对象的析构和释放先前分配的内存块。在日常编程中,通常您会更多地使用delete来释放对象和内存,而不是直接调用destroy或deallocate
8、拷贝控制成员:拷贝构造函数 调用alloc_n_copy
StrVec::StrVec(const StrVec& s)
{
// 调用alloc_n_copy分配空间以容纳与s中一样多的元素
auto newdata = alloc_n_copy(s.begin(), s.end());
elements = newdata.first;
first_free = newdata.second;
cap = newdata.second;
}
9、析构函数调用free:StrVec::~StrVec() { free(); }
10、拷贝赋值运算符 在释放已有元素之前 调用 alloc_n_copy,这样就可以 正确处理自赋值了, 防止 free了data所指的范围
StrVec& StrVec::operator=(const StrVec& rhs)
{
// 调用alloc_n_copy分配内存复制内容,大小和rhs中元素占用空间一样多
auto data = alloc_n_copy(rhs.begin(), rhs.end());
free();
elements = data.first;
first_free = data.second;
cap = data.second;
return *this;
}
11、在重新分配内存的过程中 移动而不是拷贝元素:编写reallocate成员函数
- 为一个新的、更大的string数组分配内存
- 在内存空间的前一部分构造对象,保存现有元素
- 销毁原内存空间中的元素,并释放这块内存
为一个StrVec 重新分配内存空间 会引起 从旧内存空间到新内存空间 逐个拷贝string。string具有 类值行为。当拷贝一个string时,新string和原string是相互独立的。改变 原string不会影响到副本,反之亦然
每个string对构成它的所有字符 都会保存自己的一份副本。拷贝一个string 必须为这些字符分配内存空间,而销毁一个 string 必须 释放所占用的内存
一旦将元素从旧空间拷贝到了新空间,我们就会 立即销毁原string
拷贝这些string中的数据 是多余的。在重新分配内存空间时,如果我们能避免 分配和释放string的额外开销,StrVec的性能会好得多
12、移动构造函数 和 std:move:过使用新标准库 引入的两种机制,我们就可以避免string的拷贝。移动构造函数通常是将资源从给定对象“移动” 而不是拷贝到正在创建的对象
而且我们知道 标准库保证“移后源” string仍然保持一个有效的、可析构的状态。对于string,我们可以想象每个string都有一个指向char数组的指针。可以假定 string的移动构造函数进行了 指针的拷贝,而不是 为字符分配内存空间然后拷贝字符
第二个机制是 一个名为move的标准库函数,它定义在utility头文件中
关于move我们需要了解两个关键点。首先,当reallocate.在新内存中构造string时,它必须调用 move来表示 希望使用string的移动构造函数。如果它漏掉了 move调用,将会使用 string的拷贝构造函数。其次,我们通常 不为move提供一个using声明。当我们使用move时,直接调用std::move而不是move
std::move 是 C++11 引入的一个标准库函数,用于将对象转换为右值引用(&&),从而支持移动语义。移动语义允许对象的资源(如动态分配的内存、文件句柄等)在传递所有权时被“移动”而不是“复制”,从而提高程序的性能
#include <iostream>
#include <vector>
class MyObject {
public:
MyObject() { std::cout << "Constructor" << std::endl; }
~MyObject() { std::cout << "Destructor" << std::endl; }
MyObject(const MyObject&) { std::cout << "Copy constructor" << std::endl; }
MyObject& operator=(const MyObject&) { std::cout << "Copy assignment operator" << std::endl; return *this; }
MyObject(MyObject&&) noexcept { std::cout << "Move constructor" << std::endl; }
MyObject& operator=(MyObject&&) noexcept { std::cout << "Move assignment operator" << std::endl; return *this; }
};
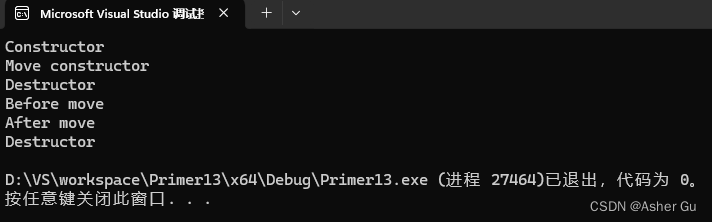
int main() {
std::vector<MyObject> vec1;
vec1.push_back(MyObject()); // 构造一个临时对象并移动到容器中
std::cout << "Before move" << std::endl;
std::vector<MyObject> vec2 = std::move(vec1); // 使用std::move移动vec1中的对象到vec2
std::cout << "After move" << std::endl;
return 0;
}
运行结果
MyObject&& 是右值引用类型的声明语法,用于声明一个右值引用
在这段代码中,vec1.push_back(MyObject()); 调用了移动构造函数 MyObject(MyObject&&) 而不是拷贝构造函数 MyObject(const MyObject&) 的原因是因为 MyObject() 创建的对象是一个临时对象,是一个右值
在 C++ 中,当你传递一个临时对象(右值)给函数时,编译器会尝试使用移动语义,以避免不必要的对象拷贝。因此,在 push_back 函数中,std::vector 会尝试移动这个临时对象到容器中,而不是拷贝它
在 C++ 中,表达式可以分为几种不同的值类别:
左值(lvalue):指向内存位置的表达式,具有持久性,可以取地址
右值(rvalue):指的是临时对象、字面量常量、函数返回值等没有持久性的表达式,通常表示一个可以移动或传递的临时值。右值是指临时创建的、即将销毁的对象
纯右值(pure rvalue):是指没有被绑定到左值引用的右值
#include <iostream>
class MyObject {
public:
MyObject() { std::cout << "Constructor" << std::endl; }
~MyObject() { std::cout << "Destructor" << std::endl; }
MyObject(const MyObject&) { std::cout << "Copy constructor" << std::endl; }
MyObject(MyObject&&) noexcept { std::cout << "Move constructor" << std::endl; }
};
MyObject createObject() {
return MyObject(); // 返回一个临时对象
}
int main() {
MyObject&& rvalueRef = createObject(); // 使用右值引用捕获临时对象
return 0;
}
13、reallocate成员:每次重新分配内存时都会将StrVec的容量加倍。如果StrVec为空,我们将分配容纳一个元素的空间
void StrVec::reallocate()
{
// 分配当前大小两倍的内存空间,0的话为1
auto newcapacity = size() ? 2 * size() : 1;
// 分配新内存
auto newdata = alloc.allocate(newcapacity);
// 将数据从旧内存移动到新内存
auto dest = newdata; // 新数据的开头
auto elem = elements;// 旧数据的开头
for (size_t i = 0; i != size(); ++i)
alloc.construct(dest++, std::move(*elem++));
free(); // 释放旧内存(即等号左边的)空间
// 更新数据成员
elements = newdata;
first_free = dest;
cap = elements + newcapacity;
}
construct的第二个参数(即,确定使用哪个构造函数的参数)是move返回的值。调用move返回的结果 会令construct使用string的移动构造函数。由于我们使用了 移动构造函数,这些string管理的内存 将不会被拷贝。相反,我们构造的每个string都会从el em指向的string那里 接管内存的所有权
在元素移动完毕后,我们调用free销毁旧元素并释放 StrVec 原来使用的内存
14、完整StrVec实现,同时给 StrVec 类添加一个构造函数,它接受一个 initializer_list 参数
std::allocator<std::string> StrVec::alloc;
缺少成员定义:在 StrVec 类中声明了一个静态成员变量 alloc,但没有在类的实现文件(例如.cpp 文件)中定义它
在C++中,对于静态数据成员,需要在类的实现文件中进行定义,以分配内存空间
StrVec.h
#include <string>
#include <memory>
class StrVec {
public:
StrVec() : // allocator成员进行默认初始化
elements(nullptr), first_free(nullptr), cap(nullptr) {}
StrVec(const StrVec&); // 拷贝构造函数
StrVec& operator=(const StrVec&); // 拷贝赋值运算符
~StrVec();// 析构函数
void push_back(const std::string&); // 拷贝元素
size_t size() const { return first_free - elements; }
size_t capacity() const { return cap - elements; }
std::string* begin() const { return elements; }
std::string* end() const { return first_free; }
void reserve(size_t n); // 预留一部分空间
void resize(size_t n); // 改变大小
void resize(size_t n, const std::string& s);
StrVec(std::initializer_list<std::string>);
private:
static std::allocator<std::string> alloc; // 分配元素
void chk_n_alloc(); // 确保有空间容纳新元素
std::pair<std::string*, std::string*> alloc_n_copy(const std::string*, const std::string*); // 将指定值复制
void free(); // 销毁元素并释放内存
void reallocate(); // 获取更多内存并拷贝已有元素
std::string* elements; // 指向数组首元素的指针
std::string* first_free; // 指向数组第一个空闲元素的指针
std::string* cap; // 指向数组尾后位置的指针
};
StrVec.cpp
#include "StrVec.h"
using namespace std;
std::allocator<std::string> StrVec::alloc;
// 缺少成员定义:在 StrVec 类中声明了一个静态成员变量 alloc,但没有在类的实现文件(例如.cpp 文件)中定义它
// 在C++中,对于静态数据成员,需要在类的实现文件中进行定义,以分配内存空间
void StrVec::chk_n_alloc()
{
if (size() == capacity())
reallocate();
}
void StrVec::push_back(const string& s) {
chk_n_alloc(); // 确保有空间容纳新元素
// 在first_free指向的元素中构造s的副本
alloc.construct(first_free++, s);
}
pair<string*, string*> StrVec::alloc_n_copy(const string* b, const string* e)
{
// 分配空间保存给定范围中的元素
auto data = alloc.allocate(e - b);
// 初始化并返回一个pair,该pair由data和uninitialized_copy的返回值构成
return { data, uninitialized_copy(b, e, data) };
}
void StrVec::free()
{
// 不能传递给deallocate一个空指针,如果element为空指针,函数什么也不做
if (elements) {
// 逆序销毁旧元素
for (auto p = first_free; p != elements;)
alloc.destroy(--p);
alloc.deallocate(elements, cap - elements);
}
}
StrVec::StrVec(const StrVec& s)
{
// 调用alloc_n_copy分配空间以容纳与s中一样多的元素
auto newdata = alloc_n_copy(s.begin(), s.end());
elements = newdata.first;
first_free = newdata.second;
cap = newdata.second;
}
StrVec::~StrVec() { free(); }
StrVec& StrVec::operator=(const StrVec& rhs)
{
// 调用alloc_n_copy分配内存复制内容,大小和rhs中元素占用空间一样多
auto data = alloc_n_copy(rhs.begin(), rhs.end());
free();
elements = data.first;
first_free = data.second;
cap = data.second;
return *this;
}
void StrVec::reallocate()
{
// 分配当前大小两倍的内存空间,0的话为1
auto newcapacity = size() ? 2 * size() : 1;
// 分配新内存
auto newdata = alloc.allocate(newcapacity);
// 将数据从旧内存移动到新内存
auto dest = newdata; // 新数据的开头
auto elem = elements;// 旧数据的开头
for (size_t i = 0; i != size(); ++i)
alloc.construct(dest++, std::move(*elem++));
free(); // 释放旧内存(即等号左边的)空间
// 更新数据成员
elements = newdata;
first_free = dest;
cap = elements + newcapacity;
}
void StrVec::reserve(size_t n) {
if (size() < n) {
reallocate();
}
}
void StrVec::resize(size_t n) {
resize(n, std::string());
}
void StrVec::resize(size_t n, const string& s)
{
if (size() > n) {
while (first_free != elements + n) {
alloc.destroy(--first_free);
}
alloc.destroy(first_free);
}
else {
while (size() < n) {
push_back(s);
}
}
}
StrVec::StrVec(std::initializer_list<std::string> il) {
// 调用 alloc_n_copy 分配与列表 il 中元素数目一样多的空间
auto newdata = alloc_n_copy(il.begin(), il.end());
elements = newdata.first;
first_free = newdata.second;
cap = newdata.second;
}
15、在之前的 TextQuery 和 QueryResult 类中用你的 StrVec 类代替vector,以此来测试你的 StrVec 类
StrVec.h 和 StrVec.cpp 不做任何修改;对 Query.h 做修改:用 StrVec 替换 vector<string>;由于类的封装特性,主程序不用进行任何修改
Query.h
#ifndef QUERY_H
#define QUERY_H
#include <string>
#include <iostream>
#include <fstream>
#include <sstream>
#include <set>
#include <map>
#include <algorithm>
#include <memory>
#include "StrVec.h" // 新加,把vector<string>改成StrVec
class QueryResult;
class TextQuery {
public:
friend class QueryResult;
TextQuery(std::ifstream& ifs);
QueryResult query(std::string& word);
private:
std::shared_ptr<StrVec> vec;
std::map<std::string, std::shared_ptr<std::set<int>>> m; // value也需要std::shared_ptr
};
class QueryResult {
public:
QueryResult(std::string s, std::shared_ptr<std::set<int>> l, std::shared_ptr<StrVec> v) :word(s), lines(l), vec(v) {}
void print();
private:
std::shared_ptr<StrVec> vec;
std::string word;
std::shared_ptr<std::set<int>> lines;
};
TextQuery::TextQuery(std::ifstream& ifs) :vec(new StrVec) // new的那个vector被shared_ptr管理了
{
std::string s;
while (getline(ifs, s)) {
std::istringstream iss(s);
std::string str;
vec->push_back(s);
int lineNo = vec->size();
while (iss >> str) {
std::string str_after;
std::copy_if(str.begin(), str.end(), std::back_inserter(str_after), isalpha);
if (m.find(str_after) == m.end()) {
m[str_after].reset(new std::set<int>); // shared_ptr用法
}
m[str_after]->insert(lineNo);
}
}
}
QueryResult TextQuery::query(std::string& word) {
std::shared_ptr<std::set<int>> emp(new std::set<int>); // new的那个set被shared_ptr管理了
if (m.find(word) == m.end())
return QueryResult(word, emp, vec);
else
return QueryResult(word, m[word], vec);
}
void QueryResult::print()
{
std::cout << word << " occurs " << lines->size() << " times" << std::endl;
int t = lines->size();
for (int i : *lines)
{
std::cout << "(line " << i << ") " << *(vec->begin() + i - 1) << std::endl;
}
}
#endif
13.42.cpp
#include "Query.h"
using namespace std;
void runQueries(ifstream& ifs) {
TextQuery tq(ifs);
while (true) {
cout << "enter word to look for, or q to quit: ";
string s;
if (!(cin >> s) || s == "q")
break;
QueryResult qr = tq.query(s);
qr.print();
}
}
int main()
{
ifstream ifs("data_27.txt");
runQueries(ifs);
return 0;
}
运行结果

16、重写 free 成员,用 for_each 和 lambda 来代替 for 循环 destroy 元素
elements 和 first_free 是 string* 类型,因此它们指出的范围中的元素是 string 类型。因此,lambda 的参数 s 应该是 string& 类型,在 lambda 的函数体中应该取 s 的地址,用来调用 destroy
void StrVec::free() {
// 不能传递给 deallocate 一个空指针,如果 elements 为 0,函数什么也不做
if (elements) {
// // 逆序销毁旧元素
// for (auto p = first_free; p != elements; /* 空 */)
// alloc.destroy(--p);
for_each(elements, first_free, [this] (string &s) { alloc.destroy(&s); });
alloc.deallocate(elements, cap - elements);
}
}
当你在类的成员函数中 使用 lambda 表达式,并且需要 访问该类的成员变量 或 成员函数时,通常需要 捕获 this 指针。这是因为类成员 不是在全局作用域中,所以 不能直接在没有任何上下文的 lambda 中直接访问
alloc 是 StrVec 类的一个私有成员变量,由于 alloc 是类的成员,如果想在 lambda 表达式内部调用它的 destroy() 方法,就必须捕获 this 指针
for_each(elements, first_free, [this] (string &s) { alloc.destroy(&s); });
这里的 [this] 捕获列表表示 lambda 表达式内部可以使用当前对象的 this 指针,从而可以访问包括 alloc 在内的所有成员变量和函数
在 C++11 引入的早期实现中,this 需要明确通过 [this] 捕获才能在 lambda 表达式中使用类成员。然而,从 C++17 开始,可以直接在 lambda 中使用 *this 来捕获当前对象的副本,这样做可以避免一些因为 this 指针悬挂 导致的问题
如果在你的环境中,没有明确捕获 [this] 或 [*this] 也能正确编译和运行,那可能是因为编译器进行了优化或者默认捕获了 this 指针。这不是标准行为,而可能是特定编译器的扩展或者配置
17、编写标准库 string 类的简化版本,命名为 String。你的类应该至少有一个默认构造函数 和 一个接受 C 风格字符串指针参数的构造函数。使用 allocator 为你的 String类分配所需内存
const char *begin() { return p; }
const char *begin() const { return p; }
const char *end() { return p + sz; }
const char *end() const { return p + sz; }
为什么要定义 const和非const两种情况
这种重载模式常见于实现自定义的迭代器或者容器类时。这里的目的是允许对象在 const 上下文中进行迭代操作,通过定义这样一对重载函数,你能够更好地支持对于 const 对象和非 const 对象的迭代操作
1)非 const 版本的 begin() 和 end():
begin() 和 end() 返回一个指向对象的起始和结束的指针
非 const 版本 用于对象 可以被修改的情况。例如,当你有一个对象 并且可以修改它时,你可能希望能够使用非 const 版本的 begin() 和 end() 来遍历并修改其中的内容
2)const 版本的 begin() 和 end():
begin() const 和 end() const 也返回 一个指向对象的起始和结束的指针。
const 版本 用于当对象 被声明为 const 时使用。在这种情况下,对象被认为是 只读的,因此只允许使用 const 成员函数 来访问它们。这意味着 只能调用 const 成员函数,并且 不能修改对象的内容。因此,const 版本的 begin() 和 end() 允许在只读的上下文中对对象进行迭代,而不会改变它们的状态
ostream &operator<<(ostream &os, const String &s) {
return print(os, s);
}
为什么不写成类函数(本题功能上没有区别)
通常来说,对于一元和二元运算符 重载函数,最好将它们定义为类的成员函数,因为这样更符合面向对象的思想,使得代码更加清晰和直观。但是,有时为了提高代码的灵活性和可扩展性,也可以将它们定义为友元函数
运算符重载函数可以定义为类成员函数,也可以定义为全局函数。对于 operator<< 这样的输出流运算符,通常更适合定义为全局函数,而不是类成员函数
1)对称性和可扩展性:运算符重载函数 通常 应该具有对称性。如果你将 operator<< 定义为 类成员函数,那么它将 只能接受一个参数(右操作数),这会限制它的使用。通过 定义为全局函数,你可以为输出流运算符 提供更多的灵活性和可扩展性,例如可以定义 多个不同的输出格式,而不必 修改类的定义
2)可访问性:全局运算符重载函数可以访问类的 public 和 protected 成员,所以通常你不必将其作为类的友元。相反,如果你将其定义为类的成员函数,可能需要将一些私有成员声明为友元,这会增加代码的复杂性
3)一致性:将常用的运算符重载函数(如 operator<< 和 operator>>)定义为全局函数可以提高代码的一致性。这是因为这些函数通常与标准库的其他操作符重载函数相似,比如 std::ostream 中的输出运算符重载函数就是全局函数
4)可读性和可维护性:将运算符重载函数 定义为全局函数 可以提高代码的可读性和可维护性。这样可以使代码更容易理解,因为它们 在类的外部定义,不会干扰 类的接口和实现
为什么要把std::allocator<char> a设为static,为什么还要设成类成员,设成全局变量行吗
std::allocator<char> a 被声明为 String 类的一个静态成员变量。将其声明为静态成员变量的主要原因有两个:
1)共享内存资源: std::allocator 负责分配和释放内存,将其设为静态成员变量意味着所有 String 类的对象共享同一个 allocator 对象。这样做可以确保在多个 String 对象之间共享内存资源,并减少内存分配和释放的开销。如果每个 String 对象都有自己的 allocator 对象,会导致内存碎片化和额外的开销
2)一致的内存管理: 由于 std::allocator<char> a 是静态成员变量,它的生命周期与程序的运行时间相同。这意味着无论创建了多少个 String 对象,它们都使用相同的 allocator 对象来分配和释放内存。这样可以确保内存管理的一致性,并且简化了代码的维护和调试
将 std::allocator<char> a 设为类的静态成员变量,而不是全局变量,有一些好处:
1)封装性: 将 std::allocator<char> a 声明为类的静态成员变量,将其封装在类的内部。这样做有助于隐藏实现细节,并提高代码的封装性。其他文件无法直接访问类的私有静态成员变量,必须通过类的公共接口来访问它
2)命名空间管理: 将 std::allocator<char> a 放置在类的作用域内,有助于避免命名冲突。如果将其设为全局变量,可能会造成命名冲突和不必要的全局命名污染
3)相关性: 将 std::allocator<char> a 设为类的静态成员变量,表明它与类 String 有关联性。这样做有助于提高代码的可读性和可维护性,因为它清楚地表明了 allocator 与 String 类密切相关
虽然将 std::allocator<char> a 设为全局变量可能是一个选择,但是将其设为类的静态成员变量更符合面向对象编程的思想,更好地体现了类的封装性和相关性
void String::swap(String& s)
{
auto tmp_sz = s.sz;
s.sz = sz;
sz = tmp_sz;
auto tmp_p = s.p;
s.p = p;
p = tmp_p;
// 这个不用交换,只是用来分配变量的东西
// auto tmp_a = s.a;
// s.a = a;
// a = tmp_a;
}
为什么不需要交换a
在这个 String::swap 函数中,std::allocator<char> a 是一个静态成员变量。静态成员变量属于类的所有对象共享,不是每个对象单独拥有的。因此,在交换两个 String 对象时,并不需要交换它们的 std::allocator<char> a
为什么在add函数中使用String res();出来res是个指针
String add(const String& s1, const String& s2)
{
String res(); // 这里使用了函数声明而不是对象定义
// ...
return res;
}
这里的 String res(); 并不是在定义一个 String 类型的对象 res,而是声明了一个返回 String 类型对象的函数 res。这是因为 C++ 在解析函数声明时,如果不提供参数列表,则该声明会被视为函数声明而不是对象定义
上述代码中的 String res(); 实际上声明了一个函数 res,该函数不接受任何参数并返回一个 String 类型的对象。当你在 add 函数中使用 res() 时,实际上是调用了这个声明的函数 res,而不是创建了一个 String 类型的对象
String add(const String& s1, const String& s2)
{
String res; // 创建一个 String 类型的对象
// ...
return res;
}
这样就可以正确地创建一个 String 类型的对象 res,而不是声明一个函数
String.h
#pragma once
#ifndef STRING_H
#define STRING_H
#include <iostream>
#include <memory>
#include <algorithm> // 头文件要加在头文件里,不加.cpp里面
class String {
friend String operator+(const String&, const String&);
friend String add(const String&, const String&);
friend std::ostream& operator<<(std::ostream&, const String&); // 为什么不定义为类函数
friend std::ostream& print(std::ostream&, const String&);
public:
String():sz(0), p(nullptr) {};
String(const char* cp):sz(strlen(cp)), p(a.allocate(strlen(cp)))
{
std::uninitialized_copy(cp, cp + strlen(cp), p);
}; // 字符串常量需要用对应的函数解决
String(size_t n, char c) :sz(n), p(a.allocate(n))
{
std::uninitialized_fill_n(p, n, c);
};
String(const String& s) :sz(s.sz), p(a.allocate(s.sz))
{
std::cout << "copy constructor -- " << s << std::endl;
std::uninitialized_copy(s.p, s.p + s.sz, p);
}
String& operator=(const String&);
~String() { free(); }
String make_plural(size_t ctr, const String&, const String&); // 前一个是单词,后一个是s或者es
inline void swap(String& s1, String& s2) {
s1.swap(s2); // 就改个形式调用swap成员函数
}
String& operator=(const char*);
String& operator=(char);
const char* begin() { return p; }
const char* begin() const { return p; } // 定义const / 非const的原因
const char* end() { return p + sz; }
const char* end() const { return p + sz; }
size_t size() const { return sz; }
void swap(String&);
private:
size_t sz;// 大小
char* p; // 指向开始指针
static std::allocator<char> a; // 分配空间,多大就分配多少
void free();
};
#endif
String.cpp
#include "String.h"
using namespace std;
allocator<char> String::a; // static别忘了声明
void String::free()
{
for_each(p, p + sz, [this](char& c) { a.destroy(&c); });
a.deallocate(p, sz);
}
void String::swap(String& s)
{
auto tmp_sz = s.sz;
s.sz = sz;
sz = tmp_sz;
auto tmp_p = s.p;
s.p = p;
p = tmp_p;
// 这个不用交换,只是用来分配变量的东西
// auto tmp_a = s.a;
// s.a = a;
// a = tmp_a;
}
String& String::operator=(char c)
{
free();
sz = 1;
p = a.allocate(1);
// 只有1个直接赋值就行
*p = c;
return *this;
}
String& String::operator=(const char* cp)
{
free();
sz = strlen(cp);
p = a.allocate(sz);
uninitialized_copy(cp, cp + sz, p);
return *this;
}
String String::make_plural(size_t ctr, const String& s1, const String& s2)
{
return ctr > 1 ? s1 + s2 : s1;
}
String& String::operator=(const String& s)
{
free(); // 先把自己原来的释放
sz = s.sz;
p = a.allocate(s.sz);
uninitialized_copy(s.p, s.p + sz, p);
return *this;
}
ostream& print(ostream& os, const String& s) // const不能少
{
auto it = s.begin();
while (it != s.end()) {
os << *it++;
}
return os;
}
ostream& operator<<(ostream& os, const String& s)
{
return print(os, s);
}
String add(const String& s1, const String& s2)
{
String res;
// 为什么String res();出来res是个指针
res.sz = s1.sz + s2.sz;
res.p = res.a.allocate(res.sz);
// 分两次插入两个String的值
uninitialized_copy(s1.begin(), s1.end(), res.p);
uninitialized_copy(s2.begin(), s2.end(), res.p + s1.sz);
return res;
}
String operator+(const String& s1, const String& s2)
{
return add(s1, s2);
}
13.44.cpp
#include "String.h"
#include <vector>
using namespace std;
int main() {
String s1("One"), s2("Two");
cout << s1 << " " << s2 << endl << endl;
String s3(s2);
cout << s1 << " " << s2 << " " << s3 << endl << endl;
s3 = s1;
cout << s1 << " " << s2 << " " << s3 << endl << endl;
s3 = String("Three");
cout << s1 << " " << s2 << " " << s3 << endl << endl;
vector<String> svec;
svec.push_back(s1); // copy constructor -- One
svec.push_back(std::move(s2)); // copy constructor -- Two copy constructor -- One
svec.push_back(String("Three")); // copy constructor -- Three copy constructor -- One copy constructor -- Two
svec.push_back("Four");
for_each(svec.begin(), svec.end(), [](const String& s) { cout << s << " "; });
cout << endl;
return 0;
}
运行结果

6、对象移动
1、新标准的一个最主要的特性是 可以移动 而非拷贝对象的能力。很多情况下 都会发生对象拷贝。在其中某些情况下,对象拷贝后就立即 被销毁了。在这些情况下,移动而非拷贝对象 会大幅度提升性能
2、StrVec类 是 这种不必要的拷贝的一个很好的例子。在重新分配内存的过程中,从旧内存 将元素拷贝到新内存 是不必要的,更好的方式是移动元素
使用移动 而不是 拷贝的另一个原因 源于IO类 或 unique_ptr这样的类。这些类都包含不能 被共享的资源(如指针或IO缓冲)。因此,这些类型的对象不能拷贝 但可以移动
在旧版本的标准库中,容器中 所保存的类 必须是可拷贝的。但在新标准中,我们可以 用容器保存 不可拷贝的类型,只要它们能 被移动即可
标准库容器、string和shared ptr类 既支持移动也支持拷贝。IO类 和 unique_ptr类 可以移动 但不能拷贝
6.1 右值引用
1、为了 支持移动操作,新标准 引入了一种新的引用类型——右值引用
右值引用 就是必须绑定到 右值的引用。通过 && 而不是 & 来获得 右值引用。右值引用 有一个重要的性质——只能绑定到 一个将要销毁的对象。因此,我们可以自由地 将一个右值引用的资源 “移动”到另一个对象中
一个左值表达式 表示的是 一个对象的身份,而一个右值表达式 表示的是对象的值
一个右值引用 也不过是 某个对象的另一个名字而已。对于 常规引用(为了 与右值引用 区分开来,我们可以 称之为左值引用)不能 将其绑定到 要求转换的表达式、字面常量 或是 返回右值的表达式
右值引用 有着 完全相反的绑定特性:我们可以将一个右值引用 绑定到这类表达式上,但不能 将一个右值引用 直接绑定到 一个左值上
int i = 42;
int &r = i; //正确:r引用i
int &&rr = i; //错误:不能将一个右值引用绑定到一个左值上
int &r2 = i * 42; //错误:i*42是一个右值
const int &r3 = i * 42; //正确:我们可以将一个const的引用绑定到一个右值上
int &&rr2 = i * 42; //正确:将rr2绑定到乘法结果上
2、返回 左值引用的函数,连同 赋值、下标、解引用 和 前置递增 / 递减运算符,都是 返回左值的表达式的例子。我们可以 将一个左值引用 绑定到 这类表达式的结果上
当函数返回一个左值引用时,意味着该函数返回的结果可以被修改,因为返回的是一个可修改的内存地址,而不是其值的拷贝
1)赋值运算符函数:
class MyClass {
public:
int value;
MyClass& operator=(const MyClass& other) {
value = other.value;
return *this; // 返回当前对象的引用
}
};
MyClass obj1, obj2;
MyClass& ref = (obj1 = obj2); // 将赋值运算符返回的左值引用绑定到 ref 上
2)下标运算符函数:
class MyArray {
public:
int arr[10];
int& operator[](int index) {
return arr[index]; // 返回数组元素的引用
}
};
MyArray arr;
int& ref = arr[5]; // 将下标运算符返回的左值引用绑定到 ref 上
3)解引用运算符函数:
class MyPtr {
public:
int value;
int& operator*() {
return value; // 返回指针指向的对象的引用
}
};
MyPtr ptr;
int& ref = *ptr; // 将解引用运算符返回的左值引用绑定到 ref 上
4)前置递增/递减运算符函数:
class MyCounter {
public:
int count;
MyCounter& operator++() {
++count;
return *this; // 返回自增后的对象的引用
}
MyCounter& operator--() {
--count;
return *this; // 返回自减后的对象的引用
}
};
MyCounter counter;
MyCounter& ref1 = ++counter; // 将前置递增运算符返回的左值引用绑定到 ref1 上
MyCounter& ref2 = --counter; // 将前置递减运算符返回的左值引用绑定到 ref2 上
3、返回 非引用类型的函数,连同 算术、关系、位 以及 后置递增 / 递减运算符,都生成右值。我们不能将一个左值引用绑定到这类表达式上,但我们 可以将一个const的左值引用 或者 一个右值引用绑定到这类表达式上
当函数返回非引用类型时,表达式生成的是右值,因为返回的是值的副本而不是可修改的内存地址。以下是一些返回非引用类型的函数的例子,以及相应的表达式,可以将一个 const 左值引用或者一个右值引用绑定到这些表达式上
1)算术运算符函数:
class MyNumber {
public:
int value;
MyNumber operator+(const MyNumber& other) const {
MyNumber result;
result.value = value + other.value;
return result; // 返回两个对象相加后的副本
}
};
MyNumber num1, num2;
const MyNumber& cref = (num1 + num2); // 将算术运算符返回的右值绑定到 const 左值引用 cref 上
int f();
int &&r4 = vi[0] * f(); // vi[0] * f() 是一个算术运算表达式,返回右值
2)关系运算符函数:
class MyNumber {
public:
int value;
bool operator<(const MyNumber& other) const {
return value < other.value; // 返回比较结果的副本
}
};
MyNumber num1, num2;
const bool& ref = (num1 < num2); // 将关系运算符返回的右值绑定到 const 左值引用 ref 上
3)位运算符函数:
class MyBitset {
public:
int bits;
MyBitset operator&(const MyBitset& other) const {
MyBitset result;
result.bits = bits & other.bits;
return result; // 返回按位与运算后的副本
}
};
MyBitset bs1, bs2;
const MyBitset& cref = (bs1 & bs2); // 将位运算符返回的右值绑定到 const 左值引用 cref 上
4)后置递增/递减运算符函数:
class MyCounter {
public:
int count;
MyCounter operator++(int) {
MyCounter temp = *this;
++count;
return temp; // 返回自增前的副本
}
MyCounter operator--(int) {
MyCounter temp = *this;
--count;
return temp; // 返回自减前的副本
}
};
MyCounter counter;
const MyCounter&& rref1 = counter++; // 将后置递增运算符返回的右值绑定到右值引用 rref1 上
const MyCounter&& rref2 = counter--; // 将后置递减运算符返回的右值绑定到右值引用 rref2 上
4、左值持久;右值短暂
左值有持久的状态
而右值要么是字面常量,要么是在表达式求值过程中创建的临时对象
由于右值引用只能绑定到临时对象,我们得知
- 所引用的对象将要被销毁
- 该对象没有其他用户
这两个特性意味着:使用右值引用的代码 可以自由地接管 所引用的对象的资源
5、变量是左值:只有一个运算对象 而没有运算符的表达式,变量表达式都是左值(不能将一个右值引用直接绑定到一个变量上)
带来的结果 就是,我们 不能将一个右值引用 绑定到 一个右值引用类型的变量上,这有些令人惊讶
int &&rr1 = 42; //正确:字面常量是右值
int &&rr2 = rr1; //错误:表达式rr1是左值
6、标准库move函数:可以显式地 将一个左值 转换为 对应的右值引用类型。我们还可以 通过调用一个名为move的新标准库函数 来获得绑定到 左值上的右值引用,此函数定义在头文件 utility 中
int &&rr3 = std::move(rr1); //ok
调用move 就意味着承诺:除了 对rr1赋值或销毁它外,我们将不再使用它。在调用move之后,我们不能 对移后源对象的值做任何假设:可以销毁 一个移后源对象,也可以 赋予它新值,但不能 使用一个移后源对象的值
7、以下是一些右值的示例:
1)临时对象:
int result = 2 + 3; // 2 + 3 是一个临时对象,是一个右值
2)字面值常量:
int x = 5; // 5 是一个字面值常量,是一个右值
3)函数返回的临时对象:
std::string createString() {
return "Hello"; // 返回一个临时字符串对象,是一个右值
}
4)具有右值引用类型的表达式:
int&& rref = 10; // 10 是一个右值,被绑定到一个右值引用变量 rref 上
5)移动语义中的右值:
std::vector<int> v1 = {1, 2, 3};
std::vector<int> v2 = std::move(v1); // std::move(v1) 是一个右值
6)lambda 表达式(如果不以引用捕获变量):
auto lambda = []() { return 42; }; // lambda 表达式返回的结果是一个右值
8、函数可能返回左值吗
函数通常返回的是右值。这是因为函数返回值是临时的,通常没有持久的身份。然而,有一些情况下函数可以返回左值引用,从而返回一个左值
#include <iostream>
int global_variable = 42;
int& returnReference() {
return global_variable;
}
int main() {
std::cout << "global_variable before calling function: " << global_variable << std::endl;
// 调用函数并获取对 global_variable 的引用
int& ref = returnReference();
// 修改 global_variable 的值
ref = 100;
std::cout << "global_variable after calling function: " << global_variable << std::endl;
return 0;
}
returnReference() 表达式返回的是一个左值,因为它返回了一个对具有持久身份的对象的引用
6.2 移动构造函数 和 移动赋值运算符
1、为了 让我们自己的类型 支持 移动操作,需要为其 定义移动构造函数 和 移动赋值运算符
类似 拷贝构造函数,移动构造函数的第一个参数是 该类类型的一个引用。这个引用参数 在移动构造函数中 是一个右值引用。与拷贝构造函数一样,任何 额外的参数 都必须 有默认实参
除了 完成资源移动,移动构造函数 还必须 确保移后源对象 处于这样一个状态——销毁它是无害的。特别是,一旦资源完成移动,源对象 必须 不再指向 被移动的资源——这些资源的所有权 已经归属新创建的对象
为StrVec类定义移动构造函数,实现从一个StrVec到另一个StrVec的元素移动而非拷贝
StrVec::StrVec(StrVec&& svm) noexcept // 移动操作 不应抛出任何异常
// 成员初始化器 接管s中的资源
:elements(svm.elements), first_free(svm.first_free), cap(svm.cap)
{
// 令s进入这样的状态——对其运行析构函数是安全的
svm.elements = svm.first_free = svm.cap = nullptr;
}
与拷贝构造函数不同,移动构造函数 不分配 任何新内存:它接管 给定的StrVec中的内存。在接管内存之后,它将 给定对象中的指针 都置为 nullptr。这样就完成了 从给定对象的移动操作,此对象将继续存在。最终,移后源对象会被销毁,意味着将在其上运行析构函数。StrVec的析构函数在first_free上 调用deallocate。如果我们忘记了改变s.first_free,则销毁移后 源对象就会释放掉 我们刚刚移动的内存
2、移动操作、标准库容器和异常:由于 移动操作“窃取”资源,它通常 不分配任何资源。因此,移动操作 通常不会抛出 任何异常。当编写一个 不抛出异常的移动操作时,我们应该 将此事通知标准库。我们将看到,除非标准库 知道我们的移动构造函数不会抛出异常,否则 它会认为移动我们的类对象时 可能会抛出异常,并且 为了处理这种可能性 而做一些额外的工作(没加也不影响运行)
一种通知标准库的方法 是 在我们的构造函数中指明noexcept。noexcept 是我们承诺一个函数不抛出异常的一种方法。在一个构造函数中,noexcept 出现在 参数列表和初始化列表开始的冒号之间:
class strVec {
public:
StrVec(StrVec&&) noexcept; //移动构造函数
//其他成员的定义,如前
};
StrVec::StrVec(StrVec &&s) noexcept : /*成员初始化器*/
{ /*构造函数体*/ }
必须在 类头文件的声明中 和 定义中(如果定义在类外的话)都指定 noexcept
不抛出异常的移动构造函数 和 移动赋值运算符 必须标记为 noexcept
3、需要指出 一个移动操作不抛出异常,这是 因为两个相互关联的事实:首先,虽然 移动操作 通常不抛出异常,但抛出异常也是允许的;其次,标准库容器 能对异常发生时 其自身的行为提供保障。例如,vector保证,如果我们调用 push_back 时发生异常,vector自身不会发生改变
4、类似对应的StrVec操作,对一个vector 调用 push_back 可能要求为 vector 重新分配内存空间。当重新分配vector的内存时,vector 将元素 从旧空间移动到新内存中,就像我们在reallocate中所做的那样
void StrVec::chk_n_alloc()
{
if (size() == capacity())
reallocate();
}
void StrVec::push_back(const string& s) {
chk_n_alloc();
alloc.construct(first_free++, s);
}
void StrVec::reallocate()
{
auto newcap = size() ? 2 * size() : 1;
auto be = alloc.allocate(newcap);
auto en = uninitialized_copy(make_move_iterator(begin()), make_move_iterator(end()), be);
free();
elements = be;
first_free = en;
cap = be + newcap;
}
移动一个对象 通常会改变它的值。如果 重新分配 过程使用了 移动构造函数,且在移动了部分 而不是全部元素后 抛出了一个异常,就会产生问题。旧空间中的移动源元素 已经被改变了,而新空间中 未构造的元素 可能尚不存在。在此情况下 vector将不能满足 自身保持不变的要求
另一方面,如果vector使用了拷贝构造函数 且发生了异常,它可以很容易地满足要求。在此情况下,当在新内存中构造元素时,旧元素保持不变。如果此时发生了异常,vector可以 释放新分配的(但还未成功构造的)内存 并返回。vector原有的元素仍然
存在
为了避免这种潜在问题,除非vector知道 元素类型的移动构造函数不会抛出异常,否则 在重新分配内存的过程中,它就必须使用拷贝构造函数 而不是移动构造函数。如果希望 在vector重新分配内存这类情况下 对我们自定义类型的对象 进行移动 而不是拷贝,就必须 显式地告诉标准库 我们的移动构造函数可以安全使用。我们通过 将移动构造函数(及移动赋值运算符)标记为noexcept 来做到这一点
虽然 noexcept 可以影响编译器是否使用移动语义,但它并不是移动语义的决定性因素。编译器在决定是否使用移动语义时会综合考虑多种因素,并进行优化,以提高程序的性能
在没有显式声明为 noexcept 的情况下,编译器仍然可以根据一些规则来确定是否使用移动语义,例如:
1)如果一个对象是通过右值构造的(例如,函数返回的临时对象),编译器通常会选择移动语义而不是拷贝构造函数
2)如果类中定义了移动构造函数和移动赋值运算符,且编译器认为使用移动语义可以提高性能,它也会选择移动语义
3)在某些情况下,即使对象是通过左值构造的,编译器也可以选择使用移动语义,例如在返回局部对象的函数中,编译器可能会进行RVO(返回值优化)或NRVO(命名返回值优化),从而避免了不必要的拷贝操作
5、移动赋值运算符:移动赋值运算符执行 与 析构函数和移动构造函数相同的工作。与移动构造函数 一样,如果 我们的移动赋值运算符 不抛出任何异常,我们就应该 将它标记为 noexcept。类似 拷贝赋值运算符,移动赋值运算符 必须正确处理自赋值
StrVec &StrVec::operator=(StrVec &&rhs) noexcept
{
//直接检测自赋值
if (this != &rhs) {
free(); //释放已有元素
elements = rhs.elements; //从rhs接管资源
first_free = rhs.first_free;
cap = rhs.cap;
//将rhs置于 可析构状态
rhs.elements = rhs.first_free = rhs.cap = nullptr;
}
return *this;
}
直接检查 this指针 与 rhs的地址 是否相同。如果相同,右侧和左侧运算对象 指向 相同的对象,我们 不需要做任何事情
移动赋值运算符 需要 右侧运算对象的一个右值。我们进行检查的原因 是此右值 可能是move调用的返回结果。与其他任何赋值运算符一样,关键点是 我们不能在 使用右侧运算对象的资源之前 就释放左侧运算对象的资源(可能是相同的资源)(所以要 检查自赋值情况)
6、移后源对象必须可析构:除了 将移后源对象 置为析构安全的状态之外,移动操作 还必须保证对象 仍然是有效的。一般来说,对象有效 就是 指可以安全地为其赋予新值 或者 可以安全地使用而不依赖其当前值。另一方面,移动操作 对移后源对象中 留下的值 没有任何要求。因此,我们的程序 不应该 依赖于移后源对象中的数据
例如,当我们 从一个标准库string 或 容器对象 移动数据时,我们知道 移后源对象 仍然保持有效。因此,我们可以 对它执行诸如empty 或 size这些操作。但是,我们不知道 将会得到什么结果。我们可能期望一个移后源对象是空的,但这并没有保证
7、合成的移动操作:编译器也会合成 移动构造函数和移动赋值运算符。但是,合成移动操作的条件 与 合成拷贝操作的条件大不相同
如果 我们不声明自己的拷贝构造函数 或 拷贝赋值运算符,编译器总会 为我们合成这些操作。拷贝操作要么被定义为 逐成员拷贝,要么 被定义为 对象赋值,要么 被定义为 删除的函数
编译器根本不会为 某些类合成移动操作。特别是,如果一个类定义了 自己的拷贝构造函数、拷贝赋值运算符 或者 析构函数,编译器 就不会 为它合成移动构造函数 和 移动赋值运算符了。因此,某些类 就没有移动构造函数 或 移动赋值运算符
如果一个类 没有移动操作,通过正常的函数匹配,类会使用 对应的拷贝操作 来代替移动操作
只有当一个类 没有定义任何自己版本的 拷贝控制成员,且类的每个非static数据成员 都可以移动时,编译器 才会为它合成移动构造函数 或 移动赋值运算符。编译器可以移动 内置类型的成员。如果一个成员是 类类型,且该类 有对应的移动操作,编译器也能移动这个成员:
//编译器会为X和has X合成移动操作
struct X {
int i; //内置类型可以移动
std::string s; //string定义了自己的移动操作
);
struct hasX {
X mem; //X有合成的移动操作
};
X x, x2 = std:move(x); //使用合成的移动构造函数
hasX hx, hx2 = std::move(hx); //使用合成的移动构造函数
与拷贝操作不同,移动操作 永远不会 隐式定义为删除的函数。但是,如果 我们显式地要求 编译器生成 = default 的 移动操作,且编译器 不能移动所有成员,则编译器 会将移动操作 定义为删除的函数。除了 一个重要例外,什么时候将合成的移动操作 定义为删除的函数 遵循与定义删除的合成拷贝操作类似的原则
- 与拷贝构造函数不同,移动构造函数 被定义为 删除的函数的条件是:有 类成员定义了 自己的拷贝构造函数 且未定义移动构造函数,或者是 有类成员 未定义自己的拷贝构造函数 且编译器不能为其合成移动构造函数。移动赋值运算符的情况类似
- 如果有类成员的移动构造函数 或 移动赋值运算符 被定义为 删除的 或是 不可访问的,则类的移动构造函数 或 移动赋值运算符 被定义为删除的
- 类似拷贝构造函数,如果类的析构函数 被定义为 删除的 或 不可访问的,则类的移动构造函数 被定义为删除的
- 类似拷贝赋值运算符,如果有类成员是 const的或是引用,则 类的移动赋值运算符被定义为删除的
//假定Y是一个类,它定义了自己的拷贝构造函数但未定义自己的移动构造函数
struct hasY {
hasY() = default;
hasY(hasY&&) = default; // 一定要显式地等于default才可能有删除的
Y mem; //hasY将有一个删除的移动构造函数
};
hasY hy, hy2 = std::move(hy); //错误:移动构造函数是删除的
编译器 可以拷贝类型为Y的对象,但 不能移动它们。类hasY 显式地要求 一个移动构造函数,但 编译器无法 为其生成。因此,hasY 会有一个 删除的移动构造函数
如果移动操作可能被定义为 删除的函数,编译器就不会合成它们
8、一个类是否定义了自己的移动操作 对拷贝操作如何合成有影响。如果类定义了一个移动构造函数 和/或 一个移动赋值运算符,则该类的合成拷贝构造函数 和 拷贝赋值运算符 会被定义为删除的
定义了一个移动构造函数 或 移动赋值运算符的类 必须也定义自己的拷贝操作
9、移动右值,拷贝左值,但如果没有移动构造函数,右值也被拷贝
1)如果一个类 既有移动构造函数,也有 拷贝构造函数,编译器使用普通的函数匹配规则 来确定使用哪个构造函数。赋值操作的情况类似。例如,在我们的StrVec类中,拷贝构造函数接受一个const StrVec的引用。因此,它可以用于任何可以转换为StrVec的类型。而移动构造函数接受一个StrVec&&,因此只能用于实参是(非static)右值的情形
StrVec v1, v2;
v1 = v2; //v2是左值;使用拷贝赋值
StrVec getVec(istream&); //getVec返回一个右值
v2 = getVec(cin); //getVec(cin)是一个右值;使用移动赋值
此表达式getVec(cin)是一个右值。在此情况下,两个赋值运算符 都是可行的
调用拷贝赋值运算符需要进行一次到const的转换(拷贝赋值运算符通常定义为接收一个 const 类型的引用参数 MyClass& operator=(const MyClass& other); 这样可以 保护源对象的数据;允许接受临时对象和常量对象),而StrVec&&则是精确匹配。因此,第二个赋值会使用移动赋值运算符
2)如果一个类有一个拷贝构造函数 但未定义 移动构造函数,编译器 不会合成 移动构造函数,这意味着 此类将有拷贝构造函数 但不会有 移动构造函数。如果一个类 没有移动构造函数,函数匹配规则 保证 该类型的对象会被拷贝,即使我们试图通过调用move来移动它们
class Foo {
public:
Foo() = default;
Foo(const Foo&); //拷贝构造函数
//其他成员定义,但Foo未定义移动构造函数
};
Foo x;
Foo y(x); //拷贝构造函数:x是一个左值
Foo z(std::move(x)); //拷贝构造函数,因为未定义移动构造函数
调用了move(x),它返回 一个绑定到x的Foo&&。Foo的拷贝构造函数 是可行的,因为我们可以 将一个 Foo&& 转换为一个 const Foo&。因此,z的初始化 将使用Foo的拷贝构造函数
3)用拷贝构造函数 代替 移动构造函数 几乎肯定是安全的(赋值运算符的情况类似)
拷贝构造函数 满足对应的移动构造函数的要求:它会拷贝 给定对象,并将 原对象置于有效状态。实际上,拷贝构造函数 甚至都不会改变 原对象的值
10、拷贝并交换赋值运算符 和 移动操作:HasPtr版本 定义了 一个拷贝并交换赋值运算符
class HasPtr {
public:
//添加的移动构造函数
HasPtr(HasPtr&& p) noexcept:ps(p.ps), i(p.i) { p.ps = 0; }
//赋值运算符既是移动赋值运算符,也是拷贝赋值运算符
HasPtr& operator=(HasPtr rhs)
{ swap(*this, rhs); return *this; }
};
为类 添加了 一个移动构造函数,它接管了 给定实参的值。此函数 不会抛出异常,因此我们将其标记为 noexcept
赋值运算符,此运算符 有一个非引用参数,这意味着 此参数要进行 拷贝初始化。依赖于 实参的类型,拷贝初始化 要么使用 拷贝构造函数,要么使用 移动构造函数——左值被拷贝,右值被移动。因此,单一的赋值运算符 就实现了 拷贝赋值运算符和移动赋值运算符两种功能
hp = hp2; //hp2是一个左值;hp2通过 拷贝构造函数来拷贝
hp = std::move(hp2); //移动构造函数移动hp2
移动构造函数 从 hp2 拷贝指针,而不会 分配任何内存。赋值运算符的函数体 都 swap 两个运算对象的状态。交换HasPtr 会交换两个对象的指针(及int)成员。在swap之后,rhs中的指针 将指向原来左侧运算对象所拥有的string。当rhs 离开其作用域时,这个string 将被销毁
11、更新 三/五法则:所有五个拷贝控制成员 应该看作一个整体:一般来说,如果一个类定义了任何一个拷贝操作,它就应该定义所有五个操作
某些类必须定义 拷贝构造函数、拷贝赋值运算符 和 析构函数 才能正确工作。这些类 拥有一个资源,而拷贝成员 必须拷贝 此资源。一般来说,拷贝一个资源 会导致一些额外开销。在这种拷贝 并非必要的情况下,定义了 移动构造函数 和 移动赋值运算符的类就可以避免此问题
12、Message类的移动操作:定义了自己的拷贝构造函数 和 拷贝赋值运算符的类 通常 也会从移动操作受益
Message类 可以使用 string和set的移动操作 来避免拷贝contents和folders成员的额外开销
除了 移动folders成员,我们还必须 更新每个指向原Message的Folder。我们必须 删除指向旧Message的指针,并添加一个指向新Message的指针
移动构造函数 和 移动赋值运算符 都需要更新Folder指针
//从本Message移动Folder指针
void Message::move_Folders(Message *m)
{
folders = std::move(m->folders); //使用set的移动赋值运算符
for(auto f : folders) { //对每个Folder
f->remMsg(m); //从Folder中删除旧Message
f->addMsg(this); //将本Message添加到Folder中
}
m->folders.clear(); //确保销毁m是无害的
}
向set插入一个元素 可能会抛出一个异常——向容器添加元素的操作 要求分配内存,意味着 可能会抛出一个bad alloc异常
因此,与我们的HasPtr 和 StrVec类的移动操作不同,Message的移动构造函数和移动赋值运算符 可能会抛出异常。因此我们未将它们标记为 noexcept
在执行了move之后,我们知道m.folders是有效的,但不知道它包含什么内容
Message的移动构造函数 调用move 来移动contents,并 默认初始化 自己的folders成员
Message::Message(Message &&m):contents(std::move(m.contents))
{
move_Folders(&m); //移动folders并更新Folder指针
}
Message& Message::operator=(Message &&rhs)
{
if (this != &rhs) { //直接检查自赋值情况
remove_from_Folders();
contents = std::move(rhs.contents); //移动赋值运算符
move_Folders(&rhs); //重置Folders指向本Message
}
return *this;
}
与任何赋值运算符一样,移动赋值运算符 必须销毁 左侧运算对象的旧状态
13、移动迭代器:StrVec的 reallocate成员 使用了 一个for循环来调用 construct 从旧内存将元素 拷贝到 新内存中。作为一种替换方法,如果我们能调用 uninitialized_copy 来构造 新分配的内存,将比循环 更为简单。但是,uninitialized_copy 恰如其名:它对元素进行拷贝操作。标准库中并没有类似的函数 将对象“移动”到未构造的内存中
新标准库中 定义了 一种 移动迭代器适配器。一个移动迭代器 通过改变 给定迭代器的解引用运算符的行为 来适配此迭代器。一般来说 一个迭代器的解引用运算符 返回 一个指向元素的左值。与其他迭代器不同,移动迭代器的解引用运算符 生成一个右值引用
通过 调用标准库的 make_move_iterator 函数 将一个普通迭代器 转换为一个移动迭代器。此函数 接受一个迭代器参数,返回一个移动迭代器
原迭代器的所有其他操作 在移动送代器中 都照常工作。由于移动迭代器 支持正常的迭代器操作,我们可以 将一对移动迭代器传递给算法。特别是,可以将移动迭代器传递给 uninitialized_copy
void StrVec::reallocate()
{
//分配大小两倍于当前规模的内存空间
auto newcapacity = size() ? 2 * size() : 1;
auto first = alloc.allocate(newcapacity);
//移动元素
auto last = uninitialized_copy(make_move_iterator(begin()),
make_move_iterator(end()),
first);
free(); //释放旧空间
elements = first; //更新指针
first_free = last;
cap = elements + newcapacity;
}
uninitialized_copy 对输入序列中的每个元素 调用 construct 来将元素“拷贝”到 目的位置。此算法 使用迭代器的解引用运算符 从输入序列中提取元素。解引用运算符 生成的是 一个右值引用,这意味着 construct 将使用移动构造函数 来构造元素
标准库 不保证哪些算法适用 移动迭代器,哪些不适用。由于移动一个对象 可能销毁掉 原对象,因此你只有在确信算法 在为一个元素赋值 或 将其传递给一个用户定义的函数后 不再访问它时,才能将移动迭代器 传递给算法
不要随意使用移动操作:在移动构造函数 和 移动赋值运算符 这些类实现代码之外的地方,只有当你确信 需要进行移动操作 且 移动操作是安全的,才可以使用 std::move
14、为 StrVec、String 和 Message 类 添加一个移动构造函数和一个移动赋值运算符
1)StrVec
添加一个移动构造函数,一个移动赋值运算符 以及 改动 StrVec 的 reallocate() 成员
StrVec_ex49.h
#pragma once
#include <string>
#include <memory>
class StrVec {
public:
StrVec() :
elements(nullptr), first_free(nullptr), cap(nullptr) {}
StrVec(const StrVec&);
StrVec(StrVec&&) noexcept; // 新加 移动构造函数,没有新开空间,noexcept随便加
StrVec& operator=(StrVec&&) noexcept; // 新加 移动赋值运算符
StrVec& operator=(const StrVec&);
~StrVec();
void push_back(const std::string&);
size_t size() const { return first_free - elements; }
size_t capacity() const { return cap - elements; }
std::string* begin() const { return elements; }
std::string* end() const { return first_free; }
void reserve(size_t n);
void resize(size_t n);
void resize(size_t n, const std::string& s);
StrVec(std::initializer_list<std::string>);
private:
static std::allocator<std::string> alloc;
void chk_n_alloc();
std::pair<std::string*, std::string*> alloc_n_copy(const std::string*, const std::string*);
void free();
void reallocate(); // 改动
void reallocate(size_t); // 新加函数
std::string* elements;
std::string* first_free;
std::string* cap;
};
StrVec_ex49.cpp
#include "StrVec_ex49.h"
#include <algorithm>
#include <utility>
using namespace std;
std::allocator<std::string> StrVec::alloc;
void StrVec::chk_n_alloc()
{
if (size() == capacity())
reallocate();
}
void StrVec::push_back(const string& s) {
chk_n_alloc();
alloc.construct(first_free++, s);
}
pair<string*, string*> StrVec::alloc_n_copy(const string* b, const string* e)
{
auto data = alloc.allocate(e - b);
return { data, uninitialized_copy(b, e, data) };
}
void StrVec::free()
{
if (elements) {
for_each(elements, first_free, [](string& s) {alloc.destroy(&s); });
}
alloc.deallocate(elements, cap - elements);
}
StrVec::StrVec(const StrVec& s)
{
auto newdata = alloc_n_copy(s.begin(), s.end());
elements = newdata.first;
first_free = newdata.second;
cap = newdata.second;
}
StrVec::~StrVec() { free(); }
StrVec& StrVec::operator=(const StrVec& rhs)
{
auto data = alloc_n_copy(rhs.begin(), rhs.end());
free();
elements = data.first;
first_free = data.second;
cap = data.second;
return *this;
}
// 用移动赋值的方式重写
void StrVec::reallocate()
{
auto newcap = size() ? 2 * size() : 1;
auto be = alloc.allocate(newcap);
auto en = uninitialized_copy(make_move_iterator(begin()), make_move_iterator(end()), be);
free();
elements = be;
first_free = en;
cap = be + newcap;
}
// 新加函数,另一种形式 移动赋值
void StrVec::reallocate(size_t newcap) {
auto be = alloc.allocate(newcap);
for (int i = 0; i < size(); i++) {
alloc.construct(be++, std::move(*elements++));
// elements 指针先被解引用,再进行递增操作,指向下一个元素的位置
// std::move参数为元素,而不是指针
}
size_t si = size();
free();
elements = be;
first_free = be + si;
cap = be + newcap;
}
void StrVec::reserve(size_t n) {
if (size() < n) {
reallocate();
}
}
void StrVec::resize(size_t n) {
resize(n, std::string());
}
void StrVec::resize(size_t n, const string& s)
{
if (size() > n) {
while (first_free != elements + n) {
alloc.destroy(--first_free);
}
alloc.destroy(first_free);
}
else {
while (size() < n) {
push_back(s);
}
}
}
StrVec::StrVec(std::initializer_list<std::string> il) {
auto newdata = alloc_n_copy(il.begin(), il.end());
elements = newdata.first;
first_free = newdata.second;
cap = newdata.second;
}
// 新加 移动构造函数
StrVec::StrVec(StrVec&& svm) noexcept:
elements(svm.elements), first_free(svm.first_free), cap(svm.cap)
{
svm.elements = svm.first_free = svm.cap = nullptr;
}
// 新加 移动赋值运算符,不用新建空间了,因为直接移过来了,直接用旧空间就行,但是自赋值的时候就会出问题,先free掉了
StrVec& StrVec::operator=(StrVec&& svm) noexcept
{
if (this != &svm) { // *this != svm对象之间没办法比(StrVec没定义!=),只能比指针
free();
elements = svm.elements;
first_free = svm.first_free;
cap = svm.cap;
svm.elements = svm.first_free = svm.cap = nullptr;
}
return *this;
}
2)Message
添加一个辅助函数,一个移动构造函数和一个移动赋值运算符
Folder_ex49.h
#pragma once
#ifndef FOLDER_EX49_H
#define FOLDER_EX49_H
#include <iostream>
#include <string>
#include <set>
class Folder;
class Message {
friend class Folder;
friend void swap(Message& lhs, Message& rhs);
public:
explicit Message(const std::string& str = "") :
contents(str) {}
Message(const Message&);
Message& operator=(const Message&);
~Message();
void save(Folder&);
void remove(Folder&);
// 新加 移动构造函数、移动赋值运算符、辅助函数
Message(Message&&);
Message& operator=(Message&&);
void move_folders(Message*);
private:
std::string contents;
std::set<Folder*> folders;
void add_to_Folders(const Message&);
void remove_from_Folders();
};
void swap(Message& lhs, Message& rhs);
class Folder {
friend class Message;
friend void swap(Message& lhs, Message& rhs);
public:
void debug_print();
private:
std::set<Message*> msgs;
void addMsg(Message* m);
void remMsg(Message* m);
};
#endif
Folder_ex49.cpp
#include "Folder_ex49.h"
using namespace std;
void Message::save(Folder& f) {
folders.insert(&f);
f.addMsg(this);
}
void Message::remove(Folder& f) {
folders.erase(&f);
f.remMsg(this);
}
void Message::add_to_Folders(const Message& m)
{
for (auto f : m.folders)
f->addMsg(this);
}
void Message::remove_from_Folders()
{
for (auto f : folders)
f->remMsg(this);
}
Message::~Message()
{
remove_from_Folders();
}
Message::Message(const Message& m) :
contents(m.contents), folders(m.folders)
{
add_to_Folders(m);
}
Message& Message::operator=(const Message& rhs) {
remove_from_Folders();
contents = rhs.contents;
folders = rhs.folders;
add_to_Folders(rhs);
return *this;
}
void swap(Message& lhs, Message& rhs) {
using std::swap;
for (auto f : lhs.folders)
f->remMsg(&lhs);
for (auto f : rhs.folders)
f->remMsg(&rhs);
swap(lhs.folders, rhs.folders);
swap(lhs.contents, rhs.contents);
for (auto f : lhs.folders)
f->addMsg(&lhs);
for (auto f : rhs.folders)
f->addMsg(&rhs);
}
void Folder::debug_print() {
cout << "Folder: ";
for (auto a : this->msgs) {
cout << a->contents << " ";
}
cout << endl;
}
void Folder::addMsg(Message* m) {
msgs.insert(m);
}
void Folder::remMsg(Message* m) {
msgs.erase(m);
}
// 新加 移动构造函数、移动赋值运算符、辅助函数(两个移动函数 都能用到)
void Message::move_folders(Message *m) {
folders = std::move(m->folders);
for (auto f : folders) {
f->remMsg(m);
f->addMsg(this); // 把之前的m的信息删掉换成自己的
}
m->folders.clear(); // 别忘了把老的清空,变成可用但是里面没东西的状态
}
Message::Message(Message&& m) : contents(std::move(m.contents)){
move_folders(&m);
}
Message& Message::operator=(Message&& m) {
if (this != &m) {
remove_from_Folders(); // 把自己的信息在folder中删完
contents = std::move(m.contents);
move_folders(&m);
}
return *this;
}
3)String
添加一个移动构造函数,一个移动赋值运算符。原理与本节书中 StrVec 类的移动构造函数和移动赋值运算符类似
String_ex49.h
#pragma once
#ifndef STRING_EX49_H
#define STRING_EX49_H
#include <iostream>
#include <memory>
#include <algorithm>
#include <utility>
// 加入移动构造函数 和 移动赋值运算符
class String {
friend String operator+(const String&, const String&);
friend String add(const String&, const String&);
friend std::ostream& operator<<(std::ostream&, const String&);
friend std::ostream& print(std::ostream&, const String&);
public:
String() :sz(0), p(nullptr) {};
String(const char* cp) :sz(strlen(cp)), p(a.allocate(strlen(cp)))
{
std::uninitialized_copy(cp, cp + strlen(cp), p);
};
String(size_t n, char c) :sz(n), p(a.allocate(n))
{
std::uninitialized_fill_n(p, n, c);
};
String(const String& s) :sz(s.sz), p(a.allocate(s.sz))
{
std::cout << "copy constructor -- " << s << std::endl;
std::uninitialized_copy(s.p, s.p + s.sz, p);
}
String& operator=(const String&);
~String() { free(); }
// 加入移动构造函数 和 移动赋值运算符
String(String&& sm) noexcept;
String& operator=(String&& sm) noexcept;
String make_plural(size_t ctr, const String&, const String&);
inline void swap(String& s1, String& s2) {
s1.swap(s2);
}
String& operator=(const char*);
String& operator=(char);
const char* begin() { return p; }
const char* begin() const { return p; } // 定义const / 非const的原因
const char* end() { return p + sz; }
const char* end() const { return p + sz; }
size_t size() const { return sz; }
void swap(String&);
private:
size_t sz;
char* p;
static std::allocator<char> a;
void free();
};
#endif
String_ex49.cpp
#include "String_ex49.h"
using namespace std;
allocator<char> String::a; // static别忘了声明
void String::free()
{
for_each(p, p + sz, [this](char& c) { a.destroy(&c); });
a.deallocate(p, sz);
}
void String::swap(String& s)
{
auto tmp_sz = s.sz;
s.sz = sz;
sz = tmp_sz;
auto tmp_p = s.p;
s.p = p;
p = tmp_p;
}
String& String::operator=(char c)
{
free();
sz = 1;
p = a.allocate(1);
*p = c;
return *this;
}
String& String::operator=(const char* cp)
{
free();
sz = strlen(cp);
p = a.allocate(sz);
uninitialized_copy(cp, cp + sz, p);
return *this;
}
// 加入移动构造函数 和 移动赋值运算符
String::String(String&& sm) noexcept: sz(std::move(sm.sz)), p(std::move(sm.p)) {
cout << "move constructor -- " << sm << endl;
sm.sz = 0;
sm.p = nullptr;
}
String& String::operator=(String&& sm) noexcept {
cout << "move-assignment operator -- " << sm << endl;
if (this != &sm) {
free();
sz = std::move(sm.sz);
p = std::move(sm.p);
sm.sz = 0;
sm.p = nullptr;
}
return *this;
}
String String::make_plural(size_t ctr, const String& s1, const String& s2)
{
return ctr > 1 ? s1 + s2 : s1;
}
String& String::operator=(const String& s)
{
free();
sz = s.sz;
p = a.allocate(s.sz);
uninitialized_copy(s.p, s.p + sz, p);
return *this;
}
ostream& print(ostream& os, const String& s)
{
auto it = s.begin();
while (it != s.end()) {
os << *it++;
}
return os;
}
ostream& operator<<(ostream& os, const String& s)
{
return print(os, s);
}
String add(const String& s1, const String& s2)
{
String res;
res.sz = s1.sz + s2.sz;
res.p = res.a.allocate(res.sz);
uninitialized_copy(s1.begin(), s1.end(), res.p);
uninitialized_copy(s2.begin(), s2.end(), res.p + s1.sz);
return res;
}
String operator+(const String& s1, const String& s2)
{
return add(s1, s2);
}
Message::Message(Message &&m) : contents(std::move(m.contents)) 中 contents(std::move(m.contents))与contents(m.contents)有什么区别
1)contents(std::move(m.contents)):
这里使用了 std::move 将 m.contents 转换为 右值引用,这意味着将 m.contents 的所有权 转移到了 当前对象的 contents 成员。
转移所有权后,m.contents 可能处于有效 但未指定的状态,即不能再对其进行操作,但也不保证一定为空。通常情况下,移动操作后 应该保证移动源对象 处于一种合适的状态,但这不是 std::move 的职责,而是类的设计者的责任
2)contents(m.contents):
这是简单的成员初始化,将 m.contents 的值直接复制给当前对象的 contents 成员
这种写法执行的是拷贝操作,而不是移动操作。这意味着不会修改 m.contents,而是会创建 contents 的一个副本,因此 m.contents 仍然保持原有的状态
通常情况下,在移动语义的情况下,使用 std::move 是更好的选择,因为它能够显式地表示你有意将对象的所有权转移给另一个对象,同时提供了更高的性能和可读性
15、Message(Message&&) 移动赋值 参数可以加const吗
移动构造函数和移动赋值运算符 通常 都不会声明参数为const。这是因为 移动语义的目的是 将资源(如动态分配的内存或文件句柄)从一个对象 转移到 另一个对象,而不是 复制资源。将参数声明为const 会阻止编译器移动资源,因为const限制了对象的可变性
当 声明一个参数为const时,意味着你承诺不会修改该对象的状态。而在移动语义中,移动构造函数和移动赋值运算符通常需要修改移动源对象的状态,例如将其指针置空,以防止资源被重复释放
16、在拷贝/移动构造函数 和 拷贝/移动赋值运算符中添加打印语句,观察输出
13.50.cpp(移动)
#include "String_ex49.h"
#include <vector>
using std::vector;
using std::cout;
using std::endl;
int main() {
String s1("One"), s2("Two");
cout << s1 << " " << s2 << endl << endl;
String s3(s2);
cout << s1 << " " << s2 << " " << s3 << endl << endl;
s3 = s1;
cout << s1 << " " << s2 << " " << s3 << endl << endl;
s3 = String("Three");
cout << s1 << " " << s2 << " " << s3 << endl << endl;
vector<String> svec;
svec.push_back(s1);
svec.push_back(std::move(s2));
svec.push_back(String("Three"));
svec.push_back("Four");
for_each(svec.begin(), svec.end(), [](const String& s) { cout << s << " "; });
cout << endl;
return 0;
}
运行结果
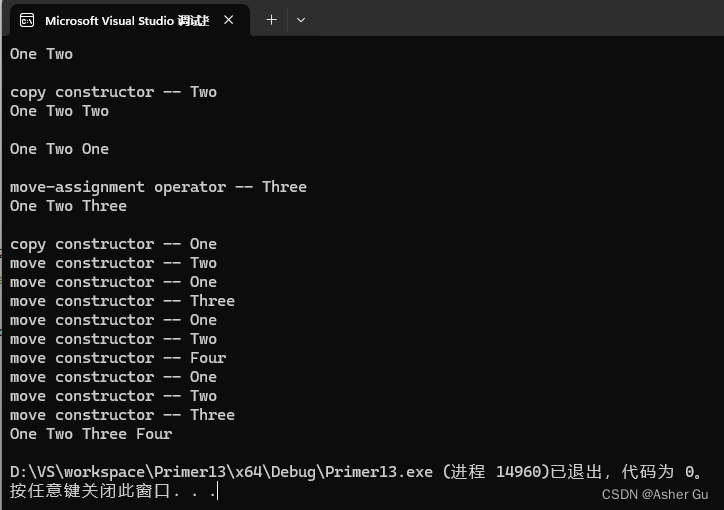
13.44.cpp
#include "String.h"
#include <vector>
using namespace std;
int main() {
String s1("One"), s2("Two");
cout << s1 << " " << s2 << endl << endl;
String s3(s2);
cout << s1 << " " << s2 << " " << s3 << endl << endl;
s3 = s1;
cout << s1 << " " << s2 << " " << s3 << endl << endl;
s3 = String("Three");
cout << s1 << " " << s2 << " " << s3 << endl << endl;
vector<String> svec;
svec.push_back(s1); // copy constructor -- One
svec.push_back(std::move(s2)); // copy constructor -- Two copy constructor -- One
svec.push_back(String("Three")); // copy constructor -- Three copy constructor -- One copy constructor -- Two
svec.push_back("Four");
for_each(svec.begin(), svec.end(), [](const String& s) { cout << s << " "; });
cout << endl;
return 0;
}
运行结果
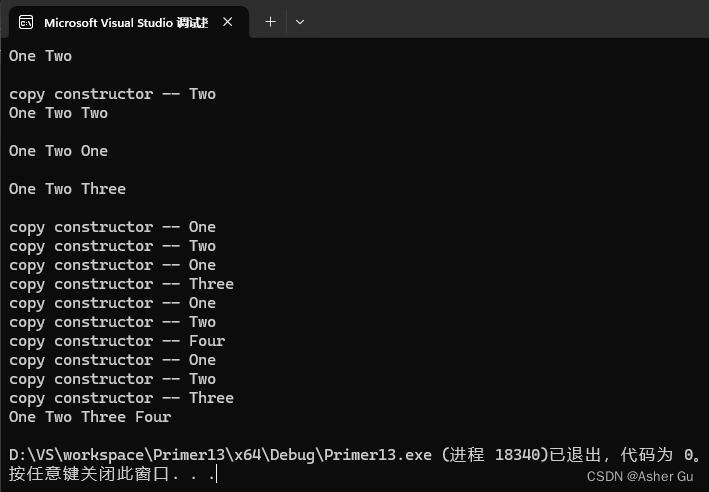
17、虽然 unique_ptr 不能拷贝,但 clone 函数,它以值的方式返回一个 unique_ptr。解释为什么函数是合法的,以及为什么它能正确工作

unique_ptr 不能拷贝,但有一个例外 —— 将要被销毁的 unique_ptr 是可以拷贝或销毁的。因此,在 clone 函数中返回局部 unique_ptr 对象 ret 是可以的,因为 ret 马上就要被销毁了。而此时 “拷贝” 其实是触发移动构造函数进行了移动
18、从底层效率的角度看,HasPtr 的赋值运算符并不理想,解释为什么
HasPtr& HasPtr::operator=(HasPtr rhs) {
// 交换左侧运算对象和局部变量 rhs 的内容
swap(*this, rhs); // rhs 现在指向本对象曾经使用的内存
return *this; // rhs 被销毁,从而 delete 了 rhs 中的指针
}
在进行拷贝赋值时,先通过拷贝构造创建了 hp2 的拷贝 rhs,然后再交换 hp 和 rhs,rhs 作为一个中间媒介,只是起到将值从 hp2 传递给 hp 的作用,是一个冗余的操作
类似的,在进行移动赋值时,先从 hp2 转移到 rhs,在交换到 hp,也是冗余的
也就是说,这种实现方式唯一的用处是统一了拷贝赋值运算和移动赋值运算,但在性能角度,多了一次从 rhs 的间接传递,性能不好
改成
HasPtr& operator=(const HasPtr &rhs_hp) {
auto newp = new std::string(*rhs_hp.ps);
delete ps;
ps = newp;
i = rhs_hp.i;
return *this;
}
HasPtr& operator=(HasPtr &&rhs_hp) noexcept
{
if (this != &rhs_hp)
{
delete ps;
ps = std::move(rhs_hp.ps);
i = rhs_hp.i;
}
return *this;
}
19、如果我们为 HasPtr 定义了移动赋值运算符,但未改变拷贝并交换运算符,会发生什么
HasPtr &operator=(HasPtr); // 赋值运算符(拷贝并交换版本)
HasPtr(HasPtr&&) noexcept; // 移动构造函数
HasPtr& HasPtr::operator=(HasPtr rhs) {
// 交换左侧运算对象和局部变量 rhs 的内容
swap(*this, rhs); // rhs 现在指向本对象曾经使用的内存
return *this; // rhs 被销毁,从而 delete 了 rhs 中的指针
}
HasPtr::HasPtr(HasPtr &&p) noexcept // 移动操作不应抛出任何异常
// 成员初始化器接管 p 中的资源
: ps(p.ps), i(p.i) {
// 令 p 进入这样的状态 —— 对其运行析构函数是安全的
p.ps = nullptr;
p.i = 0;
}
会产生编译错误
因为对于 h2 = std::move(h3); 这样的赋值语句来说,两个运算符匹配的一样好,从而产生了二义性
赋值运算符 operator=(HasPtr rhs):这个赋值运算符是按值传递参数的。当你尝试执行 h2 = std::move(h3); 时,它既可以通过拷贝构造函数将 h3 复制到 rhs 中,也可以通过移动构造函数将 h3 移动到 rhs 中
6.3 右值引用和成员函数
1、如果一个成员函数 同时提供 拷贝和移动版本,它也能 从中受益。这种允许移动的成员函数 通常使用与 拷贝/移动构造函数 和 赋值运算符相同的参数模式——一个版本 接受一个指向const的左值引用,第二个版本 接受一个指向非const的右值引用
void push_back(const X&); //拷贝:绑定到任意类型的X
void push_back(X&&); //移动:只能绑定到类型X的可修改的右值
可以将 能转换为类型x的任何对象 传递给 第一个版本的push_back。此版本 从其参数拷贝数据。对于第二个版本,我们只可以传递给它 非const的右值。此版本对于非 const的右值是精确匹配(也是更好的匹配)的,因此当我们传递一个 可修改的右值时,编译器会选择 运行这个版本。此版本会从 其参数窃取数据
一般来说,我们 不需要为函数操作定义 接受一个const X&& 或是 一个(普通的)X&参数的版本。当我们希望 从实参“窃取”数据时,通常 传递一个右值引用。为了达到这一目的,实参不能是const的。类似的,从一个对象进行拷贝的操作 不应该改变 该对象。因此,通常 不需要定义一个接受一个(普通的)X&参数的版本
为 StrVec类 定义另一个版本的 push_back
class StrVec {
public:
void push_back(const std::string&); //拷贝元素
void push_back(std::string&&); //移动元素
//其他成员的定义,如前
};
void StrVec::push_back(const string& s)
{
chk_n_alloc(); //确保有空间容纳新元素
//在first free指向的元素中构造s的一个副本
alloc.construct(first_free++, s);
}
void StrVec::push_back(string &&s)
{
chk_n_alloc(); //如果需要的话为str Vec重新分配内存
alloc.construct(first_free++, std::move(s));
}
construct函数 使用 其第二个和随后的实参的类型 来确定使用 哪个构造函数。由于 move返回一个右值引用,传递给 construct 的实参类型是 string&&。因此,会使用string的移动构造函数 来构造新元素
2、右值和左值引用成员函数:通常,我们在一个对象上 调用成员函数,而不管该对象 是一个左值 还是一个右值
string s1 = "a value", s2 ="another";
auto n = (s1 + s2).find('a');
// 此处我们对两个string的连接结果 —— 一个右值,进行了赋值
s1 + s2 = "wow!";
允许 向右值赋值。但是,我们可能希望 在自己的类中阻止这种用法。在此情况下,我们 希望强制 左侧运算对象(即,this指向的对象)是一个左值
指出this的左值 / 右值属性的方式 与 定义const成员函数相同,即,在参数列表后 放置一个引用限定符
class Foo {
public:
Foo &operator = (const Foo&) &; //只能 向可修改的左值赋值
//Foo的其他参数
};
Foo &Foo::operator = (const Foo &rhs) &
{
//执行将rhs赋予本对象所需的工作
return *this;
}
引用限定符 可以是&或&&,分别指出 this可以指向 一个左值或右值。类似const限定符,引用限定符 只能用于(非static)成员函数,且必须 同时出现在函数的声明和定义中
Foo &retFoo(); //返回一个引用;ret Foo调用是一个左值
Foo retVal(); //返回一个值:ret Val调用是一个右值
Foo i, j; //i和j是左值
i = j; //正确:i是左值
retFoo() = j; //正确:retFoo()返回一个左值
retVal() = j; //错误:retVal()返回一个右值
i = retVal(); //正确:我们可以将一个右值作为赋值操作的右侧运算对象
一个函数 可以同时用const 和 引用限定。在此情况下,引用限定符 必须跟随在 const限定符之后
class Foo {
public:
Foo someMem() & const; //错误:const限定符必须在前
Foo anotherMem() const &; //正确:const限定符在前
};
3、就像 一个成员函数可以根据 是否有const 来区分其重载版本一样,引用限定符 也可以区分 重载版本。而且,我们可以 综合引用限定符 和 const 来区分 一个成员函数的重载版本
class Foo {
public:
Foo sorted()&&; //可用于可改变的右值
Foo sorted() const &; //可用于任何类型的Foo
//Foo的其他成员的定义
private:
vector<int> data;
};
//本对象为右值,因此可以原址排序
Foo Foo::sorted() &&
{
sort(data.begin(), data.end());
return *this;
}
//本对象是const或是一个左值,哪种情况我们都不能对其进行原址排序
Foo Foo::sorted() const & {
Foo ret(*this); //拷贝一个副本
sort(ret.data.begin(), ret.data.end());
return ret; //返回副本
左值进行原址排序:
左值是具有持久身份的对象,可以被修改。因此,如果你有一个左值表示的容器对象(如数组或 std::vector),你可以直接对容器内的元素进行原址排序。例如:
std::vector<int> vec = {3, 1, 4, 1, 5, 9};
std::sort(vec.begin(), vec.end()); // 对 vec 中的元素进行原址排序
右值进行原址排序:
右值是临时的对象,通常不具有持久性,并且可能在排序后立即销毁。在实践中,对右值进行原址排序并不是一个常见的操作,因为右值通常是临时创建的对象,排序后可能没有持久的对象来使用排序后的结果
std::sort(std::vector<int>{3, 1, 4, 1, 5, 9}.begin(), std::vector<int>{3, 1, 4, 1, 5, 9}.end());
尽管在此示例中右值也可以进行原址排序,但它没有实际的应用场景,因为右值是临时的,排序后的结果无法持久地保存下来
编译器会根据调用 sorted的对象 的左值/右值属性 来确定使用哪个sorted版本
retVal().sorted(); //retVal() 是一个右值,调用Foo::sorted() &&
retFoo().sorted(); //retFoo() 是一个左值,调用Foo::sorted() const &
4、当我们定义 const成员函数时,可以定义 两个版本,唯一的差别是 一个版本有const限定 而另一个没有。引用限定的函数 则不一样。如果我们 定义两个 或 两个以上具有相同名字 和 相同参数列表的成员函数,就必须 对所有函数都加上 引用限定符,或者所有都不加(&/&&)
class Foo {
public:
Foo sorted() &&;
Foo sorted() const; //错误:必须加上引用限定符(&/&&)
//Comp是函数类型的类型别名
//此函数类型可以用来比较int值
using Comp = bool(const int&, const int&);
Foo sorted(Comp*); //正确:不同的参数列表
Foo sorted(Comp*) const; //正确:两个版本都没有引用限定符
};
5、为 StrBlob 添加一个右值引用版本的 push_back
void push_bach(string &&t) { data->push_back(std::move(t)); }
6、 sorted 定义如下,会发生什么
Foo Foo::sorted() const & {
Foo ret(*this);
return ret.sorted();
}
首先,局部变量 ret 拷贝了 被调用对象的一个副本。然后,对 ret 调用 sorted,由于 并非是函数返回语句 或 函数结束(虽然写成一条语句,但执行过程是 先调用 sorted,然后 将结果返回),因此编译器认为 它是左值,仍然调用 左值引用版本,产生 递归循环
如果更改定义为
Foo Foo::sorted() const & { return Foo(*this).sorted(); }
可以正确利用 右值引用版本 来完成排序。原因在于,编译器认为 Foo(*this) 是一个 “无主” 的右值,对它调用 sorted 会匹配右值引用版本
为什么Foo(*this)是一个右值
Foo(*this) 是一个临时对象,因为它是通过构造函数 调用创建的,而且构造函数调用 返回的是一个临时对象,即右值。即使 *this 是一个左值(因为在 const & 成员函数中)
Foo(*this) 是一个右值,它会调用 Foo 类的移动构造函数或复制构造函数(在这种情况下是复制构造函数),然后在返回的临时对象上调用 sorted() 成员函数
Foo.h
#pragma once
#ifndef FOO_H_
#define FOO_H_
#include <algorithm>
#include <iostream>
#include <vector>
class Foo {
public:
Foo sorted() const& {
std::cout << "Foo sorted() const&" << std::endl;
/*Foo ret(*this);
return ret.sorted();*/
// Foo ret = Foo(*this); ret不是左值,Foo(*this)是
return Foo(*this).sorted();
}
Foo sorted()&& {
std::cout << "Foo sorted()&&" << std::endl;
std::sort(vec.begin(), vec.end());
return *this;
}
private:
std::vector<int> vec;
};
#endif
13.58.cpp
#include "Foo.h"
using namespace std;
int main()
{
Foo fo;
fo.sorted();
return 0;
}
运行结果
术语表
1、拷贝并交换:涉及 赋值运算符的技术,首先 拷贝右侧运算对象,然后 调用 swap 来交换副本 和 左侧运算对象
2、移动迭代器:迭代器适配器,它生成的迭代器 在解引用时 会得到一个 右值引用
3、合成赋值运算符:编译器 为未显式定义 赋值运算符的类 创建的(合成的)拷贝 或 移动赋值运算符版本。除非 定义为删除的,合成的拷贝运算符 会逐成员地 将右侧运算对象赋值 或 移动到左侧运算对象
如果在类中没有显式定义赋值运算符重载函数,则编译器会合成一个赋值运算符。合成赋值运算符的形式类似于以下代码:
class MyClass {
public:
MyClass& operator=(const MyClass& rhs) {
if (this != &rhs) {
// 逐个成员赋值
member1 = rhs.member1;
member2 = rhs.member2;
// ...
}
return *this;
}
};
合成的赋值运算符 只会按成员逐个赋值,而不会 进行深度复制。如果类的成员 包含指向动态分配内存的指针,那么默认的合成赋值运算符 将会产生 浅拷贝,这可能导致 资源管理的问题。在这种情况下,通常需要 显式地定义 自定义的赋值运算符,以实现深度复制 或 其他需要的行为
需要注意的是,合成的移动赋值运算符只有在符合特定条件时才会被生成,否则编译器会继续使用合成的拷贝赋值运算符
在 C++11 及之后的版本中,如果类满足以下条件,编译器会生成合成的移动赋值运算符:
对于合成的移动赋值运算符而言,其生成的条件并不是必须有合成的移动构造函数存在。移动赋值运算符的生成条件是:
1)类没有显式声明移动赋值运算符;
2)类没有显式声明析构函数、复制构造函数、移动构造函数;
3)类的基类没有虚析构函数,且类的所有非静态数据成员都可以移动赋值
在这种情况下,如果右侧运算对象(rvalue)是可移动的,并且类的数据成员具有移动赋值运算符,合成的赋值运算符将会逐个成员地将右侧运算对象的成员移动到左侧运算对象,而不是进行拷贝赋值
class MyClass {
public:
int* ptr;
};
MyClass obj1;
MyClass obj2;
obj1 = std::move(obj2);
如果 ptr 是一个指向动态分配内存的指针,而且 MyClass 类 没有显式定义赋值运算符重载,那么编译器 会生成合成的赋值运算符。这个合成的赋值运算符 将会逐个成员地将 obj2 的成员 移动到 obj1 中,而不是 简单地进行指针的拷贝赋值