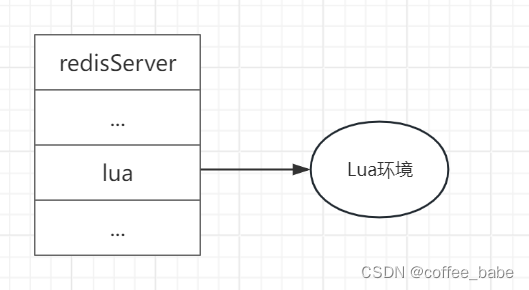
在未标记数据上进行预训练
本章概要
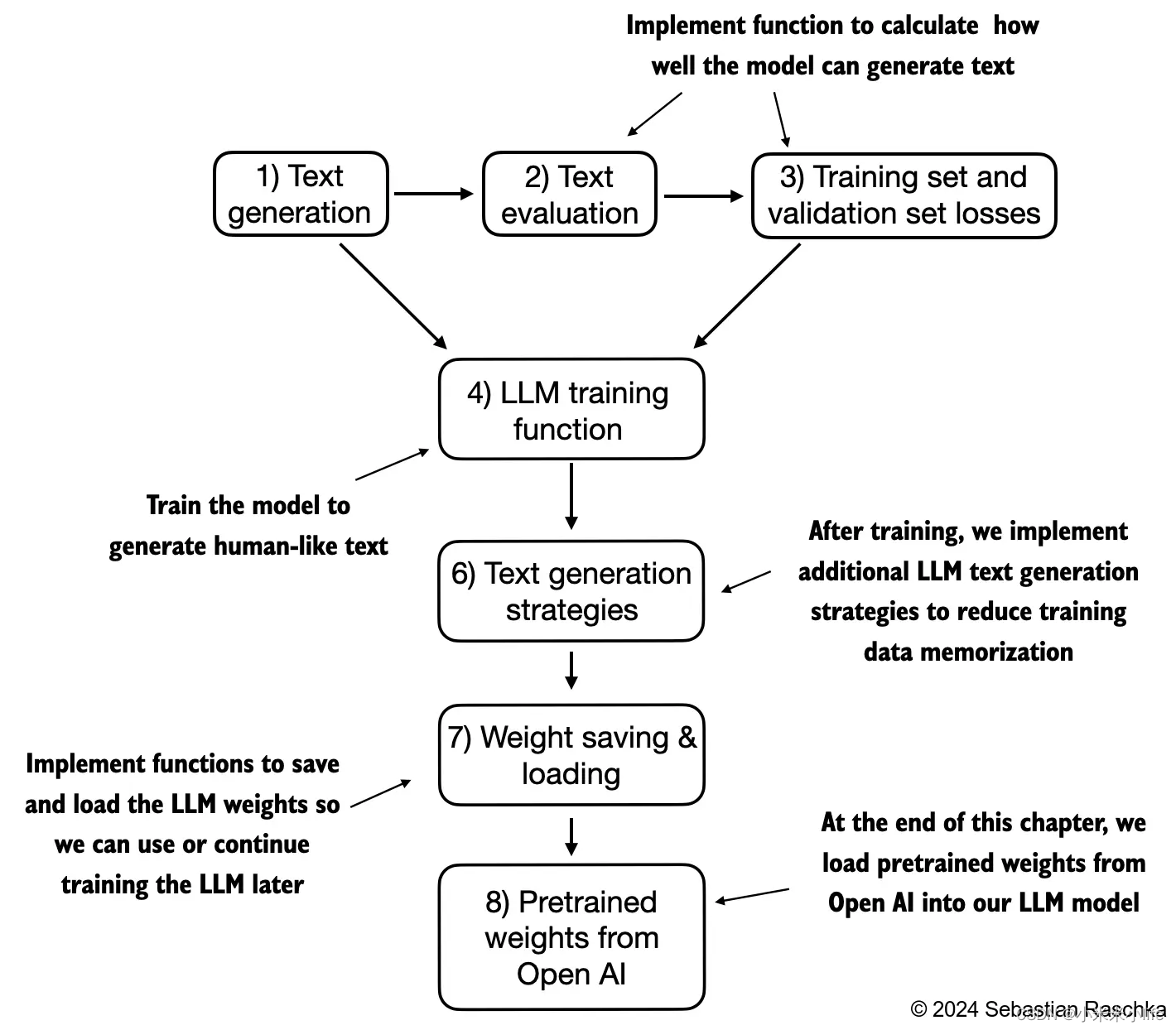
在上节的笔记中,因为训练出的效果,并不是特别理想,在本节中,会用数据进行训练,使得模型更加的好;

计算文本生成损失
inputs = torch.tensor([[16833, 3626, 6100], # ["every effort moves",
[40, 1107, 588]]) # "I really like"]
targets = torch.tensor([[3626, 6100, 345 ], # [" effort moves you",
[588, 428, 11311]]) # " really like chocolate"]
假设我们有一个inputs张量,包含了2个训练样本(行)的标记ID。,以下改图,进行阐释了此词汇表的产生

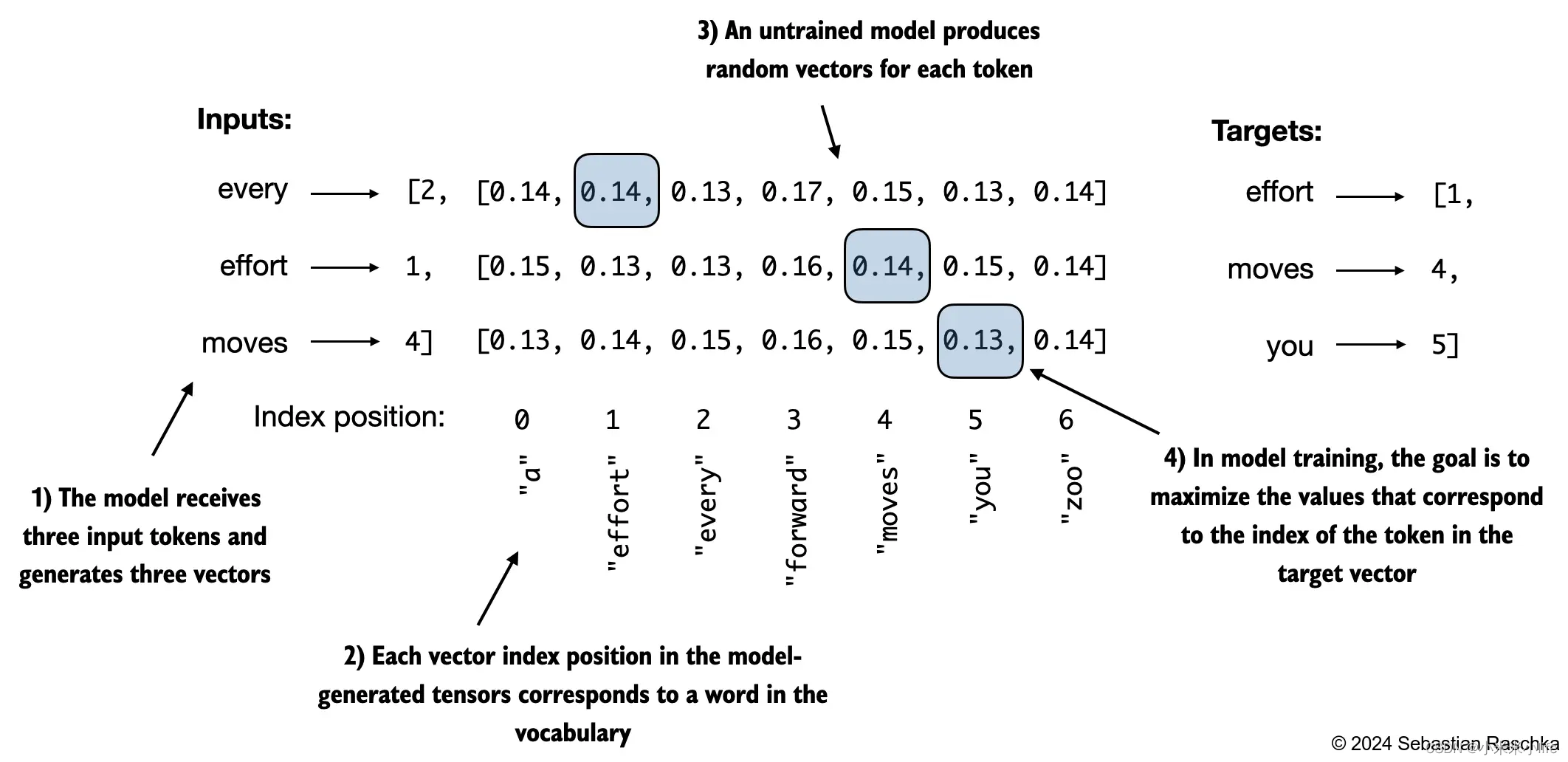
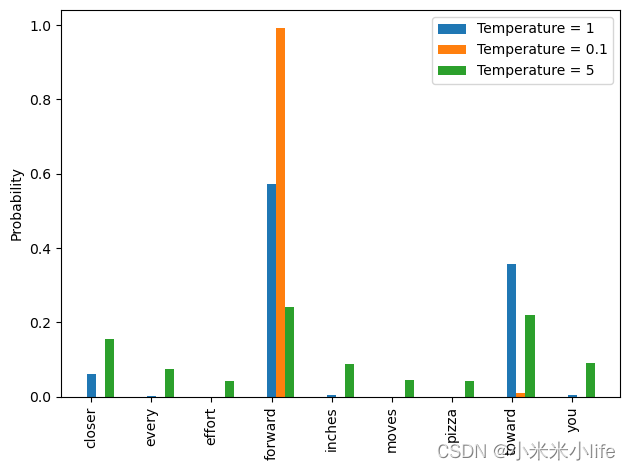
在数学优化中,最大化概率分数的对数比分数值本身更容易,这里介绍一个回归损失函数Youtube
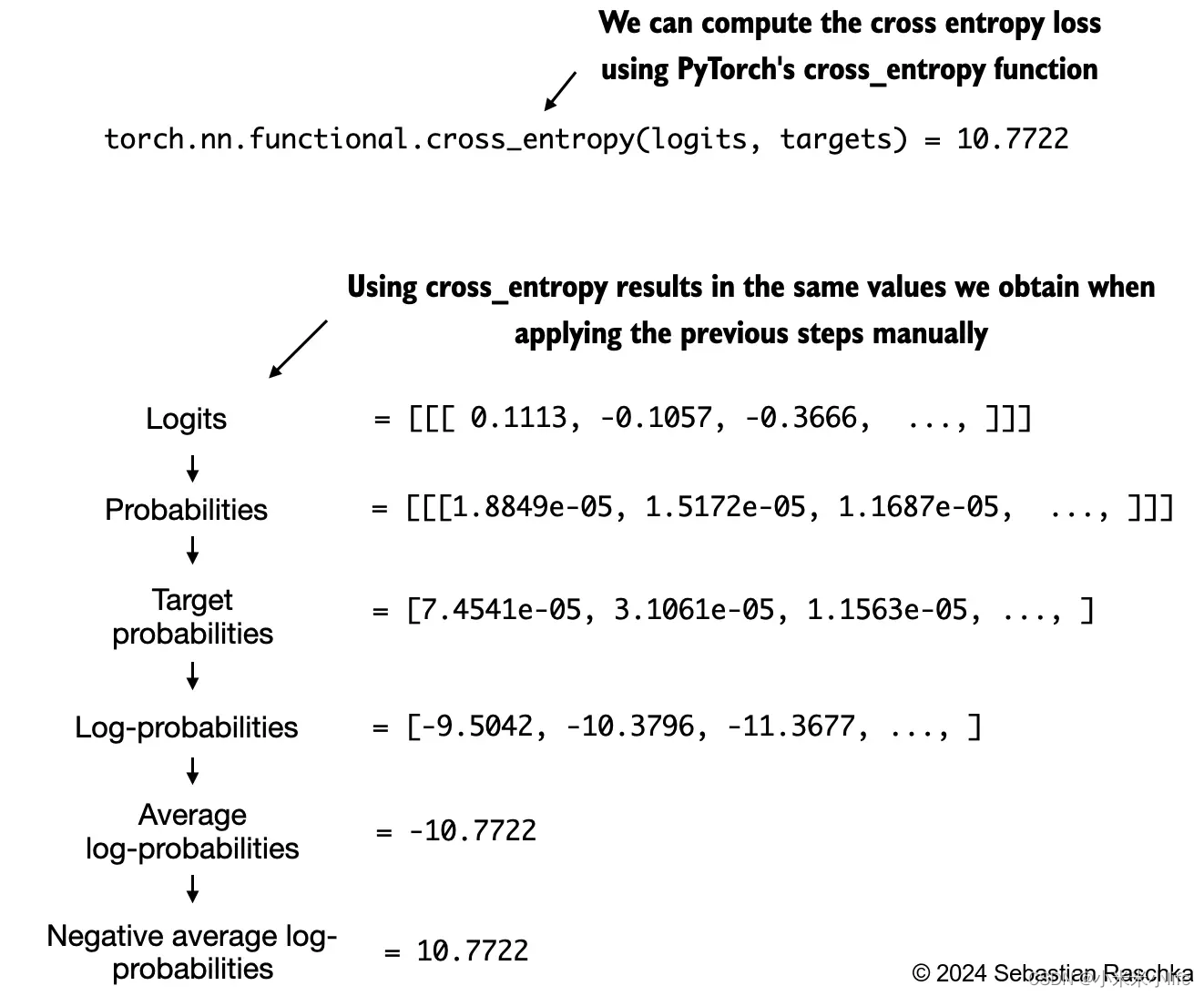
其中10.7722称为交叉熵损失。
训练阶段(代码整理完后更新)
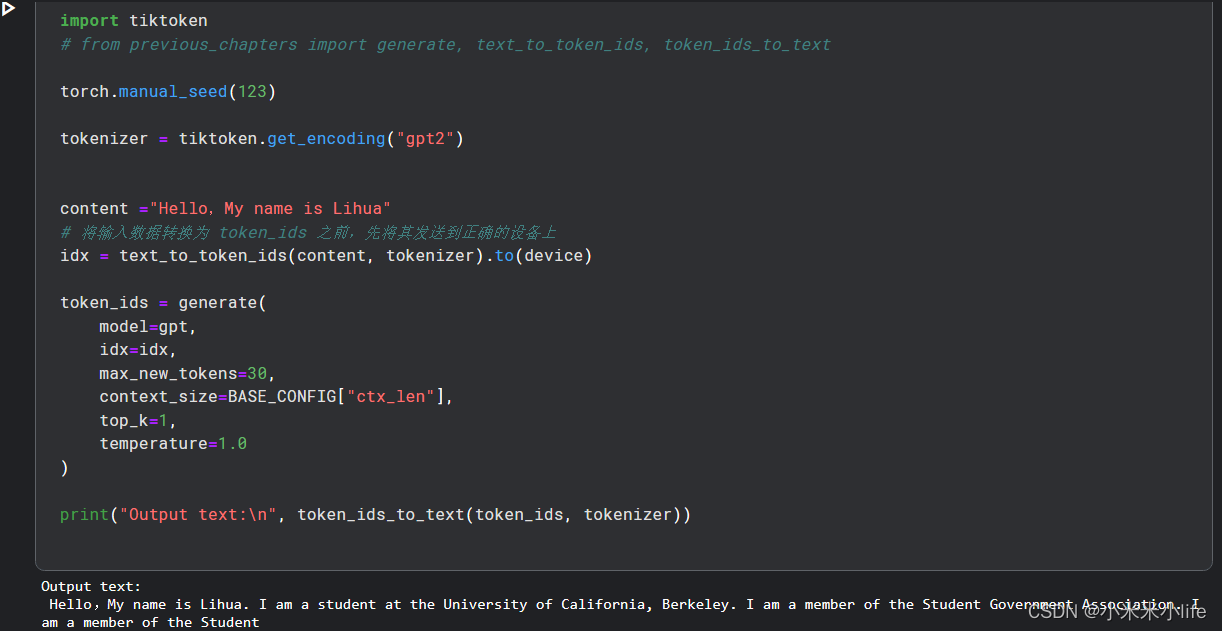
训练结果
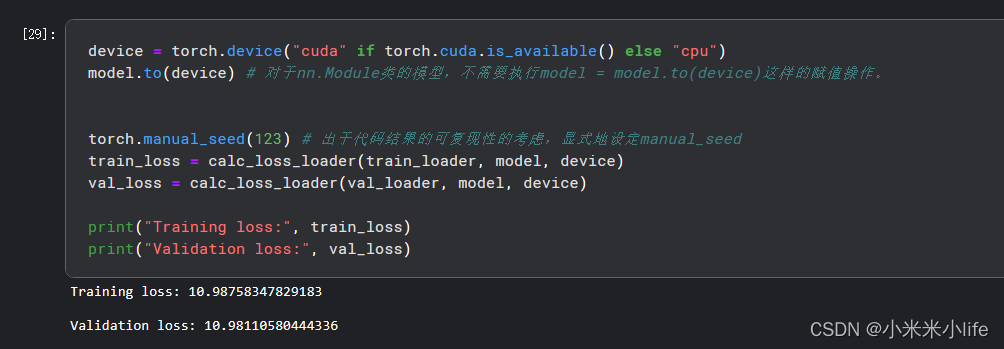
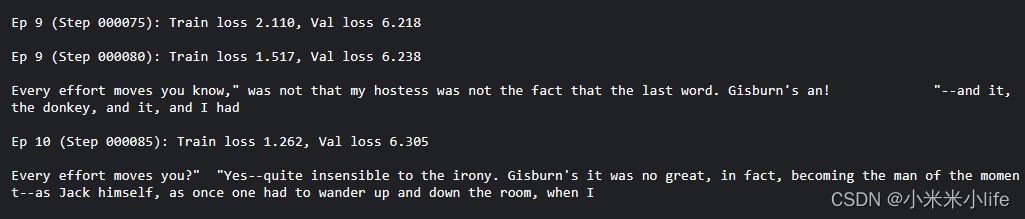
这次效果比上一节的效果好了很多。有很大的进步。