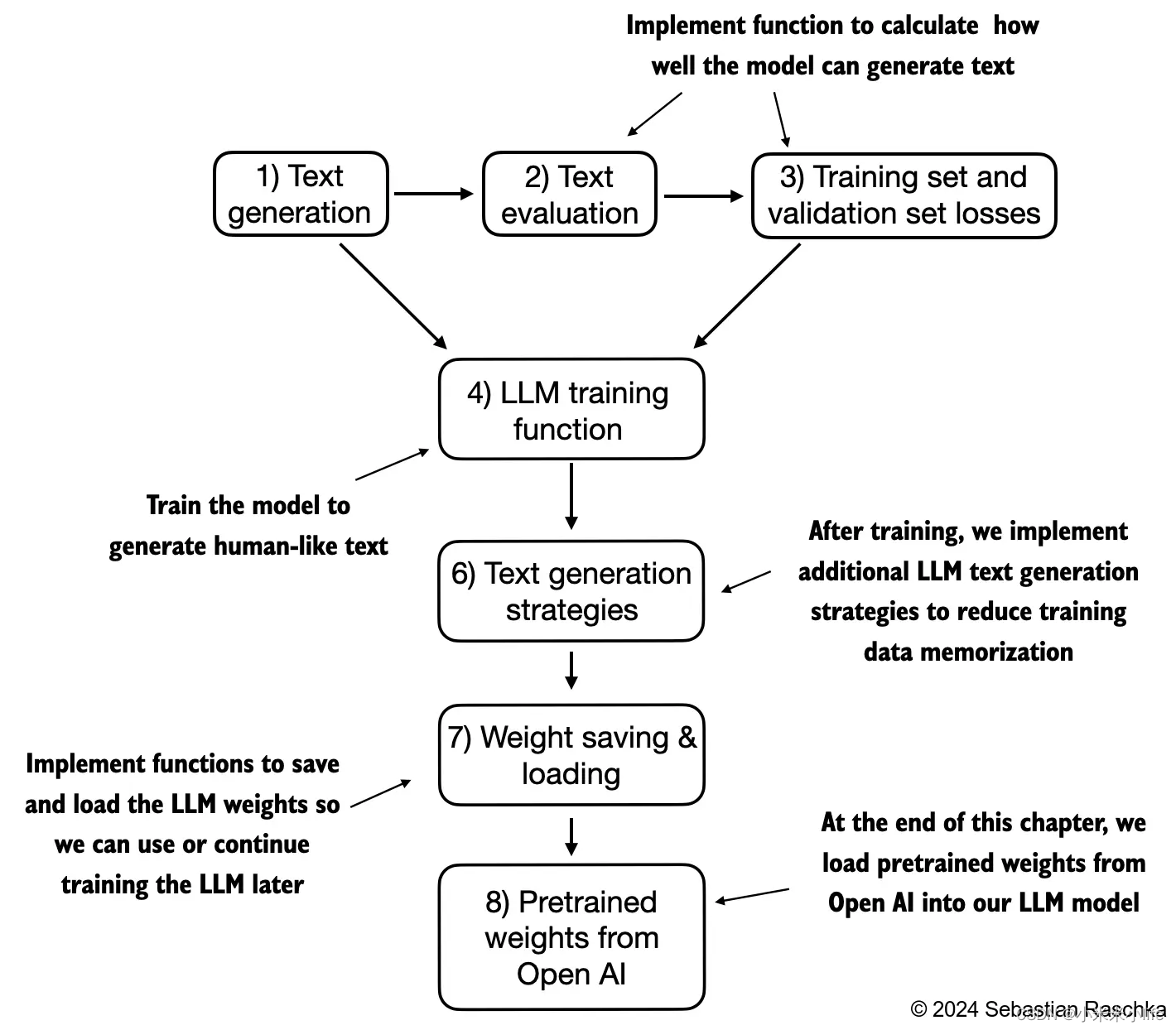
温度缩放
概念
1)在机器学习中,"温度缩放"通常指的是一种技术,用于调整神经网络输出的概率分布。这个技术通常在 softmax 函数的输出上进行操作。
2)在 softmax 函数中,神经网络会输出一个概率分布,表示每个类别的预测概率。温度缩放通过引入一个称为"温度"的参数来调整这些概率值。增大温度会使得概率分布更加平滑,降低温度会使得概率分布更加尖锐。
3)但是也不是说,温度越高越好,较高的温度可以使得概率分布更加平滑,从而降低模型的过度自信,有助于减少模型的过拟合,提高模型的泛化能力。然而,如果温度设置得过高,可能会导致模型失去了对真实分布的区分能力,造成预测的不准确性。另一方面,较低的温度可以使得概率分布更加尖锐,增强模型的置信度,有助于更准确地进行分类。但是,如果温度设置得过低,可能会导致模型过于自信,忽略了真实世界的不确定性,从而产生过拟合的风险。
下面是一个关于温度变化导致单词相关性变化的例子
vocab = {
"closer": 0,
"every": 1,
"effort": 2,
"forward": 3,
"inches": 4,
"moves": 5,
"pizza": 6,
"toward": 7,
"you": 8,
}
inverse_vocab = {v: k for k, v in vocab.items()}
# 假设input是 "every effort moves you", 模型返回的logits值为下面tensor中的数值:
next_token_logits = torch.tensor(
[4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79]
)
probas = torch.softmax(next_token_logits, dim=0)
next_token_id = torch.argmax(probas).item()
# 下一个标记:
print(inverse_vocab[next_token_id])
forward
torch.manual_seed(123)
next_token_id = torch.multinomial(probas, num_samples=1).item()
print(inverse_vocab[next_token_id])
toward
def print_sampled_tokens(probas):
torch.manual_seed(123) # Manual seed for reproducibility
sample = [torch.multinomial(probas, num_samples=1).item() for i in range(1_000)] # 使用torch.multinomial函数从probas中进行了1000次采样
sampled_ids = torch.bincount(torch.tensor(sample)) # 使用torch.bitcount函数统计每个token的采样数量
for i, freq in enumerate(sampled_ids):
print(f"{freq} x {inverse_vocab[i]}")
print_sampled_tokens(probas)
71 x closer
2 x every
0 x effort
544 x forward
2 x inches
1 x moves
0 x pizza
376 x toward
4 x you
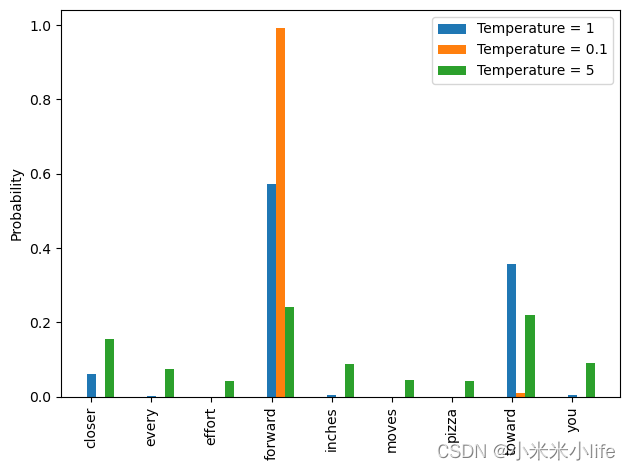
我们记:大于1的温度值将在应用softmax后导致更均匀分布的标记概率。
小于1的温度值将在应用softmax后导致更自信(更尖锐或更高峰)的分布。
def softmax_with_temperature(logits, temperature):
scaled_logits = logits / temperature
return torch.softmax(scaled_logits, dim=0)
# Temperature values
temperatures = [1, 0.1, 5] # Original, higher confidence, and lower confidence
# Calculate scaled probabilities
scaled_probas = [softmax_with_temperature(next_token_logits, T) for T in temperatures]
# Plotting
x = torch.arange(len(vocab))
bar_width = 0.15
fig, ax = plt.subplots()
for i, T in enumerate(temperatures):
# 条形图的绘制,ax.bar()函数里面的参数分别为条形的x轴位置、高度、宽度、图例标签
rects = ax.bar(x + i * bar_width, scaled_probas[i], bar_width, label=f'Temperature = {T}')
ax.set_ylabel('Probability')
ax.set_xticks(x)
ax.set_xticklabels(vocab.keys(), rotation=90)
ax.legend()
plt.tight_layout()
# plt.savefig("temperature-plot.pdf")
plt.show()
print_sampled_tokens(scaled_probas[1])#通过温度0.1进行重新缩放会得到一个更尖锐的分布
0 x closer
0 x every
0 x effort
992 x forward
0 x inches
0 x moves
0 x pizza
8 x toward
print_sampled_tokens(scaled_probas[2])#通过temperature=5重新缩放的概更加均匀
153 x closer
68 x every
55 x effort
223 x forward
102 x inches
50 x moves
43 x pizza
218 x toward
88 x you
通过这种方法调参,使得输出的变化更加趋向于平滑,但是也有缺陷使用上述方法有时会产生无意义的文本,例如“every effort moves you pizza”,这种情况发生的频率是3.2%。


























](https://img-blog.csdnimg.cn/cd12b8e7444248c5a57eed793c4f1fe0.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5YWl5Z2RJuWhq-WdkQ==,size_16,color_FFFFFF,t_70,g_se,x_16)