Cmake是什么?
很多C++小白刚进入公司开始接触业务代码的时候,或者在学校实验室接触一些大型的C++项目的时候,才发现有Cmake这个东西,一开始可能会有很大的疑惑:Cmake是什么?
而当你打开搜索引擎去检索Cmake的时候,搜索引擎告诉你Cmake仅仅是一个跨平台的编译工具,这时候你可能又会产生疑惑:为什么会有Cmake?C++还需要花费这么大精力去编译吗?之前在DEV,Visual Studio里明明一点“编译”,“运行”就能跑起来的程序,为什么现在还要去写Cmake去编译程序?有这么麻烦吗?
尽管当时的你有很多疑惑,但是你看不懂Cmake,你就无法适应你手上的工程,于是手头上面临的处境在逼迫你此时不得不了解Cmake,以满足生产环境的需要。而当你去找一些教程学习Cmake的时候,可能心里又会产生一个疑惑:为什么学习成本这么大?有必要搞这么麻烦吗?
事实上,如果你留心你所找的教程下面的评论或者公司里带你的师傅对你说过的话,你会发现他们好像都提过一句:Cmake不用学,用一用就会了。真相确实是这样,Cmake确实是用一用就会了。不信的话,你先去跟着一些教程去学一学,然后再来看这篇博文。
我们假定你现在已经系统学习了Cmake,那我现在要考一考你,如果说把你的工程里的CMake删除的话,你能重头到尾去写一个CMake吗?对于刚入门的C++程序员,我想你的答案应该是不能。是的,现在的你可能了解CMake中的每一个语法,每一个关键字,但是你还是无法写出一个CMake,原因在于现在的你不懂如何组织你的代码,这其实就是你看教程永远也学不会CMake的原因。而当你对你的工程比较熟悉之后,知道如何组织你的代码,这时候你就明白什么叫CMake不用学,用一用就会了。
但是这个过程是很艰难的。
Cmake是怎么出现的?
等你自己去写一个大型工程的时候,你会用到很多第三方库,你会需要把自己的代码打包成库,供他人使用,这时候,如果你还用学校里学的那一套:打开Visual Studio,新建文件,巴拉巴拉一大堆的时候,等到编译的时候,你就会知道为什么需要CMake。没有CMake肯定也能编译,但是那个复杂程度远超你的想象。
你的任务是把自己的工程跑起来,等你自己想办法仅仅为了绕开CMake去走传统的路子去跑你的程序的时候,你会发现,你在编译上花费的精力是巨大的,程序你已经写好了,却在最后一步编译上付出了很多努力,最后仅仅是为了运行,肯定是得不偿失的。
工具的出现是为了提高生产力,Cmake也是一样。现在的你可以这样想,在没有CMake时,已经有了这么一个人,走了刚刚你走过的路,但是等到他复盘的时候,发现自己的精力都花费在编译上了,这很不值得,于是,这个人想了一个办法,造出来了CMake这么个工具。
很多问题就是这样,你没有遇见过这个问题,所以你认为这个问题没有意义。CMake帮你解决了大型工程文件编译过程中的复杂问题,但是由于自身经验不足,你之前没有遇到过这种问题,所以一开始才会认为Cmake没有意义。
C++语言为什么会有头文件?
所有编程技术不断优化与升级的本质无外乎都是在做三件事情:
- 提升效率(程序运行相关)
- 减少重复
- 减轻依赖
我们试着反推这件事情,看看头文件是在解决什么问题。
#include 命令实际上只是将对应hpp中的文件原封不动的粘贴到#include所在位置,从这个角度而言,假如你的工程文件里有10个hpp,10个cpp,现在我们想砍掉所有的hpp文件,砍掉之后只剩下10个cpp文件,看上去我们的文件减少了,非常好,但是由于去掉了头文件,我们不得不做一些复制粘贴的工作:比如A.cpp中需要用到A.hpp中的add函数,由于砍掉了头文件,所以现在需要将hpp的声明原封不动的抄过来,还行,简简单单。然后你发现不光A.cpp中用到这个函数了,其他cpp文件中也遇到这个函数了,于是不得不再抄几份声明,抄来抄去发现:文件减少了,但是工作量却增加了!
这还只是一个函数,如果是一堆函数声明呢?
所以,现在明白了吗?我们可以借助头文件完成这些函数或者对象定义的快速复制粘贴,减少重复,从而提升工作效率。
就是这么简单,这些头文件在预处理阶段被展开到cpp中,之后的编译链接实际上用到的只是cpp文件。真正的编译单元只有cpp文件,头文件什么也不是,只是为了减少重复!
为什么会出现CMake?
要回答这个问题,我们需要先从源头说起。
C++程序是怎么编译的?
C++程序的编译流程
编译流程分为四个阶段:预处理、编译、汇编、链接
以Linux系统下g++编译为例:
通过g++的选项可以查看过程中的每一步

预处理: 处理一些#号定义的命令或语句(如#define、#include、#ifdef等),生成.i文件
编译:进行词法分析、语法分析和语义分析等,生成.s的汇编文件
汇编:将对应的汇编指令翻译成机器指令,生成二进制.o目标文件
链接:调用链接器对程序需要调用的库进行链接。链接分为两种
静态链接
在链接期,将静态链接库中的内容直接装填到可执行程序中。
在程序执行时,这些代码都会被装入该进程的虚拟地址空间中。
动态链接
在链接期,只在可执行程序中记录与动态链接库中共享对象的映射信息。
在程序执行时,动态链接库的全部内容被映射到该进程的虚拟地址空间。其本质就是将链接的过程推迟到运行时处理
举个例子,现在仅仅给你一个main文件,里面只声明了add函数并调用了add函数,但是不包括add函数的实现,现在要对这个main文件进行编译运行,那么会走到哪一步?前三步走完都不会报错,直到遇到链接,才会报错,因为找不到add函数的实现。
你可以这样理解:每个文件都是独立编译的,直到链接开始前,这些文件被处理成.o文件,里面是一些机器码,等到链接的时候,这些文件才被组合起来。声明相当于你提前向你的程序做出了一份承诺:我现在有一个add函数,你在main文件里只管调用就行,我已经在其它文件里实现了!于是,main文件转头忙活自己的事,尽管它没见过add函数的实现,因为你已经向它做出了承诺。但是等到链接的时候才发现:根本没有add函数的实现。所以报错。
C++程序编译演化史
你可以写一份main文件,按照上面的流程,使用g++一步一步编译看看每一步会输出什么文件。你在整个过程中遇到的命令大概如下:
g++ -E main.cpp -o main.i
g++ -E add.cpp -o add.i
g++ -S main.i -o main.s
g++ -S add.i -o add.s
g++ -c main.s -o main.o
g++ -c add.s -o add.o
g++ main.o add.o -o main
当然,一般情况下我们会这么编译:
g++ main.cpp add.cpp -o main
现在引入一个问题:你有一个大的工程文件,里面有上百个cpp文件,分别存放在不同的目录中。这种情况如果用g++编译,其难度可想而知。于是,可以得出一个结论:g++对于大型工程并不是特别好用。
接着我们尝试做一些改进。
g++敲命令去编译,对于大型文件简直就是噩梦,每次编译都要敲一大串命令。但是写成文件总比敲命令要方便,要是把这些命令写成文件,每次编译的时候直接复用这个文件就好了。于是,Makefile诞生了。
上面的一大串命令写成对应的Makefile文件是这样的:
main: main.o add.o
g++ main.o add.o -o main
main.o add.o: main.s add.s
g++ -c main.s -o main.o
g++ -c add.s -o add.o
main.s add.s:main.i add.i
g++ -S main.i -o main.s
g++ -S add.i -o add.s
main.i add.i: main.cpp add.cpp
g++ -E main.cpp -o main.i
g++ -E add.cpp -o add.i
Makefile底层执行逻辑是只执行第一个命令,也就是:
main: main.o add.o
g++ main.o add.o -o main
但是由于没有main.o add.o ,所以才会向下执行。具体的语法有兴趣可以去查相关资料,这不是本文的侧重点。
嗯,看起来Makefile是g++的升级,我们可以借助Makefile文件实现相对于直接使用g++更快的编译。我们的问题被解决了吗?解决了一部分,但是还没完全解决。这次的问题出在跨平台上。
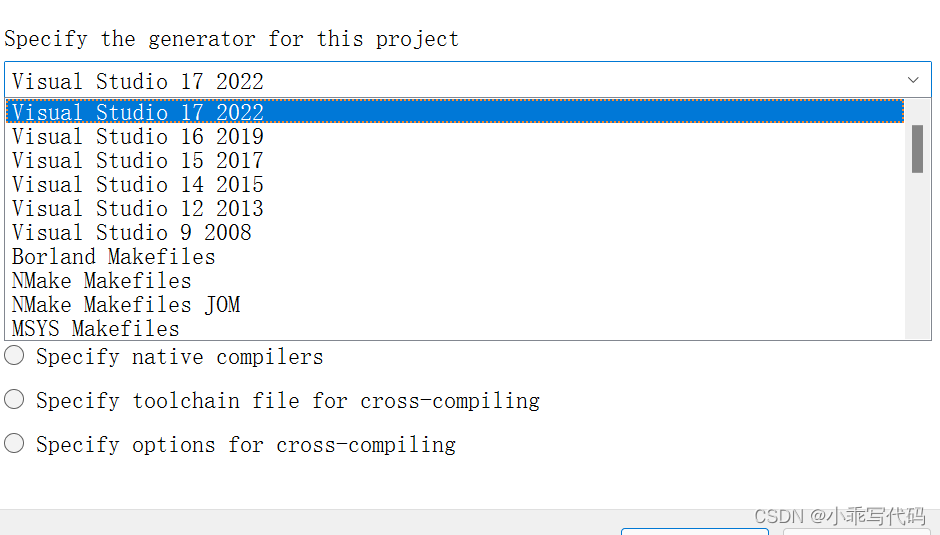
g++是Linux平台下的编译器,如果你使用win下的Visual Studio开发代码,它使用的是MSVC编译器,Makefile并不适用这种编译器,它跟Makefile相对应的文件是.sln文件。也就是说尽管大家都要经过预处理,编译,汇编,链接这四个步骤,但是大家走的路是不相同的。
于是,CMake就出现了。
Cmake本质上帮我们做的事情就是针对于不同的编译器,生成相对应的编译命令。针对Linux下的g++就是Makefile文件,针对win下的MSVC就是.sln文件。
CMake相当于在用户和操作系统上的编译器之间做了一层抽象,用户借助于CMake,不用关心自己的操作系统上用了什么编译器就能直接完成工程的快速编译。