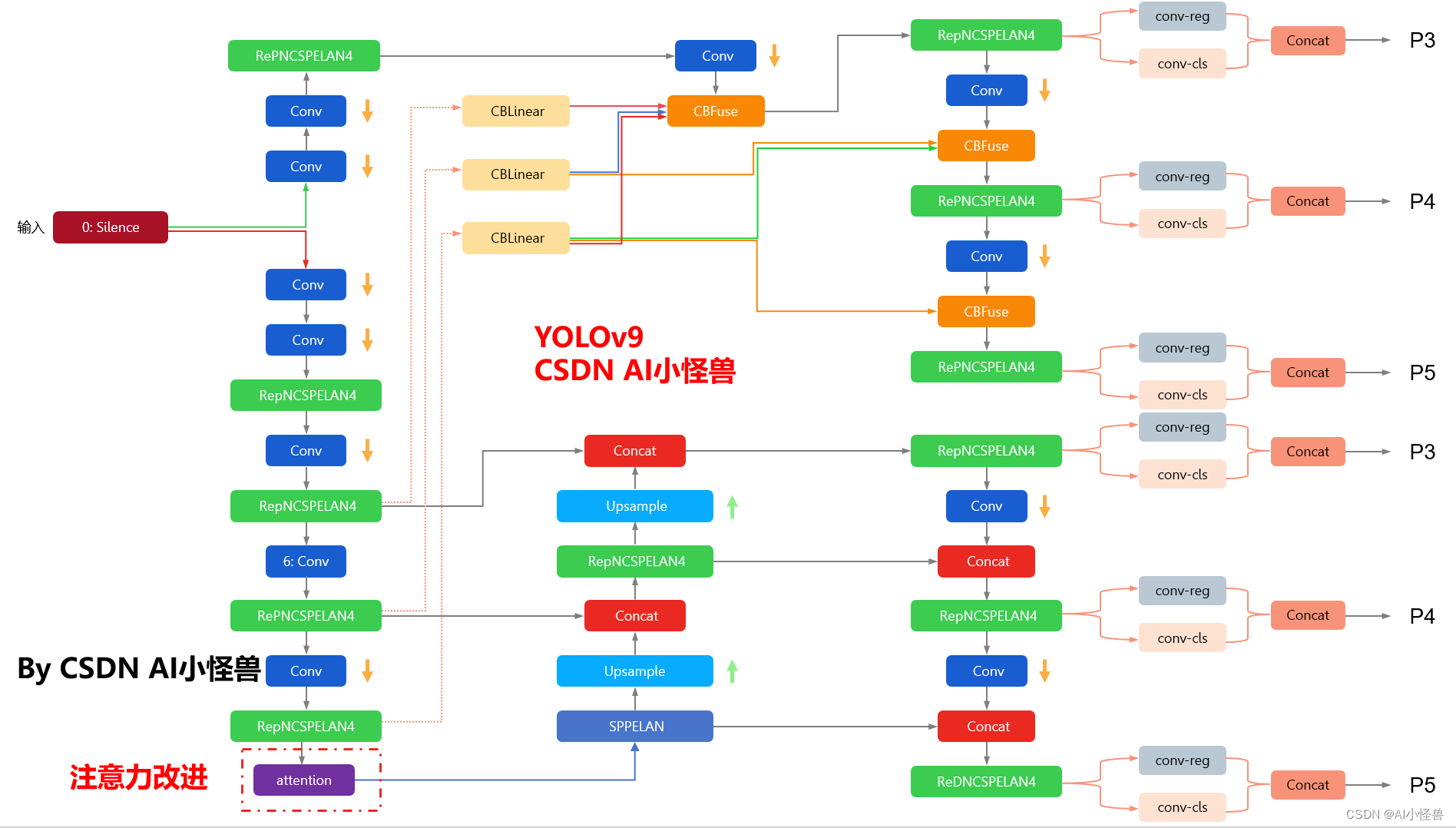
1.能够得到3D的占用信息
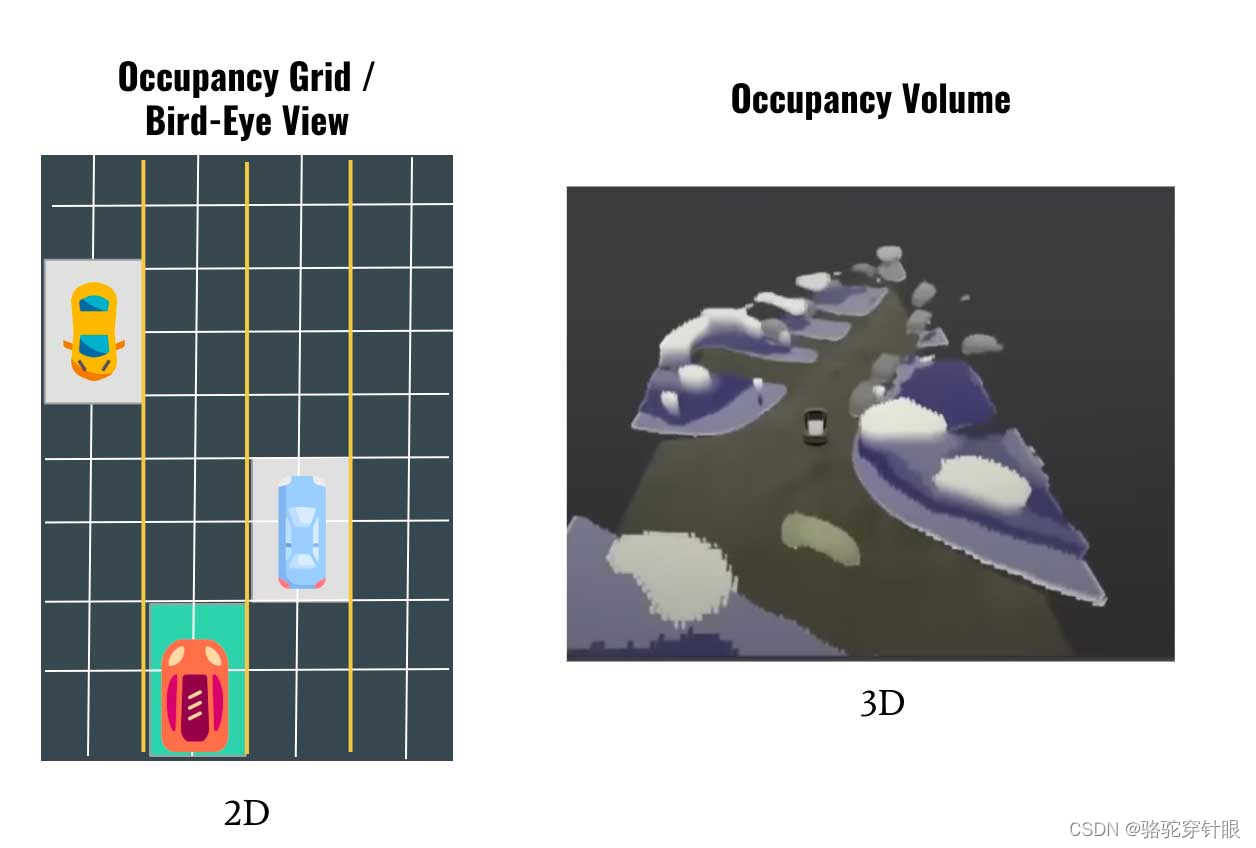
在基于BEV (鸟瞰图) 的2D预测模型中,我们通常仅具有二维平面(x和y坐标)上的信息。这种方法对于很多应用场景来说已经足够,但它并不考虑物体在垂直方向(z轴)上的分布。这限制了模型的能力,特别是在需要理解复杂场景的空间布局时,比如自动驾驶和机器人导航领域。在这些场景中,不同的物体可能在垂直方向上堆叠,比如一个车辆可能在桥下行驶,而桥梁则位于上方。在这种情况下,仅仅使用2D预测是无法区分这两个物体的。
引入高度方向上的信息,即将预测扩展到三维,极大地增强了模型的表现力。这种3D预测模型能够在相同的xy坐标上识别和区分出存在于不同z轴高度的多个物体。通过这种方式,模型可以更精确地预测物体的占用空间。这在某些xy坐标点上同时存在多个物体的情况下尤其重要,比如上述的桥下行驶的车辆和桥梁的例子。3D模型能够区分这些物体,并分别预测它们的位置和体积。
2.多模态的统一表现
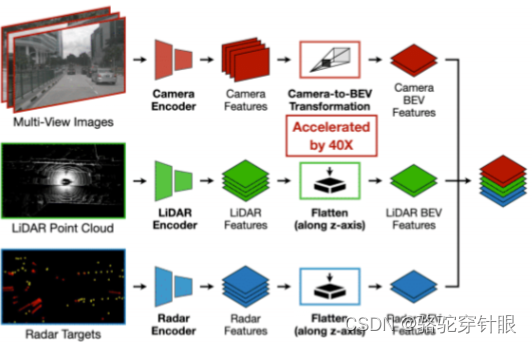
从感知系统的角度看,不同的传感器,如相机、激光雷达或其他类型,都可以在鸟瞰图(BEV)空间内统一回归占用空间(Occupancy)信息。这意味着无论数据来源的差异,最终都能融合到一个共同的框架下进行空间占用的推断。
在自动标注(AutoLabel)的应用中,从相机到激光雷达,甚至包括毫米波雷达和超声波传感器,都可以被转换为占用空间的数据表示。这一转换使得多种传感器获得的信息可以无缝集成,提升了数据处理的效率和一致性。
深入本质,占用空间信息可以被视为一个分辨率可变的体素(voxel)表示。如果将体素大小缩减至极限,理论上它可以精确到与点云相当的级别。这种表示不仅仅说明了空间被占用的状态,而且还能随着体素大小的减小而逐渐揭示出更多细节信息,为精确建模和分析提供可能。在实际应用中,这种高度精细的表示有助于提高感知系统的精确度,尤其在需要高度精细化处理的场景,如自动驾驶车辆在复杂城市环境中的导航,确保了更高的安全性和可靠性。
3. 分离语义和几何
当我们将语义分析(Semantic)与几何分析(Geometry)进行解耦时,我们允许自动驾驶系统的安全关键部分——几何信息——单独训练,从而获得更为精确和可靠的结构表达,而不受语义不确定性的干扰。这种解耦也部分避开了开放集检测(Open-set Detection)的挑战,因为它将几何信息的确立放在了首位,而不是依赖于可能不完整或不准确的语义标签。这为系统设计提供了一个更加可靠的安全层,因为它减少了对语义理解的直接依赖,特别是在未知或未标记对象的情况下。
























![[CVPR-24] Text-to-3D using Gaussian Splatting](https://img-blog.csdnimg.cn/direct/9b7c29cedf374019b7498c79e4fba314.png)


