Attention 机制
概述
自上而下的有意识的注意力,称为聚焦式注意力(Focus Attention). 聚焦式注意力也常称为选择性注意力聚焦式注意力是指有预定目的、依赖任务的,主动有意识地聚焦于某一对象的注意力
自下而上的无意识的注意力,称为基于显著性的注意力(Saliency Based Attention).基于显著性的注意力是由外界刺激驱动的注意,不需要主动干预,也和任务无关.
在计算能力有限的情况下, 注意力机制也可称为注意力模型.注意力机制(Attention Mechanism)作为一种资源分配方案,将有限的计算资源用来处理更重要的信息,是解决信息超载问题的主要手段
Attention的引入
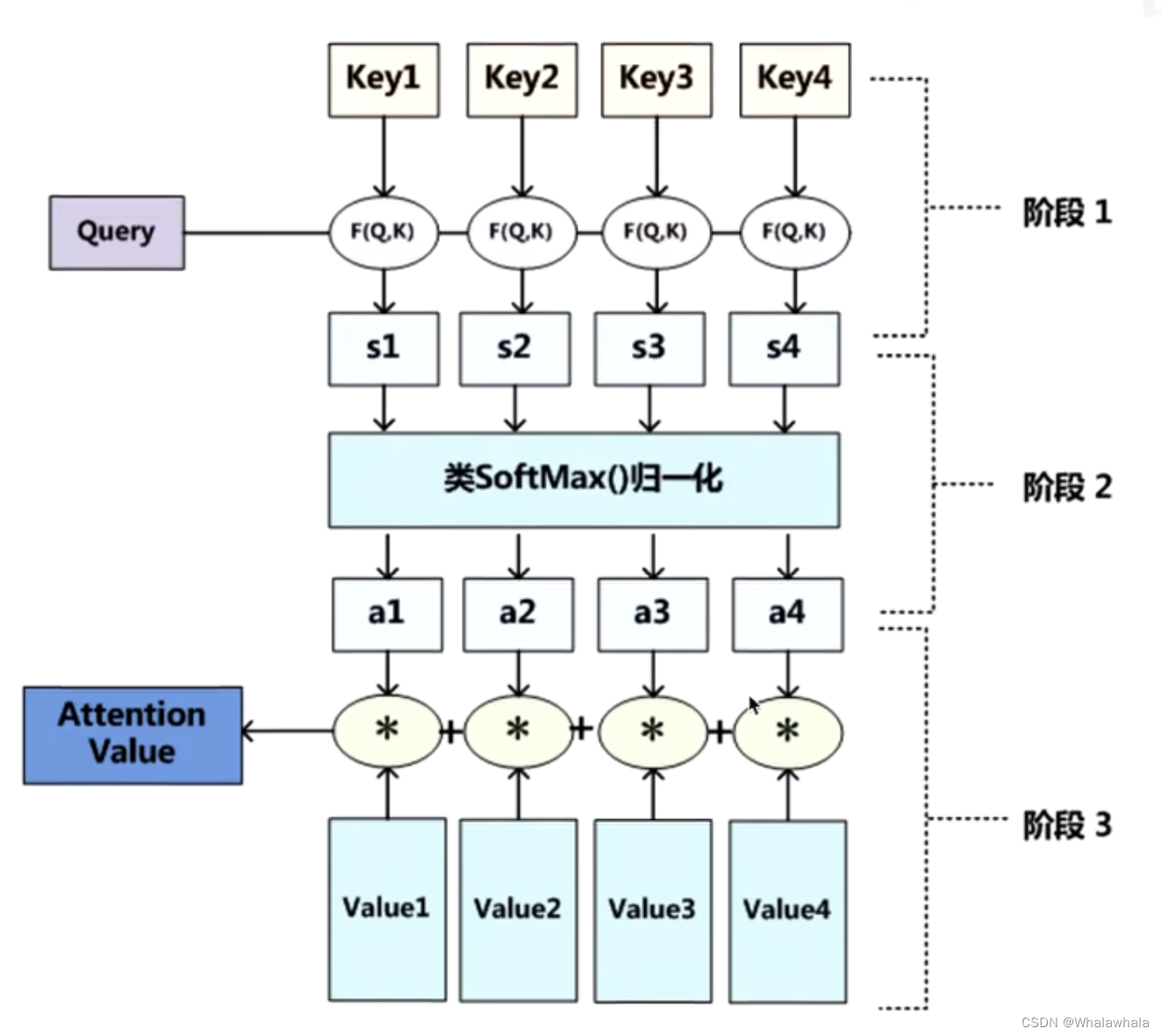
用 X = [ x 1 , ⋯ , x N ] ∈ R D × N X=[x_1,\cdots,x_N]\in\mathbb{R}^{D\times N} X=[x1,⋯,xN]∈RD×N表示 N N N组输入信息,其中 D D D 维向量 x n ∈ x_n\in xn∈ R D , n ∈ [ 1 , N ] \mathbb{R}^D,n\in[1,N] RD,n∈[1,N]表示一组输入信息。为了节省计算资源,不需要将所有信息都输入神经网络,只需要从 X X X中选择一些和任务相关的信息。 注意力机制的计算可以分为两步:一是在所有输入信息上计算注意力分布,二是根据注意力分布来计算输入信息的加权平均。
为了实现注意力机制,引入一个和任务相关的向量作为查询向量(query vector),并通过一个注意力打分机制计算输入向量与查询向量之间的相关性
给定一个和任务相关的查询向量 q q q,用注意力变量 z ∈ [ 1 , N ] z\in[1,N] z∈[1,N]来表示被选择信息的索引位置,即 z = n z=n z=n 表示选择了第 n n n 个输入向量.为了方便计算,我们采用一种“软性”的信息选择机制. 首先计算在给定 q q q和 X X X下,选择第 n n n个输入向量的概率 α n \alpha_n αn
α n = p ( z = n ∣ X , q ) = s o f t m a x ( s ( x n , q ) ) = exp ( s ( x n , q ) ) ∑ j = 1 N exp ( s ( x j , q ) ) \begin{aligned} \alpha_n &=p(z=n|X,q)\\ &= softmax\left ( s( \boldsymbol{x}_n, \boldsymbol{q}) \right ) \\ &=\frac{\exp\left(s(x_n,q)\right)}{\sum_{j=1}^N\exp\left(s(x_j,q)\right)} \end{aligned} αn=p(z=n∣X,q)=softmax(s(xn,q))=∑j=1Nexp(s(xj,q))exp(s(xn,q))
其中 α n \alpha_n αn称为注意力分布( Attention Distribution ) , s ( x , q ) (x,q) (x,q) 为注意力打分函数, 可以使用以下几种方式来计算:
加性模型 : s ( h , q ) = v T tanh ( W h + U q ) 点积模型 : s ( h , q ) = h T q 缩放点积模型 : s ( h , q ) = h T q D 双线性模型 : s ( h , q ) = h T W ˙ q \begin{aligned} \text{加性模型}:&s(h,q)=v^T\tanh(Wh+Uq) \\ \text{点积模型}:&s(h,q)=h^Tq\\ \text{缩放点积模型}:& s(h,q)=\frac{h^Tq}{\sqrt D}\\ \text{双线性模型}: &s(h,q)=h^T\dot{W}q\\ \end{aligned} 加性模型:点积模型:缩放点积模型:双线性模型:s(h,q)=vTtanh(Wh+Uq)s(h,q)=hTqs(h,q)=DhTqs(h,q)=hTW˙q
其中 W , U , υ W,U,\boldsymbol{\upsilon} W,U,υ为可学习的参数,D为输入向量的维度.
理论上,加性模型和点积模型的复杂度差不多,但是点积模型在实现上可以更好地利用矩阵乘积,从而计算效率更高.
当输入向量的维度 D D D比较高时,点积模型的值通常有比较大的方差,从而导致 Softmax 函数的梯度会比较小。因此,缩放点积模型可以较好地解决这个问题. 双线性模型是一种泛化的点积模型。公式中 W = U ⊺ V W=U^\intercal V W=U⊺V,双线性模型可以写为 s ( x , q ) = x ⊺ U ⊺ V q = ( U x ) ⊺ ( V q ) s(x,q)=x^\intercal U^\intercal V\boldsymbol{q}=(Ux)^\intercal(V\boldsymbol{q}) s(x,q)=x⊺U⊺Vq=(Ux)⊺(Vq),即分别对 x x x和 q q q进行线性变换后计算点积。相比点积模型,双线性模型在计算相似度时引入了非对称性。
注意力分布 α n \alpha_n αn 可以解释为在给定任务相关的查询 𝒒 时,第 𝑛 个输入向量受关注的程度,由此对输入信息汇总可得
att ( X , q ) = ∑ n = 1 N α n x n , = E z ∼ p ( z ∣ X , q ) [ x z ] . \operatorname{att}(X,q)=\sum_{n=1}^N\alpha_nx_n, =\mathbb{E}_{z\sim p(z|X,q)}[x_z]. att(X,q)=n=1∑Nαnxn,=Ez∼p(z∣X,q)[xz].
其中注意力机制如图所示

此为:注意力是软性注意力,其选择的信息是所有输入向量在注意力分布下的期望
Attention机制的变体
硬性注意力机制
若以选取最高概率的一个输入向量,即
att ( X , q ) = X n ^ \text{att}(X,q)=X_{\hat n} att(X,q)=Xn^
其中 n ^ = arg m a x n = 1 n α n \hat n=\arg max_{n=1}^n\ \alpha_n n^=argmaxn=1n αn
另一种硬性注意力可以通过在注意力分布式上随机采样的方式实现.
硬性注意力的一个缺点是基于最大采样或随机采样的方式来选择信息,使得最终的损失函数与注意力分布之间的函数关系不可导,无法使用反向传播算法进行训练.因此,硬性注意力通常需要使用强化学习来进行训练.为了使用反向传播算法,一般使用软性注意力来代替硬性注意力.
基于键值对的注意力机制
用 ( K , V ) = [ ( k 1 , υ 1 ) , ⋯ , ( k N , υ N ) ] (\boldsymbol{K},\boldsymbol{V})=[(\boldsymbol{k}_1,\boldsymbol{\upsilon}_1),\cdots,(\boldsymbol{k}_N,\boldsymbol{\upsilon}_N)] (K,V)=[(k1,υ1),⋯,(kN,υN)]表示 N N N组输入信息,给定任务相关的查询向量 q \boldsymbol{q} q时,注意力函数为
att ( ( K , V ) , q ) = ∑ n = 1 N α n υ n = ∑ n = 1 N exp ( s ( k n , q ) ) ∑ j exp ( s ( k n , q ) ) v n \begin{aligned} \operatorname{att}((K,V),\boldsymbol{q}) &=\sum_{n=1}^N\alpha_n\boldsymbol{\upsilon}_n\\ &=\sum_{n=1}^N\frac{\exp (s(k_n,q))}{\sum_j\exp (s(k_n,q))}v_n \end{aligned} att((K,V),q)=n=1∑Nαnυn=n=1∑N∑jexp(s(kn,q))exp(s(kn,q))vn
其中 s ( k n , q ) s(\boldsymbol{k}_n,\boldsymbol{q}) s(kn,q)为打分函数.
当𝑲 = 𝑽 时,键值对模式就等价于普通的注意力机制
多头注意力机制
多头注意力机制是采用多个查询向量 Q = [ q 1 , q 2 , … , q n ] Q=[q_1,q_2,\dots,q_n] Q=[q1,q2,…,qn],可以并行地从输入信息中选取多组信息。
a t t ( ( K , V ) , Q ) = a t t ( ( K , V ) , q 1 ) ⊕ ⋯ ⊕ a t t ( ( K , V ) , q M ) \mathrm{att}\Big((K,V),Q\Big)=\mathrm{att}\Big((K,V),q_1\Big)\oplus\cdots\oplus\mathrm{att}\Big((K,V),q_M\Big) att((K,V),Q)=att((K,V),q1)⊕⋯⊕att((K,V),qM)
其中 ⊕ \oplus ⊕表示向量拼接.
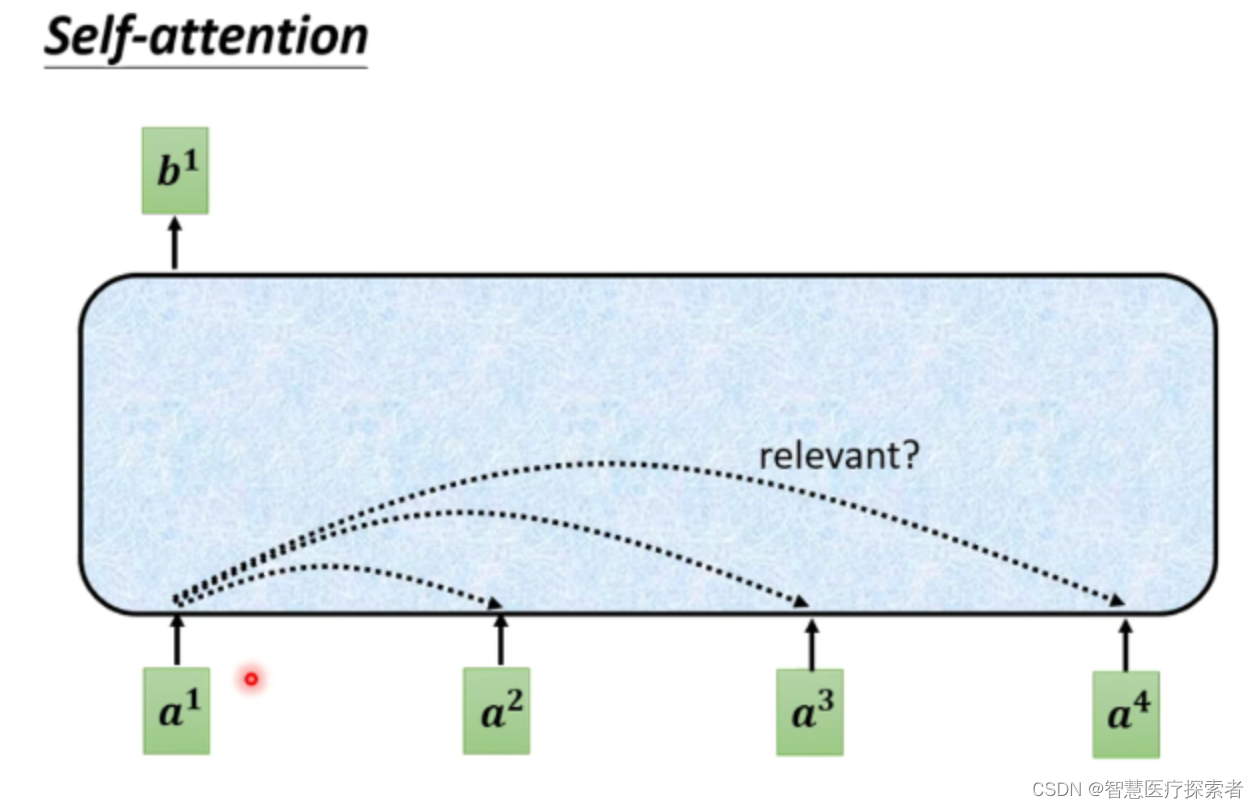
自注意力机制
不同的输入长度,其连接权重的大小也是不同的.自注意力也称为内部注意力(Intra Attention).这时我们就可以利用注意力机制来“动态”地生成不同连接的权重,这就是自注意力模型(Self-Attention Model).
为了提高模型能力,自注意力模型经常采用查询-键-值(Query-Key-Value,QKV)模式
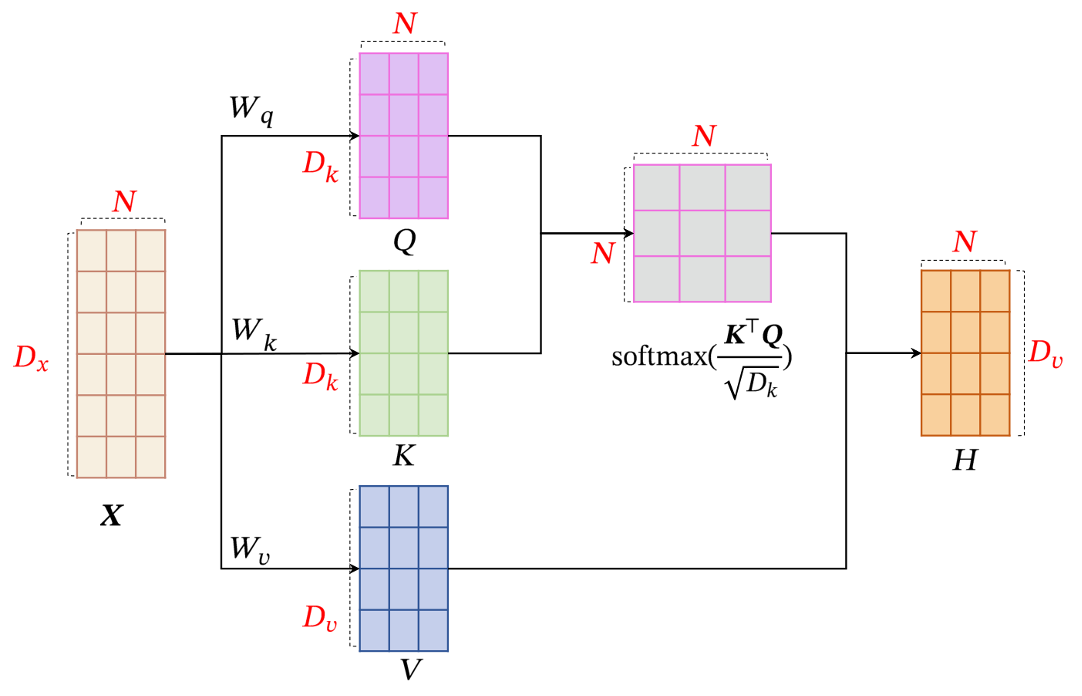
假设输入序列为 X = [ x 1 , ⋯ , x N ] ∈ R D x × N X=[x_1,\cdots,x_N]\in\mathbb{R}^{D_x\times N} X=[x1,⋯,xN]∈RDx×N,输出序列为 H = [ h 1 , ⋯ , h N ] ∈ H=[h_1,\cdots,h_N]\in H=[h1,⋯,hN]∈ R D υ × N \mathbb{R}^{D_\upsilon\times N} RDυ×N
首先将每个输入 x i x_i xi,我们首先将其线性映射到三个不同的空间,得到查询向量 q i ∈ R D k q_i\in\mathbb{R}^{D_k} qi∈RDk、键向量 k i ∈ R D k \boldsymbol{k}_i\in\mathbb{R}^{D_k} ki∈RDk和值向量 v i ∈ R D v . \boldsymbol{v}_i\in\mathbb{R}^{D_v}. vi∈RDv.
对于整个输入序列 X X X,线性映射过程可以简写为
Q = W q X ∈ R D k × N K = W k X ∈ R D k × N V = W υ X ∈ R D υ × N Q=W_qX\in\mathbb{R}^{D_k\times N}\\ K=W_kX\in\mathbb{R}^{D_k\times N}\\ V=W_\upsilon X\in\mathbb{R}^{D_\upsilon\times N} Q=WqX∈RDk×NK=WkX∈RDk×NV=WυX∈RDυ×N
然后对每一个查询向量 q n ∈ Q q_n\in Q qn∈Q,利用键值对注意力机制,可以得到输出向量 h n h_n hn,
h n = a t t ( ( K , V ) , q n ) \boldsymbol{h}_n=\mathrm{att}\Big((K,V),\boldsymbol{q}_n\Big) hn=att((K,V),qn)
![[论文阅读]Generalized <span style='color:red;'>Attention</span>——空间<span style='color:red;'>注意力</span><span style='color:red;'>机制</span>](https://img-blog.csdnimg.cn/direct/d5629a539212432a9becde3ad213c930.png)