由于此文章是记录为了笔者的学习过程而写的,因为可能在形式上会有些臃肿,且有些废话,若有错误的地方,请指正。
1.介绍
在处理多指标赋权的问题时,可以消除人为主观赋值带来的结果偏差,规避主观因素的影响,提高评价结果的客观性和准确性。
熵的物理意义是体系混乱程度的度量,当一个指标所具有的熵越大,说明其变化的越不确定,便越没有参考价值。
指标的熵值越大 -> 指标信息混乱程度越高 -> 不确定性越大 -> 信息量越小 -> 变异指数越小 -> 指标信息综合评价能力越弱 -> 指标权重越小
熵权由数据本身得出的,但存在许多局限性,例如,指标分为一级指标,二级指标等等,需要人为进行分类,例如计算一个产品是否能增产,则需要从成本,销售情况等,而成本又可以分为二级指标:人工成本,运输成本等。
2.指标类型:
由于每个指标对应的类型可能不同,而为了方便计算,则将其全部正向化
指标类型分为极大型,极小型,中间型,区间型
极大型:即数据越大越好,例如颜值,肯定越好看越好
极小型:即数据越小越好,例如亏损,亏损越少越好
中间型指标:靠近某一个值越好,例如水的ph
区间型指标:靠近某一个区间越好
正向化:即将指标类型全部化为极大型
由于每个指标对应的类型可能不同,而为了方便计算,则将其全部正向化
3.基本步骤
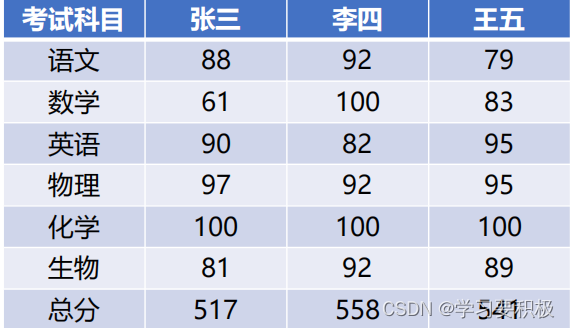
假设有n个参与评价的项目,m个评价指标,则可构建n*m 的矩阵A
1.先将矩阵正向化:(图出自b站up数模加油站)

2.正向化后矩阵标准化
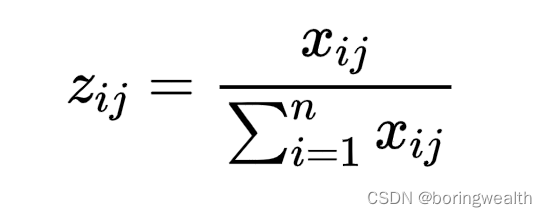
若矩阵中存在负值,由于后面会用到对数,所以不能有负数,则先利用

将矩阵里的值全部化为正数,然后进行标准化
3.计算概率矩阵p(对得到的Z进行归一化处理)
既
5.计算熵权
计算第j个指标的熵权:
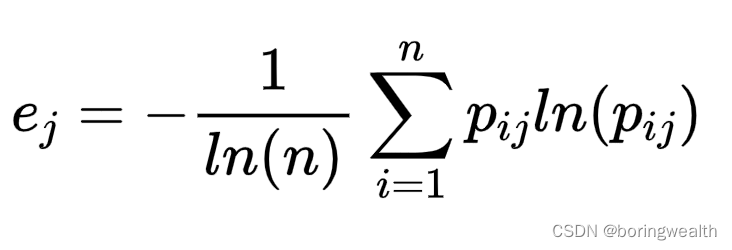
6.计算变异系数
7.计算熵权
第j个指标的权重为
3.python代码演示
1.先输入矩阵A
import numpy as np
print("请输入评价数目")
n = int(input())#由于input得到的为字符,则需要强制类型转化为int
print("请输入指标个数")
m = int(input())
A = np.zeros(shape=(n,m))#np.zeros()将A赋为0矩阵,shape则为A的行与列
print("请输入矩阵")
# 对A的每一行进行操作输入
for i in range(n):
#将输入的数值按照" "的形式分开形成列表
A[i] = input().split(" ")
A[i] = list(map(float, A[i]))代码解析:1.input().split(" ") 中split是将input中输入以" "空格来进行分割,并将分割后的数据放入一个列表中
a = input().split(" ")
print(a)
print(type(a))此为运行结果

2.map函数
map()有许多用法,例如做数组的运算,这里只提一种,将数组的元素转化为同一类型
但需要注意的是,进行map()操作后并不会影响a,简单来说map函数是将a的值拿来进行操作,但不赋予a
a = [1,2,3]
print("map前a[0]的类型",type(a[0]))
b = list(map(float,a))
print("map后a[0]的类型",type(a[0]))
print("b的类型",type(b[0]))
运行结果为

而由于a的类型为list,在对a进行map函数操作后,拿出了a中的值,若要赋予给b,则要将值放到一个与a的结构相似的类型中,例如a为list,map函数操作后,由于list与tuple结构类似可将值赋予给元组
2.将矩阵正向化
1.极小型指标正向化
import numpy as np
def minTomax(x): #x为指标所对应的列
max_1 = max(x) #取出x中最大值
#先转换为列表,才能进行列表操作遍历
x = list(x)
# 将x中的每一个元素进行 max -e的操作,e为x中元素的值,得到的ans为列表
ans = [[(max - e)] for e in x]
return np.array(ans) #返回矩阵形式2.中间型指标正向化
def midTomax(x):
print("请输入最优值")
best_n = eval(input())
x = list(x)
#abs为绝对值
y = [abs(bestx -e)for e in x]
max_y = max(y)
if max_y == 0:
max_y = 1 #防止最大差值为0,既这个指标全部数相同
ans = [[(1-e/max_y)] for e in y]
return np.array(ans) #返回矩阵形式3.区间型指标正向化
import numpy as np
def regTomax(lowx,highx,x):
print("请输入区间[a,b]的a:")
low_a = eval(input())
print("请输入区间[a,b]的b:")
high_b = eval(input())
x = list(x)
max_1 = max(lowx - min(x),highx - max(x))#求出指标区间最大的距离
if max_1 == 0:#防止指标全部数相同
max_1 =1
ans = []#创建一个空列表
for i in range(len(x)):#循环x的含有的元素个数的次数
if x[i] < lowx: #若元素小于lowx,则计算其与lowx的距离比上max_1(最大距离)
ans.append([1-(lowx - x[i])/max_1]) #append接长列表
elif x[i] > highx:#若元素大于highx,则计算其与highx的距离max_1(最大距离)
ans.append([1-(highx - x[i])/max_1])
else:#在区间内为一
ans.append([1])
return np.array(ans)#返回矩阵形式代码解析:
1.eval():即将元素转化为你输入的对应的原本类型
例如:
n = input()
m = eval(input())
# type()函数可以用来检测数据类型
print(type(n))
print(type(m))
#利用eval()将字符串类型转为整形
print(type(eval(n)))运行结果为:

再例如:
# 输入[1,2,3,4]
m = input() # 得到一个字符串
n = eval(input()) # 得到一个列表
print(type(m))
print(type(n))
print(type(n[0]))运行结果为:

由此我们便可以知道,eval函数便是将数据转化为我们所看见的,例如1就是1,不存在字符1,有[ ]就是列表,而不是字符串,其他形式也是如此,例如元组,字典等,以及计算
2.[表达式 for e in ]
在3-将正向化后的矩阵标准化中详细解释
3.append,用于接长列表
例:
a = [1,2,3]
print(a)
a.append(4)
print(a)运行结果:
可以看到,对a接长是直接从a后接上去,改变了a的值,与map()函数不同。
3.将正向化后的矩阵标准化
import numpy as np
for i in range(m):
min_a = min(A[: ,i])#取出第i列元素的最小值
max_a = max(A[: ,i])#取出第i列元素的最大值
if max_a == min_a:
max_a = max_a +1#避免分母为0
#防止有负数,全部化为正数
ans = [ [(e - min_a) / (max_a - min_a)] for e in A[:, i] ]
#ans此时为列表形式,需转化为矩阵形式
b = np.array(ans)
if i == 0:
z = b.reshape(-1,1)
elif i !=0 :
z = np.hstack([z, b.reshape(-1, 1)])
z = A/ np.sqrt(np.sum(A*A,axis = 0))代码解析:利用for循环将A中的每一列拿出来进行标准化,A[: , i ]既为A的第i列
利用min()与max()拿出第i列中最小的元素与最大的元素,并进行利用 [表达式 for e in ] 来进行标准化。
e为x的第j个元素,拿出e并且进行运算再以列表的形式储存起来,既e为第j个元素,其进行运算后将其赋值给其创建的列表并也是第j个元素,但也同样不改变x中的元素值
例:
import numpy as np
x = np.array([[1,2,3],
[3,4,5],
[4,5,9]])
ans = [ [(e -1 ) / 2] for e in x[: ,2] ]
print(type(ans))
print(x[:,1])运行结果:

ans为列表形式,且得到为行向量形式,为了与我们的矩阵对齐,我们需要列向量形式,为转变为列向量形式,为此我们进行numpy的reshape操作,但由于只能对数组操作,则将ans转化为数组形式
b = np.array(ans)reshape():重新定义数组的形状,reshape(-1,1)则为一列,自动组织行数,便将行向量形式转化为了列向量形式
hstack():水平堆叠函数,可以将行数相同的数组按水平方向堆叠在一起,便可以构造出我们的标准化矩阵。
import numpy as np
x = np.array([[1,2,3],[4,5,6]])
x_1 = x.reshape(-1,2)
print("reshape前 \n{}".format(x))
print("reshape后 \n{}".format(x_1))
y = np.array([[10],[11],[12]])
print(y)
x_2 = np.hstack([x_1 ,y])
print("水平堆叠后 \n{}".format(x_2))运行结果为:

4.将标准化后的矩阵化为概率矩阵(归一化)并进而算出熵与变异系数
import numpy as np
d = np.zeros(shape=(m))#构建变异系数的数组来储存每个指标对应的变异系数
for i in range(m):
x = z[:, i]
x_sum = np.sum(x)
if x_sum == 0 :
x_sum = n
x = np.ones(shape=(n,1))#构造全为一的列向量,由于x_sum要做分母,不能为0
#概率矩阵p
p = x / x_sum
#算熵
e = -np.sum(p * my_log(p))/np.log(n)
#信息效用值d
d[i] = 1-e由于可能为0,所以不能简单的直接写成ln(
),会报错,自定义一个函数my_log用于计算
def my_log(a):
n = len(a)#算出传入p的长度,以决定循环次数
lnp = np.zeros(n)
for i in range(n):
if p[i] == 0:
lnp[i] = 0
else:
lnp[i] = np.log(p[i])
return lnp4.算出熵权
import numpy as np
W = d / np.sum(d)由于每个指标的对于人们的重要程度不同,有时数据往往不能真正反映人们对此指标的喜爱,因此也难以达到真正的客观,在此基础可以使用topsis法等赋权方法人为的赋予一个权重,再进行归一化,能真实一点。