yolo系列
1.You Only Look Once: Unified, Real-Time Object Detection cvpr2016
https://bbs.huaweicloud.com/blogs/392995
预处理数据集得到 yolov1需要的label
训练
后处理数据得到方便显示的方式。
后处理:98个bbox , 20个种类, 然后NMS处理
https://zhuanlan.zhihu.com/p/416909015
2.yolov2
YOLO系列算法精讲:从yolov1至yolov8的进阶之路(2万字超全整理)
2.1 BN
在卷积或池化之后,激活函数之前,对每个数据输出进行标准化

2.2 anchor box
anchor box就是
首先一个数据集中的所有 gt box分析,
得到若干个固定 height, width的 box, 成为anchor box
这些anchor box具有一定的代表性。
在预测的时候,不是像 yolov1直接预测 x,y,h,w而是预测 相对于预先得到的anchor box的偏移量。
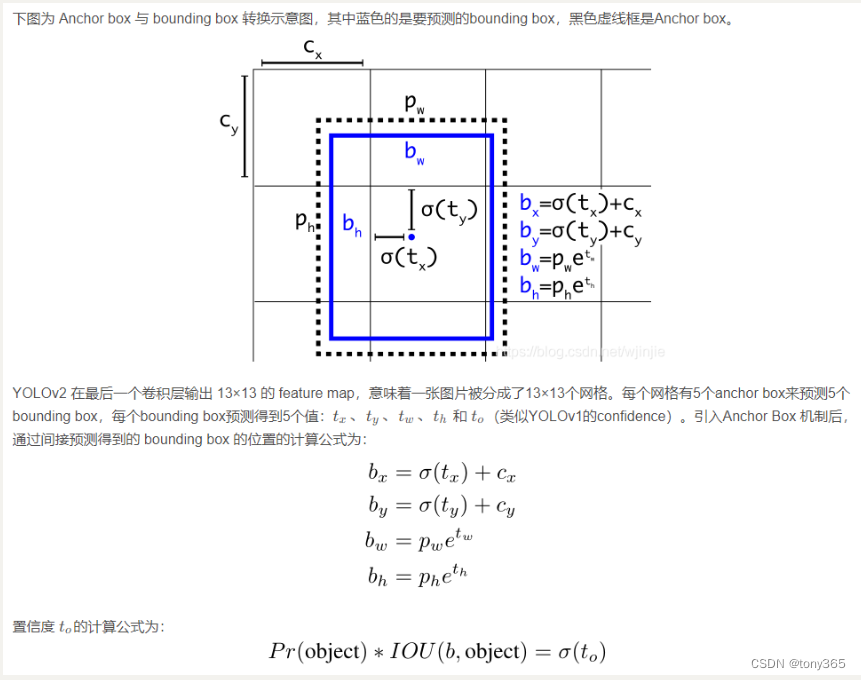
预测的4个数是 tx, ty, th, tw
yolov2 选择了5个anchor box。 faster rcnn中凭经验选择了9个anchor box, yolov2中选择了5个anchor box, 这5个anchor box是通过对数据集中的左右标注好的gt box 聚类得到的。
聚类的目的是得到若干个anchor box 的高度和宽度 。
使 Anchor boxes 和临近的 ground truth boxes有更大的IOU值

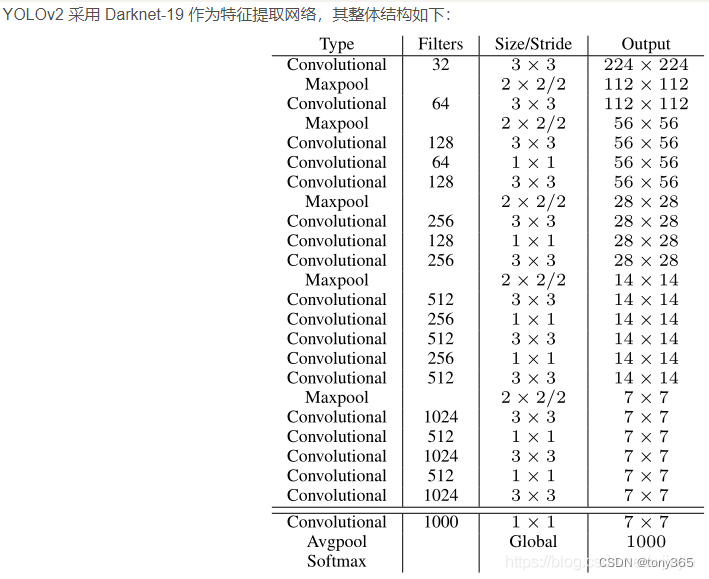
2.3 网络结构
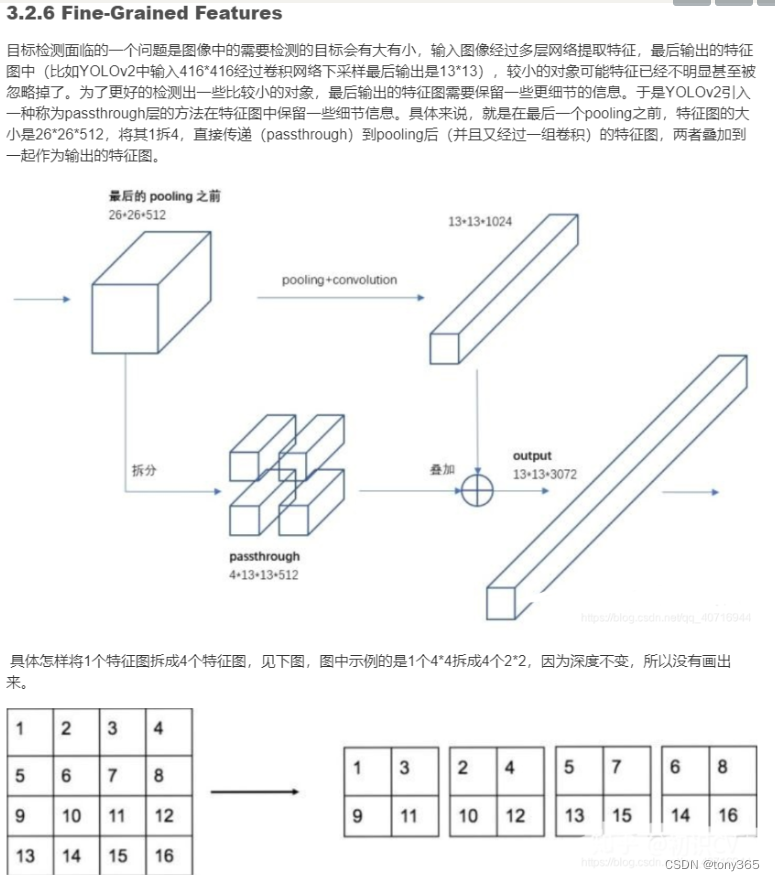
2.4pass through 模块
3.yolov3
3.1结构
https://blog.csdn.net/leviopku/article/details/82660381
把结构介绍的很详细:
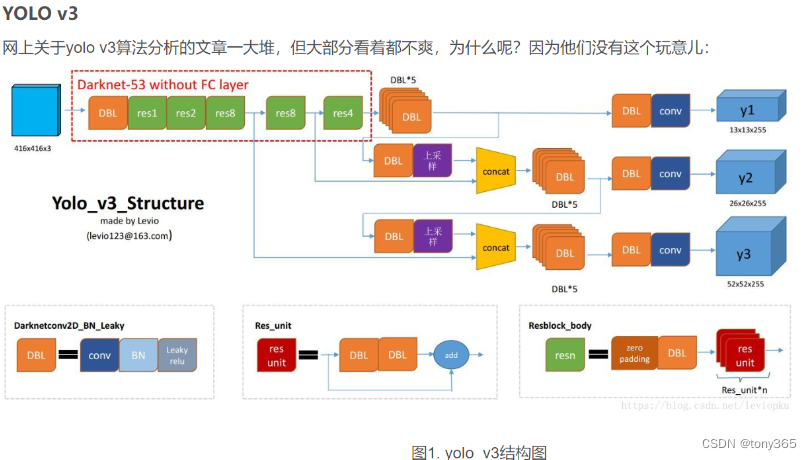
与darknet-19对比可知,darknet-53主要做了如下改进:
没有采用最大池化层,转而采用步长为2的卷积层进行下采样。
为了防止过拟合,在每个卷积层之后加入了一个BN层和一个Leaky ReLU。
引入了残差网络的思想,目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。
将网络的中间层和后面某一层的上采样进行张量拼接,达到多尺度特征融合的目的。
https://blog.csdn.net/wjinjie/article/details/107509243
3.2anchor
v3 和 v2一样也是预测相对位置:
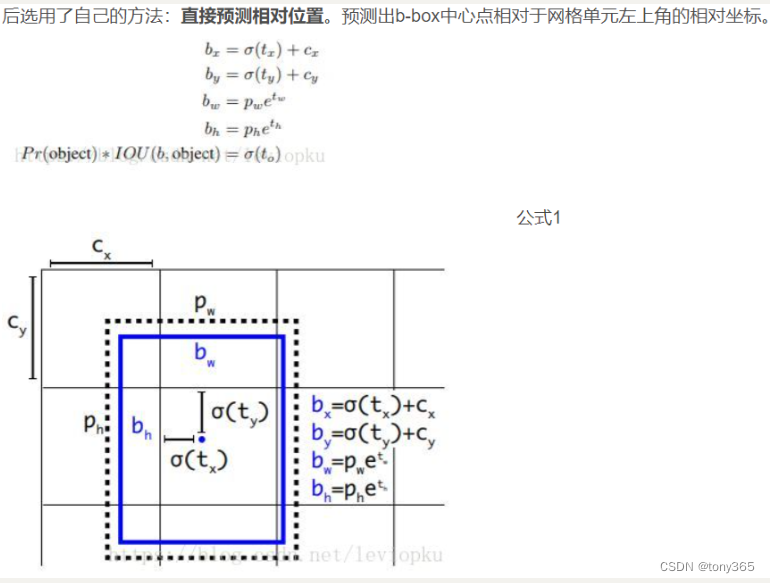
v3的anchor选用数量是9个:
高度,宽度

3.3output
output是

9个anchor 按size 对应 y1,y2,y3 各三个anchor.
损失函数:

4.yolov4
YOLO系列算法精讲:从yolov1至yolov8的进阶之路(2万字超全整理)
4.1 CSPNet全称是Cross Stage Partial Networ
在前面的YOLOv3中,我们已经了解了Darknet53的结构,它是由一系列残差结构组成。进行结合后,CSPnet的主要工作就是将原来的残差块的堆叠进行拆分,把它拆分成左右两部分:主干部分继续堆叠原来的残差块,支路部分则相当于一个残差边,经过少量处理直接连接到最后。
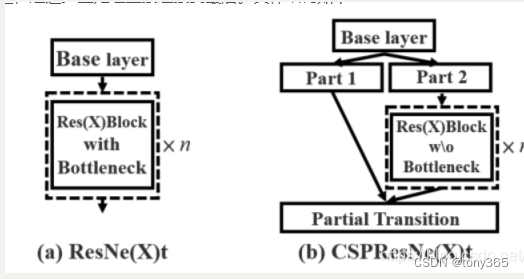
CSPNet和PRN都是一个思想,将feature map拆成两个部分,一部分进行卷积操作,另一部分和上一部分卷积操作的结果进行concate。
从实验结果来看,分类问题中,使用CSPNet可以降低计算量,但是准确率提升很小;在目标检测问题中,使用CSPNet作为Backbone带来的提升比较大,可以有效增强CNN的学习能力,同时也降低了计算.
作者认为网络推理成本过高的问题是由于网络优化中的梯度信息重复导致的。CSPNet 通过将梯度的变化从头到尾地集成到特征图中,在减少了计算量的同时可以保证准确率。CSP(Cross Stage Partial Network,简称 CSPNet) 方法可以减少模型计算量和提高运行速度的同时,还不降低模型的精度,是一种更高效的网络设计方法,同时还能和Resnet、Densenet、Darknet 等 backbone 结合在一起。
网络结构如下:
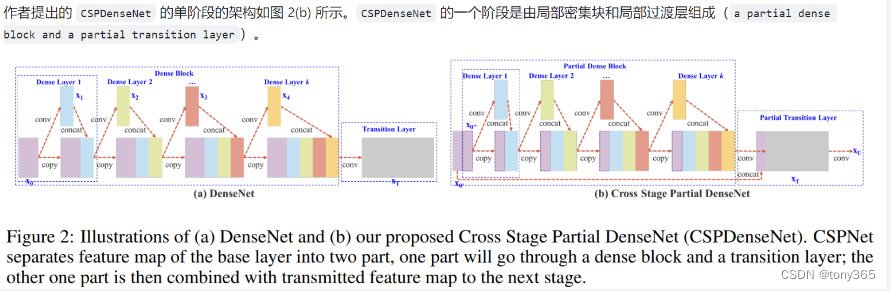
Transition layer 的含义和 DenseNet 类似,是一个 1x1 的卷积层(没有再使用 average pool)。上图中 transition layer 的位置决定了梯度的结构方式,并且各有优势
4.2 mish代替 leaky relu
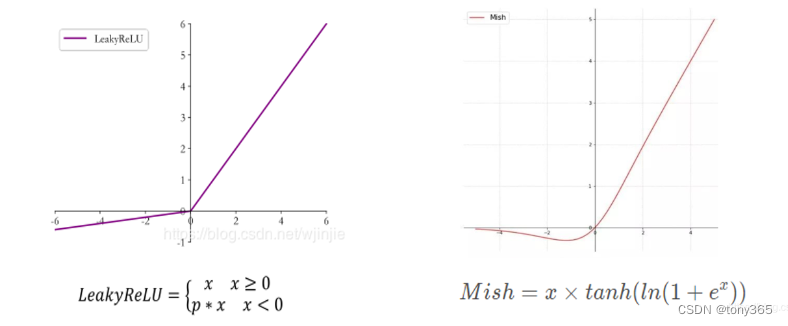
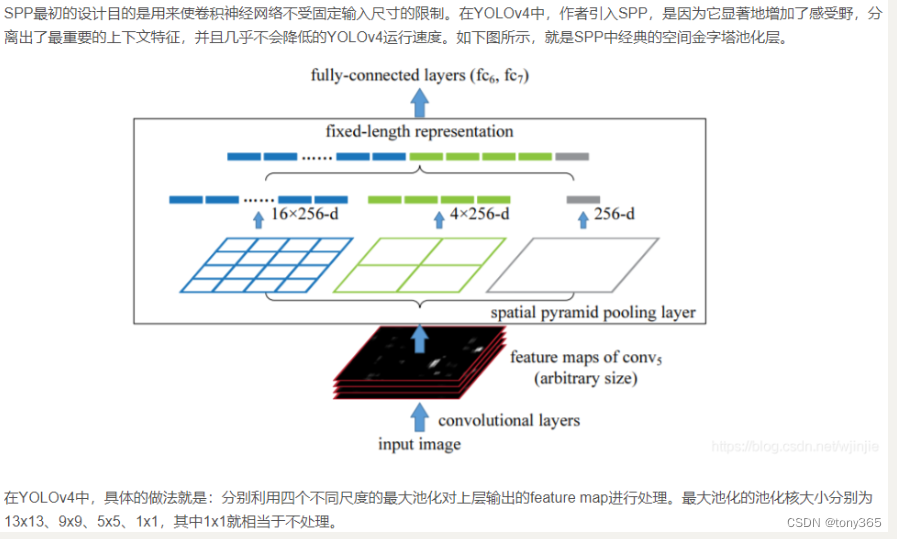
4.3 spp结构
SPP来源于这篇论文:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
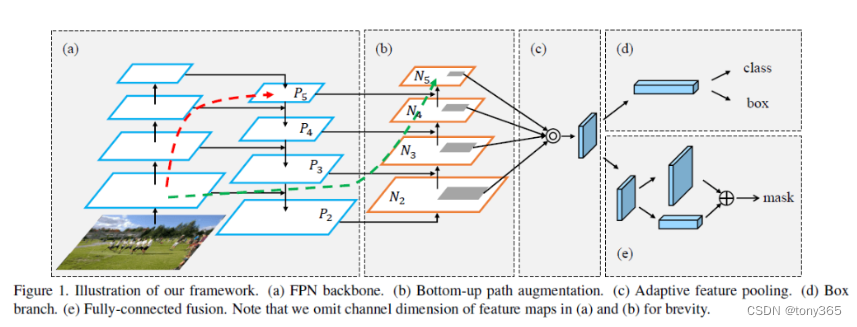
4.4 PANet
《Path Aggregation Network for Instance Segmentation》
这篇文章发表于CVPR2018,它提出的Path Aggregation Network (PANet)既是COCO2017实例分割比赛的冠军,也是目标检测比赛的第二名。代码和模型见:https://github.com/ShuLiu1993/PANet。
4.5 数据增强方法 mosaic

总之 yolov4 有特别多的tricks.
YOLOv4的体系结构确定为:CSPDarknet53(主干) + SPP附加模块(颈) + PANet路径聚合(颈) + YOLOv3(头部)
4.6 结构
前面介绍了相关组块的结构和论文来源,再来看下整体结构会更加清晰明了:
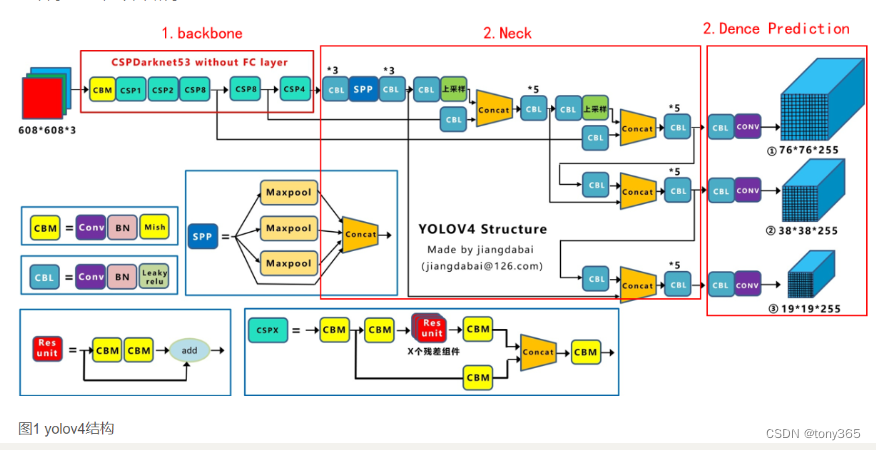
https://zhuanlan.zhihu.com/p/143747206
5. yolov5
也是从yolov4发展过来的
5.1 focus结构
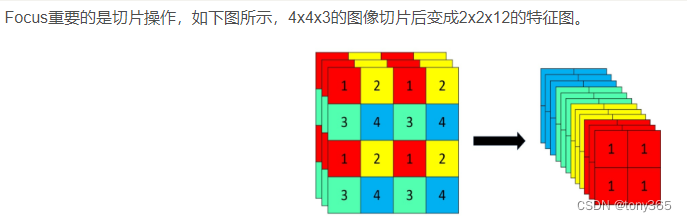
和pixel_unshuffle在最后的通道排列顺序上有差异。
参考:https://blog.csdn.net/tywwwww/article/details/137342458
def autopad(k, p=None): # kernel, padding自动填充的设计,更加灵活多变
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class Conv(nn.Module):
# 这里对应结构图部分的CBL,CBL = conv+BN+Leaky ReLU,后来改成了SiLU(CBS)
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):#正态分布型的前向传播
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):#普通前向传播
return self.act(self.conv(x))
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
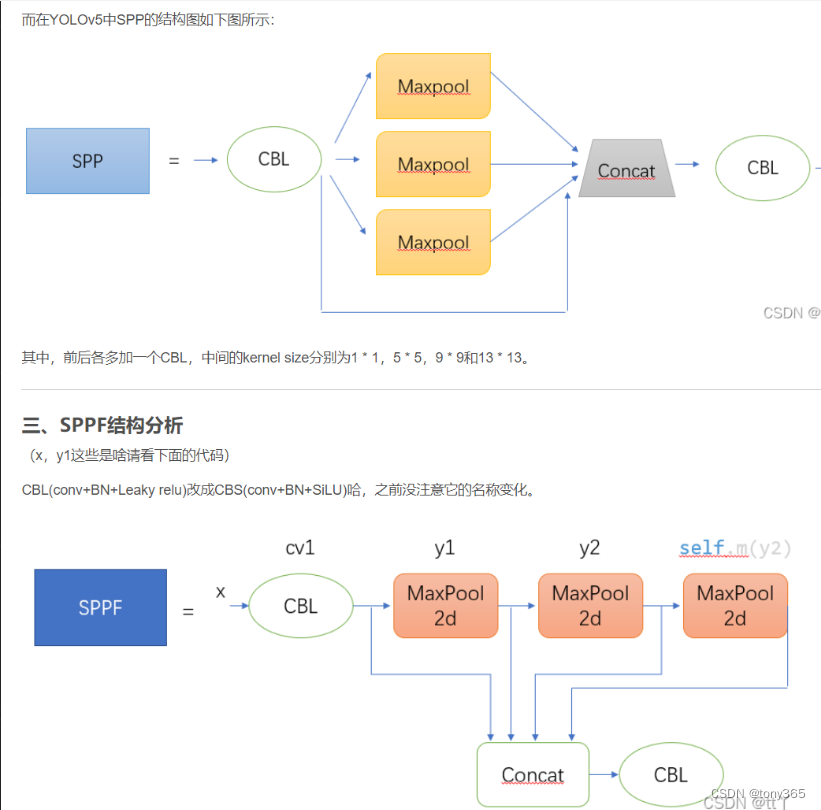
5.2 spp结构和sppf结构:
参考:https://blog.csdn.net/weixin_55073640/article/details/122621148?spm=1001.2014.3001.5502
需要注意的是yolov5中的spp结构的 maxpool stride = 1,因此池化后尺寸是不变的。
和最开始的spp 有差异。
sppf只不过 并联变成串联。
import time
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
class SPPF(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return torch.cat([x, o1, o2, o3], dim=1)
def main():
input_tensor = torch.rand(8, 32, 16, 16)
spp = SPP()
sppf = SPPF()
output1 = spp(input_tensor)
output2 = sppf(input_tensor)
print(torch.equal(output1, output2))
t_start = time.time()
for _ in range(100):
spp(input_tensor)
print(f"spp time: {time.time() - t_start}")
t_start = time.time()
for _ in range(100):
sppf(input_tensor)
print(f"sppf time: {time.time() - t_start}")
if __name__ == '__main__':
main()
5.5 bottleneck
resnet中的bottleneck:
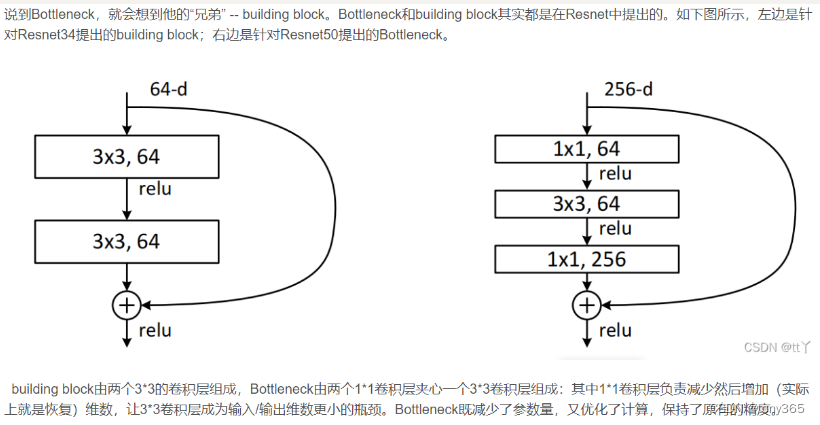
yolov5中的bottleneck代码:2各卷积层组成
class Bottleneck(nn.Module):#瓶颈层,由两个CBL组成,1个1*1,一个3*3,再横跨一个Residual
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))#这里对应判断:如果False就只有self.cv2(self.cv1(x)),True就x + self.cv2(self.cv1(x))
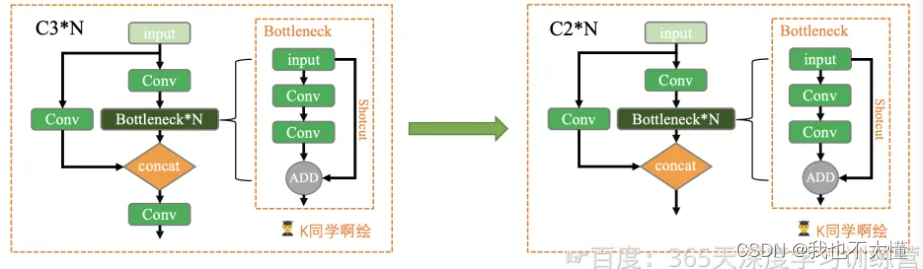
5.55 完整结构
https://blog.csdn.net/qq_37541097/article/details/123594351
一图胜过千言万语