接上文,在主函数我们看到下载的函数InstallFunc,在这个下载的函数中,根据指引我们可以看见
下载所需要的函数
也就是
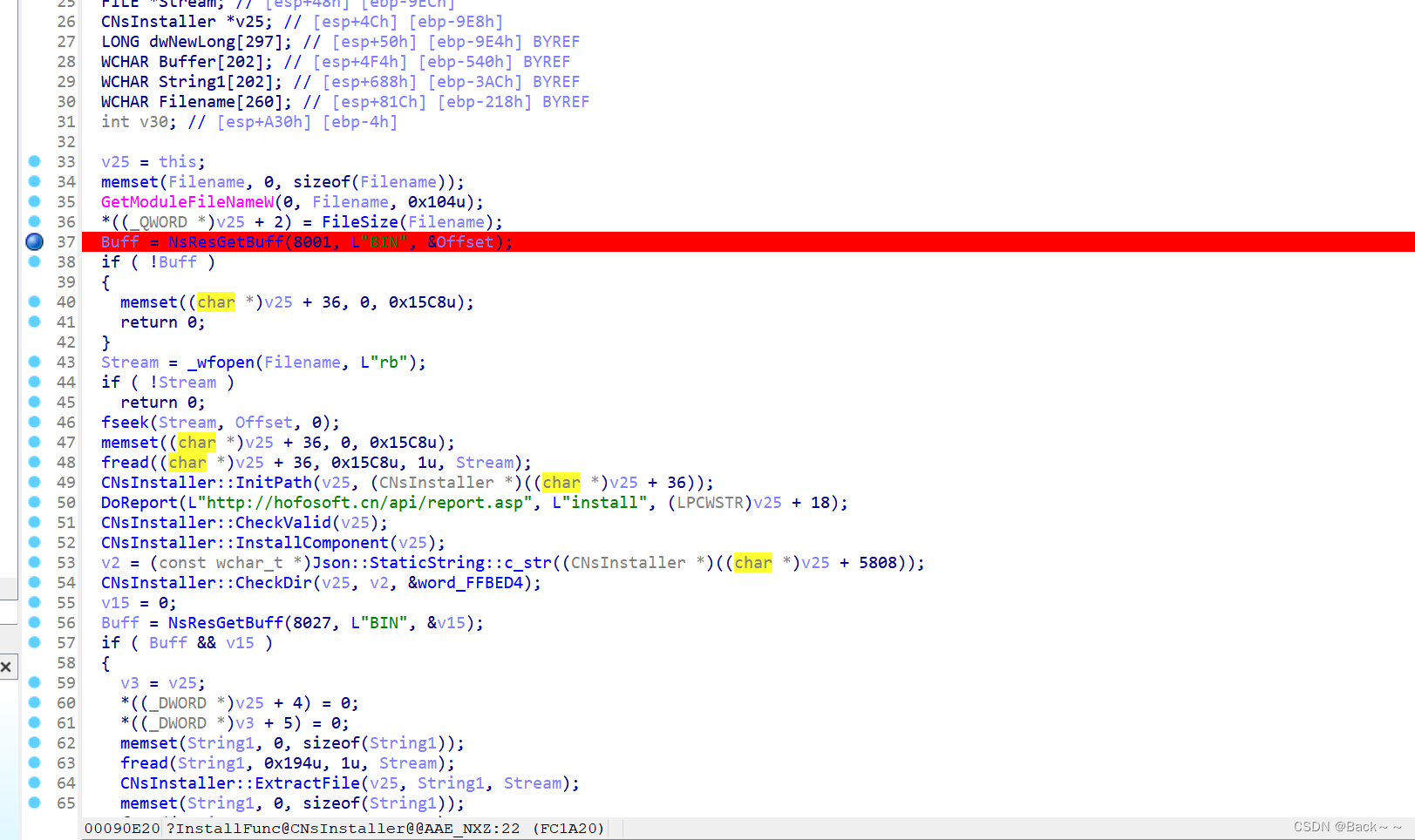 这段函数是一个安装程序的主要功能函数。它的作用是从文件中读取数据,并根据这些数据执行安装相关的操作。以下是该函数的逻辑解释:
这段函数是一个安装程序的主要功能函数。它的作用是从文件中读取数据,并根据这些数据执行安装相关的操作。以下是该函数的逻辑解释:
获取模块文件名和大小
首先获取当前执行的模块(可执行文件)的文件名,并计算文件的大小。获取资源缓冲区
通过调用NsResGetBuff函数获取资源缓冲区的信息。如果未能获取到资源缓冲区,则将安装程序的数据区清零,并返回。打开文件并读取数据
打开当前模块的文件流,并将文件流的指针移动到资源偏移量处,然后从文件流中读取数据,填充安装程序的数据区。初始化路径和报告初始化安装程序的路径,并向指定的 URL 发送安装报告。
检查有效性和安装组件
检查安装的有效性,并安装相关组件。检查目录和提取文件
检查目录,然后从文件中提取指定的文件。根据条件提取文件和执行操作
- 如果存在指定的资源缓冲区,则循环读取文件数据并提取文件,然后执行一些后续操作,如删除临时文件、执行脚本等。
- 如果提取失败或其他条件满足,则根据情况返回不同的结果,如安装成功或失败的标志。
处理异常情况
如果出现异常情况,如文件操作失败或没有写权限等,则根据情况返回不同的错误码,并进行相应的处理,如显示错误消息、退出程序等。
总的来说,这个函数负责执行安装过程中的一系列操作,包括读取文件数据、提取文件、执行脚本等,并根据执行结果返回相应的结果码。
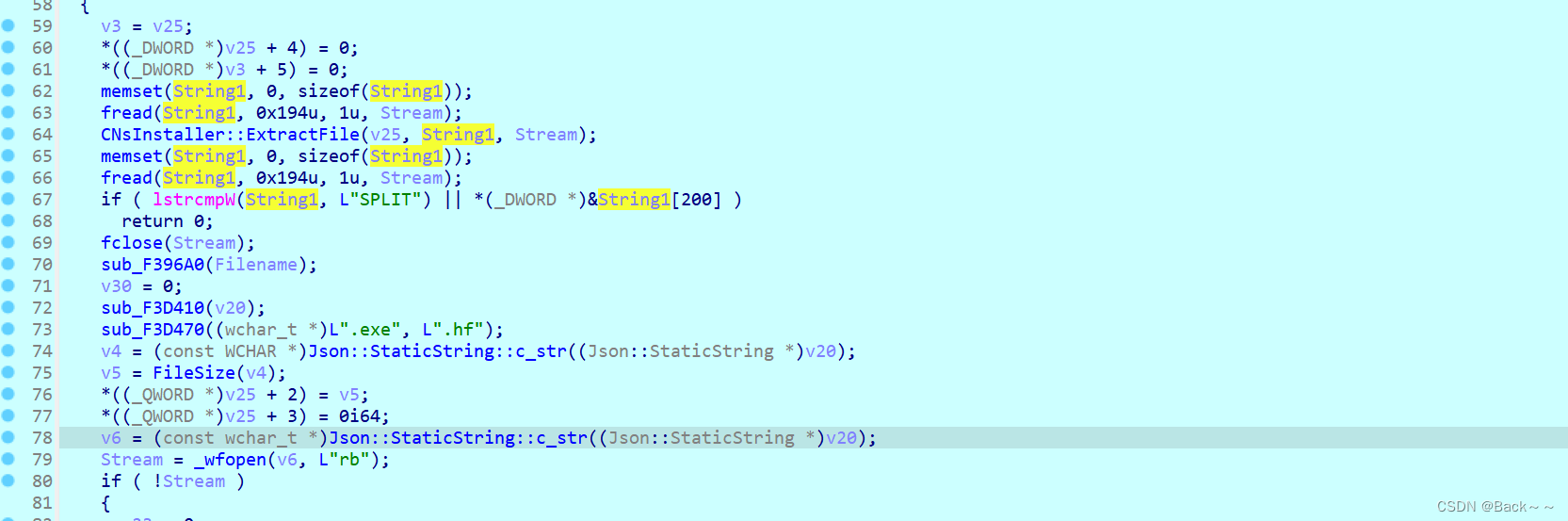
这里面最重要的是EtractFile函数
char __thiscall CNsInstaller::ExtractFile(CNsInstaller *this, wchar_t *a2, struct _iobuf *a3)
{
const wchar_t *v3; // eax
const WCHAR *v4; // eax
int v5; // esi
int v6; // esi
CNsProcess *v7; // eax
CNsHook *v8; // eax
const wchar_t *v9; // eax
const WCHAR *v11; // eax
const wchar_t *v12; // [esp-4h] [ebp-27Ch]
const wchar_t *v13; // [esp-4h] [ebp-27Ch]
int v14; // [esp+14h] [ebp-264h] BYREF
int v15; // [esp+18h] [ebp-260h] BYREF
void *v16; // [esp+1Ch] [ebp-25Ch]
void *v17; // [esp+20h] [ebp-258h]
void *Src; // [esp+24h] [ebp-254h]
CNsInstaller *v19; // [esp+28h] [ebp-250h]
int v20; // [esp+2Ch] [ebp-24Ch] BYREF
char v21[4]; // [esp+30h] [ebp-248h] BYREF
WPARAM wParam; // [esp+34h] [ebp-244h]
void *v23; // [esp+38h] [ebp-240h]
int i; // [esp+3Ch] [ebp-23Ch]
int Buffer[2]; // [esp+40h] [ebp-238h] BYREF
void *v26; // [esp+48h] [ebp-230h]
FILE *Stream; // [esp+4Ch] [ebp-22Ch]
char v28; // [esp+51h] [ebp-227h]
char v29; // [esp+53h] [ebp-225h]
int v30; // [esp+54h] [ebp-224h] BYREF
CNsInstaller *v31; // [esp+58h] [ebp-220h]
int v32; // [esp+5Ch] [ebp-21Ch] BYREF
WCHAR String1[260]; // [esp+60h] [ebp-218h] BYREF
int v34; // [esp+274h] [ebp-4h]
v31 = this;
CNsInstaller::CheckDir(this, a2, 0);
sub_F397C0(&v30);
v34 = 0;
sub_F39D70((int)&v30, (wchar_t *)L"%s\\%s", *((_DWORD *)v31 + 1452));
v3 = (const wchar_t *)Json::StaticString::c_str((Json::StaticString *)&v30);
Stream = _wfopen(v3, L"wb");
if ( !Stream )
{
v4 = (const WCHAR *)Json::StaticString::c_str((Json::StaticString *)&v30);
if ( !PathFileExistsW(v4) )
{
CNsInstaller::MovePos(v31, (struct tagPacketInfo *)a2, a3);
v34 = -1;
sub_F39680(&v30);
return 0;
}
sub_F3D410(&v30);
v5 = sub_F3ED80((wchar_t *)L".exe", 0);
if ( v5 == sub_F397F0(&v30) - 4 )
{
v6 = sub_F397F0(&v30);
Src = (void *)(v6 - sub_F46640(92) - 1);
sub_F41EB0((int)&v20, Src);
LOBYTE(v34) = 1;
v12 = (const wchar_t *)Json::StaticString::c_str((Json::StaticString *)&v20);
v7 = CNsProcess::Instance();
CNsProcess::KillProcess(v7, v12);
LOBYTE(v34) = 0;
sub_F39680(&v20);
}
else
{
v13 = (const wchar_t *)Json::StaticString::c_str((Json::StaticString *)&v30);
v8 = CNsHook::Instance();
CNsHook::CloseUsedProc(v8, v13);
}
v9 = (const wchar_t *)Json::StaticString::c_str((Json::StaticString *)&v30);
Stream = _wfopen(v9, L"wb");
if ( !Stream )
{
CNsInstaller::MovePos(v31, (struct tagPacketInfo *)a2, a3);
v29 = 1;
v34 = -1;
sub_F39680(&v30);
return v29;
}
}
sub_F397C0(v21);
LOBYTE(v34) = 2;
sub_F395C0(a2);
if ( !sub_F397F0((char *)v31 + 5612) && sub_F3ED80((wchar_t *)L"\\", 0) < 0 )
{
v32 = 1;
v11 = (const WCHAR *)Json::StaticString::c_str((Json::StaticString *)&v30);
lstrcpyW(String1, v11);
sub_F4F5D0(&v32);
}
for ( i = 0; i < *((_DWORD *)a2 + 100); ++i )
{
memset(Buffer, 0, sizeof(Buffer));
fread(Buffer, 8u, 1u, a3);
v17 = (void *)unknown_libname_48(Buffer[0]);
v26 = v17;
_NsReadFile(a3, v17, Buffer[0]);
v16 = (void *)unknown_libname_48(Buffer[1]);
v23 = v16;
v14 = Buffer[1];
v15 = Buffer[0] - 5;
sub_FA8A50(v16, &v14, (char *)v26 + 5, &v15, v26, 5);
_NsWriteFile(Stream, v23, Buffer[1]);
j_j_j___free_base(v26);
j_j_j___free_base(v23);
v19 = v31;
if ( *((__int64 *)v31 + 2) > 0 )
{
*((_QWORD *)v31 + 3) += 8i64;
*((_QWORD *)v31 + 3) += Buffer[0];
wParam = 10000i64 * *((_QWORD *)v31 + 3) / *((_QWORD *)v31 + 2);
if ( (int)wParam >= 10000 )
wParam = 9900;
PostMessageW(*(HWND *)v31, 0x7E9u, wParam, *((_DWORD *)v31 + 8));
}
}
fclose(Stream);
v28 = 1;
LOBYTE(v34) = 0;
sub_F39680(v21);
v34 = -1;
sub_F39680(&v30);
return v28;
}
这段代码是 CNsInstaller::ExtractFile 函数的实现,其功能是从输入流 a3 中提取文件,并将其写入到指定的文件流 Stream 中。
函数的主要逻辑如下:
首先调用
CNsInstaller::CheckDir检查目录,然后初始化一些变量。调用
PathFileExistsW检查文件是否存在,如果文件不存在,则调用CNsInstaller::MovePos移动文件指针并返回失败。如果文件存在,则尝试打开文件流,并写入数据。如果打开文件失败,则再次调用
CNsInstaller::MovePos移动文件指针并返回失败。调用
sub_F395C0函数输出错误消息,并进行一些其他的异常处理。循环读取文件数据,每次读取 8 字节数据,然后将数据写入到指定文件流中。
如果读取到的文件数据不为空,则更新文件指针位置,并通过
PostMessageW发送消息更新进度。当读取完所有文件数据后,关闭文件流,返回成功。
其中还有个函数计算偏移位置的大小
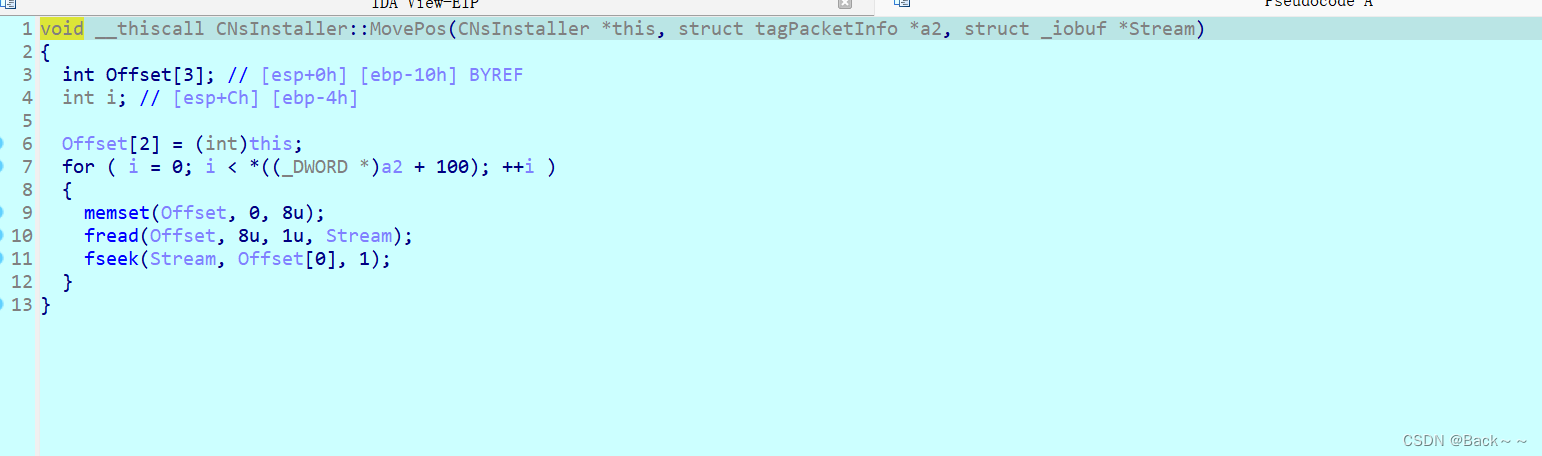
函数的主要逻辑如下:
首先初始化一个包含 3 个整数的数组
Offset,并将当前对象指针存储在数组的第三个元素中。使用循环迭代结构体
tagPacketInfo的 100 个整数成员(假设为_DWORD类型),依次进行以下操作:a. 使用
memset函数将数组Offset中的前 8 字节清零。b. 使用
fread函数从文件流中读取 8 字节数据到数组Offset中。c. 使用
fseek函数将文件指针从当前位置向前移动Offset[0]字节。
具体来说,它用于在文件流中按照一系列预定义的偏移量依次移动文件指针的位置。这个函数在文件流处理的过程中使用,用于定位到特定数据或者跳过特定的数据段
根据上面的代码逻辑
代码:
import os
import struct
import lzma
import hashlib
DEBUG = False
BASE_ADDRESS = 0x00120200
class Base:
def __init__(self):
self.startFilePos = 0
self.data = bytearray(0x15C8)
class SingleFileData:
def __init__(self):
self.fileInt = [0, 0]
self._dataSize = 0
self.fileData = bytearray()
self.nextSingleFileData = None
class SingleFile:
def __init__(self):
self.startFilePos = 0
self.data = bytearray(0x194)
self._times = 0
self._isFolder = False
self._fileSize = 0
self.firstFileData = None
def read_base(file):
file.seek(BASE_ADDRESS)
base = Base()
base.startFilePos = file.tell()
base.data = bytearray(file.read(0x15C8))
return base
def read_next_file(file, need_data):
single_file = SingleFile()
single_file.startFilePos = file.tell()
single_file.data = bytearray(file.read(0x194))
single_file._isFolder = (single_file.data[200] == -1)
single_file._times = single_file.data[0x190]
first_file_data = None
for i in range(single_file._times):
file_data = SingleFileData()
file_data.fileInt = struct.unpack('<2I', file.read(8))
single_file._fileSize += file_data.fileInt[0]
if not single_file._isFolder:
if not DEBUG:
file_data.fileData = bytearray(file.read(file_data.fileInt[0]))
else:
file.seek(file_data.fileInt[0], os.SEEK_CUR)
if first_file_data is None:
single_file.firstFileData = file_data
first_file_data = file_data
else:
first_file_data.nextSingleFileData = file_data
first_file_data = file_data
return single_file
import re
def extract_file(f, output_folder):
filename = re.sub(r'[^\w\-_. ]', '', f.data.decode("utf-16le").replace("\x00", ""))
path = os.path.join(output_folder, filename)
os.makedirs(os.path.dirname(path), exist_ok=True)
with open(path, "wb") as file_handle:
file_data = f.firstFileData
while file_data is not None:
if file_data.fileData is not None:
file_handle.write(file_data.fileData)
file_data = file_data.nextSingleFileData
return path
def calculate_md5(file_path):
hasher = hashlib.md5()
with open(file_path, "rb") as file:
for chunk in iter(lambda: file.read(4096), b""):
hasher.update(chunk)
return hasher.hexdigest()
def main():
output_folder = "F:\The couers of He predecessor\The fourth lesson\data"
with open("F:/The couers of He predecessor/The fourth lesson/MeiqiaWinLatest.exe", "rb") as f:
base = read_base(f)
print(f"baseStartPos: {base.startFilePos:0x}")
while True:
file = read_next_file(f, not DEBUG)
if file._fileSize <= 0:
break
extracted_file_path = ""
if not DEBUG:
extracted_file_path = extract_file(file, output_folder)
md5 = ""
if extracted_file_path:
md5 = calculate_md5(extracted_file_path)
print(f"fileStartPos: {file.startFilePos:0x}\t\tisFolder: {file._isFolder}")
print(f"fileName: {file.data.decode('utf-16le')}\t\tfileZipSize: 0x{file._fileSize:0x}\n")
print(f"MD5: {md5}\n")
if __name__ == "__main__":
main()
这个extract_file函数(ExtractFile)用于提取单个文件并将其保存到指定的输出文件夹中
获取文件名:从参数 f 中获取文件名,并在给定的输出文件夹路径 output_folder 中构建文件的完整路径。
创建文件夹:如果文件所在的文件夹不存在,则创建文件夹以保存提取的文件。
打开文件:使用二进制写入模式以追加数据的方式打开文件,如果文件不存在,则创建新文件。
提取文件数据:遍历文件的每个数据节点,如果数据节点中包含文件数据,则将文件数据写入到已打开的文件中。
返回文件路径:返回提取的文件的完整路径
基地址数据 (Base):
- 包含在安装包的指定位置 (BASE_ADDRESS)。
- 数据长度为 0x15C8 字节。
单个文件数据 (SingleFile):
- 每个单个文件的信息存储在一块 0x194 字节大小的数据块中。
- 文件信息包括文件名、文件大小、是否是文件夹等。
- 如果是文件夹,则还会存储其包含的子文件数量。
- 如果不是文件夹,则会存储每个子文件的大小和其他属性。
文件数据 (SingleFileData):
- 每个文件数据节点存储在单个文件数据 (SingleFile) 对象中。
- 用于存储文件的实际数据。
- 文件数据以字节流的形式存储。
- 如果单个文件包含多个数据块,则会使用链表连接这些数据块。
import os
import struct
import lzma
import hashlib
DEBUG = False
BASE_ADDRESS = 0x00120200
class Base:
def __init__(self):
self.startFilePos = 0
self.data = bytearray(0x15C8)
class SingleFileData:
def __init__(self):
self.fileInt = [0, 0]
self._dataSize = 0
self.fileData = bytearray()
self.nextSingleFileData = None
class SingleFile:
def __init__(self):
self.startFilePos = 0
self.data = bytearray(0x194)
self._times = 0
self._isFolder = False
self._fileSize = 0
self.firstFileData = None
def read_base(file):
file.seek(BASE_ADDRESS)
base = Base()
base.startFilePos = file.tell()
base.data = bytearray(file.read(0x15C8))
return base
def read_next_file(file, need_data):
single_file = SingleFile()
single_file.startFilePos = file.tell()
single_file.data = bytearray(file.read(0x194))
single_file._isFolder = (single_file.data[200] == -1)
single_file._times = single_file.data[0x190]
first_file_data = None
for i in range(single_file._times):
file_data = SingleFileData()
file_data.fileInt = struct.unpack('<2I', file.read(8))
single_file._fileSize += file_data.fileInt[0]
if not single_file._isFolder:
if not DEBUG:
file_data.fileData = bytearray(file.read(file_data.fileInt[0]))
else:
file.seek(file_data.fileInt[0], os.SEEK_CUR)
if first_file_data is None:
single_file.firstFileData = file_data
first_file_data = file_data
else:
first_file_data.nextSingleFileData = file_data
first_file_data = file_data
return single_file
import re
def extract_file(f, output_folder):
filename = re.sub(r'[^\w\-_. ]', '', f.data.decode("utf-16le").replace("\x00", ""))
path = os.path.join(output_folder, filename)
os.makedirs(os.path.dirname(path), exist_ok=True)
with open(path, "wb") as file_handle:
file_data = f.firstFileData
while file_data is not None:
if file_data.fileData is not None:
file_handle.write(file_data.fileData)
file_data = file_data.nextSingleFileData
return path
def calculate_md5(file_path):
hasher = hashlib.md5()
with open(file_path, "rb") as file:
for chunk in iter(lambda: file.read(4096), b""):
hasher.update(chunk)
return hasher.hexdigest()
def main():
output_folder = "F:\The couers of He predecessor\The fourth lesson\data"
with open("F:/The couers of He predecessor/The fourth lesson/MeiqiaWinLatest.exe", "rb") as f:
base = read_base(f)
print(f"baseStartPos: {base.startFilePos:0x}")
while True:
file = read_next_file(f, not DEBUG)
if file._fileSize <= 0:
break
extracted_file_path = ""
if not DEBUG:
extracted_file_path = extract_file(file, output_folder)
md5 = ""
if extracted_file_path:
md5 = calculate_md5(extracted_file_path)
print(f"fileStartPos: {file.startFilePos:0x}\t\tisFolder: {file._isFolder}")
print(f"fileName: {file.data.decode('utf-16le')}\t\tfileZipSize: 0x{file._fileSize:0x}\n")
print(f"MD5: {md5}\n")
if __name__ == "__main__":
main()
提取出来
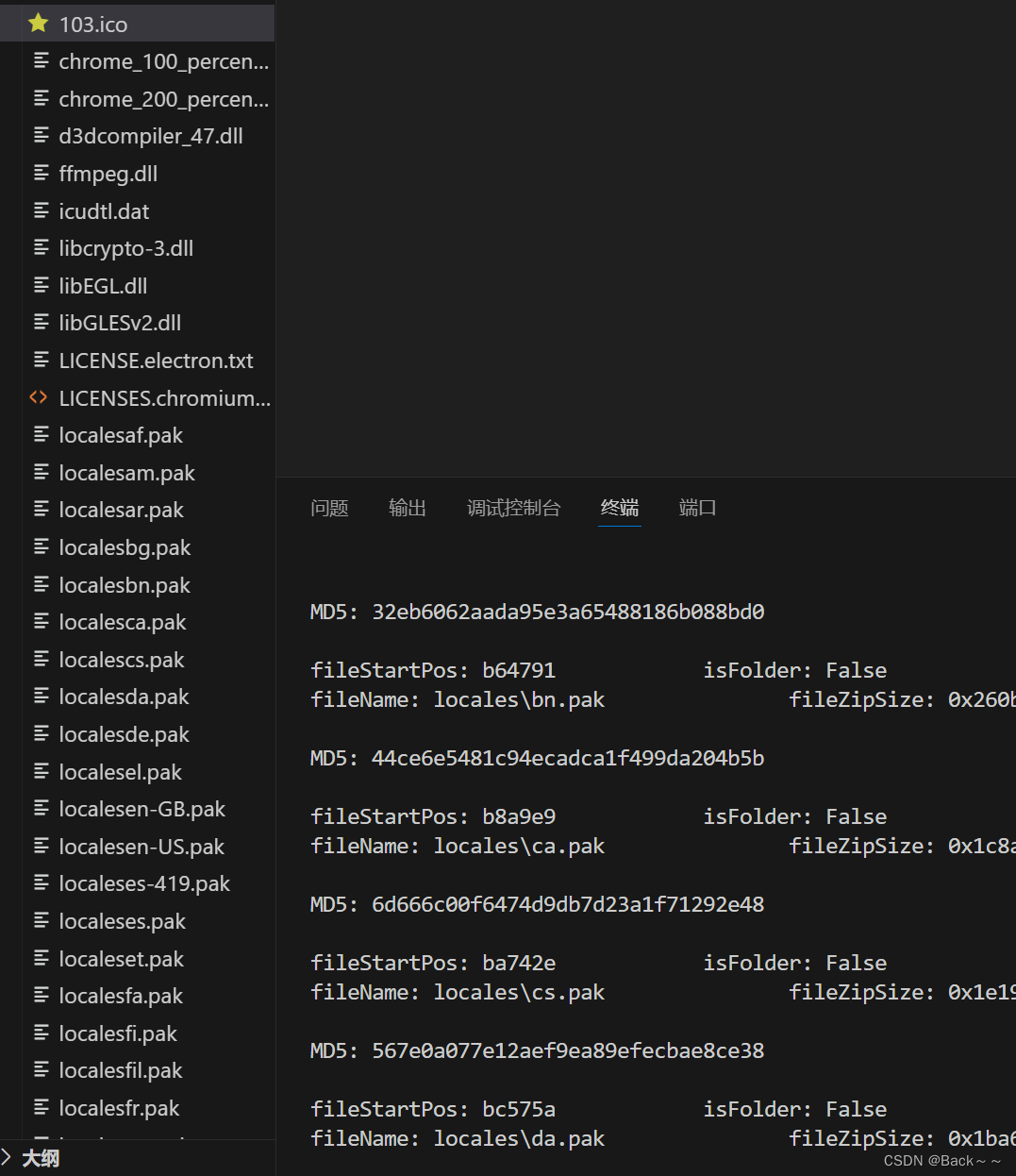
特别不过代码中没有用到解压的函数,意思是数据还是压缩的形式,MD5没对上
 看看同学的
看看同学的
// main.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include <Windows.h>
#pragma comment(lib, "7zra.lib")
#pragma comment(lib, "zlibstat.lib")
#include "LzmaLib.h"
#include "pathcch.h"
#pragma comment(lib, "pathcch.lib")
//#pragma comment(lib, "zlibwapi.lib")
#define BYTE unsigned char
#include <iostream>
#define BASE_ADDRESS 0x00120200
bool debug = false;
struct Base
{
long startFilePos;
BYTE data[0x15C8];
};
struct SingleFileData {
unsigned int fileInt[2];
size_t _dataSize;
BYTE* fileData;
struct SingleFileData* nextSingleFileData;
};
struct SingleFile
{
long startFilePos;
BYTE data[0x194]; // first:name [0x190]:times [200]:folder?
unsigned int _times; //DWORD
bool _isFolder;
size_t _fileSize;
SingleFileData* firstFileData;
};
SingleFileData* callocSingleFileData() {
SingleFileData* p = (SingleFileData*)malloc(sizeof(SingleFileData));
memset(p, 0, sizeof(SingleFileData));
return p;
}
void appendSingleFileData(SingleFile* file, SingleFileData* fileData) {
auto pre = file->firstFileData;
if (pre == NULL)
{
file->firstFileData = fileData;
return;
}
while (pre->nextSingleFileData) {
pre = pre->nextSingleFileData;
}
pre->nextSingleFileData = fileData;
}
Base* readBase(FILE* f) {
fseek(f, BASE_ADDRESS, SEEK_SET);
Base* base = (Base*)malloc(sizeof(Base));
base->startFilePos = ftell(f);
memset(base->data, 0, sizeof(base->data));
fread_s(base->data, sizeof(base->data), 1, sizeof(base->data), f);
return base;
}
SingleFile* readNextFile(FILE* f, bool needData) {
SingleFile* singleFile = (SingleFile*)malloc(sizeof(SingleFile));
memset(singleFile, 0, sizeof(SingleFile));
//singleFile->firstFileData = NULL;
singleFile->startFilePos = ftell(f);
//memset(singleFile->data, 0, sizeof(singleFile->data));
fread_s(singleFile->data, sizeof(singleFile->data), 1, sizeof(singleFile->data), f);
singleFile->_isFolder = (singleFile->data[200] == -1);
singleFile->_times = (unsigned int)(singleFile->data[0x190]);
//int debugI = 0;
for (size_t i = 0; i < singleFile->_times; i++)
{
// read 8 bytes
auto fileData = callocSingleFileData();
fread_s(fileData->fileInt, sizeof(fileData->fileInt), 8, 1, f);
singleFile->_fileSize = singleFile->_fileSize + fileData->fileInt[0];
//if (!lstrcmpW((wchar_t*)singleFile->data, L"icudtl.dat"))
//{
// debugI++;
// if (debugI == 4)
// {
// int a = 0;
// }
// // 前三次是正确的。
// // 第四次少了。(第四次有问题!)
// // 第五次没少。
// // 第六次没少。
//}
fileData->_dataSize = fileData->fileInt[0];
appendSingleFileData(singleFile, fileData);
if (!singleFile->_isFolder)
{
if (!debug)
{
fileData->fileData = (BYTE*)malloc(fileData->_dataSize);
fread_s(fileData->fileData, fileData->_dataSize, 1, fileData->_dataSize, f);
}
else {
printf_s("fileDataStart: 0x%x\n", ftell(f));
fseek(f, fileData->_dataSize, SEEK_CUR);
}
}
else {
}
}
return singleFile;
}
int lzmaTest() {
FILE* f;
fopen_s(&f, "1.lzma", "rb");
//get size
fseek(f, 0, SEEK_END);
long _fileSize = ftell(f);
unsigned char* buff = (unsigned char*)malloc(_fileSize);
// 重置文件指针位置到文件开头
rewind(f);
size_t flen = fread_s(buff, _fileSize, 1, _fileSize, f); // 读入整个文件
size_t buff5len = flen - 5;
size_t outBufLen = 0x399999;
unsigned char* outBuf = (unsigned char*)malloc(outBufLen);
LzmaUncompress(outBuf, &outBufLen, buff + 5, &buff5len, buff, 5);
FILE* fout;
fopen_s(&fout, "2.out", "wb");
fwrite(outBuf, 1, outBufLen, fout);
return 0;
}
void extractFile(SingleFile* f) {
wchar_t path[MAX_PATH] = {0};
wcscat(path, L"data/");
wcscat(path, (wchar_t*)f->data);
WCHAR folderPath[MAX_PATH];
wcscpy_s(folderPath, MAX_PATH, path);
PathCchRemoveFileSpec(folderPath,MAX_PATH);
CreateDirectory(folderPath, NULL);
HANDLE hFile = CreateFileW(path, FILE_APPEND_DATA, 0, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL);
DWORD dwBytesWritten;
if (hFile == INVALID_HANDLE_VALUE) {
printf("Error creating/opening file. Error code: %d\n", GetLastError());
return;
}
// 移动文件指针到文件末尾
SetFilePointer(hFile, 0, NULL, FILE_END);
auto p = f->firstFileData;
size_t fileDataBufLen = p->_dataSize;
size_t fileDataBufLenMinus5 = fileDataBufLen - 5;
/*if (f->_times > 1)
{
printf("f->_times>1\n");
}*/
size_t outBufLen = 0;
unsigned char* outBuf;
//int debugI = 0;
for (size_t i = 0; i < f->_times; i++)
{
fileDataBufLen = p->_dataSize;
fileDataBufLenMinus5 = fileDataBufLen - 5;
outBufLen = p->fileInt[1];
outBuf = (unsigned char*)malloc(outBufLen);
if (p->fileData == NULL)
{
continue;
}
//if (!lstrcmpW((wchar_t*)f->data,L"icudtl.dat"))
//{
// debugI++;
// if (debugI == 4)
// {
// int a = 0;
// }
// // 前三次是正确的。
// // 第四次少了。(第四次有问题!)
// // 第五次没少。
// // 第六次没少。
//}
LzmaUncompress(outBuf, &outBufLen, p->fileData + 5, &fileDataBufLenMinus5, p->fileData, 5);
/*if (!lstrcmpW((wchar_t*)f->data, L"icudtl.dat"))
{
if (debugI == 4)
{
int a = 0;
}
}*/
// 写入数据到文件
if (!WriteFile(hFile, outBuf, outBufLen, &dwBytesWritten, NULL)) {
printf("Error writing to file. Error code: %d\n", GetLastError());
CloseHandle(hFile); // 关闭文件句柄
outBufLen = 0;
free(outBuf);
return;
}
outBufLen = 0;
free(outBuf);
p = p->nextSingleFileData;
}
printf("Data extract to file successfully.\n");
CloseHandle(hFile);
}
int main()
{
//return lzmaTest();
FILE* f1,*f;
fopen_s(&f, "MeiqiaWinLatest.exe.data", "rb");
if (f == NULL) return 0;
Base* base = readBase(f);
printf_s("baseStartPos: 0x%x\n", base->startFilePos);
while (!feof(f))
{
SingleFile* file = readNextFile(f, !debug);
if (file->_fileSize <= 0)
{
break;
}
if (!debug)
{
extractFile(file);
}
else {
}
printf_s("fileStartPos: 0x%x\t\tisFolder: %d\n", file->startFilePos, file->_isFolder);
printf_s("fileName: %ws\t\tfileZipSize: 0x%x\n", (wchar_t*)file->data, file->_fileSize);
printf_s("\n");
}
fclose(f);
return 0;
}