人工智能AI-机器学习-深度学习
-强化学习
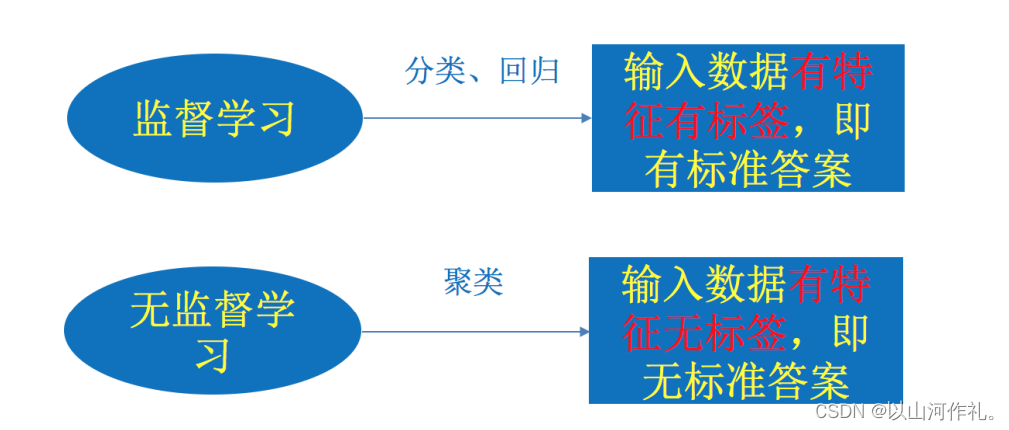
机器学习的分类:
- 监督学习:训练集有标记信息,有分类和回归
- 无监督学习:训练集没有标记信息,有聚类和降维
- 半监督学习:一半数据有标记,另外一半数据没有标记
- 强化学习:数据没有label标记,但需要每一步行动环境给予的反馈来不断调整训练对象
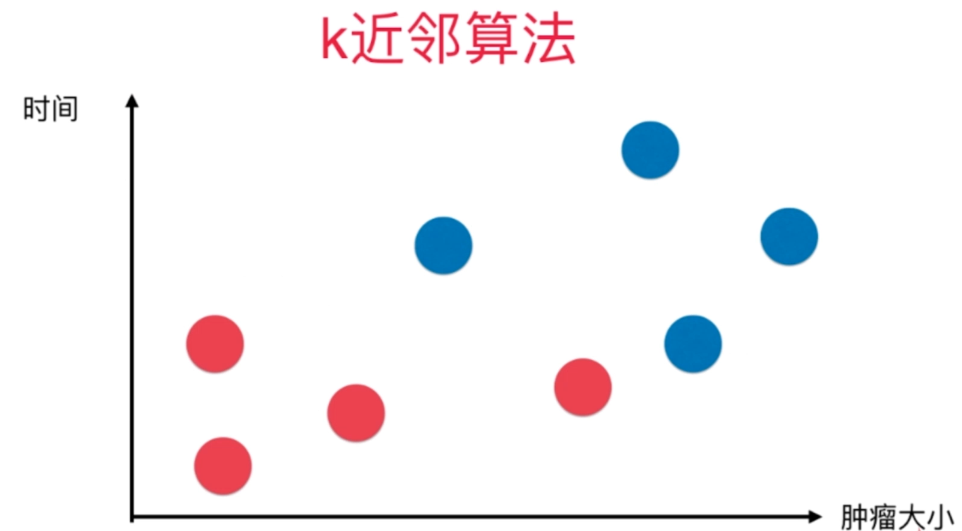
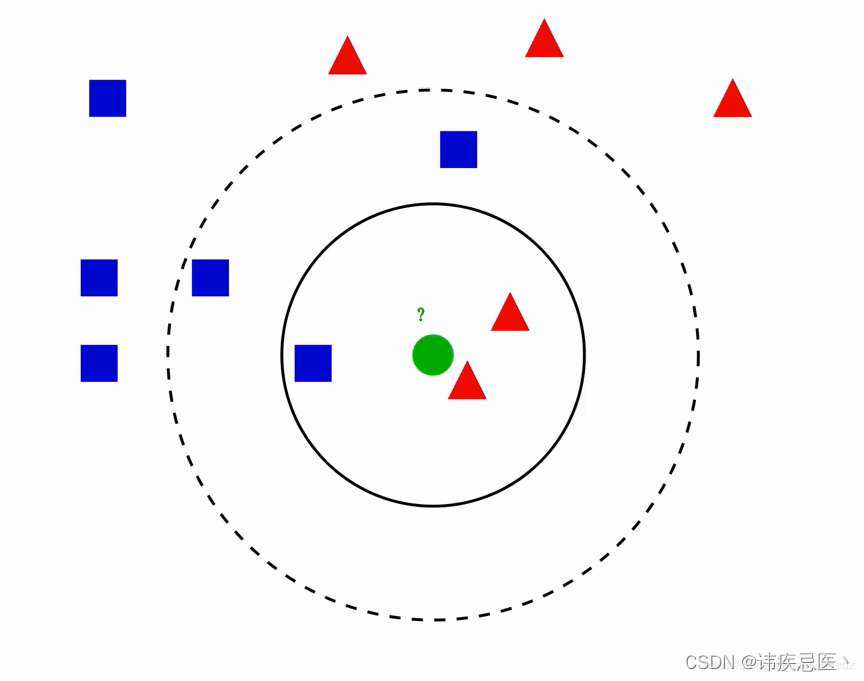
最近邻算法(KNN,K-Nearest Neighbor)
核心思想:如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别
KNN的优缺点:
优点:精度高,对异常值不敏感。
缺点:时间复杂度高,空间复杂度高
时间复杂度:描述算法运行的时间
空间复杂度:占用内存的大小
数据:data,target:一半表示全部数据
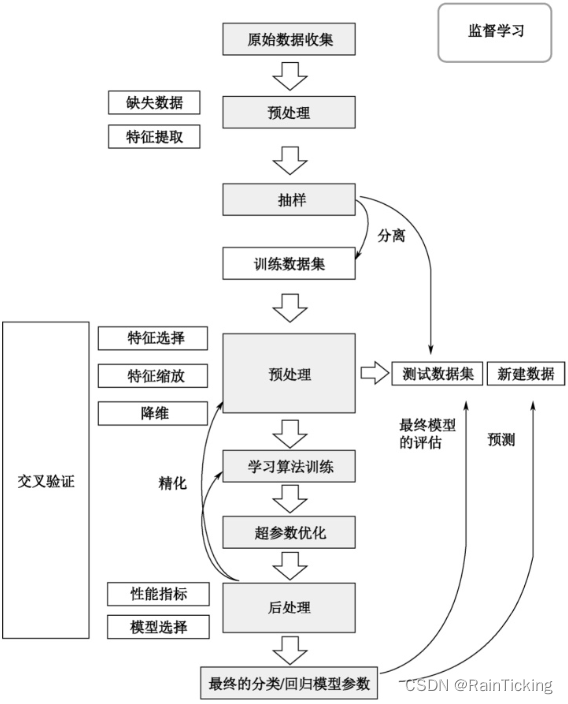
训练数据:
x_train:训练集中的数据
y_train:训练集中的数据对应的结果
预测数据:
x_test:测试集中的数据
y_test:测试集中的数据对应的真实结果
y_pred:测试集中的数据对应的预测结果
测试数据和训练数据中不能有中文和英文等的字符串类型,需要转换成int或者float类型
将data.education这一列字符串转化成int类型
data.education = data.education.factorize()[0]
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris #加载鸢尾花数据集
from sklearn.model_selection import train_test_split # 分割数据集
- 创建对象
n_neighbors=5 表示找最近邻的5个对象,
p=1 使用曼哈顿距离 p=2 使用欧氏距离
knn = KNeighborsClassifier(n_neighbors=5,p=2)
- 训练数据
# 将字符串转化成int类型
data.education = data.education.factorize()[0]
# 分割数据集
x_train,x_test,y_train,y_test=train_test_split(data,target,test_size=0.2)
# 训练数据
knn.fit(X=x_train,y=y_train)
- 预测数据
knn.predict(x_test)
- 评分
knn.score(x_test,y_test) # 测试数据及标签
- 保存训练模型
import joblib
保存模型:joblib.dump(knn,‘knn.plk’)
导入模型:joblib.load(“knn.plk”)
import joblib
joblib.dump(knn,'knn.plk')
new_knn=joblib.load('knn.plk')
# 预测,用新加载的模型进行预测
new_knn.predict(x_test)
线性回归
from sklearn.datasets import load_diabetes #糖尿病
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split # 拆分训练数据和预测数据
from sklearn.metrics import mean_squared_error as mse #求均方误差
# 创建模型
linear = LinearRegression()
linear.fit(x_train,y_train)
# 预测
y_pred = linear.predict(x_test)
# 线性回归的评估指标
# 均方误差
mse(y_test,y_pred)
# 求线性方程 中的系数和截距b
# w系数和b截距,有10个特征就有10个系数,越大,重要性越大
linear.coef_
# 截距
linear.intercept_
# 研究每个特征和标记结果之间的关系,来分析哪些特征对结果影响较大
plt.figure(figsize=(20,8))
for i,col in enumerate(df.columns):
data2 = df[col].copy()
ax = plt.subplot(2,5,i+1)
ax.scatter(data2,target)
# 线性回归:对每一个特征进行回归分析
linear2 = LinearRegression()
linear2.fit(df[[col]],target)
# 每个特征的系数w和截距b
# y=wx+b
w = linear2.coef_
b=linear2.intercept_
# 画直线
x = np.linspace(data2.min(),data2.max(),2)
y=w*x+b
ax.plot(x,y,c='r')
# 特征
score = linear2.score(df[[col]],target) # 模型得分
ax.set_title(f'{col}:{round(score,3)}',fontsize=16)
# 研究每个特征和标记结果之间的关系,来分析哪些特征对结果影响较大
plt.figure(figsize=(20,8))
for i,col in enumerate(df.columns):
data2 = df[col].copy()
ax = plt.subplot(2,5,i+1)
ax.scatter(data2,target)
# 线性回归:对每一个特征进行回归分析
linear2 = LinearRegression()
linear2.fit(df[[col]],target)
# 每个特征的系数w和截距b
# y=wx+b
w = linear2.coef_
b=linear2.intercept_
# 画直线
x = np.linspace(data2.min(),data2.max(),2)
y=w*x+b
ax.plot(x,y,c='r')
# 特征
score = linear2.score(df[[col]],target) # 模型得分
ax.set_title(f'{col}:{round(score,3)}',fontsize=16)
逻辑回归(Logistic Regression)
基于线性回归的回归分析算法,常用于数据挖掘,疾病自动诊断,经济预测等领域
解决的是分类问题,
线性回归是一种利用数理统计中的回归分析来确定两种或者两种以上变量间相互依赖的定量关系的一种统计分析方法。线性回归在二维平面中就是用一条线来拟合数据的过程
from sklearn.linear_model import LogisticRegression
对比KNN算法和LR算法
训练速度:KNN更快
预测速度:LR更快
用户一般希望预测时间越短越好:这一点逻辑回归LR跟好一点
决策树(Decision Tree)
优点:计算复杂度不高,既能分类,又能用于回归
缺点:可能会产生过渡匹配问题(过拟合)
决策树的构造:
分类解决离散问题,回归解决连续问题
from sklearn.tree import DecisionTreeClassifier
# 特征重要性
tree.feature_importances_
ID3算法
划分数据集的最大原则:将无序的数据变得更加有序
组织杂乱无章数据的一种方法就是使用信息论度量信息,在划分数据集之前之后信息发生的变化称为信息增益,知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择
CART算法
基尼系数,作用类似于信息熵
gini_D =1-sum(p(x)^2)
C4.5 算法
解决主要算法:ID3算法中出现的ID属性的问题
单独计算每个特征的信息熵
计算信息增益率
信息增益率 = 信息增益 / 每个特征单独的信息熵
随机森林(Random Forest)
包含多个决策数的分类器,并且其输出的类别是由每个树输出的类别的==众数(或少数服从多数)==而定
随机:
1.样本随机,样本个数一定
从原始数据集中采取有放回的抽样,构造子数据集
2.特征随机,特征数一定
from sklearn.ensemble import RandomForestClassifier
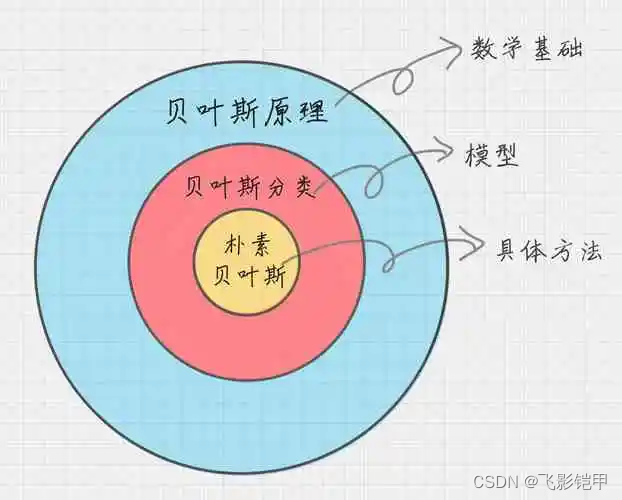
朴素贝叶斯(Naive Bayes)
基于贝叶斯定理与特征条件独立假设的分类算法
贝叶斯方法是结合先验概率和后验概率,贝叶斯分类算法在数据集较大的情况下表现出较高的准确率,同时算法本身也比较简单
对缺失数据不太敏感,常用于文本分类,但是只能用于分类问题,需要计算先验概率
from sklearn.naive_bayes import GaussianNB,MultinomialNB,BernoulliNB
高斯分布朴素贝叶斯
多项式分布朴素贝叶斯:多用于文本分类
伯努利分布朴素贝叶斯:多用于文本分类
from sklearn.feature_extraction.text import TfidfVectorizer
支持向量机(SVM)
按照监督学习方式对数据进行分类的分类器,其边界是学习样本求解的最大边距超平面
from sklearn.svm import SVC




















![[大模型]大语言模型量化方法对比:GPTQ、GGUF、AWQ](https://img-blog.csdnimg.cn/direct/8eca778e9ca24d0ab78412ae00555bbd.png)