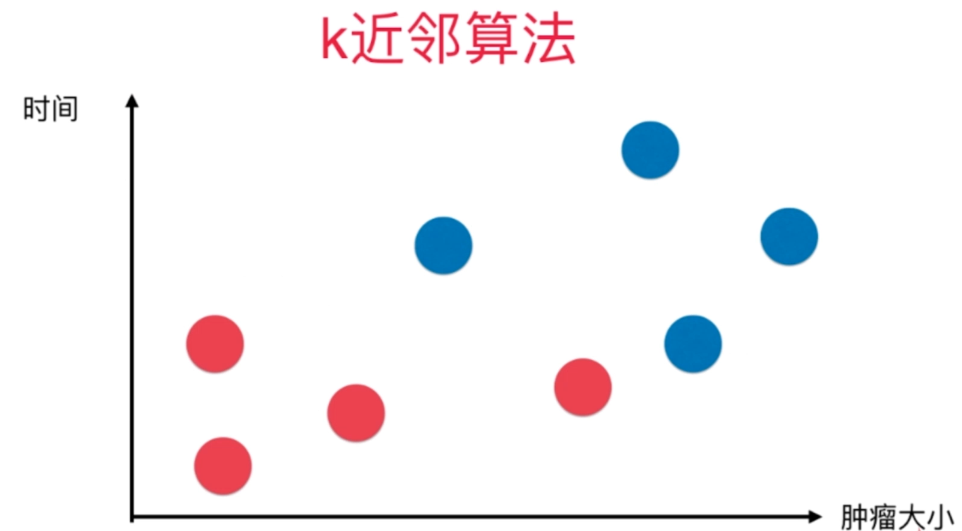
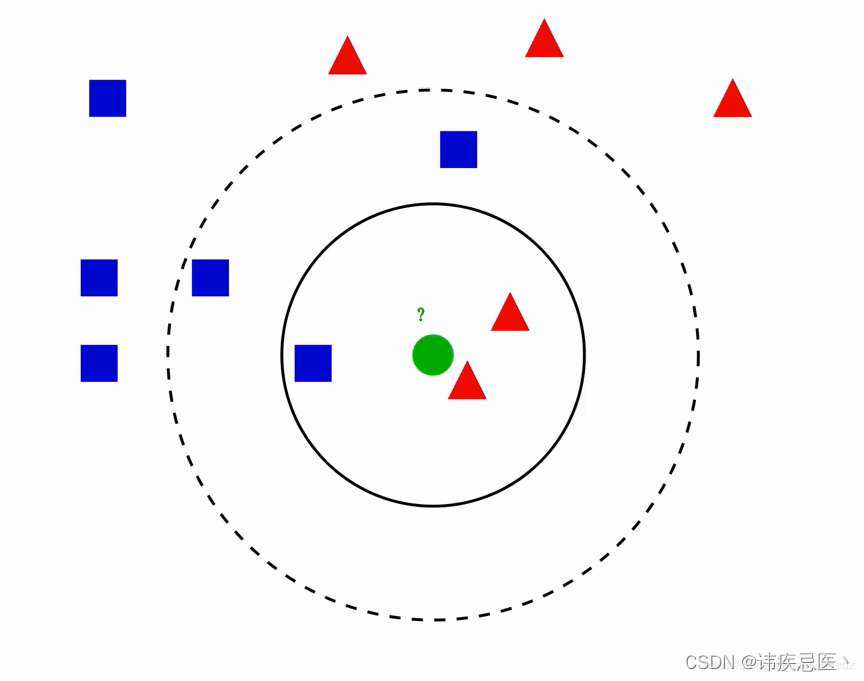
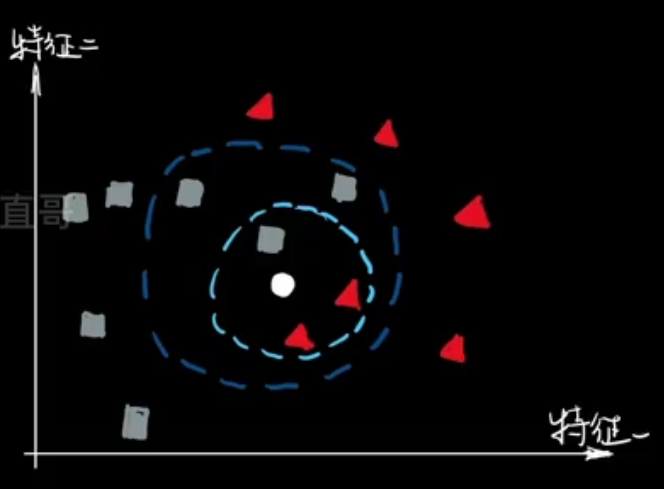
当谈到机器学习中的分类算法时,K最近邻(K-Nearest Neighbors,简称KNN)是一个简单而又常用的算法。在本篇博客中,我们将探讨KNN算法的原理、应用和优缺点。
一、原理
K最近邻算法是一种基于实例的学习方法,它通过利用已知类别的训练样本集来对新的实例进行分类。其核心思想是通过测量不同实例之间的距离来确定新实例的类别。
具体来说,KNN算法的原理可以概括为以下几个步骤:
数据准备:首先,我们需要准备一个有标签的训练数据集,其中每个样本都有一个已知的类别标签。
计算距离:对于一个新的未知实例,KNN算法会计算其与训练数据集中每个样本之间的距离。常用的距离度量方法包括欧氏距离、曼哈顿距离等。
选择K值:K值代表着在进行分类决策时要考虑的最近邻数目。我们需要选择一个合适的K值,它会对分类结果产生影响。较小的K值可能会导致噪声的影响,而较大的K值可能会忽略类别之间的细粒度差异。
确定最近邻:根据计算的距离,选择K个与新实例最接近的样本作为最近邻。
进行投票:在K个最近邻中,统计每个类别的出现次数,并将具有最高频次的类别作为新实例的预测类别。
输出结果:根据投票结果,将新实例分类于最高频次的类别。
举个例子:
假设我们有一个狗的分类问题。我们收集了一些关于不同狗的数据,并将它们分为三类:拉布拉多、哈士奇和贵宾。每个狗的数据都包括两个特征:体重和身高。
现在,我们想要对一个新的狗进行分类,但我们不知道它属于哪一类。我们使用KNN算法来解决这个问题。
首先,我们需要准备一个训练数据集,其中包含已知类别的狗的数据。例如:
| 狗的编号 | 体重(kg) | 身高(cm) | 类别 |
|---|---|---|---|
| 1 | 25 | 60 | 拉布拉多 |
| 2 | 30 | 65 | 拉布拉多 |
| 3 | 18 | 55 | 哈士奇 |
| 4 | 22 | 58 | 哈士奇 |
| 5 | 10 | 40 | 贵宾 |
接下来,我们选择一个合适的K值。假设我们选择K=3。
现在,假设我们有一个新的狗,它的体重是20kg,身高是50cm。我们希望通过KNN算法来对它进行分类。
我们首先计算这个新狗与训练数据集中每个狗之间的距离。常用的距离度量方法是欧氏距离。通过计算,我们可以得到以下结果:
| 狗的编号 | 体重(kg) | 身高(cm) | 类别 | 距离 |
|---|---|---|---|---|
| 1 | 25 | 60 | 拉布拉多 | 11.18 |
| 2 | 30 | 65 | 拉布拉多 | 15.81 |
| 3 | 18 | 55 | 哈士奇 | 10 |
| 4 | 22 | 58 | 哈士奇 | 8.06 |
| 5 | 10 | 40 | 贵宾 | 14.14 |
接下来,我们选择最近的K个狗,即距离最近的三个狗。在这种情况下,最近的三个狗是编号3、4和5。
最后,我们根据这三个最近邻的类别进行投票。在这种情况下,我们发现有两个哈士奇和一个贵宾。
因此,根据投票结果,我们可以将新的狗分类为哈士奇。
二、应用
K最近邻算法在许多领域都有广泛的应用,包括图像分类、文本分类、推荐系统等。以下是一些常见的应用场景:
图像分类:KNN算法可以通过比较图像的特征向量来对图像进行分类,例如人脸识别、手写数字识别等。
文本分类:KNN算法可以通过比较文本的词频或TF-IDF值来对文本进行分类,例如情感分析、垃圾邮件过滤等。
推荐系统:KNN算法可以根据用户的兴趣和行为,找到与其最相似的其他用户或物品,从而进行个性化的推荐。
医学诊断:KNN算法可以根据患者的症状和已知病例的数据来进行医学诊断,例如癌症预测、疾病分类等。
三、算法的优缺点
K最近邻算法具有以下优点:
简单易懂:KNN算法的原理简单明了,易于理解和实现。
适用性广泛:KNN算法可以应用于各种数据类型和领域,适用性广泛。
非参数化:KNN算法不对数据做任何假设,可以适应各种数据分布。
可以处理多类别问题:KNN算法可以处理多类别问题,不受二分类限制。
然而,KNN算法也存在一些缺点:
计算开销大:KNN算法需要计算新实例与所有训练样本之间的距离,当数据集较大时,计算开销较大。
对异常值敏感:KNN算法的分类结果容易受到异常值的影响。
需要选择合适的K值:选择合适的K值对于KNN算法的分类结果至关重要,需要通过交叉验证等方法进行选择。
数据不平衡问题:当训练数据中某些类别样本数量远远大于其他类别时,KNN算法可能会出现偏向较多样本的情况。
四、总结
KNN算法是一种简单而又常用的分类算法,通过计算新实例与训练数据集中样本之间的距离来进行分类。它在图像分类、文本分类、推荐系统和医学诊断等领域有广泛的应用。然而,KNN算法需要考虑计算开销、异常值敏感性、选择合适的K值和数据不平衡等问题。在实际应用中,我们需要根据具体情况来选择合适的分类算法,以获得更好的分类结果。





















![[晓理紫]每日论文分享(有中文摘要,源码或项目地址)--强化学习、模仿学习、机器人](https://img-blog.csdnimg.cn/direct/6389642cc7c84e53925a0718a073ba4c.jpeg#pic_center)


](https://img-blog.csdnimg.cn/direct/9da9423e499c4bc788a2119b5ba44f5a.png)