一、简介
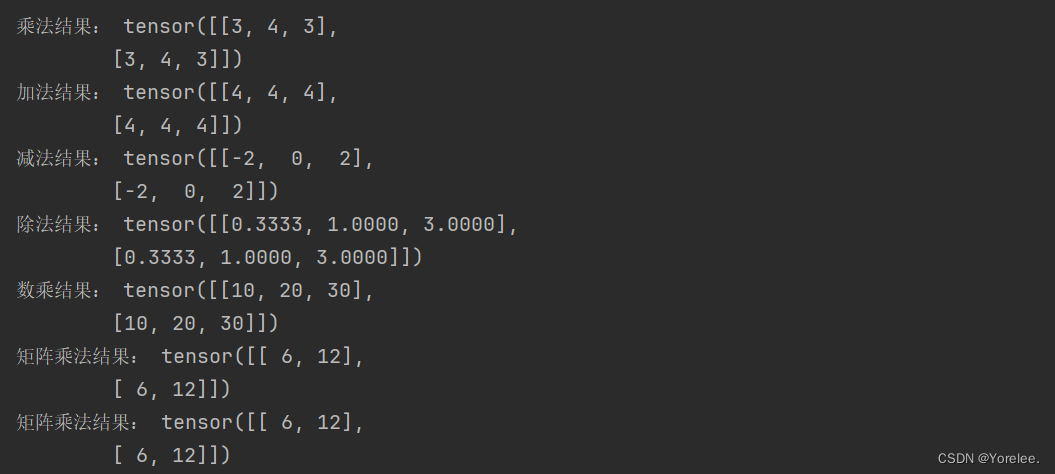
Pytorch中的张量有超过一百种运算,其中包括算术、线性代数、矩阵操作(转置、索引、切片)、抽样等内容,详细方法见如下链接[1]。本节将介绍几种pytorch中常用的几种非算术运算。
二、非算数运算
(一)cpu张量转换为gpu张量
默认情况下,张量是在 CPU 上创建的。我们可以使用 .to 方法将张量明确移动到 GPU(在检查 GPU 可用性后)。值得注意的是,在设备之间复制大型张量可能会在时间和内存方面耗费巨大!转换代码如下:
t1 = torch.tensor([1, 2, 3])
print(f"t1张量运算设备为{t1.device}")
if torch.cuda.is_available():
t2 = t1.to('cuda')
print(f"t2张量运算设备为{t2.device}")
运行结果为:

(二)张量的索引与切片
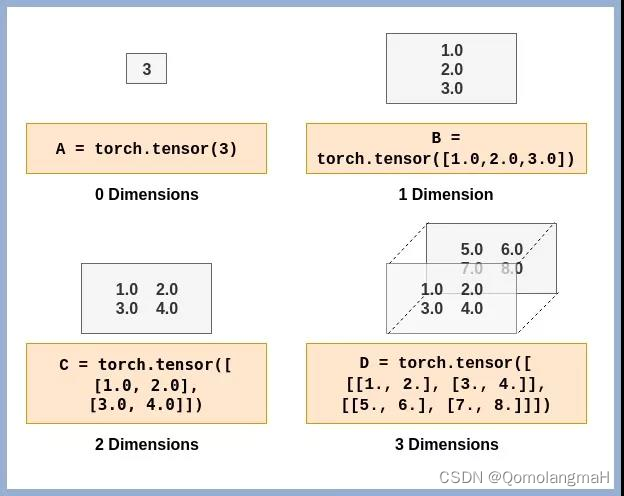
张量是深度学习中非常重要的数据结构,它是一种多维数组,可以是标量(0维张量)、向量(1维张量)、矩阵(2维张量),以及更高维度的张量。在张量中,索引和切片操作是非常常见的,用于获取特定位置的元素或者对张量进行切片操作。
1.张量的索引
张量的索引操作用于获取张量中特定位置的元素。在 Python 中,张量的索引从 0 开始,并且可以使用逗号分隔的索引来获取多维张量中的元素,具体代码示例如下:
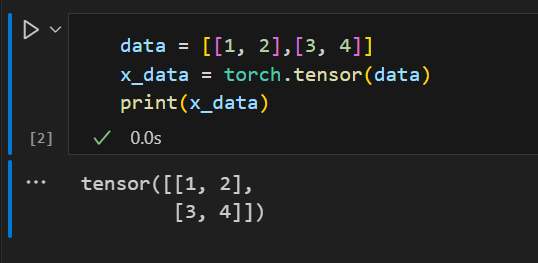
t1 = torch.tensor([[1, 2, 3], [4, 5, 6]])
#索引到张量t1中第二行第二列的元素
element = t1[1,1]
print(f"t1张量第二行第二列的元素为{element}")
运行结果为:

2.张量的切片
切片操作用于获取张量的子集。在 Python 中,可以使用来指定切片的范围。
例如,对于一个一维张量tensor,可以使用tensor[start:end]的形式来获取从start到 end-1的元素。
t1 = torch.tensor([1, 2, 3])
#输出t1张量中前两个元素
print(t1[0:2])#运行结果为tensor([1, 2])
对于多维张量,可以通过逗号分隔的切片范围来对不同维度进行切片操作。此外,对于一个shape为(2, 3)的张量tensor,tensor[:, 0]指对每一行的第一列进行切片,tensor[..., 0]与其效果相同。切片后我们可以对张量的切片中的元素进行修改。
t1 = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(f"t1的第一行为{t1[0, :]}")
print(f"t1的第一行为{t1[0, ...]}")
print(f"t1的最后一列为{t1[:, -1]}")
t1[1, ...] = 1
print(f"t1为{t1}")
运行结果为:

(三)张量的拼接
在深度学习中,经常需要对张量进行拼接操作,以便在不同维度上合并多个张量。PyTorch 提供了两种方法来进行张量的拼接操作,它们分别是torch.cat()和torch.stack()。
1.torch.cat()方法
torch.cat()用于按照指定维度拼接多个张量。它接受一个张量列表以及一个指定的拼接维度作为输入,并返回拼接后的张量。
#当张量为二阶(矩阵)时
t1 = torch.ones(2, 3)
t2 = torch.zeros(1, 3)
t3 = torch.zeros(2, 1)
print(f"按照0维拼接\n{torch.cat([t1, t2], dim=0)}")
print(f"按照1维拼接\n{torch.cat([t1, t3], dim=1)}")
运行结果为:

#当张量为三阶时
t4 = torch.ones(2, 2, 3)
t5 = torch.zeros(1, 2, 3)
print(f"按照0维拼接\n{torch.cat([t4, t5], dim=0)}")
t4 = torch.ones(2, 2, 3)
t5 = torch.zeros(2, 1, 3)
print(f"按照1维拼接\n{torch.cat([t4, t5], dim=1)}")
t4 = torch.ones(2, 2, 3)
t5 = torch.zeros(2, 2, 1)
print(f"按照2维拼接\n{torch.cat([t4, t5], dim=2)}")
运行结果为:
按照0维拼接
tensor([[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]],
[[0., 0., 0.],
[0., 0., 0.]]])
按照1维拼接
tensor([[[1., 1., 1.],
[1., 1., 1.],
[0., 0., 0.]],
[[1., 1., 1.],
[1., 1., 1.],
[0., 0., 0.]]])
按照2维拼接
tensor([[[1., 1., 1., 0.],
[1., 1., 1., 0.]],
[[1., 1., 1., 0.],
[1., 1., 1., 0.]]])
由二阶张量与三阶张量的拼接结果可知,tensor.cat([t1, t2], dim=)对张量进行拼接的规则为:dim的取值范围为[0, t1.dim()),当dim值取定时,t1,t2除dim所指维度可以不同外,其余维度均需相同。如当dim=0时,张量可取的一种shape为t1(2, 3, 4), t2(1, 3, 4) 。拼接时dim=0所指含义为从最高阶进行拼接,即当为三阶张量时,则需要将t1,t2中的矩阵进行拼接,当dim=1时,则需要对t1,t2进行行拼接。
2.torch.stack()方法[2]
torch.stack()用于在一个新的维度上堆叠多个张量。与 torch.cat()不同,torch.stack() 会在新创建的维度上堆叠张量。
#当张量为一阶(向量)时
t1 = torch.ones(3)
t2 = torch.zeros(3)
print(f"{torch.stack([t1, t2], dim=0)}")
print(f"{torch.stack([t1, t2], dim=1)}")
运行结果为:
t1和t2按行进行拼接结果为:
tensor([[1., 1., 1.],
[0., 0., 0.]])
t1和t2按列进行拼接结果为:
tensor([[1., 0.],
[1., 0.],
[1., 0.]])
#当张量为二阶(矩阵)时
t1 = torch.ones(2, 3)
t2 = torch.zeros(2, 3)
print(f"t1和t2按矩阵进行拼接结果为:\n{torch.stack([t1, t2], dim=0)}")
print(f"t1和t2按行进行拼接结果为:\n{torch.stack([t1, t2], dim=1)}")
print(f"t1和t2按列进行拼接结果为:\n{torch.stack([t1, t2], dim=2)}")
运行结果为:
t1和t2按矩阵进行拼接结果为:
tensor([[[1., 1., 1.],
[1., 1., 1.]],
[[0., 0., 0.],
[0., 0., 0.]]])
t1和t2按行进行拼接结果为:
tensor([[[1., 1., 1.],
[0., 0., 0.]],
[[1., 1., 1.],
[0., 0., 0.]]])
t1和t2按列进行拼接结果为:
tensor([[[1., 0.],
[1., 0.],
[1., 0.]],
[[1., 0.],
[1., 0.],
[1., 0.]]])
由上述运行结果可知,一阶张量使用tensor.stack()进行拼接获得二阶张量,二阶张量进行拼接获得三阶张量。在使用tensor.stack([t1, t2], dim=)对张量拼接时,t1,t2的shape必须完全相同,dim的值代表进行矩阵拼接、行拼接或者列拼接。这块建议按照上述代码实际运行即可弄清,如实在觉得抽象可参考这篇博文[2]中的图解进行理解。