kmp算法
有一个文本串S,和一个模式串P,现在要查找P在S中的位置,意思就是给出两个字符串,文本串 S 和 模式串 T,若 S 的区间 [ l ,r ]子串与 T 完全相同,则称 T 在 S 中出现了,其出现位置为 l
请求出 T 在 S 中所有出现的位置。
这个问题,我们需要在给定的文本串S中找出模式串P的所有出现位置。如果采用暴力匹配的方法,我们可以按照以下步骤进行操作:
假定目前我们在文本串S中已匹配到的位置为i,在模式串P中已匹配到的位置为j。
如果当前字符匹配成功(即S[i] == P[j]),则i++,j++,继续匹配下一个字符
如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0。相当于每次匹配失败时,i 回溯,j 被置为0
但是这样做将会出现两层循环,时间复杂度将会达到 O(n*m) (n为 S 的长度,m为 T 的长度)。当数据量过大时,很容易出现超时的问题
这个时候我们发现,如果出现这种情况,我们会浪费很多时间

可以发现一个个回退的话很浪费时间,这个时候我们就要引入kmp算法了,时间复杂度会变为o(n+m)
怎么理解next数组
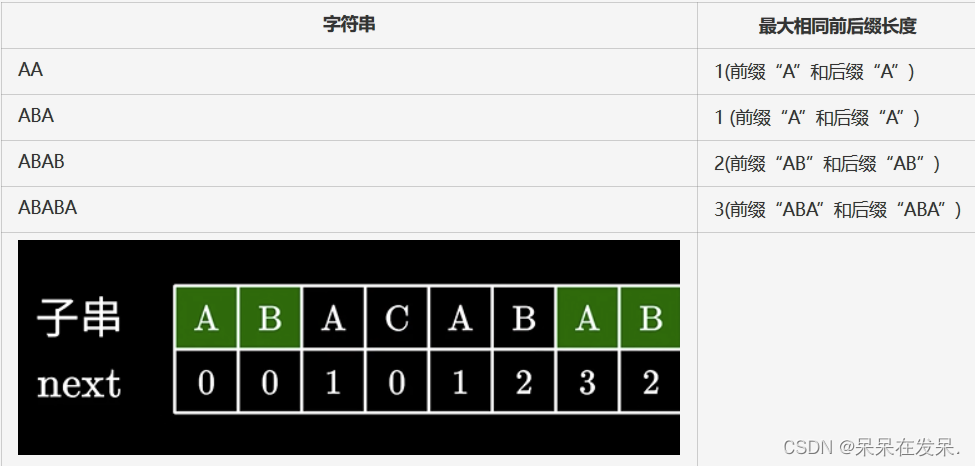
next[j]的值是模式串前j个字符组成的子串的最长相等的前缀和后缀的长度
以下是几个最大相同前后缀长度的例子
| 字符串 | 最大相同前后缀长度 |
|---|---|
| AA | 1(前缀“A”和后缀“A”) |
| ABA | 1 (前缀“A”和后缀“A”) |
| ABAB | 2(前缀“AB”和后缀“AB”) |
| ABABA | 3(前缀“ABA”和后缀“ABA”) |
 |
我们先假设我们已经得到了next数组
假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
如果当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符
如果当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位
换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值,即移动的实际位数为:j - next[j],且此值大于等于1
此也意味着在某个字符失配时,该字符对应的next 值会告诉你下一步匹配中,模式串应该跳到哪个位置(跳到next [j] 的位置)。如果next [j] 等于0或-1,则跳到模式串的开头字符,若next [j] = k 且 k > 0,代表下次匹配跳到j 之前的某个字符,而不是跳到开头,且具体跳过了k 个字符
运用next数组
先依次向后比较,找到跟第一个相同的位置,然后失配的话,根据next数组的值,跳转到下一个位置
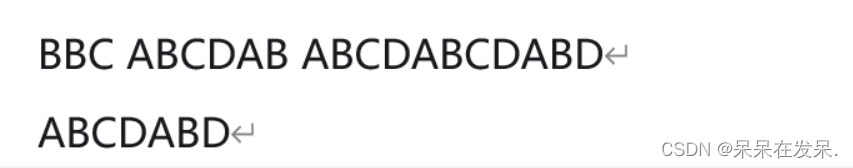
求解next数组
vector<int> computeNextArray(const string& pattern)
{
int m = pattern.length();
vector<int> next(m);
next[0] = 0;
int k = 0;
for (int q = 1; q < m; ++q)
{
while (k > 0 && pattern[k] != pattern[q])
k = next[k - 1];
if (pattern[k] == pattern[q])
++k;
next[q] = k;
}
return next;
}
图解

总代码
// 计算模式字符串的next数组
vector<int> computeNextArray(const string& pattern)
{
int m = pattern.length();
vector<int> next(m);
next[0] = 0;
int k = 0;
for (int q = 1; q < m; ++q)
{
while (k > 0 && pattern[k] != pattern[q])
k = next[k - 1];
if (pattern[k] == pattern[q])
++k;
next[q] = k;
}
return next;
}
// 使用next数组进行字符串匹配
vector<int> KMPMatcher(const string& text, const string& pattern)
{
int n = text.length();
int m = pattern.length();
vector<int> next = computeNextArray(pattern);
vector<int> indices;
int q = 0;
for (int i = 0; i < n; ++i)
{
while (q > 0 && pattern[q] != text[i])
{
q = next[q - 1];
}
if (pattern[q] == text[i])
{
++q;
}
if (q == m)
{
indices.push_back(i - m + 1);
q = next[q - 1];
}
}
return indices;
}
给出一个例题链接
【模板】KMP
题目描述
给出两个字符串 s 1 s_1 s1 和 s 2 s_2 s2,若 s 1 s_1 s1 的区间 [ l , r ] [l, r] [l,r] 子串与 s 2 s_2 s2 完全相同,则称 s 2 s_2 s2 在 s 1 s_1 s1 中出现了,其出现位置为 l l l。
现在请你求出 s 2 s_2 s2 在 s 1 s_1 s1 中所有出现的位置。
定义一个字符串 s s s 的 border 为 s s s 的一个非 s s s 本身的子串 t t t,满足 t t t 既是 s s s 的前缀,又是 s s s 的后缀。
对于 s 2 s_2 s2,你还需要求出对于其每个前缀 s ′ s' s′ 的最长 border t ′ t' t′ 的长度。
输入格式
第一行为一个字符串,即为 s 1 s_1 s1。
第二行为一个字符串,即为 s 2 s_2 s2。
输出格式
首先输出若干行,每行一个整数,按从小到大的顺序输出 s 2 s_2 s2 在 s 1 s_1 s1 中出现的位置。
最后一行输出 ∣ s 2 ∣ |s_2| ∣s2∣ 个整数,第 i i i 个整数表示 s 2 s_2 s2 的长度为 i i i 的前缀的最长 border 长度。
样例 #1
样例输入 #1
ABABABC
ABA
样例输出 #1
1
3
0 0 1
提示
样例 1 解释
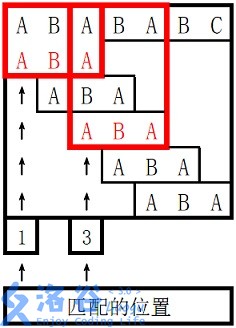 。
。
对于 s 2 s_2 s2 长度为 3 3 3 的前缀 ABA,字符串 A 既是其后缀也是其前缀,且是最长的,因此最长 border 长度为 1 1 1。
数据规模与约定
本题采用多测试点捆绑测试,共有 3 个子任务。
- Subtask 1(30 points): ∣ s 1 ∣ ≤ 15 |s_1| \leq 15 ∣s1∣≤15, ∣ s 2 ∣ ≤ 5 |s_2| \leq 5 ∣s2∣≤5。
- Subtask 2(40 points): ∣ s 1 ∣ ≤ 1 0 4 |s_1| \leq 10^4 ∣s1∣≤104, ∣ s 2 ∣ ≤ 1 0 2 |s_2| \leq 10^2 ∣s2∣≤102。
- Subtask 3(30 points):无特殊约定。
对于全部的测试点,保证 1 ≤ ∣ s 1 ∣ , ∣ s 2 ∣ ≤ 1 0 6 1 \leq |s_1|,|s_2| \leq 10^6 1≤∣s1∣,∣s2∣≤106, s 1 , s 2 s_1, s_2 s1,s2 中均只含大写英文字母。
ac代码
#include <bits/stdc++.h>
using namespace std;
#define quc ios::sync_with_stdio(false),cin.tie(nullptr),cout.tie(nullptr)
const int N = 1e6 + 5;
string s1;
string s2;
int next[N];
void get_next()
{
int len2 = s2.length();
int k = 0;
next[0] = -1;
int p = -1;
while (k < len2)
{
if (p == -1 || s2[k] == s2[p])
{
k++;
p++;
next[k] = p;
}
else
{
p = next[p];
}
}
}
void kmp()
{
int p = 0;
int t = 0;
while (p < s1.length())
{
if (t == -1 || s1[p] == s2[t])
{
p++;
t++;
}
else
{
t = next[t];//不用从头开始了
}
if (t == s2.length())
{
cout << p - s2.length() + 1 << '\n';
t = next[t];//继续跳过
}
}
}
int main()
{
quc;
cin >> s1;
cin >> s2;
get_next();
kmp();
int len = s2.length();
for (int i = 1; i <= len; i++)
{
cout << next[i]<< " ";
}
return 0;
}
| 序号 | 题号 | 标题 | 题型 | 难度评级 | 题解 |
|---|---|---|---|---|---|
| 1 | luogu P3375 | 【模板】KMP | kmp | ⭐ | 👍 |
| 2 | [ABC284F] | ABCBAC | kmp | ⭐⭐ | 👍 |
| 3 | UVA10298 | Power Strings | kmp | ⭐⭐⭐ | 👍 |
| 4 | CF126B | Password | kmp | ⭐⭐⭐ | 👍 |
| 5 | CF1029A | Many Equal Substrings | kmp | ⭐⭐ | 👍 |



























![[深度学习] 无人车环境准备](https://img-blog.csdnimg.cn/direct/296efc58996f4de3ac658fb579f762c6.png)