// 定义一个名为Solution的类
class Solution {
public:
// 定义一个公开成员函数partitionLabels,输入一个字符串S,输出一个整数向量(vector)
vector<int> partitionLabels(string S) {
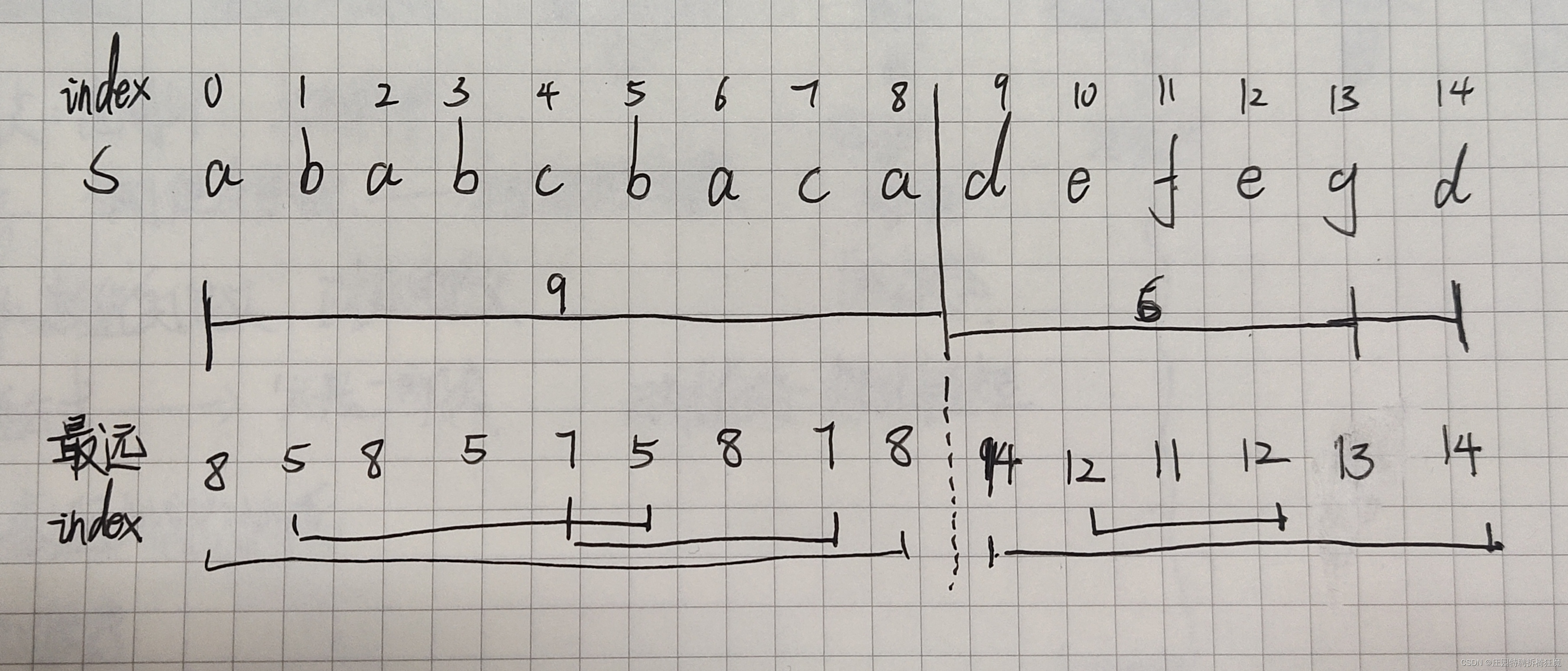
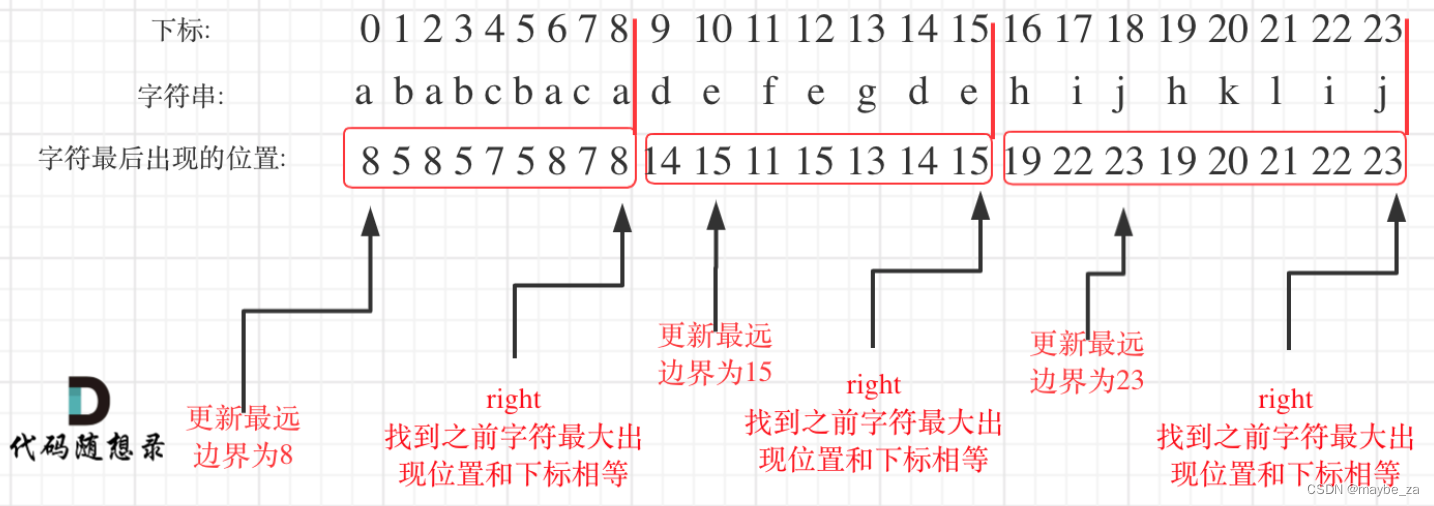
// 初始化一个长度为27的整数数组hash,用于存储每个小写字母('a'-'z')最后一次出现的位置
int hash[27] = {0};
// 遍历输入字符串S的每一个字符
for (int i = 0; i < S.size(); i++) {
// 更新该字符在hash数组中的值,记录它在字符串中最后一次出现的位置
hash[S[i] - 'a'] = i;
}
// 初始化结果向量result,用于存储分割后的子串长度
vector<int> result;
// 初始化左边界left和右边界right变量
int left = 0;
int right = 0;
// 遍历字符串S
for (int i = 0; i < S.size(); i++) {
// 更新右边界right为当前遍历到的字符对应的最大边界(即其在字符串中最后一次出现的位置)
right = max(right, hash[S[i] - 'a']);
// 当前字符所在位置等于右边界时,说明已经找到了一个连续的、包含所有字符至少一次的子串
if (i == right) {
// 将这个子串的长度(right-left+1)添加到结果向量result中
result.push_back(right - left + 1);
// 左边界更新为当前子串的下一个位置,开始寻找下一个满足条件的子串
left = i + 1;
}
}
// 返回结果向量result
return result;
}
};
这段代码实现了一个名为Solution的类,其中有一个成员函数partitionLabels。给定一个字符串S,该函数将字符串分割成多个子串,使得每个子串包含的字符都是互异且连续的。最终返回一个整数向量,表示各个子串的长度。通过创建一个哈希表(在这里使用数组hash)来记录每个字符最后一次出现的位置,并逐步更新左右边界以找到符合条件的子串。