目录
3.1.2 使用from selenium import webdriver连接网页,创建网页测试
3.2.1 使用beautifulsoup获取标签间文本内容爬取
5.3.1 2023年黑龙江和四川产品的单台中央补贴额(元)比较
实验 爬虫黑龙江省与四川省农机补贴
以及数据分析
一、实验目的
- 了解并熟悉爬虫过程
- 了解数据分析
- 学习并利用python和excel能够解决网页爬虫和数据分析问题
二、实验内容
2.1 实验爬取数据选择
1.选择网站(2022年全国各省市农机购置补贴系统登录入口-农机360网 (nongji360.com))黑龙江省和四川省农机购置补贴系统

图1:2022年全国各省市农机购置补贴系统登录入口界面
2.选择爬取两省三年表格内的全部数据
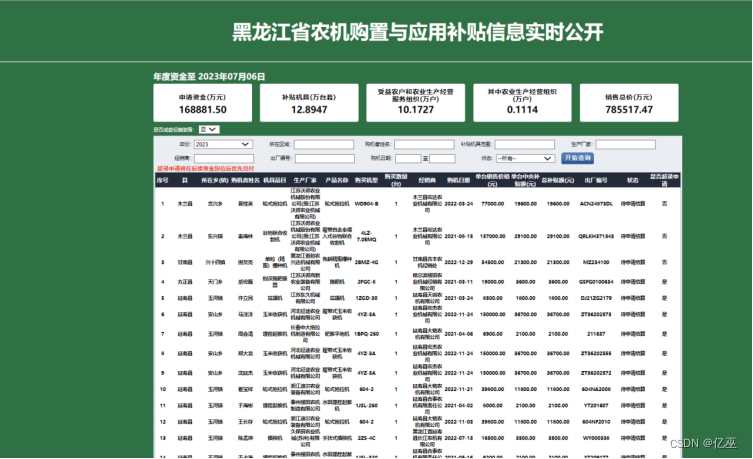
图2:黑龙江省农机购置补贴系统登录入口界面
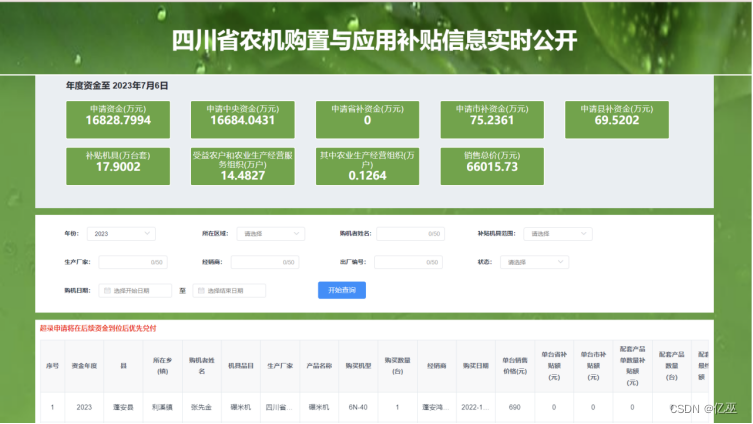
图3:四川省农机购置补贴系统登录入口界面
2.2python代码爬取数据
爬取方式使用beautifulsoup和selenium两种方式爬取
详情见实验过程
2.3数据处理与分析
1.地理可视化分析
2.同省不同年比较
3.同年不同省比较
4.同省单项数据分析
详情见实验过程
三、实验原理
3.1 python 连接网页的两种方式
3.1.1 使用requests连接网页
- 确定url,网址base_url = http://218.7.20.115:2021/pub/gongshi
- 确定起始页current_page_index = 5721
- 获取当前页的内容response = requests.get(f"{base_url}?pageIndex={current_page_index}")
3.1.2 使用from selenium import webdriver连接网页,创建网页测试
- 实例化测试网页
- driver = webdriver.Edge()
- 连接网页
- driver.get(f'http://202.61.89.161:12021/subsidyOpen')
3.2 python 获取网页内容的两种方式
3.2.1 使用beautifulsoup获取标签间文本内容爬取
1、导入模块:
from bs4 import beautifulsoup
2、选择解析器解析指定内容:
soup=beautifulsoup(解析内容,解析器)
常用解析器:html.parser,lxml,xml,html5lib
3、使用find\find_all方式
- find_all( name , attrs , recursive , text , **kwargs )
- 根据参数来找出对应的标签,但只返回第一个符合条件的结果。
- find( name , attrs , recursive , text , **kwargs )
- 根据参数来找出对应的标签,但只返回所有符合条件的结果。
筛选条件参数介绍:
- name:为标签名,根据标签名来筛选标签
- attrs:为属性,,根据属性键值对来筛选标签,赋值方式可以为:属性名=值,attrs={属性名:值}(但由于class是python关键字,需要使用class_)
分层获取表格行内容
- find("table") 获取表格
- find_all("tr") 获取每一行
- find_all("td") 获取行中列项,具体到一个单元格
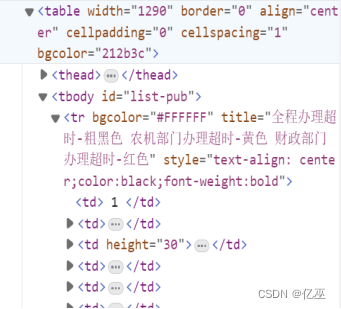
图1:黑龙江省农机补贴系统元素示例
3.2.2 使用selenium模拟点击爬取网页
1.使用selenium中的webdriver连接测试网页
sous=driver.find_elment_by_xpath("//*[@id='app']/div/div[2]/div[2]/form/div/div/div[1]/div/div/div/div/span/span/i")
sous.click()
time.sleep(1)
图2:定位到高级搜素并点击
driver.find_element(By.XPATH, "/html/body/div[2]/div[1]/div[1]/ul/li[2]").click()
time.sleep(1)
![]()
4.点击查询
button = driver.find_element_by_xpath("//*[@id='app']/div/div[2]/div[2]/form/div/div/div[10]/button")
button.click()
time.sleep(1)
![]()
图4:点击查询
5.点击下一页或先点击尾页再点击上一页,进行翻页操作
button = driver.find_element_by_xpath("//*[@id='app']/div/div[2]/div[3]/div[2]/div/div/button[2]").click()
3.3 两种方式的优缺点分析
Beautifulsoup:
缺点:遇到选择不同年份,网址无改变,无法获取2021和2022年内容
优点:爬取速度快
Selenium:
缺点:爬取速度慢
优点:解决了beautifulsoup的缺点
四、实验过程
4.1 爬取网页
4.1.1第一种爬取方式:
import csv import requests from bs4 import BeautifulSoup import sys import io base_url = "http://218.7.20.115:2021/pub/gongshi" current_page_index = 5721 # 创建CSV文件 file_path = "C:/Users/prx17/anaconda3/scirapy/2023黑龙江农机补贴3.csv" with open(file_path, mode="w", newline="", encoding="utf-8") as file: writer = csv.writer(file) # 循环遍历页面 while current_page_index<8340: # 获取当前页的内容 response = requests.get(f"{base_url}?pageIndex={current_page_index}") response.encoding = 'utf-8' html_content = response.text soup = BeautifulSoup(html_content, "html.parser") table = soup.find("table") rows = table.find_all("tr") # 写入每一行数据 for row in rows[1:]: data = [cell.text for cell in row.find_all("td")] writer.writerow(data) #输出页数作为观察获取数据的情况的指标 print(current_page_index) current_page_index += 1 print(f"成功保存信息至文件:{file_path}")

图1:爬虫过程输出图
爬取结果:

图2:爬虫结果csv图
4.1.2使用第二种方式进行爬虫
import requests
import csv
from bs4 import BeautifulSoup
# 发送HTTP请求获取网页内容
import requests
import csv
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
import pandas as pd
import numpy as np
from selenium.webdriver.support.ui import Select
# 或者直接从select导入
# from selenium.webdriver.support.select import Select
#打开
driver = webdriver.Edge()
header={"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.58"
}
driver.get(f'http://202.61.89.161:12021/subsidyOpen')
time.sleep(1)
#s = driver.find_element_by_id('YearNum')
#options_list = Select(s).options # 返回所有选项
#for option in options_list:
#print(option.text) # 打印每个选项的文本值
#Select(s).select_by_index(2) # 选中索引值为2的选项(index从0开始)
#time.sleep(2)
#Select(s).select_by_value('2022') # 选中value值为49的选项:Fax
time.sleep(1)
#button2 = driver.find_element_by_xpath("//*[@id='app']/div/div[2]/div[3]/div[2]/div/div/ul/li[12]")
#button2.click()
#time.sleep(2)
#Select(s).select_by_visible_text('Mail') # 选中文本为Mail的选项
#创建dataframe
num=1
#定位客户列表
file_path = "C:/Users/prx17/anaconda3/scirapy/2023四川农机补贴1.csv"
#print(df[-10:-1])
#time.sleep(2)
for i in range(4987):
#print(i)
for n in range(1,16):
userslist = driver.find_elements_by_xpath(f"//*[@id='app']/div/div[2]/div[3]/div[1]/div[3]/table/tbody/tr[{n}]")
#print(userslist)
for user in userslist:
data = user.text.split('\n')
#print(data)
#print(type(data))
datas=[]
datas.append(data)
#print(datas)
with open(file_path, mode="a", newline="",encoding="utf-8") as file:
writer = csv.writer(file)
for m in datas:
#n=m.split(' ')//*[@id="app"]/div/div[2]/div[3]/div[2]/div/div/button[2]
#print(m)
#data=[cell.text for cell in user.find_all("td")]
writer.writerow(m)
file.close()
print(num)
num += 1
#if i<6:
time.sleep(2)
button = driver.find_element_by_xpath("//*[@id='app']/div/div[2]/div[3]/div[2]/div/div/button[2]")
# else:
# button2 = driver.find_element_by_xpath("//*[@id='pager']/div/a[14]")
button.click()
# print(df[-10:-1])
time.sleep(2)
print(f"成功保存信息至文件:{file_path}") 爬取结果:

图3:爬虫结果csv图
4.2 数据量统计
总共约82.8万条数据

图4:爬虫数据量结果统计
4.3 处理数据
因为第一次爬虫时发现未删除换行符,导致数据中有换行符,不方便进行数据分析
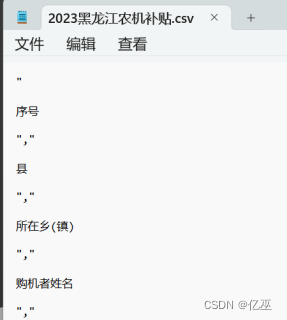
图1:数据结果
后加上去除换行符得到解决
五、数据分析
5.1 地理可视化分析
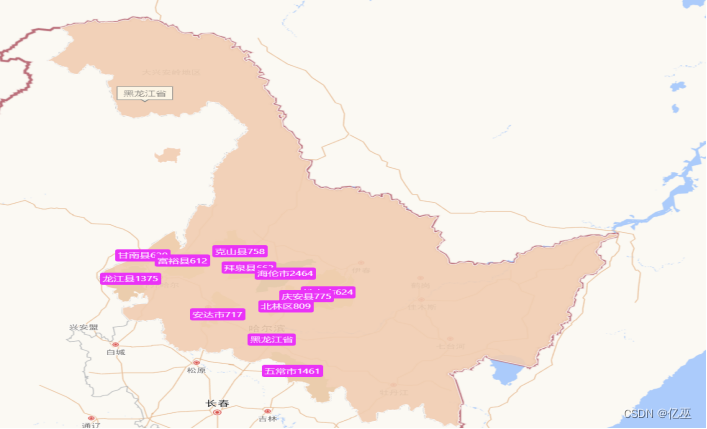
图1:黑龙江省前十一名补贴频率最高城市地图
从黑龙江省的地图来看,补贴高频城市前十一名主要集中在黑龙江省的西南部,在黑龙江省的西南部的原因有以下几个方面:
- 近江
- 温度比北部更高
- 东北平原地区有着肥沃的黑土地,黑龙江的西南地区就位于东北平原内,黑土地对农作物的生长有好作用
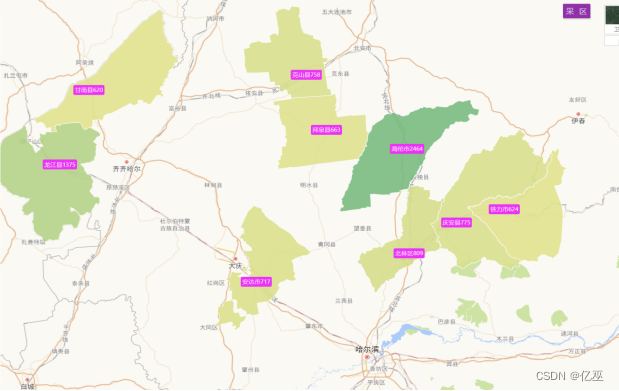
图2:黑龙江省前十一名补贴频率最高城市地图
可以看出高频城市有:
- 海伦市
- 龙江县
- 北林区
- 铁力市
- 克山县
- 安达市、等
绿色颜色越深,补贴次数申请次数越多,变相显示使用农机的频率更高。
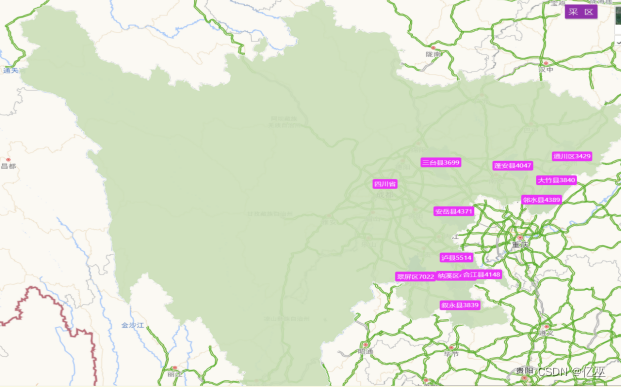
图3:四川省前十一名补贴频率最高城市地图
从四川省的地图来看,补贴高频城市前十一名主要集中在四川省的东部,在黑龙江省的东部的原因有以下几个方面:
- 靠近长江
- 温度比西部高原草原地区更高
- 科技也比较发达
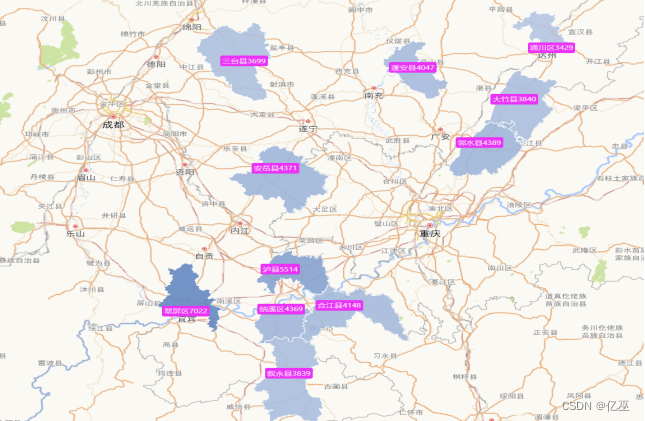
图4:四川省前十一名补贴频率最高城市地图
可以看出高频城市有:
- 翠屏区
- 沪县
- 邻水县
- 安岳县
- 纳溪区
- 合江县
- 蓬安县
绿色颜色越深,补贴次数申请次数越多,变相显示使用农机的频率更高。
5.2 同省不同年比较
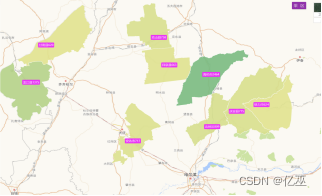
图5:黑龙江省2021年前十一名补贴频率最高城市地图 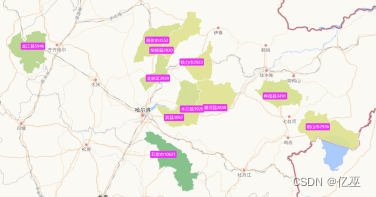
图6:黑龙江省2023年前十一名补贴频率最高城市地图

图7:2021年黑龙江补贴高频城市图
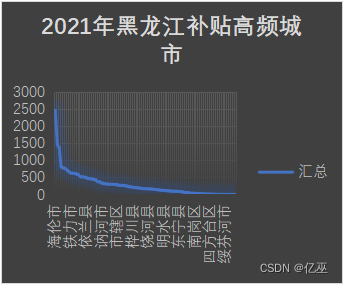
图8:2023年黑龙江补贴高频城市图
由图可以看出,从2021到2023年,补贴频率前十一名城市波动较大,但总体还是集中在黑龙江省的西南部,并且,新兴五常市对农机补贴申请大大增加,可以分析出五常市对科技农业的重视开始上升。
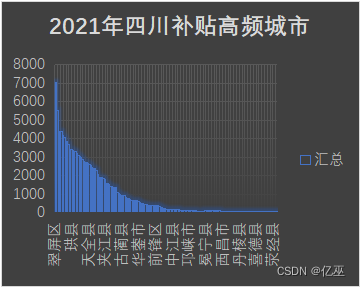
图9:2021年四川补贴高频城市图

图10:2023年四川补贴高频城市
由图可以看出,四川省从2021到2023年,补贴频率前十一名城市略有波动,变化不大

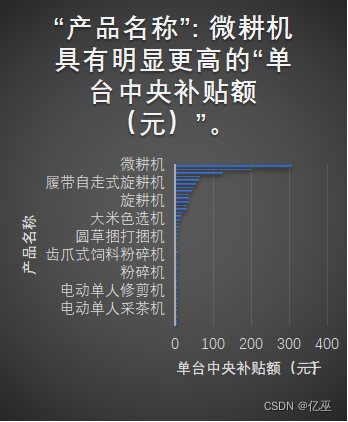
图11:2021年四川的单台中央补贴额(元)的产品名称 图12:2023年四川的单台中央补贴额(元)的产品名称
四川各产品的单台中央补贴额(元)从2021年到2023年,高补贴额的产品变化大,2021年排名在前的轮式拖拉机变为后来2023年的微耕机,各种器具的使用变化很大,说明农机的产品使用变化比较大。
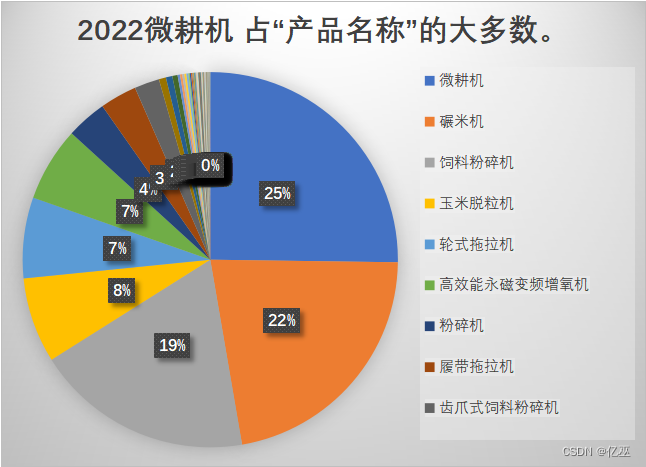
图13:2022年四川的的产品名称占数扇形图

图14:2023年四川的的产品名称占数扇形图
四川各产品的数量从2022年到2023年的变化来看,使用最多的还是微耕机,并且微耕机使用的频率越来越高了,从2022年的占全部的百分之二十五变化为2023年的占全部的百分之五十二,碾米机和饲料粉碎机的使用也变多了,但是细看饲料粉碎机的使用频率变化更大,比碾米机多百分之二,说明畜牧业的科技使用程度变高。
5.3 同年不同省比较
5.3.1 2023年黑龙江和四川产品的单台中央补贴额(元)比较
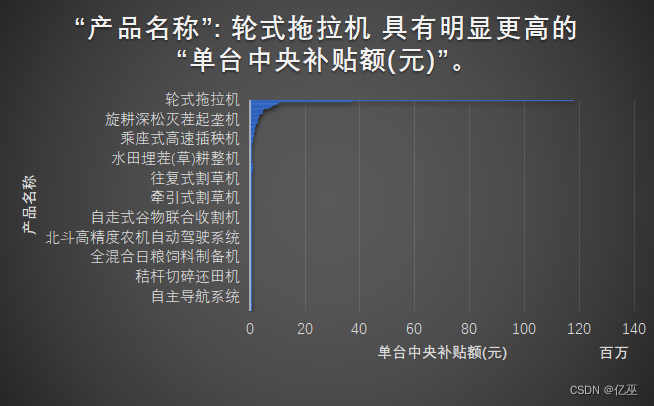
图15:2023年黑龙江的单台中央补贴额(元)的产品名称
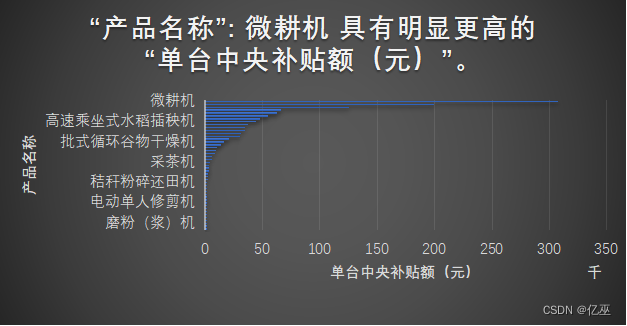
图16:2023年四川的单台中央补贴额(元)的产品名称
黑龙江作为中国东北的代表,四川作为中国西南的代表,从常用农机上来看,使用差别很大,在黑龙江里面,单台中央补贴额高的有轮式拖拉机,水田平地搅浆机,全混日粮搅拌机,秸秆压捆机等,而对于四川省高的是微耕机,高速乘坐式水稻插秧机,批式循环谷物干燥机,采茶机等,可以看出来使用什么样的机器原因如下
- 农作物种类,南北差异大
- 地形差异大,使用农机不同,四川多为山区,而黑龙江西南地区在东北平原上

图17:黑龙江与四川三年补贴数比较折线图
从三年的补贴数的变化趋势上来看,四川省补贴数在2021年达到最高,后两年有有所下降,但都大于黑龙江省,黑龙江省的年补贴数连续三年都有上升趋势。
5.4 同省单项数据分析

图18:黑龙江购机日期频率折线图
从黑龙江省购机日期频率折线图来看,购机日期多集中在11,12月。

图19:黑龙江机具品目单台中央补贴额图
从黑龙江机具品目单台中央补贴额图来看,机具具有高单台中央补贴额的极具排名为
- 轮式拖拉机
- 喷杆喷雾机
- 搂草机
- 秸秆粉碎还田机
- 薯类收获机
- 根茎作物播种机
并且轮式拖拉机明显高于其他机器,其余都低于60万,而轮式拖拉机达到了110万以上

图20:黑龙江城市补贴数折线图
从黑龙江城市补贴数折线图来看,五常市排名最高,并且与其他市区有很大的差距,唯一达到10000以上的补贴数
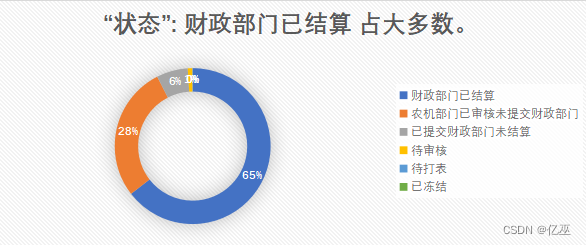
图21:结算状态扇形图
从结算状态扇形图来看,财政部门已结算占大多数,第二位为农机部门已审核未提交财政部门,说明农机部门的审核很快,但有一大部分未提交给财政部门。

图22:黑龙江单台中央补贴额频率柱状图
从黑龙江单台中央补贴额频率柱状图来看,频率很分散。

图23:黑龙江购买数量频率柱状图
从黑龙江购买数量频率柱状图来看,购买数量全低于6,说明农机单次购买不集中。
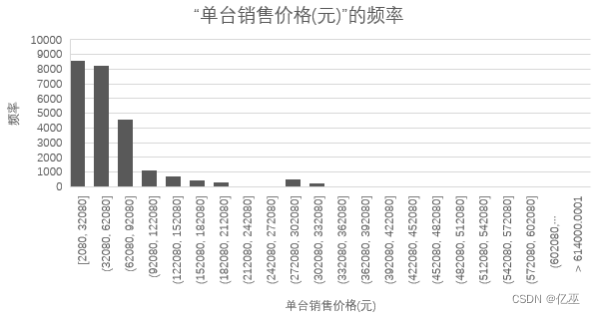
图24:黑龙江单台销售价格的频率的柱状图
从黑龙江单台销售价格的频率的柱状图来看,低价农机的频率比较高,有价钱越高,农机越少的趋势。

图25:黑龙江单台中央补贴额(元)的柱状图
从黑龙江单台中央补贴额(元)的柱状图来看,低价的频率会更高。

图26:生产厂家受补贴数扇形图
从生产厂家受补贴数扇形图来看,前四大公司如图,各生产厂家的受补贴数差别不大。
六、实验结果
6.1代码文件
见提交版本中的main(爬取黑龙江2023年数据),scir1(爬取黑龙江2021,2022年数据),sichuan(爬取四川省2021,2022,2023年数据)
6.2 数据文件
黑龙江农机补贴.xlsx
四川农机补贴.xlsx
七、问题和解决方法
7.1 爬取不同年份的信息
遇到的问题:在使用requests连接网页,beautifulsoup方式爬取数据时,发现在爬取选择年份之后,网页的网址并没有发生改变,就无法爬取2021和2023年的数据
解决方法:使用selenium模拟用户点击来获取网页内容,就不用担心网址是否改变这个问题。
7.2爬四川的数据显示xpath找不到
原因时selenium版本太高,使用find_element(By.XPATH,path)得到解决
7.3网页不稳定
遇到的问题: 四川页面数据爬多了之后会总页数不稳定,比如从一万多页变成两百多页,造成代码运行中断。原因是网页服务器不稳定,未得到解决方法
7.4 爬取内容格式有误
原因:未去除换行符
使用 user.text.split('\n')得到解决