在Linux系统中,CPU缓存的控制由操作系统内核负责管理。具体来说,CPU缓存的策略和管理取决于硬件架构、处理器类型以及内核的版本和配置。
通常情况下,CPU缓存的加入和删除是由硬件内存管理单元(Memory Management Unit, MMU)来处理的。MMU会根据特定的算法和策略来管理缓存,以提高内存访问效率。一般来说,当程序访问某个内存区域时,MMU会检查该区域是否已经在缓存中,如果没有,则会将该区域的数据加载到缓存中,以加快后续的访问速度。
至于何时加入一级缓存或其他级别的缓存,这取决于处理器的硬件设计。不同级别的缓存通常有不同的访问速度和容量,CPU会根据特定的访问模式和工作负载来决定将数据存放在哪个级别的缓存中。通常来说,一级缓存(L1 Cache)是最快但容量最小的,而后续级别的缓存(如L2 Cache、L3 Cache等)速度逐渐减慢但容量逐渐增大。
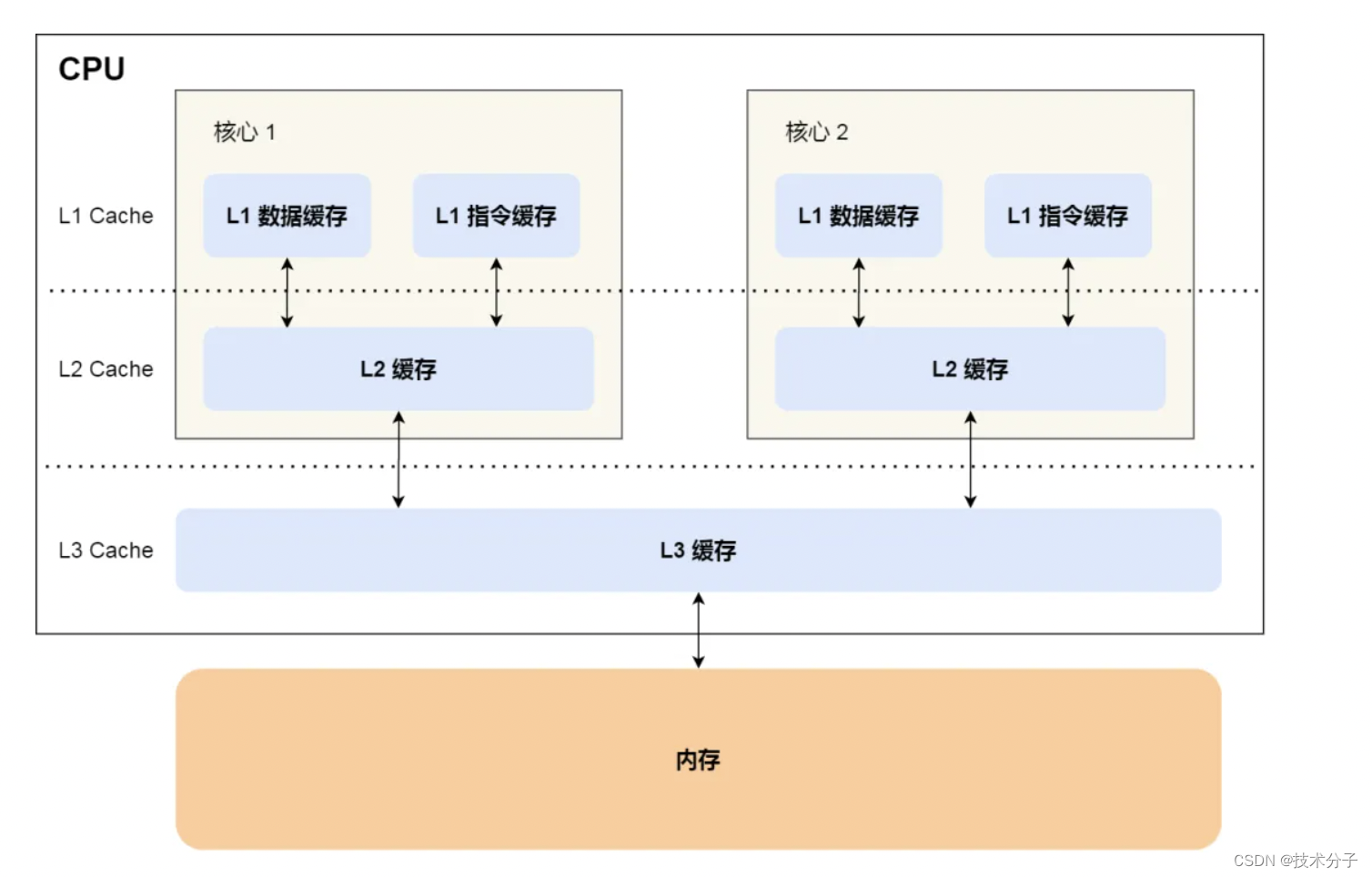
缓存与CPU的核数有一定的关系,特别是对于多核处理器。每个CPU核都可能有自己的缓存,这意味着每个核都可以独立地管理自己的缓存。然而,不同核之间可能会共享某些级别的缓存,比如L3缓存,以便更好地利用缓存资源并提高整体性能。
随着多核的发展,CPU Cache分成了三个级别:L1、 L2、L3。级别越小越接近CPU,所以速度也更快,同时也代表着容量越小。L1是最接近CPU的,它容量最小,例如32K,速度最快,每个核上都有一个L1 Cache(准确地说每个核上有两个L1 Cache,一个存数据 L1d Cache,一个存指令 L1i Cache)。L2 Cache 更大一些,例如256K,速度要慢一些,一般情况下每个核上都有一个独立的L2 Cache;L3 Cache是三级缓存中最大的一级,例如12MB,同时也是最慢的一级,在同一个CPU插槽之间的核共享一个L3 Cache。
就像数据库cache一样,获取数据时首先会在最快的cache中找数据,如果没有命中(Cache miss)则往下一级找,直到三层Cache都找不到,那只有向内存要数据了。一次次地未命中,代表取数据消耗的时间越长。
为了高效地存取缓存,不是简单随意地将单条数据写入缓存的。缓存是由缓存行组成的,典型的一行是64字节。CPU存取缓存都是按行为最小单位操作的。一个Java long型占8字节,所以从一条缓存行上可以获取到8个long型变量。所以如果访问一个long型数组,当有一个long被加载到cache中,将会无消耗地加载了另外7个,所以可以非常快地遍历数组。
既然典型的CPU微架构有3级缓存,每个核都有自己私有的L1、 L2缓存,那么多线程编程时,另外一个核的线程想要访问当前核内L1、L2缓存行的数据时,该怎么办呢?
有一种办法可以通过第2个核直接访问第1个核的缓存行。这是可行的,但这种方法不够快。跨核访问需要通过Memory Controller,典型的情况是第2个核经常访问第1个核的这条数据,那么每次都有跨核的消耗。更糟的情况是,有可能第2个核与第1个核不在一个插槽内,况且Memory Controller的总线带宽是有限的,扛不住这么多数据传输。所以CPU设计者们更偏向于另一种办法:如果第2个核需要这份数据,由第1个核直接把数据内容发过去,数据只需要传一次。
那么什么时候会发生缓存行的传输呢?答案很简单:当一个核需要读取另外一个核的脏缓存行时发生。但是前者怎么判断后者的缓存行已经被弄脏(写)了呢?
下面将详细地解答以上问题. 首先需要谈到一个协议---MESI协议。现在主流的处理器都是用它来保证缓存的相干性和内存的相干性。M、E、S和I代表使用MESI协议时缓存行所处的四个状态:
M(修改,Modified):本地处理器已经修改缓存行, 即是脏行, 它的内容与内存中的内容不一样. 并且此cache只有本地一个拷贝(专有).
E(专有,Exclusive):缓存行内容和内存中的一样, 而且其它处理器都没有这行数据.
S(共享,Shared):缓存行内容和内存中的一样, 有可能其它处理器也存在此缓存行的拷贝.
I(无效,Invalid):缓存行失效, 不能使用.
下面简单地说明下缓存行的四种状态怎么转换的:
初始:一开始时,缓存行没有加载任何数据,所以它处于I状态。
本地写(Local Write):如果本地处理器写数据至处于I状态的缓存行,则缓存行的状态变成M。
本地读(Local Read):如果本地处理器读取处于I状态的缓存行, 很明显此缓存没有数据给它。此时分两种情况:(1)其它处理器的缓存里也没有此行数据,则从内存加载数据到此缓存行后,再将它设成E状态,表示只有我一家有这条数据,其它处理器都没有;(2)其它处理器的缓存有此行数据,则将此缓存行的状态设为S状态。P.S.如果处于M状态的缓存行,再由本地处理器写入/读出,状态是不会改变的。
远程读(Remote Read):假设有两个处理器c1和c2。如果c2需要读另外一个处理器c1的缓存行内容,c1需要把它缓存行的内容通过内存控制器(Memory Controller)发送给c2,c2接到后将相应的缓存行状态设为S。在设置之前,内存也得从总线上得到这份数据并保存。
远程写(Remote Write):其实确切地说不是远程写,而是c2得到c1的数据后,不是为了读,而是为了写,也算是本地写,只是c1也拥有这份数据的拷贝,这该怎么办呢?c2将发出一个RFO(Request For Owner)请求,它需要拥有这行数据的权限,其它处理器的相应缓存行设为I,除了它自已,谁不能动这行数据。这保证了数据的安全,同时处理RFO请求以及设置I的过程将给写操作带来很大的性能消耗。
上述内容知道,写操作的代价很高,特别当需要发送RFO消息时。那编写程序时,什么时候会发生RFO请求呢?有以下两种:
1. 线程的工作从一个处理器移到另一个处理器,它操作的所有缓存行都需要移到新的处理器上。此后如果再写缓存行,则此缓存行在不同核上有多个拷贝,需要发送RFO请求了。
2. 两个不同的处理器确实都需要操作相同的缓存行。
在Java程序中,数组的成员在缓存中也是连续的。其实从Java对象的相邻成员变量也会加载到同一缓存行中。如果多个线程操作不同的成员变量,但是相同的缓存行,伪共享(False Sharing)问题就发生了。
举个例子:一个运行在处理器core 1上的线程想要更新变量X的值,同时另外一个运行在处理器core 2上的线程想要更新变量Y的值。但是,这两个频繁改动的变量都处于同一条缓存行。两个线程就会轮番发送RFO消息,占得此缓存行的拥有权。当core 1取得了拥有权开始更新X,则core 2对应的缓存行需要设为I状态。当core 2取得了拥有权开始更新Y,则core 1对应的缓存行需要设为I状态(失效态)。轮番夺取拥有权不但带来大量的RFO消息,而且如果某个线程需要读此行数据时,L1和L2缓存上都是失效数据,只有L3缓存上是同步好的数据。读L3的数据非常影响性能,更坏的情况是跨槽读取,L3都要miss,只能从内存上加载。
表面上X和Y都是被独立线程操作的,而且两操作之间也没有任何关系。只不过它们共享了一个缓存行,但所有竞争冲突都是来源于共享。