来源: 动手学深度学习
对于序列数据处理问题,我们在 8.1节中 评估了所需的统计工具和预测时面临的挑战。 这样的数据存在许多种形式,文本是最常见例子之一。 例如,一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。 本节中,我们将解析文本的常见预处理步骤。 这些步骤通常包括:
1.、将文本作为字符串加载到内存中。
2.将字符串拆分为词元(如单词和字符)。
3.建立一个词表,将拆分的词元映射到数字索引。
- 将文本转换为数字索引序列,方便模型操作。
[https://zh-v2.d2l.ai/chapter_recurrent-neural-networks/text-preprocessing.html](https://zh-v2.d2l.ai/chapter_recurrent-neural-networks/text-preprocessing.html
细节知识点
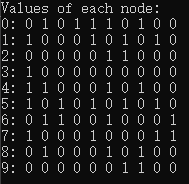
从文档中只提取字母,将其他字符去掉
def read_time_machine(): #@save
"""将时间机器数据集加载到文本行的列表中"""
with open(d2l.download('time_machine'), 'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines] # ^ 非