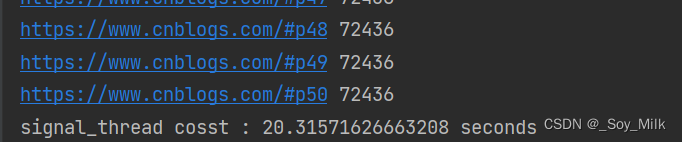
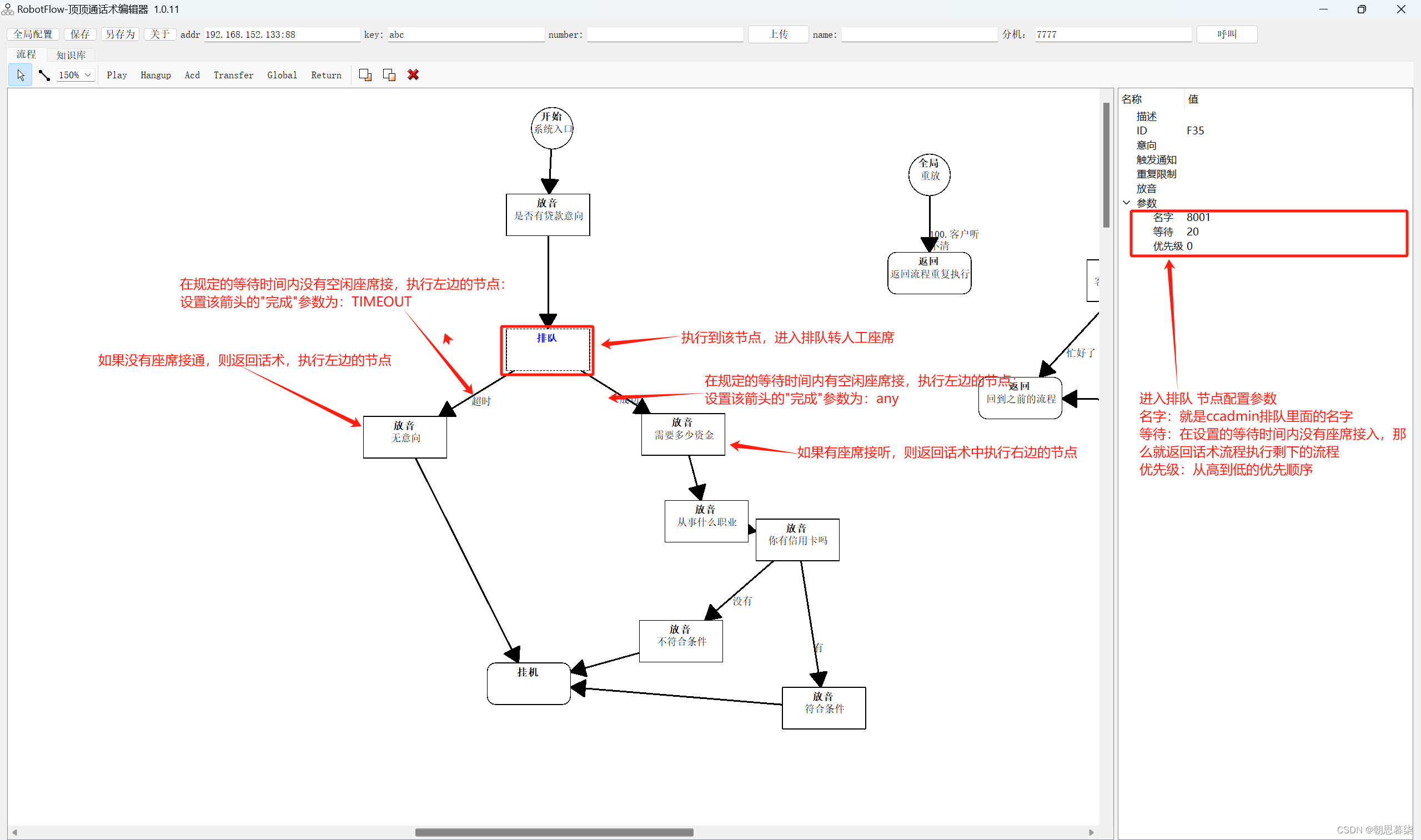
Queue的模块里面提供了同步的、线程安全的队列类,包括FIFO(先入后出)队列Queue、FIFO(后入先出)LifoQueue和优先队列PriorityQueue。(在上个文件创建了爬取文件)我们使用这个方法来获取,代码如下:
import threading
import requests
import time
import queue as Queue
link_list=[]
with open('alexa.tex','r')as file:
file_list=file.readlines()
for eachone in file_list:
link=eachone.split('\t')[1]
link=link.replace('\n','')
link_list.append(link)
start=time.time()
class myThread(threading.Thread):
def __init__(self,name,q):
threading.Thread.__init__(self)
self.name=name
self.q=q
def run(self):
print('Starting'+self.name)
while True:
try:
crawler(self.name,self.q)
except:
break
print('Exiting'+self.name)
def crawler(threadName,q):
url=q.get(timeout=2)
try:
r=requests.get(url,timeout=20)
print(q.qsize(),threadName,r.status_code,url)
except Exception as e:
print(q.qsize(),threadName,url,'Error:',e)
aii_list=['Thread-1','Thread-2','Thread-3','Thread-4','Thread-5']
workQueue=Queue.Queue(1000)
thread=[]
#建立新的线程
for thName in aii_list:
thread=myThread(thName,workQueue)
thread.start()
aii_list.append(thread)
#填充列表
for i in link_list:
workQueue.put(link_list)
#结束线程
for t in thread:
thread.join()
end=time.time()
print('当前的总时间:',end-start)
print('Exiting')对象传入myThread中;
thread = myThread(tName,workQueue)
使用一个for循环来实现:
for url in link_list=:
work.Queue.put(url)
多进程:
使用multiprocess库有两种方法:1.Process+Queue的方法 2.Pool+Queue的方法
我们因先了解计算机的cpu的核心:
from multiprocessing import cpu_count
print(cpu_count())然后代码示例:
from multiprocessing import Process,Queue
import requests
import time
link_list=[]
with open('alexa.tex','r')as file:
file_list=file.readlines()
for eachone in file_list:
link=eachone.split('\t')[1]
link=link.replace('\n','')
link_list.append(link)
start=time.time()
class myProcess(Process):
def __init__(self,q):
Process.__init__(self)
self.q=q
def run(self):
print('Starting'+self.name)
while True:
try:
crawler(self.name,self.q)
except:
break
print('Exiting'+self.name)
def crawler(q):
url=q.get(timeout=2)
try:
r=requests.get(url,timeout=20)
print(q.qsize(),r.status_code,url)
except Exception as e:
print(q.qsize(),url,'Error:',e)
if __name__ == '__main__':
ProcessNames=['prcess1','prcess2','prcess3']
workQueue=Queue(1000)
for url in link_list:
workQueue.put(url)
for i in range(0,3):
p=myProcess(workQueue)
p.daemon=True
p.start()
p.join()
end=time.time()
print('当前的总时间:',end-start)
print('Exiting')与多线程相比多进程相比,多进程里面设置了:(当父进程结束后,子进程就会自动被终止)
p.daemon=Ture
并且multprocessing自带了Queue