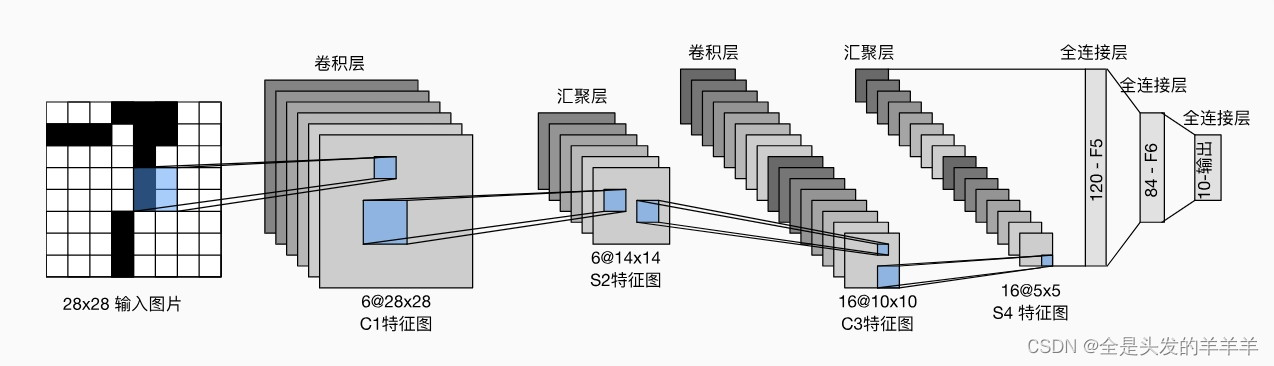
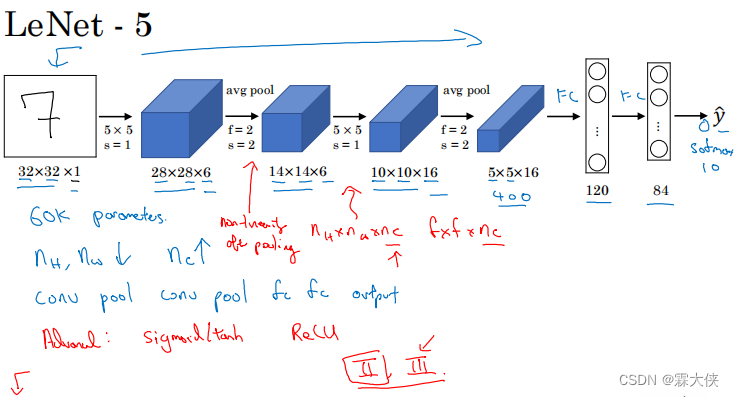
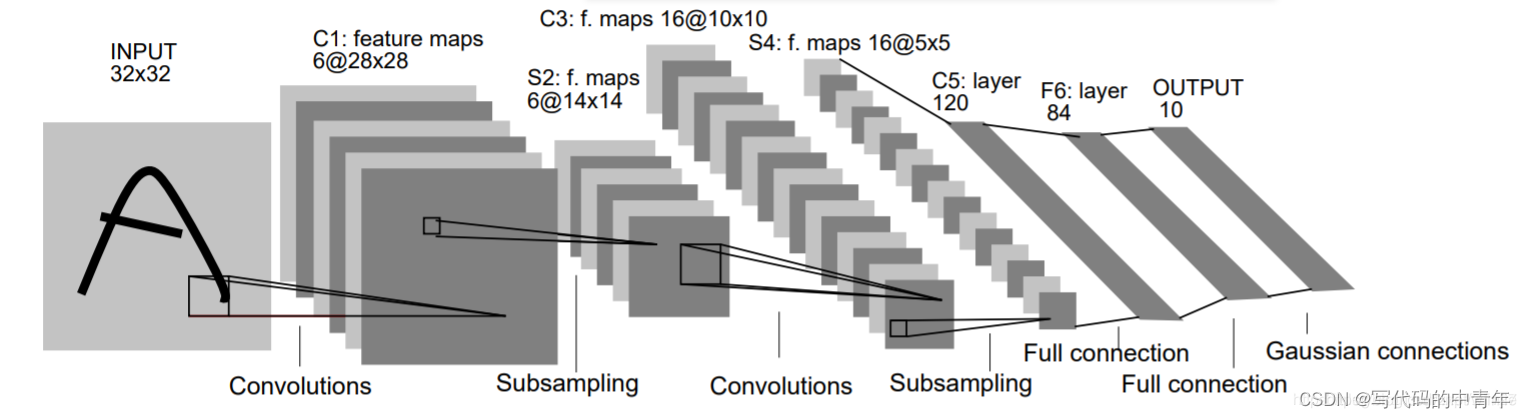
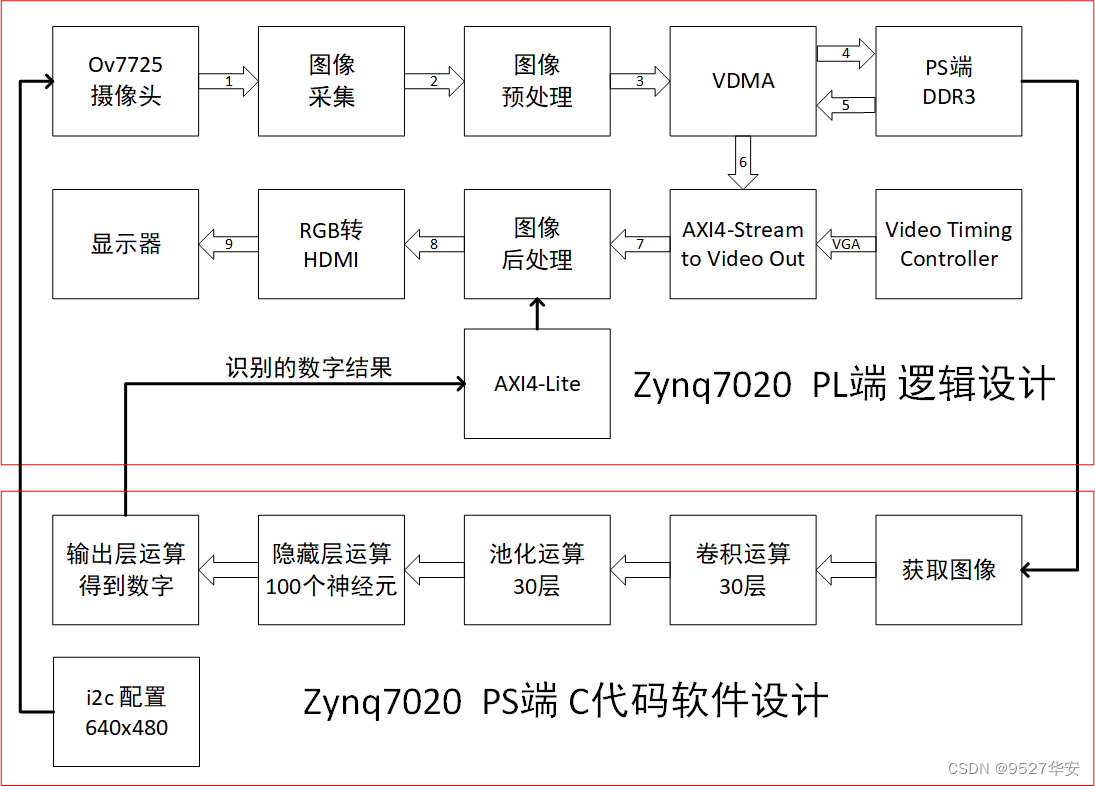
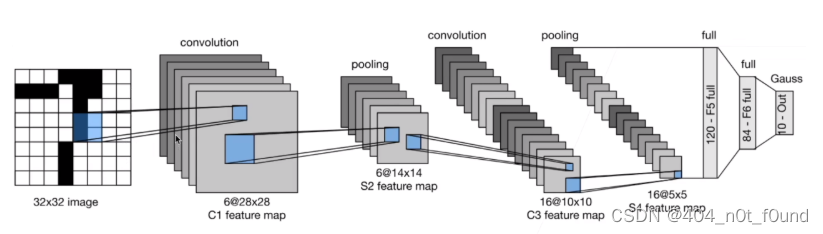
LetNet-5
参考链接:https://paddlepedia.readthedocs.io/en/latest/tutorials/CNN/convolution_operator/Convolution.html
Model
import torch
from torch import nn
class LetNet5(nn.Module):
def __init__(self):
super(LetNet5, self).__init__()
# padding=2是为了模拟原始输入的图像(32*32)
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)
self.Sigmoid = nn.Sigmoid
self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
self.pool2 = nn.AvgPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(16*5*5, 120)
self.linear2 = nn.Linear(120, 84)
self.output = nn.Linear(84, 10)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = self.pool1(x)
x = torch.relu(self.conv2(x))
x = self.pool2(x)
x = self.flatten(x)
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
x = torch.sigmoid(self.output(x))
return x
网络结构
模型model处理输入X的形式是以[batch_size, channel, height, width]的TensorShape传入的。
- X代表一个batch内多个样本输入数据
- 在MNIST中,每个图片通道数为1,所以X的通道数为1;MNIST图片大小为28x28像素;batch_size为输入的批量大小
因此:
- X的形状为torch.Size([batch_size, 1, 28, 28])
- 这里batch_size=16,则X.shape为torch.Size([16, 1, 28, 28])
这个形状就对应一个批量数据中:
- 第一维度表示batch_size=16个样本
- 第二维度表示每个图片的通道数为1
- 后两维度表示每个图片的高和宽
模型model的输入就是这种四维的形状tensor。它会逐sample处理每个28x28的特征图,进行卷积、池化等操作,输出格式保持不变。model处理X输入时,是以[batch_size, channel, height, width]的NCHW格式进行前向传播的。
所以经过conv1层后,特征图的通道数发生了改变:
- 输入x形状:(batch_size, 1, 28, 28)
- conv1核参数:核大小5x5,输出通道数6
- 经过conv1后形状:(batch_size, 6, 24, 24)
深度卷积
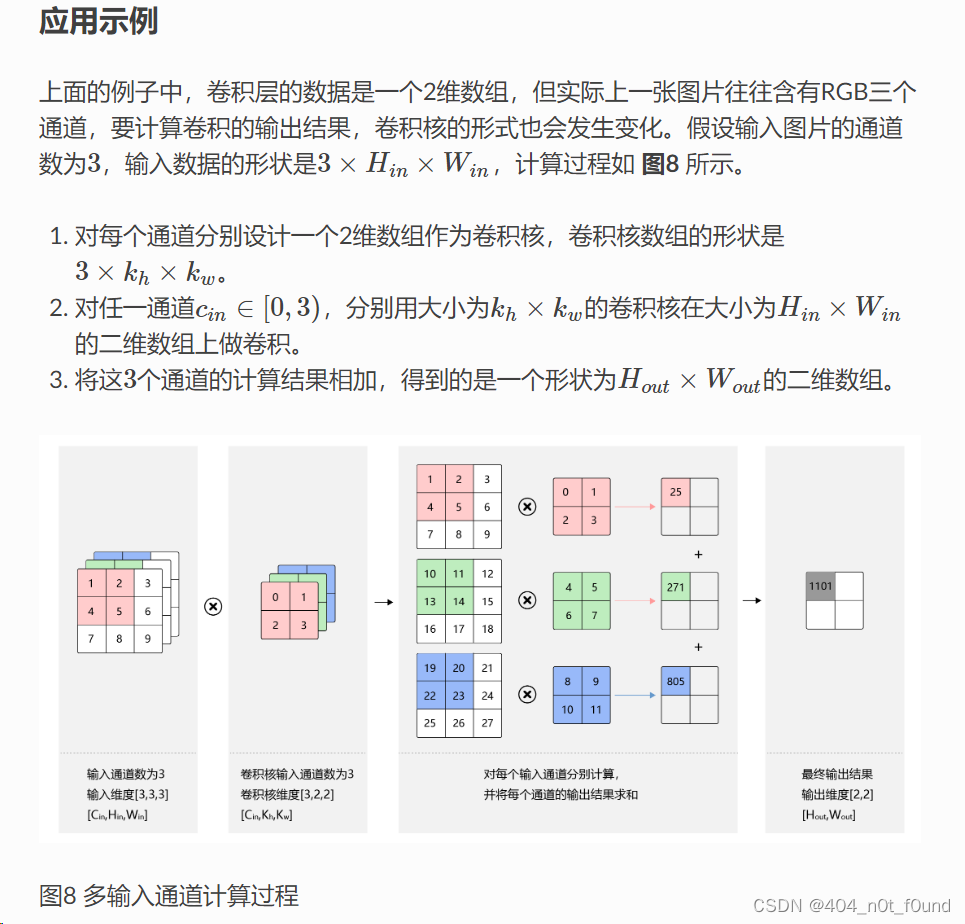
例子
如LetNet5有一个5x5大小的卷积层,第二层卷积中输通道为6、输出通道为16。
- 首先需要16个卷积核,卷积核的大小为5x5,卷积核里面有卷积层6个(这是根据输入的channel来的)
- 第一个卷积核里面的6个卷积层会对输入的6个channel的同一位置进行卷积,然后相加就得到了第一个张特征图的特征值,可以参考上图输出的特征图的第一个位置,它的结果是三个通道卷积层进行卷积的结果相加。
- 以此类推,第一个卷积核就完成了计算并输出特征图,其他15个卷积核进行的操作也是跟第一个卷积核一样的
- 至于参数首先是1个卷积核里面有6个卷积层,其次我们有16个卷积核,那参数大小就是**(5x5x6)x16**
ps:这里的卷积层是我自己的一个定义,是为了方便理解,我不知道实际上是怎么形容的,我也没去查
以下这个结果是网上的一个示意图

Train
预处理
import torch
from torch import nn
from LetNet5 import LetNet5
from torch.optim import lr_scheduler
from torchvision import datasets, transforms
import os
#初始化
data_transform = transforms.Compose(
[
transforms.ToTensor()
]
)
# 加载数据集,初始化加载器
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=data_transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, shuffle=True)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=data_transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=16, shuffle=True)
devive = "cuda" if torch.cuda.is_available() else 'cpu'
model = LetNet5().to(devive)
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)
Dataset对象存储数据的结构如下:
- Dataset是一个类,它本身不存储数据,而是封装了数据读取及索引访问的逻辑
- Dataset内部会有几个关键属性:
- datasets: 实际存储所有样本数据的列表或元组等数据结构
- transform: 数据预处理函数
- targets: 样本标签数据
- etc
- 每个样本数据以tuple的形式存储,比如(image, label);image会直接以numpy形式存储,label可能是int类型
DataLoader是将Dataset转换为minibatch的过程:
- 每次调用next()会从Dataset中读取一定数量样本
- 使用transform将图片数据转换为tensor
- 打包image字段为图片特征tensor
- 打包label字段为标签tensor
- 返回(特征tensor, 标签tensor)这个元组
具体过程:
- 遍历Dataset中所有的样本数据
-取出batchsize个sample元组
-调用transform转换image为tensor
-组装image、label为批量tensor返回
所以通过 DataLoader,我们可以一步得到处理好的(特征tensor, 标签tensor)来训练模型。它将离散的数据集转换为连续的、固定形状的小批量
训练
def train(dataloader, model, loss_function, optimizer):
loss, current, n = 0.0, 0.0, 0
for batch, (X, y) in enumerate(dataloader):
"""
X的形状为torch.Size([16, 1, 28, 28]),y的形状为torch.Size([16])
output是一个形状为(batch_size, 10)的Tensor;
——batch_size表示一个batch中样本的个数;10表示MNIST问题的类别数目,也就是0-9共10个数字
output[i,:]表示第i个样本的所有类别预测概率
"""
X, y = X.to(devive), y.to(devive)
output = model(X)
cur_loss = loss_function(output, y)
"""
返回索引及十个中最大的概率
_ : 各类别预测概率的最大值,返回的是具体值,predict:返回最大值对应的索引
清空上一轮残余梯度;计算本轮梯度;使用梯度进行参数更新
"""
_, predict = torch.max(output, axis=1)
cur_acc = torch.sum(y == predict) / output.shape[0]
optimizer.zero_grad()
cur_loss.backward()
optimizer.step()
loss += cur_loss.item()
current += cur_acc.item()
n = n+1
print("train_loss" + str(loss/n))
print("train_acc" + str(current/n))
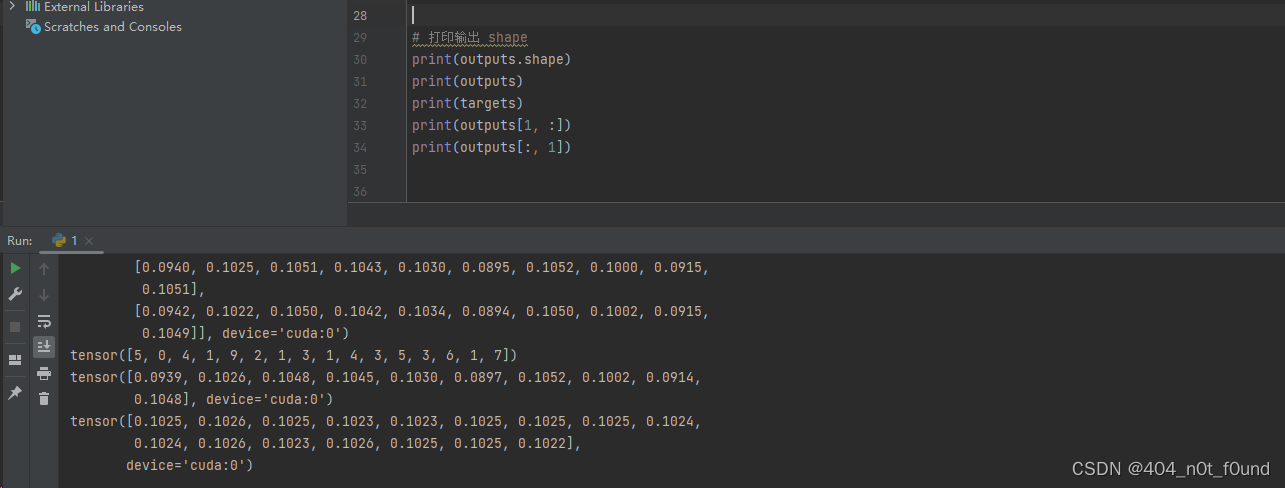
output
- 如果一个batch有16个样本,那么output的形状是torch.Size([16, 10])
- output[0,:]就是第一个样本的各类别预测概率分布,output[1,:]是第二个样本的预测概率分布
- 其中最大概率的那个类,就对应这个样本的预测结果。
举例:
- 如果output[0,7]最大,那么第一个样本的预测结果就是7
loss
oss_function计算output和y之间的损失主要有以下步骤:
输出output形状为(batch_size, num_classes),即每个样例对应每个类别的预测概率分布
如:batch_size=4, num_classes=10
output = [[0.1, 0.2, 0.3, …],
[0.4, 0.1, 0.5, …],
[0.2, 0.7, 0.1, …],
[0.9, 0.05, 0.05, …]]
标签y形状为(batch_size,),每个元素对应样例的真实类别标签
如:y = [2, 0, 7, 4]
loss_function内部会将output进行softmax获得每个样例的概率分布p
如:p = [0.1, 0.3, 0.2, …, 0.4]
将y作为索引,从对应样例的p中提取真实类别的概率
如:p[0][y[0]] = p[0][2] = 0.2
计算交叉熵损失:
loss = -log(p[y])
对应第一个样例:
loss = -log(0.2
_,predict
- _ : torch.max(output, axis=1)计算每个样例各类别预测概率的最大值,返回的是具体值。
- predict : torch.max(output, axis=1)同时也返回最大值对应的索引。也就是每个样例的预测类别索引。
具体来说:
- output形状为(batch_size, num_classes),每个样例对应的各类别预测概率
- torch.max(output, axis=1) 按行(axis=1, 即类标签维度)求最大值
- _ 返回的是这个最大概率值
- predict返回的是最大概率所在类标签的索引
Test
# 验证,不进行反向传播
def val(dataloader, model, loss_function):
model.eval()
loss, current, n = 0.0, 0.0, 0
with torch.no_grad():
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(devive), y.to(devive)
output = model(X)
cur_loss = loss_function(output, y)
# 返回索引及十个中最大的概率
_, predict = torch.max(output, axis=1)
cur_acc = torch.sum(y == predict) / output.shape[0]
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
print("val_loss" + str(loss / n))
print("val_acc" + str(current / n))
return current/n
model.eval(): 将模型设置成eval模式,这和训练模式trainable不同。eval模式下会关闭掉dropout、batchnorm等只在训练时使用的模块。
初始化验证结果统计变量loss、current、n:
loss, current, n = 0.0, 0.0, 0
使用无梯度记录模式torch.no_grad():
epoch = 50
min_acc = 0
for t in range(epoch):
print(f'epoch{t+1}\n--------------')
train(train_loader, model, loss_function, optimizer)
a = val(test_loader, model, loss_function)
# 保存最好的模型参数
if a > min_acc:
folder = 'save_model'
if not os.path.exists(folder):
os.mkdir('save_model')
min_acc = a
print('save best model')
torch.save(model.state_dict(), 'save_model/LetNet5.pth')
print('Done!')
- torch.save(model.state_dict())只保存了模型参数(权重)的状态字典,不会保存整个模型的对象
- torch.save(model, ‘model.pt’): 保存整个模型对象
示例:
假设batch_size为2, num_classes为3:
- 数据输入X shape为torch.Size([2, 1, 28, 28]);
- 输出预测结果predict shape为:torch.Size([2, 3])
例如预测概率矩阵为:
predict = torch.tensor([[0.1, 0.8, 0.1],
[0.3, 0.6, 0.1]])
- 取第一个样本的预测结果:
predict[0] = torch.tensor([0.1, 0.8, 0.1]) - torch.argmax返回概率最大的类别序号1:
torch.argmax(predict[0]) = 1 - classes值为[‘cat’,‘dog’,‘bird’]
classes[torch.argmax(predict[0])] = ‘dog’ - 真实标签y=1, classes[y] = ‘dog’
- 打印结果:
predict: ‘dog’
actual: ‘dog’