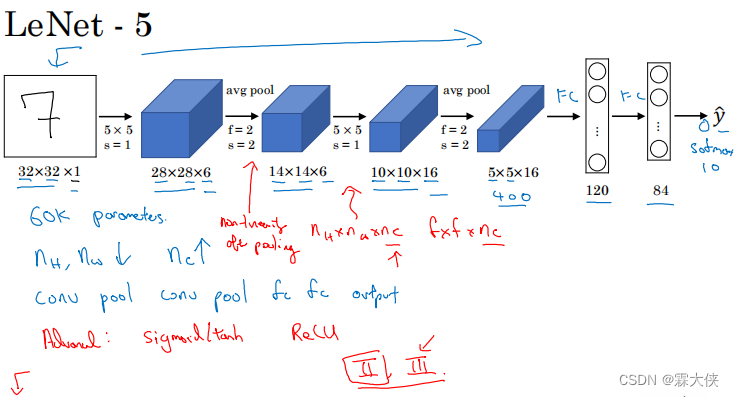
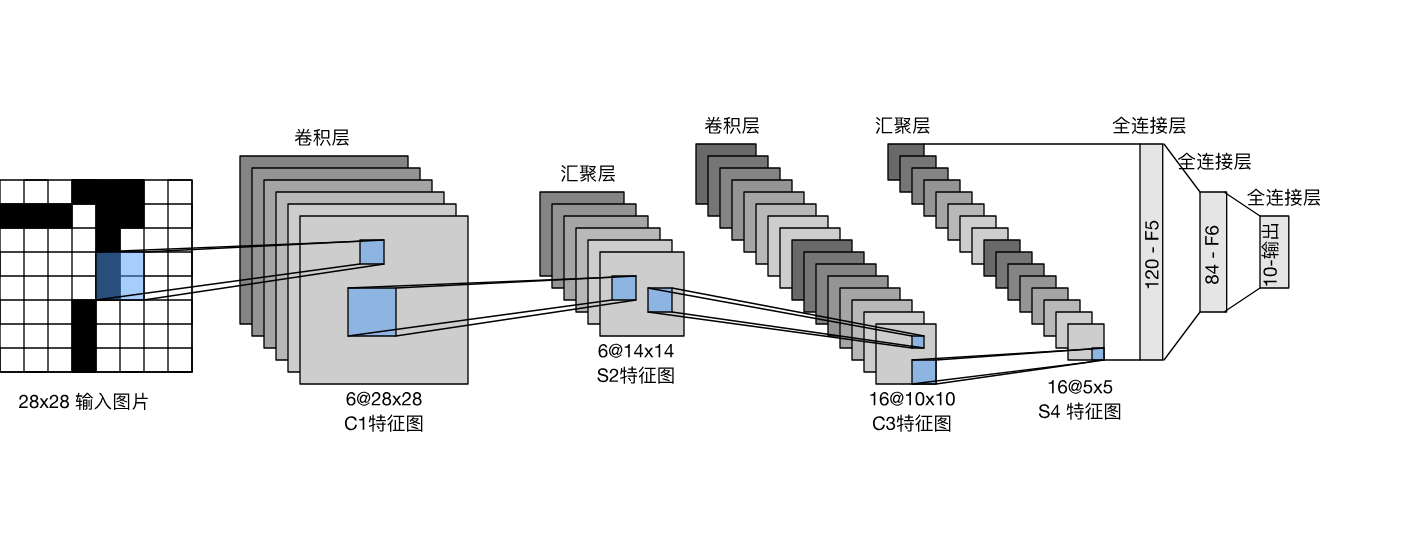
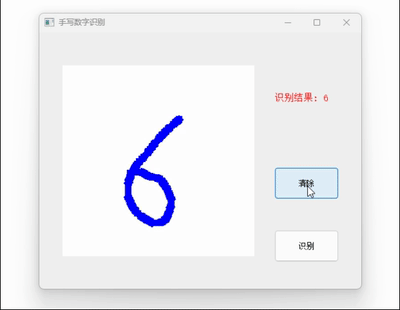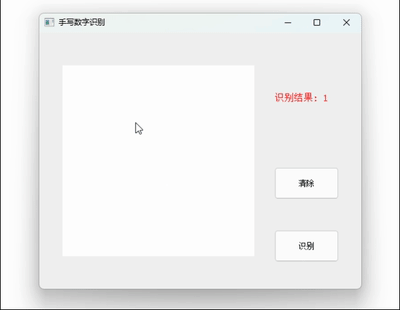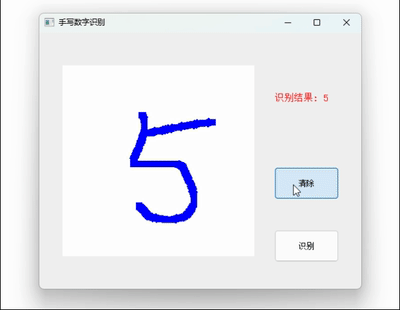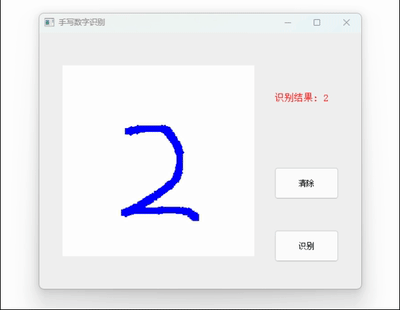
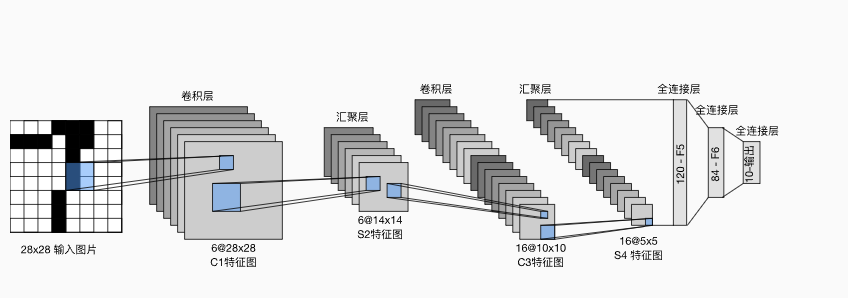
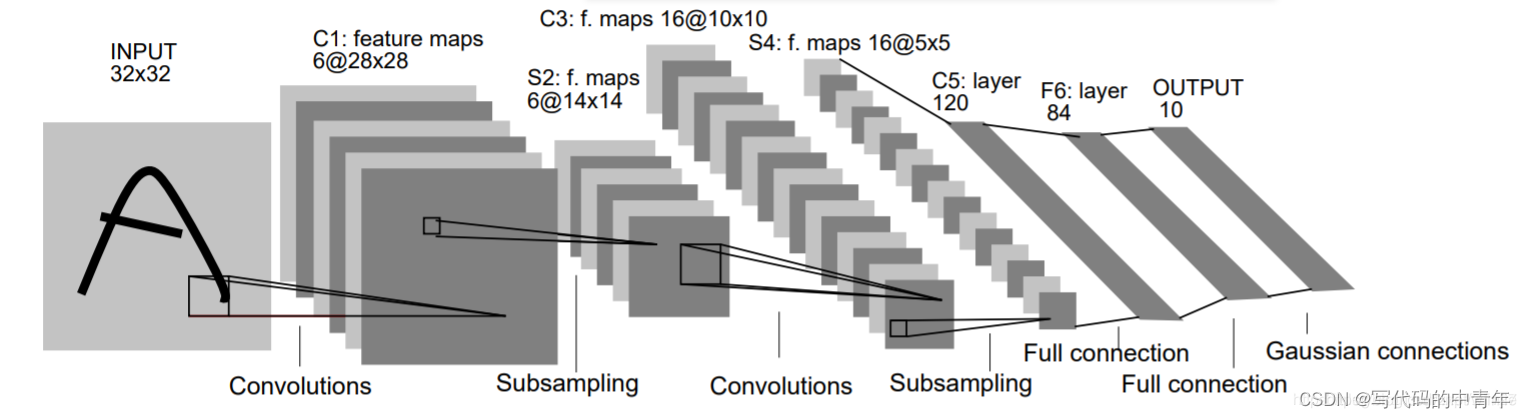
卷积神经网络CNN + Cifar10 + letnet5 深度学习实战
本文使用 p y t o r c h pytorch pytorch 和 C i f a r 10 Cifar10 Cifar10 数据集完成深度学习实战
基于卷积神经网络 C N N CNN CNN,网络结构为 l e t n e t 5 letnet5 letnet5
导入库
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
对图片进行多种预处理操作
# 对训练集图片进行多种预处理操作
train_transform = transforms.Compose([
# 数据增强
# 根据概率对图片进行水平(左右)翻转,每次根据概率来决定是否执行翻转
transforms.RandomHorizontalFlip(),
# 根据一定概率将图片转换为灰度图
transforms.RandomGrayscale(),
# 将图片数组转成张量
transforms.ToTensor(),
# 归一化操作
transforms.Normalize((0.5,), (0.5,))
])
# 对测试集图片进行多种预处理操作
test_transform = transforms.Compose([
# 将图片数组转成张量
transforms.ToTensor(),
# 归一化操作
transforms.Normalize((0.5,), (0.5,))
])
数据加载 (方法有别)
# 将路径下的图片自动加载
# 训练集的加载设置train项为True,download设置为True后,自动从网络下载并解压
train_dataset = datasets.CIFAR10(root="./data", train=True, download=True, transform=train_transform)
test_dataset = datasets.CIFAR10(root="./data", train=False, download=True, transform=test_transform)
# 定义数据加载器
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# shuffle 用来打乱数据的顺序,防止过拟合提高模型的鲁棒性
查看数据集图片
for i, (images, _) in enumerate(train_loader):
# print(images.shape)
# 把一批数据的图片组成一张图片
img = torchvision.utils.make_grid(images)
# 调整图片维度,将通道数放在最后一维
img = np.array(img).transpose(1, 2, 0)
plt.imshow(img)
plt.show()
break
设备检查
# 定义训练设备, 检查是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
定义超参
# 批大小,训练时每次输入到模型的数据的数量
batch_size = 128
# 定义学习率0.001
learning_rate = 1e-3
# 训练循环次数
epochs = 10
# 分类数
num_classes = 10
定义随机数种子以确保可重复性,设置CPU生成随机数的种子,方便下次复现实验结果
seed = 42
torch.manual_seed(seed)
定义模型结构
class CNNNeuralNetwork(nn.Module):
# 构造函数
def __init__(self):
# 访问父类的构造方法
super().__init__()
# Flatten层用来将二维图片reshape为一维向量
self.flatten = nn.Flatten()
# 在构造方法里,定义网络的结构。Sequential是一种容器,允许用户按顺序去定义神经网络的各个层
# 卷积部分提取特征
self.cnn_layer = nn.Sequential(
# 卷积层,参数含义依次为输入通道、输出特征图数(卷积核数量)、卷积核大小、步长、填充padding
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=0),
# 激活函数
nn.ReLU(),
# 池化层,选择最大池化
nn.MaxPool2d(2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=5, stride=1, padding=0),
nn.ReLU()
)
# 全连接层,进行分类
self.fc_layer = nn.Sequential(
nn.Linear(in_features=128, out_features=128),
nn.ReLU(),
# 随机丢弃,缓解过拟合,参数为丢弃的概率
nn.Dropout(0.5),
nn.Linear(in_features=128, out_features=num_classes)
)
# 定义前向传播的过程,x是输入模型的数据
def forward(self, x):
x = self.cnn_layer(x)
# view方法类似 numpy 的 reshape,用于改变张量的形状
x = x.view(-1, 128)
# logits用来描述模型未经处理(未经过激活层处理)的输出值
logits = self.fc_layer(x)
return logits
实例化模型
# 实例化模型
model = CNNNeuralNetwork().to(device)
定义损失函数和优化器
# 定义目标函数,使用交叉熵函数作为目标函数,即损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义优化器(反向传播——随机梯度下降的实现)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
定义训练过程
def train(dataloader, model, loss_fn, optimizer):
# 训练集大小
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# 计算预测值
predict = model(X)
# 计算损失值
loss = loss_fn(predict, y)
# 反向传播, backward()是用于自动计算梯度并进行反向传播的方法
loss.backward()
# 更新神经网络模型中的参数
optimizer.step()
# 清楚之前的计算梯度, torch中的梯度计算时,若不进行清除会导致梯度累加
optimizer.zero_grad()
# 显示当前训练了多少数据
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss:{loss:>7f} [{current:>5d}/{size:>5d}]")
定义测试函数
def test(dataloader, model, loss_fn):
# 训练集大小
size = len(dataloader.dataset)
num_batches = len(dataloader)
# 设置为评估模式
model.eval()
test_loss, correct = 0, 0
# 测试过程中不再进行梯度计算
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
# 计算预测值
predict = model(X)
# 计算整个数据集总的loss
test_loss += loss_fn(predict, y).item()
# 计算总正确率, argmax返回最大值的索引
correct += (predict.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \nAccuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
return correct, test_loss
绘制图像
# 存储迭代次数
iterations = []
accuracies = []
losses = []
# 初始化图形
plt.ion()
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
ax1.set_title("Accuracy over iterations")
ax1.set_xlabel("Iterations")
ax1.set_ylabel("Accuracy")
accuracy_line, = ax1.plot([], [], 'b')
ax2.set_title("Loss over iterations")
ax2.set_xlabel("Iterations")
ax2.set_ylabel("Loss")
loss_line, = ax2.plot([], [], 'r')
# 实时更新图形的函数
def update_plot(iteration, accuracy, loss):
# 添加元素到列表的最后面
iterations.append(iteration)
accuracies.append(accuracy)
losses.append(loss)
# 更新数据
accuracy_line.set_data(iterations, accuracies)
loss_line.set_data(iterations, losses)
# 更新坐标轴范围
ax1.set_xlim(0, max(iterations))
ax1.set_ylim(0, 1)
ax2.set_xlim(0, max(iterations))
ax2.set_ylim(0, max(losses) if losses else 1)
plt.draw()
plt.pause(0.1)
运行测试 t r a i n train train 和 t e s t test test
if __name__ == '__main__':
for i in range(epochs):
print(f"Epoch {i+1}\n--------------------------")
train(train_loader, model, loss_fn, optimizer)
acc, loss = test(test_loader, model, loss_fn)
update_plot(i, acc, loss)
plt.show()
输出