机器学习课程的第一个算法knn算法,全称K-Nearest Neighbor,k最邻近算法,为机器学习中最常用,也是最简单的算法。KNN通过测量不同特征值之间的距离来进行分类。本文实现的是较为简单的knn算法,包括测试集,训练集,文本记录转化为Numpy的解析,使用matplotlib创建散点图,归一化数值。
本文的训练集,测试集是来源于网上查询的鸢尾花(iris)数据集。
knn算法概述:
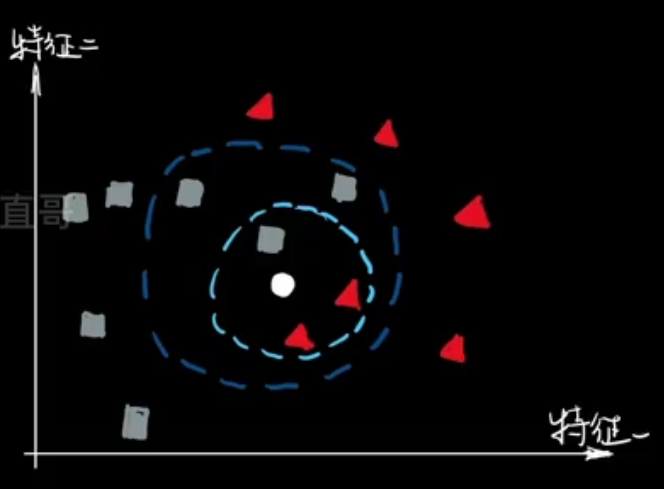
knn算法是最简单的分类算法,主要用于将一个还未分类的点进行分类,得到该点的标签。
K近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表,也就是该点的标签是用他k个最近邻居中占比最大的标签(每个邻居都带有标签,统计标签出现的个数,取最多的那个标签),把该点分类到其中。
课本中的算法思路:
对未知类别属性的数据集中的每个点依次执行以下操作:
- 计算已知类别数据集中点与当前点之间的距离。
- 按照距离递增次序排序。
- 选取与当前点距离最小的k个点。
- 确定前k个点所在类别出现的频率。
- 返回前k个点出现频率最高的类别作为当前点的预测分类。
实现过程需要用到的库:
Pandas 用于数据处理
NumPy 用于数值计算
Matplotlib 用于绘图
归一化处理:
由于数据的样式不一定统一,当数据的两个数值之间的差距过大的时候,例如(1,1000)(2,3000)这两个数据,得到欧氏距离根号(1*1+2000*2000),我们可以很清楚的看到,由于x比y小很多,所以该数据的受y的影响比较大,这不是我们想看到的,因此我们采用归一化处理,也就是说我们要让所有特征的取值在0到1中分布,这样就可以使得特征影响的相同。
我这边采用的归一化公式为:
newvalue=(oldvalue-min)/(max-min)
max和min是数据集中的最小特征值和最大特征值。我们把所有的值都转化为0~1中的值。
当然,归一化公式并不唯一,具体情况具体分析了。
训练集样式:
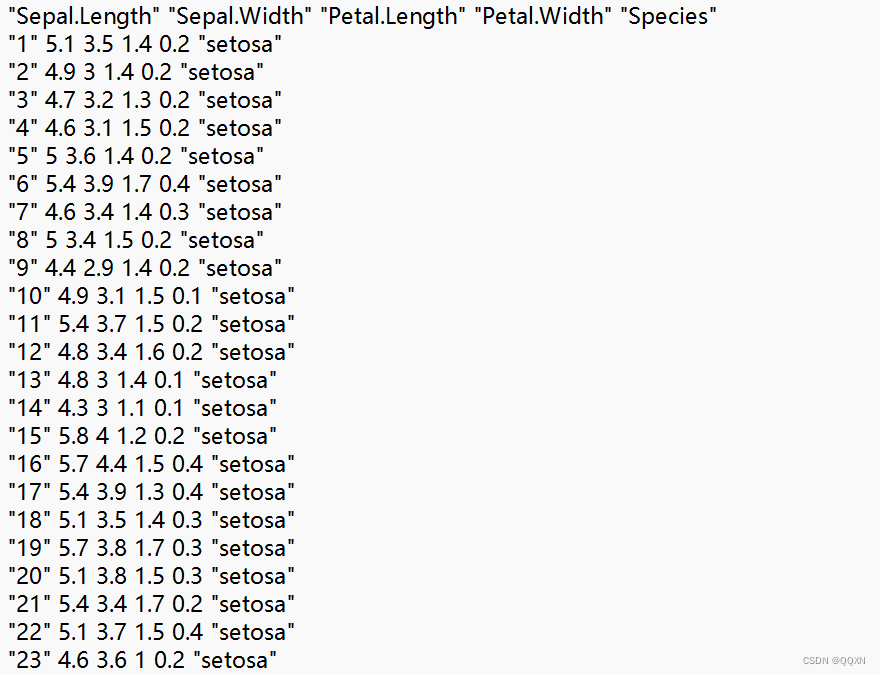
测试集样式:

编码运行问题及其我编写代码前不了解的函数:
- 读取训练集数据文件 train_data = pd.read_csv("训练集路径", sep='\s+'),函数默认情况下是用逗号分隔的,这边由于我的格式是以空格分隔的,所以加上sep='\s+'来表示是以空格区分的,当然如果你的格式是以回车分隔的,也可以改为sep='\t'。
- plt.figure()创建一个新的图形窗口或画布。
- plt.scatter(横坐标, 纵坐标, color=颜色, label=标签)用来绘制图上的一个点。
由于我未正确设置中文字体,matplotlib 画出的散点图无法显示中文,并且会抛出错误。因此我使用以下代码来表示我们采用的是微软雅黑字体,就可以正常显示中文。
plt.rcParams['font.sans-serif'] = ['SimHei']
5.X_train.max(axis=0)这里的X_train是变量名,axis=0表示沿着数组行的方向,axis=1就是表示沿着数组列的方向进行。max也就是是取这一行(列)的最大值。
6.np.mean(a == b)这个函数的作用就是a与测试集标签b相等的比例。
部分代码解释:
1.画出训练集散点图:
创建画布,并利用训练集中的数据绘制散点图。for循环中每次取到训练集中的一个数据,plt.scatter()函数根据这个鸢尾花的长度为x,宽度为y来在散点图中绘制这个点。其中xlabel,ylabel,title分别表示x轴,y轴,还有散点图的名称。然后显示散点图。以下是该部分代码和得到的散点图。
plt.figure()//创建画布
colors = {'setosa': 'red', 'versicolor': 'blue', 'virginica': 'green'}
for i in range(len(train_data)):
row = train_data.iloc[i]
plt.scatter(row["Sepal.Length"], row["Sepal.Width"], color=colors[row["Species"]], label=row["Species"])
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.xlabel('鸢尾花长度')
plt.ylabel('鸢尾花宽度')
plt.title('训练集--鸢尾花长度与宽度的关系')
plt.show()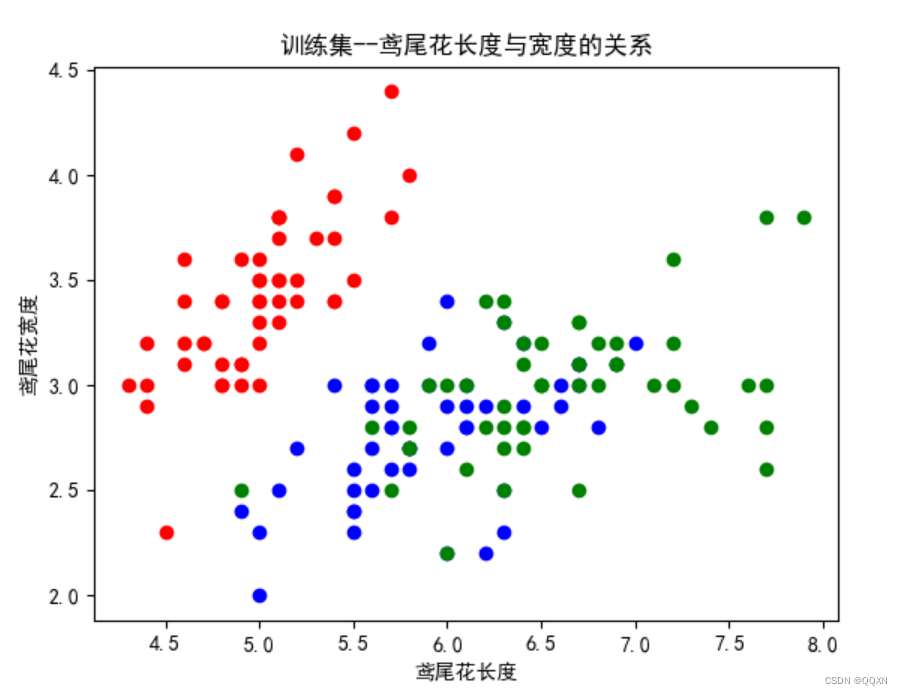
2.欧式距离计算:
欧式距离也算是空间中两点间的直线距离,也就是传统的空间距离公式:
那么对应函数也就是:
- (x1 - x2) 计算了两点在每个维度上的差值。
- (x1 - x2) ** 2 对每个维度上的差值进行平方。
- np.sum(...) 对所有维度上的平方差值求和。
- np.sqrt(...) 对上一步得到的和进行平方根运算,得到最终的欧式距离。
def euclidean_distance(x1, x2):
return np.sqrt(np.sum((x1 - x2) ** 2))3.归一化:
在代码中我们用max_vals来存储x这个特征值中的最大值,x_train.max(axis=0)(这里的axis是变量名,可以自己取)表示的是在这个训练集中x_train这一列的最大值。后面的x_train_scaled也就是把数据归一化结论得到的训练集表示。
max_vals = X_train.max(axis=0)
min_vals = X_train.min(axis=0)
X_train_scaled = (X_train - min_vals) / (max_vals - min_vals)4. K 近邻分类器:(也就是上面说的课本中的算法思路)
对于每个测试集中的点,求出该点与训练集中每个点的距离存储在distances中。np.argsort(distances)[:k]是用二分排序得到距离该点的最近k个存在nearest_indices中
在把那k个点的标签都加入到 nearest_laels中,得到最大标签数的那个加入测试集标签中。
def predict_knn(X_train, y_train, X_test, k):
y_pred = []
for test_point in X_test:
distances = [euclidean_distance(test_point, train_point) for train_point in X_train]
nearest_indices = np.argsort(distances)[:k]
nearest_labels = [y_train[i] for i in nearest_indices]
pred_label = max(set(nearest_labels), key=nearest_labels.count)
y_pred.append(pred_label)
return y_pred
5.得到最合适的k值
遍历k的取值,我这边k的取值为2~20。
将每一个k的值用临近分类器分类,然后用np.mean()计算准确率。
用best_k, best_accuracy,y_pred_test_best来记录准确率最高的k,和最高的准确率,还有这个最高的k对应的测试集中各个点的分类标签。
for j in range(2, 21):
y_pred_test_custom = predict_knn(X_train_scaled, y_train, X_test_scaled, j)
accuracy = np.mean(y_pred_test_custom == y_test)
accuracies.append(round(accuracy, 3))
print(f"准确率k={j}: {accuracy:.3f}")
if best_accuracy < accuracy:
best_k = j
best_accuracy = accuracy
y_pred_test_best = y_pred_test_custom
print(f"k取值为{best_k}的准确率最高,准确率为{best_accuracy:.3f} ")
6.计算准确率,精确值,召回率,f1值
按照课本上给出的定义和公式:
TP 表示真正例,TN 表示真负例,FP 表示假正例,FN 表示假负例
准确率: 准确率是分类器正确预测的样本数占总样本数的比例。 公式:准确率 = (TP + TN) / (TP + TN + FP + FN)
精确率: 精确率衡量的是被分类器预测为正类的样本中有多少是真正的正类样本。 公式:精确率 = TP / (TP + FP)
召回率: 召回率衡量的是真正的正类样本中有多少被分类器预测为正类。 公式:召回率 = TP / (TP + FN)
F1 值: F1 值是精确率和召回率的调和平均值,综合考虑了精确率和召回率。 公式:F1 值 = 2 * (精确率 * 召回率) / (精确率 + 召回率)
def calculate(y_test, y_pred_test_best):
accuracy = best_accuracy
precision = precision_score(y_test, y_pred_test_best, average='weighted')
recall = recall_score(y_test, y_pred_test_best, average='weighted')
f1=(accuracy*recall)*2/(accuracy+recall)
print("准确率: {:.2f}".format(accuracy))
print("精确率: {:.2f}".format(precision))
print("召回率: {:.2f}".format(recall))
print("F1值: {:.2f}".format(f1))
calculate(y_test, y_pred_test_best)学习别人的代码之后才发现对于这四个值都有对应的计算函数,例如accuracy_score, precision_score, recall_score, f1_score这些都在sklearn.metrics库中。
并且classification_report(y_test, y_pred_test_best)这个代码可以直接生成如图的表格,确实功能强大。
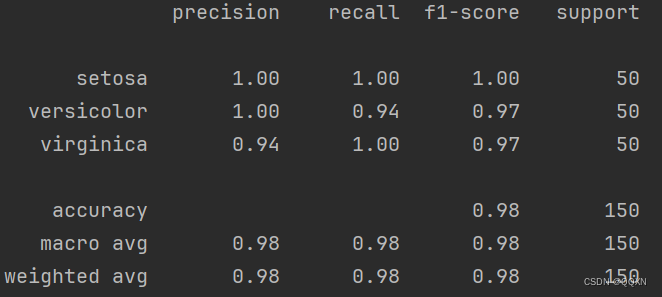
代码展示:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report
train_data = pd.read_csv("C:\\Users\\李烨\\Desktop\\新建文件夹\\6\\iris.txt", sep='\s+')
X_train = train_data[["Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width"]].values
y_train = train_data["Species"].values
plt.figure()
colors = {'setosa': 'red', 'versicolor': 'blue', 'virginica': 'green'}
for i in range(len(train_data)):
row = train_data.iloc[i]
plt.scatter(row["Sepal.Length"], row["Sepal.Width"], color=colors[row["Species"]], label=row["Species"])
plt.rcParams['font.sans-serif'] = ['SimHei']
# plt.rcParams['axes.unicode_minus'] = False
plt.xlabel('鸢尾花长度')
plt.ylabel('鸢尾花宽度')
plt.title('训练集--鸢尾花长度与宽度的关系')
plt.show()
max_vals = X_train.max(axis=0)
min_vals = X_train.min(axis=0)
X_train_scaled = (X_train - min_vals) / (max_vals - min_vals)
def predict_knn(X_train, y_train, X_test, k):
y_pred = []
for test_point in X_test:
distances = [euclidean_distance(test_point, train_point) for train_point in X_train]
nearest_indices = np.argsort(distances)[:k]
nearest_labels = [y_train[i] for i in nearest_indices]
pred_label = max(set(nearest_labels), key=nearest_labels.count)
y_pred.append(pred_label)
return y_pred
def euclidean_distance(x1, x2):
return np.sqrt(np.sum((x1 - x2) ** 2))
test_data = pd.read_csv("C:\\Users\\李烨\\Desktop\\新建文件夹\\6\\iris.csv")
X_test = test_data[["Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width"]].values
y_test = test_data["Species"].values
X_test_scaled = (X_test - min_vals) / (max_vals - min_vals)
accuracies = []
best_k = 2
best_accuracy = 0
for j in range(2, 21):
y_pred_test_custom = predict_knn(X_train_scaled, y_train, X_test_scaled, j)
accuracy = np.mean(y_pred_test_custom == y_test)
accuracies.append(round(accuracy, 3))
print(f"准确率k={j}: {accuracy:.3f}")
if best_accuracy < accuracy:
best_k = j
best_accuracy = accuracy
y_pred_test_best = y_pred_test_custom
print(f"k取值为{best_k}的准确率最高,准确率为{best_accuracy:.3f} ")
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
def calculate(y_test, y_pred_test_best):
accuracy = best_accuracy
precision = precision_score(y_test, y_pred_test_best, average='weighted')
recall = recall_score(y_test, y_pred_test_best, average='weighted')
f1=(accuracy*recall)*2/(accuracy+recall)
print("准确率: {:.2f}".format(accuracy))
print("精确率: {:.2f}".format(precision))
print("召回率: {:.2f}".format(recall))
print("F1值: {:.2f}".format(f1))
calculate(y_test, y_pred_test_best)
print(classification_report(y_test, y_pred_test_best))
代码运行结果展示:

优缺点分析(参照课本):
优点:
简单易理解:KNN 是一种直观且易于理解的算法,适合入门级别的学习和实践。
适用于多分类问题:KNN 可以处理多分类问题,并且对特征空间的结构没有严格的假设。
对异常值不敏感:KNN 算法对异常值不敏感,因为它是基于邻居间的距离计算结果。
缺点:
计算复杂度高:在预测阶段,KNN 需要计算新数据点与所有训练集数据点的距离。
预测速度较慢:由于需要计算新数据点与所有训练数据点的距离,导致在预测阶段速度较慢。
对数据不平衡和高维数据敏感:当数据集存在类别不平衡或者维度较高时,KNN 的表现可能会受到影响。
参数选择困难:KNN 中的 K 值选择对算法的性能影响较大,选择不当可能导致过拟合或欠拟合。


![[<span style='color:red;'>机器</span><span style='color:red;'>学习</span>]<span style='color:red;'>KNN</span>——K邻近<span style='color:red;'>算法</span><span style='color:red;'>实现</span>](https://img-blog.csdnimg.cn/direct/8054effd5f304dc99ac5db8e954295f0.png)

![[<span style='color:red;'>机器</span><span style='color:red;'>学习</span>]练习-<span style='color:red;'>KNN</span><span style='color:red;'>算法</span>](https://img-blog.csdnimg.cn/direct/b376f7358092469a83ff03caae3d8bb4.png)